

Google Cloud NetApp Volumes で SQL Server Always On 可用性グループを構成する
 変更を提案
変更を提案
Google Cloud NetApp Volumes iSCSI ブロックストレージを使用して、単一サブネット内の Google Compute Engine インスタンスで SQL Server Always On 可用性グループを構成します。コンピューティングインスタンスの設定方法、NetApp ボリュームの構成方法、フェールオーバークラスタリングの確立方法、および高可用性と災害復旧のための可用性グループの展開方法について説明します。
前提条件
続行する前に、Google Cloud ドキュメントにある構成の前提条件の手順を完了してください:
開始する前に
次の要件が満たされていることを確認してください:
-
コンピューティング、ネットワーク、IAM、ストレージの管理者権限を持つ Google Cloud プロジェクト
-
リージョン設定用のサブネットを持つ VPC ネットワーク
-
リージョン内で Active Directory と DNS の設定が可能
-
必要なポートを許可するように設定されたファイアウォールルール
-
SQL Server Always On 可用性グループとフェールオーバークラスタリングに関する知識

|
新規Google Cloudユーザーは、"無料トライアルクレジット"の対象となる場合があります。 |
目的
SQL Server Always On 可用性グループの構成には、次の概要タスクが含まれます。
-
Compute EngineインスタンスとNetAppストレージボリュームを設定
-
両方のノードにSQL Serverをセットアップする
-
Windows Server フェールオーバークラスタをセットアップする
-
ファイル共有監視を使用してクラスタークォーラムを設定する
-
SQL Server 可用性グループを設定する
-
リスナーアクセス用の分散ネットワーク名(DNN)を設定する
コストに関する考慮事項
このチュートリアルでは、Google Cloud の課金対象コンポーネントを使用します。"Compute Engineインスタンス"と"Google Cloud NetApp Volumes"ストレージが含まれます。
"価格計算ツール"を使用して、コンピューティングとストレージの要件に基づいてコスト見積りを生成します。この例の構成では、SQL Server Always On可用性グループのセットアップにN4-SKUコンピューティングインスタンスとNetApp Flexサービスレベルストレージを使用します。
ドメインアカウントを設定する
Active Directory に 2 つのアカウントを構成します。1 つはインストール アカウント(管理者アカウント)、もう 1 つは両方の SQL Server VM 用のサービス アカウントです。
たとえば、アカウントには次の表の値を使用します:
|
|
この例では、 `cvsdemo`をドメイン名として使用します。 `cvsdemo`を、この手順全体で実際のドメイン名に置き換えてください。 |
| アカウント | VM | 完全修飾ドメイン名 | 概要 |
|---|---|---|---|
<your account> |
両方(sqlnode1 と sqlnode2) |
cvsdemo\DomainAdmin |
いずれかの VM にサインインし、クラスタと可用性グループを設定するための管理者アカウント |
sqlsvc |
両方(sqlnode1 と sqlnode2) |
cvsdemo\sqlsvc |
両方の SQL Server VM 上の SQL Server と SQL Server Agent のサービスアカウント |
SQL Server 用の Compute Engine VM を作成する
可用性グループのレプリカをホストするために、Windows Server 2025にSQL Server 2022 Enterpriseがプレインストールされた2つのGoogle Compute Engine VMインスタンスを作成します。
-
Google Cloud コンソールで、"インスタンスを作成する"ページに移動します。
詳細については、"Google Cloud ドキュメント"を参照してください。
-
*名前*には、 `sqlnode1`を入力します。
-
マシン構成 セクションで:
-
*General Purpose*を選択
-
*Series*リストで*N4*を選択します
-
*マシンタイプ*リストで、*n4-highmem-8 (8 vCPU, 64 GB memory)*を選択します。
-
-
VPC を作成したリージョンを選択します(例:region=us-west1、zone=us-west1-a)。
-
ブート ディスク セクションで、変更 をクリックします:
-
パブリック イメージ タブの オペレーティング システム リストで、SQL Server on Windows Server を選択します。
-
バージョン リストで、SQL Server 2022 Enterprise on Windows Server 2025 Datacenter を選択します。
-
*ブート ディスクの種類*リストで、*Hyperdisk Balanced*を選択します。
-
サイズ(GB) フィールドに 50 GB と入力します。
-
Select をクリックしてブート ディスクの構成を保存します。
-
-
Networking セクションで、ネットワークインターフェイスを編集して、正しい VPC とサブネットを選択します。VPC ネットワークが 1 つしかない場合は、それがデフォルトで選択されます。
-
ネットワークインターフェイスカードで、gVNIC を選択します。
-
"ネットワーク サービス階層"の場合、ミッションクリティカルなワークロードには Premium を選択し、コストを最適化するには Standard を選択します。
-
-
作成 をクリックして VM を作成します。
-
これらの手順を繰り返して `sqlnode2`を作成します。
サーバーをドメインに参加させる
VM を作成したら、それらを Active Directory ドメインに参加させ、フェールオーバークラスタリングと iSCSI 接続に必要な Windows 機能をインストールします。
-
ローカル管理者アカウントを使用して仮想マシンにリモートで接続します。
-
サーバー マネージャーで、*ローカル サーバー*を選択します。
-
WORKGROUP リンクを選択します。
-
*コンピューター名*セクションで、*変更*を選択します。
-
*ドメイン*チェックボックスを選択し、テキストボックスにドメイン(例:
cvsdemo.internal)を入力します。 -
*OK*をクリックします。
-
Windows セキュリティ ダイアログで、デフォルトのドメイン管理者アカウントの資格情報を指定します(例:
cvsdemo\DomainAdmin)。 -
「cvsdemo.internal ドメインへようこそ」というメッセージが表示されたら、OK をクリックします。
-
*閉じる*をクリックし、ダイアログで*今すぐ再起動*を選択します。
-
サーバーを再起動したら、 `sqlsvc`アカウントをAdministratorsグループに追加します。
|
|
SQL インスタンスは、クラスタリングとフェールオーバーのセットアップに必要な sqlsvc アカウントを使用して実行されます。 |
必要なWindows機能をインストールする
サーバーマネージャーまたはPowerShellを使用して、両方のSQL ServerVMにフェイルオーバークラスタリングとMPIOをインストールします。
-
サーバー マネージャーで、管理 > 役割と機能の追加 を選択します。
-
*役割ベースまたは機能ベースのインストール*を選択し、*次へ*をクリックします。
-
サーバーを選択し、*次へ*をクリックします。
-
*機能*ページで、*フェールオーバー クラスタリング*と*マルチパス I/O*を選択します。
-
管理ツールを追加するように求められたら、機能の追加 をクリックします。
-
ウィザードを完了し、プロンプトが表示されたら再起動します。
PowerShellを管理者として実行し、次のコマンドを実行します:
# Install Failover Clustering and tools
Install-WindowsFeature Failover-Clustering, RSAT-Clustering-PowerShell, RSAT-Clustering-CmdInterface -IncludeAllSubFeature -IncludeManagementTools
# Install/enable MPIO
Install-WindowsFeature -Name Multipath-IO
Enable-MSDSMAutomaticClaim -BusType "iSCSI"
# Install .NET and other SQL prerequisites (if not already installed)
Install-WindowsFeature NET-Framework-45-Core, NET-Framework-45-Features
Install-WindowsFeature RSAT-AD-PowerShelliSCSIイニシエーター名を取得する
iSCSIイニシエーターGUIまたはPowerShellを使用して、ホストグループに含める各SQL Server VMのiSCSI修飾名(IQN)を取得します。
-
*Win+R*を押すか、Windowsの検索バーを使用して `iscsicpl`を開きます。
-
iSCSI イニシエーターのプロパティダイアログで、*構成*タブに移動します。
-
イニシエーター名 の値をコピーし、ホストグループに含めます。
例:
iqn.1991-05.com.microsoft:sqlnode1.cvsdemo.internal
PowerShellで次のコマンドを実行します:
Get-InitiatorPort | Select-Object NodeAddressNetAppブロックストレージボリュームを作成する
Google Cloud NetApp Volumes を使用して iSCSI ブロックストレージボリュームを作成し、SQL Server データベース用のハイパフォーマンスな共有ストレージを提供します。このプロセスには、ホストグループ、ストレージプール、およびデータ、ログ、一時、バックアップ用の個別のボリュームの作成が含まれます。
ホストグループを作成する
-
両方の SQL ノードからの iSCSI イニシエーターを含むホストグループを作成します。
gcloud beta netapp host-groups create HOST_GROUP_NAME \ --location=LOCATION \ --type=ISCSI_INITIATOR \ --hosts=HOSTS \ --os-type=OS_TYPE \ --description=DESCRIPTION詳細については、"ホストグループを作成する"ドキュメントを参照してください。
-
次の値を置き換えます:
-
HOST_GROUP_NAME:ホストグループの名前(例:demosql) -
LOCATION:地域(例:us-west1) -
HOSTS:sqlnode1 と sqlnode2 の両方からの IQN のコンマ区切りリスト例:
iqn.1991-05.com.microsoft:sqlnode1.cvsdemo.internal,iqn.1991-05.com.microsoft:sqlnode2.cvsdemo.internal -
OS_TYPE:オペレーティングシステムの種類(例:WINDOWS) -
DESCRIPTION:ホストグループの説明(オプション)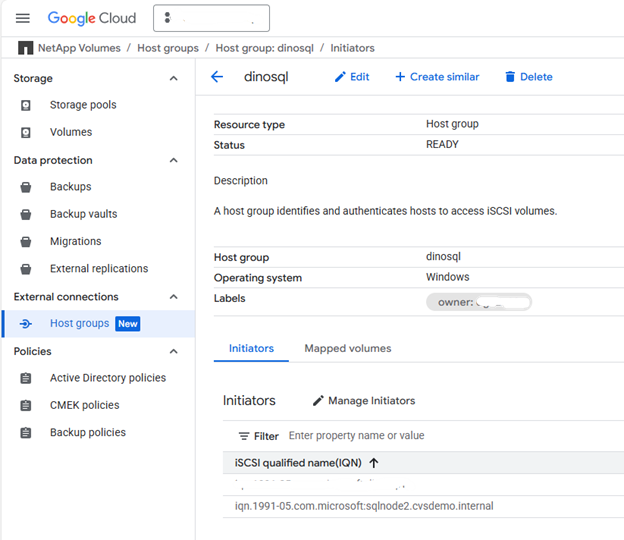
-
ストレージプールを作成する
-
適切な容量とパフォーマンスを備えたストレージプールを作成します。
gcloud netapp storage-pools create POOL_NAME \ --project=PROJECT_ID \ --location=LOCATION \ --service-level=Flex \ --type=Unified \ --capacity=1024 \ --total-throughput=64 \ --total-iops=1024 \ --network=name=VPC_NAME,psa-range=PSA_RANGE詳細については、"ストレージプールを作成する"ドキュメントを参照してください。
-
次の値を置き換えます:
-
POOL_NAME:プールの名前(例:sqltest) -
PROJECT_ID:Google Cloud プロジェクト名 -
LOCATION:コンピューティングインスタンスと同じ場所(例:us-west1-b) -
CAPACITY:プール容量(GiB単位)(例:1024) -
SERVICE_LEVEL:サービスレベル(例:Flex) -
VPC_NAME:VPCネットワーク名 -
PSA_RANGE:プライベートサービスアクセス範囲(例:xx.xxx.xxx.0/20) -
THROUGHPUT:オプションのスループット(MiBps単位)(例:64) -
IOPS:オプションのIOPS(例:1024)
-
ボリュームの作成
-
データ、ログ、一時、バックアップ用のボリュームを作成します。各ボリュームタイプに対して次のコマンドを実行します:
gcloud beta netapp volumes create VOLUME_NAME \ --project=PROJECT_ID \ --location=LOCATION \ --storage-pool=POOL_NAME \ --capacity=CAPACITY \ --protocols=ISCSI \ --block-devices="name=VOLUME_NAME,host-groups=HOST_GROUP_PATH,os-type=WINDOWS" \ --snapshot-directory=false詳細については、"ボリュームの作成"ドキュメントを参照してください。
-
次の値を置き換えます:
-
VOLUME_NAME:各ボリュームの一意の名前(例:node1data、node1log、node1temp、node1backup) -
PROJECT_ID:Google Cloud プロジェクト名 -
LOCATION:ストレージプールと同じ場所(例:us-west1-b) -
POOL_NAME:ストレージプール名(例:sqltest) -
CAPACITY:ボリューム容量(GiB単位)(例:200) -
HOST_GROUP_PATH:ホストグループへの完全なリソースパス(例:projects/PROJECT_ID/locations/us-west1/hostGroups/demosql)
-

|
複数のホストグループを指定する場合は、各ホストグループを # 記号で区切ります。 |
|
|
データ、ログ、一時、バックアップの各ボリュームタイプに対してこの手順を繰り返します。 |
iSCSI ボリュームをマウントする
各 SQL インスタンスに非共有 iSCSI ボリュームをマウントします:
-
Google Cloud コンソールで、NetApp volumes > Volumes に移動します。
-
SQLインスタンス用に作成されたボリュームを選択します(例:
node1data)。 -
iSCSIターゲットの両方のIPアドレスをコピーします(例:
10.165.128.216`および `10.165.128.217)。 -
sqlnode1で実行 `iscsicpl`またはPowerShellを使用:
-
Discover タブをクリックし、次に Discover Portal をクリックします。
-
取得した各 IP アドレスを追加します。デフォルトのポート 3260 のままにします。
"10.165.128.216","10.165.128.217" | % { New-IscsiTargetPortal -TargetPortalAddress $_ }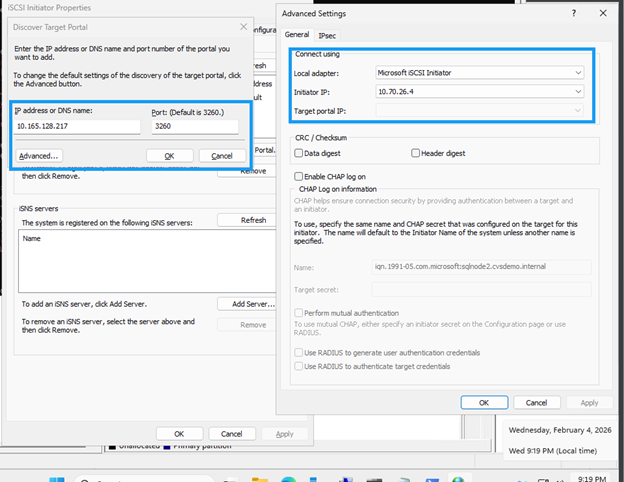
-
*ターゲットに接続*ダイアログで、マルチパスを使用する場合は*マルチパスを有効にする*をチェックします。
-
*詳細*をクリックし、ドロップダウンからターゲットポータルIPを選択します。
-
*OK*をクリックして接続します。
-
iSCSIデバイスのMPIOを設定する
-
コントロールパネルまたはServer ManagerからMPIOを開きます。
-
*Discover Multi-Paths*タブをクリックします。
-
iSCSI デバイスのサポートを追加する をチェックし、追加 をクリックします。
-
プロンプトが表示されたら再起動します。
-
デバイス マネージャーの ディスク ドライブ でマルチパス構成を確認します。
-
-
ボリュームの初期化とフォーマット
-
コンピュータ管理を起動し(
compmgmt.msc、*ディスクの管理*を選択します。 -
各ディスクを 64K の割り当て単位で初期化、パーティション分割、フォーマットします:
Format-Volume -DriveLetter <DriveLetter> -FileSystem NTFS -NewFileSystemLabel <Label> -AllocationUnitSize 65536 -Confirm:$false -
ドライブ文字を割り当てます(たとえば、データの場合は D:、ログの場合は E:、バックアップの場合は F:、Temp の場合は G:)。
-
SQL Server のディレクトリ構造を作成します:
$paths = "D:\MSSQL\DATA","E:\MSSQL\Log","F:\MSSQL\Backup","G:\MSSQL\Temp" $paths | % { New-Item -ItemType Directory -Path $_ -Force }
-
SQL Server を設定する
両方のノードでSQL Serverをドメインサービスアカウントを使用するように構成し、デフォルトのパスをNetAppボリュームを使用するように更新し、システムデータベースを新しいストレージの場所に移動します。
-
クラスター認証とフェールオーバーのサポートのために、SQL Server および SQL Server Agent サービスを更新して、ドメイン サービス アカウントで実行されるようにします。
-
各SQLインスタンスで、 `services.msc`を開きます。
-
SQL ServerおよびSQL Server Agentサービスの*ログオン名*を `domain\sqlsvc`に更新します。
-
SQL Server Management Studio(SSMS)を開き、ドメインアカウントに接続します。
接続に失敗した場合は、SSMSを `<local computer>\Administrator`として起動します。ユーザーとグループで適切なパスワードを使用して管理者アカウントが有効になっていることを確認します。
-
-
必要な権限を持つドメインアカウントログインを作成します。
`CVSDEMO`を、次の SQL コマンドの実際のドメイン名に置き換えます。 USE [master] GO -- Create login for SQL service account CREATE LOGIN [CVSDEMO\sqlsvc] FROM WINDOWS WITH DEFAULT_DATABASE=[master], DEFAULT_LANGUAGE=[us_english] GO -- Add to sysadmin role ALTER SERVER ROLE [sysadmin] ADD MEMBER [CVSDEMO\sqlsvc] GO -- Create user in master and assign role USE [master] GO CREATE USER [CVSDEMO\sqlsvc] FOR LOGIN [CVSDEMO\sqlsvc] GO ALTER ROLE [db_owner] ADD MEMBER [CVSDEMO\sqlsvc] GO -- Repeat for model, msdb, and tempdb databases USE [model] GO CREATE USER [CVSDEMO\sqlsvc] FOR LOGIN [CVSDEMO\sqlsvc] GO ALTER ROLE [db_owner] ADD MEMBER [CVSDEMO\sqlsvc] GO USE [msdb] GO CREATE USER [CVSDEMO\sqlsvc] FOR LOGIN [CVSDEMO\sqlsvc] GO ALTER ROLE [db_owner] ADD MEMBER [CVSDEMO\sqlsvc] GO USE [tempdb] GO CREATE USER [CVSDEMO\sqlsvc] FOR LOGIN [CVSDEMO\sqlsvc] GO ALTER ROLE [db_owner] ADD MEMBER [CVSDEMO\sqlsvc] GO -
デフォルトのパスを更新して、OSドライブの代わりにNetAppボリュームを使用します:
USE [master] GO EXEC xp_instance_regwrite N'HKEY_LOCAL_MACHINE', N'Software\Microsoft\MSSQLServer\MSSQLServer', N'BackupDirectory', REG_SZ, N'F:\MSSQL\Backup' GO EXEC xp_instance_regwrite N'HKEY_LOCAL_MACHINE', N'Software\Microsoft\MSSQLServer\MSSQLServer', N'DefaultData', REG_SZ, N'D:\MSSQL\DATA' GO EXEC xp_instance_regwrite N'HKEY_LOCAL_MACHINE', N'Software\Microsoft\MSSQLServer\MSSQLServer', N'DefaultLog', REG_SZ, N'E:\MSSQL\Log' GO -
システムデータベース(model、msdb、tempdb、master)をOSドライブからNetAppボリュームに移動して、パフォーマンスと管理を向上させます。
-
現在のパスを確認します:
-- Check current paths SELECT name, physical_name FROM sys.master_files WHERE database_id IN (DB_ID('model'), DB_ID('msdb')); -
新しい場所への更新:
-- Move model database ALTER DATABASE model MODIFY FILE (NAME = modeldev, FILENAME = 'D:\MSSQL\Data\model.mdf'); ALTER DATABASE model MODIFY FILE (NAME = modellog, FILENAME = 'E:\MSSQL\Log\modellog.ldf'); -- Move msdb database ALTER DATABASE msdb MODIFY FILE (NAME = MSDBData, FILENAME = 'D:\MSSQL\Data\MSDBData.mdf'); ALTER DATABASE msdb MODIFY FILE (NAME = MSDBLog, FILENAME = 'E:\MSSQL\Log\MSDBLog.ldf'); GO -
SQL Server を停止し、ファイルを古い場所から新しいパスに手動で移動して、SQL Server を再起動します。
-
tempdbデータベースを移動する
USE master; GO -- Check current tempdb files SELECT name, physical_name FROM sys.master_files WHERE database_id = DB_ID('tempdb'); -- Change paths for tempdb ALTER DATABASE tempdb MODIFY FILE (NAME = tempdev, FILENAME = 'G:\MSSQL\Temp\tempdb.mdf'); ALTER DATABASE tempdb MODIFY FILE (NAME = templog, FILENAME = 'G:\MSSQL\Temp\templog.ldf'); GO -
変更を有効にするには、SQL Server を再起動します:
Restart-Service -Name "MSSQLSERVER" -Force
-
-
マスターデータベースを移動する
-
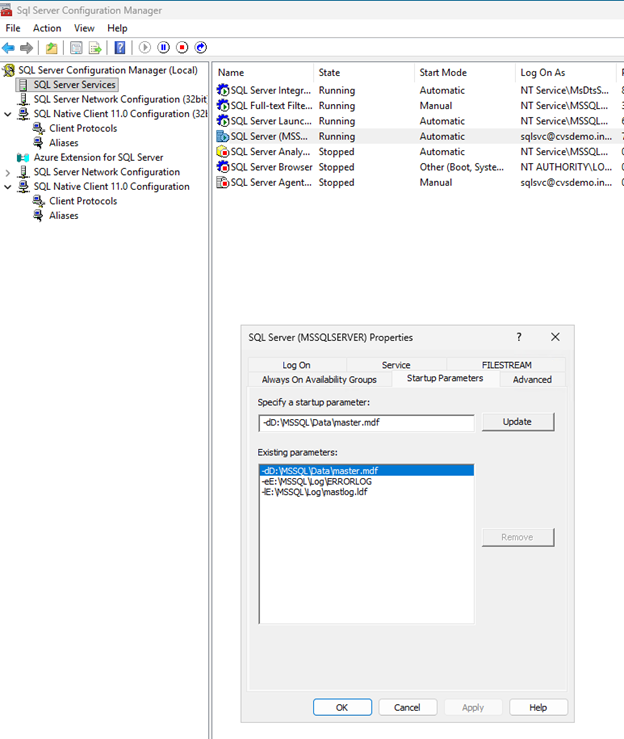
*SQL Server Configuration Manager*を開きます。
-
SQL Server Services に移動し、SQL Server (MSSQLSERVER) を右クリックして、Properties を選択します。
-
Startup Parameters タブをクリックします。
-
*既存のパラメータ*で、
-d、-e、および `-l`で始まるパラメータを探します。 -
古いパラメータを削除し、新しいパラメータを追加します:
-dD:\MSSQL\Data\master.mdf -lE:\MSSQL\Log\mastlog.ldf -eE:\MSSQL\Log\ERRORLOG
-
*OK*をクリックします。
-
-
SQL Server サービスを停止します。
-
`master.mdf`と `mastlog.ldf`を古い場所から新しいパスに手動で移動します。
-
エラーログのパスを更新した場合は、 `ERRORLOG`ファイルも移動してください。
-
SQL Server サービスを開始します。
フェールオーバークラスタを設定する
SQL Server に高可用性を提供するために、Windows Server フェールオーバー クラスタリングをセットアップします。詳細については、"Windows Server フェールオーバー クラスタリングのドキュメント"を参照してください。
ファイアウォールルールを設定する
クラスター通信、SQL Server 接続、および可用性グループのレプリケーションを有効にするには、両方の SQL ノードで必要なネットワークポートを開きます。
-
クラスター通信のために、両方の SQL ノードで必要なポートを開きます。
必要なポートは次のとおりです:UDP 3343、TCP 3343、TCP 1433、TCP 5022、TCP 135、TCP 445、TCP 49152-65535(動的RPC)。
-
両方のサーバーで次のチェックポイントを実行して、ファイアウォール経由での SQL Server とクラスタの通信を許可します。
カスタム構成がある場合は、ポート番号を調整します。
# Open firewall for SQL Server netsh advfirewall firewall add rule name="Allow SQL Server" dir=in action=allow protocol=TCP localport=1433 # Open firewall for SQL Server replication netsh advfirewall firewall add rule name="Allow SQL Server replication" dir=in action=allow protocol=TCP localport=5022ファイアウォールの詳細な要件については、"Windows Server サービスとネットワークポートの要件"を参照してください。
-
クラスターを作成する前に、両方のノードで検証チェックを実行します:
Test-Connection servername Resolve-DnsName servername Get-NetAdapterBinding -ComponentID ms_tcpip6
フェールオーバークラスタを作成する
高可用性と自動フェールオーバー機能を有効にするには、両方の SQL Server ノードを使用して Windows Server フェールオーバークラスタを作成します。
-
実行 `cluadmin.msc`または、Server Managerからフェールオーバー クラスター マネージャーを開きます。
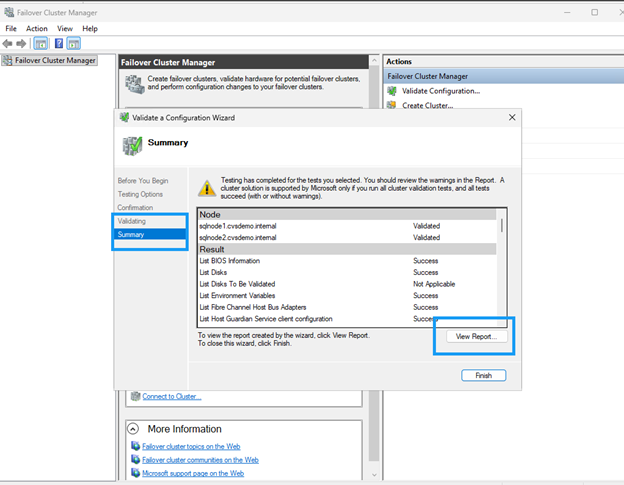
-
* Create Cluster *を選択します。
-
両方の SQL ノード(sqlnode1、sqlnode2)を追加します。
-
検証テストを実行し、すべてのチェックに合格したことを確認します。続行する前に警告を確認して修正してください。
-
クラスタ名を入力します(例:
sqlcluwest1)。 -
クラスタの作成を完了します。
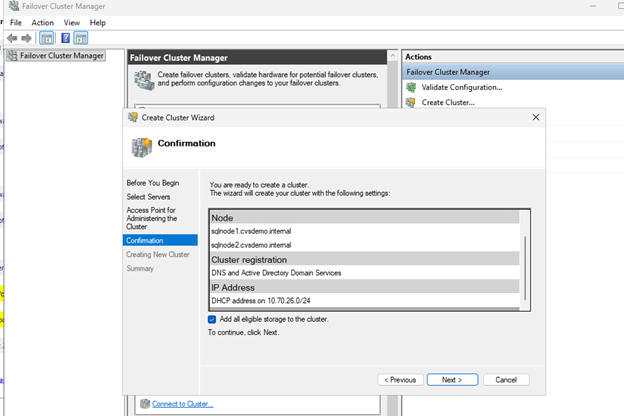
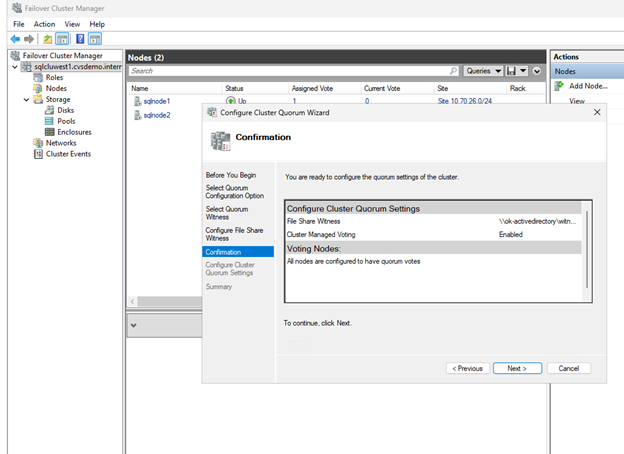
ファイル共有監視を使用してクラスタ クォーラムを設定する
2ノードクラスタ構成でクォーラムを維持するためにファイル共有監視を設定します。監視は、スプリット ブレイン シナリオを防ぎ、クラスタの可用性を確保するために追加の投票を提供します。
ファイル共有の作成
ネットワーク接続があり、同じ Active Directory ドメイン内にある別のゾーンまたはリージョンの VM にファイル共有を作成します。
-
ファイル共有監視サーバー VM に接続します。
-
サーバー マネージャーで、ツール > コンピューターの管理 を選択します。
-
*共有フォルダー*を選択し、*共有*を右クリックして、*新しい共有*を選択します。
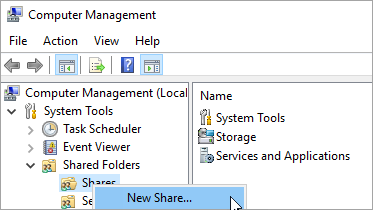
-
*共有フォルダの作成ウィザード*を使用して共有を作成します
\\servername\share。 -
フォルダー パス ページで、参照 を選択します。
-
共有フォルダーのパスを見つけるか作成し、次へ を選択します。
-
*名前、概要、および設定*ページで、共有名とパスを確認し、*次へ*を選択します。
-
*共有フォルダの権限*ページで、*権限のカスタマイズ*を選択し、*カスタム*をクリックします。
-
[権限のカスタマイズ]ダイアログで[追加]を選択してクラスタアカウントを追加します。
クラスタの作成に使用されるアカウント(sqlcluwest1$)にフル コントロール権限があることを確認します。
-
権限を保存するには、OK をクリックします。
-
*共有フォルダーのアクセス許可*ページで、*完了*を選択し、もう一度*完了*を選択します。
クォーラム設定を構成する
クォーラム投票にファイル共有監視を使用するようにクラスタを構成します。
-
フェイルオーバー クラスタ マネージャで、クラスタを右クリックし、[その他のアクション] > [クラスタ クォーラム設定の構成] を選択します。
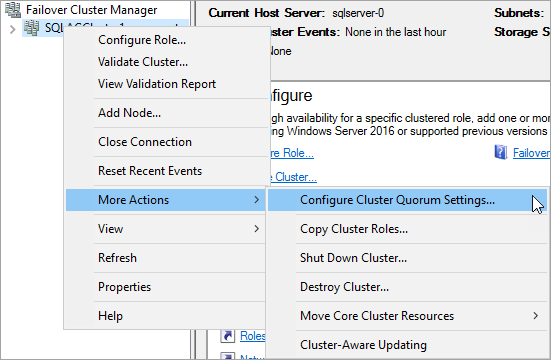
-
クラスター クォーラムの構成ウィザードで、次へ をクリックします。
-
*Select Quorum Configuration*ページで、*Select the quorum witness*を選択し、*Next*をクリックします。
-
*クォーラム監視の選択*ページで、*ファイル共有監視の構成*を選択します。
-
*ファイル共有監視の構成*ページで、*ファイル共有監視の構成*を選択します。
-
作成した共有へのパスを入力し(例:
\\servername\share)、*次へ*をクリックします。 -
確認ページで設定を確認し、*次へ*をクリックします。
-
*完了*をクリックします。
クラスター コア リソースは、ファイル共有監視を使用して構成されました。
Always On 可用性グループを有効にする
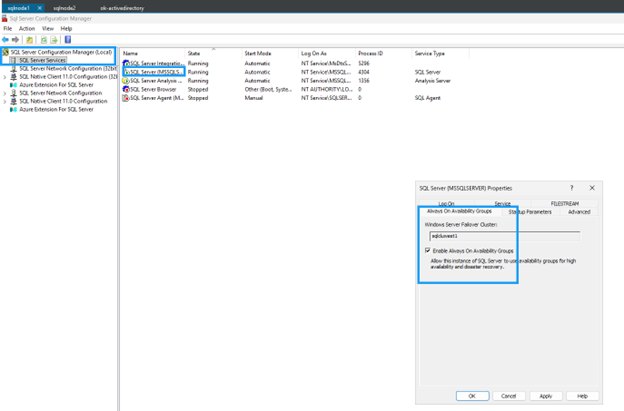
両方の SQL Server VM で Always On 可用性グループを有効にします:
-
スタートメニューから*SQL Server Configuration Manager*を開きます。
-
ブラウザ ツリーで、SQL Server Services を選択します。
-
SQL Server (MSSQLSERVER) を右クリックし、プロパティ を選択します。
-
Always On High Availability タブを選択します。
-
*Always On 可用性グループを有効にする*をチェックします。
-
*適用*をクリックし、プロンプトが表示されたらSQL Serverサービスを再起動します。
-
2番目のSQL Serverインスタンスに対しても繰り返します。
最初の SQL Server インスタンスにデータベースを作成する
最初の SQL Server インスタンスにデータベースを作成します。
-
sysadmin 固定サーバー ロールのメンバーであるドメイン アカウントを使用して、最初の SQL Server VM に接続します。
-
SQL Server Management Studio を開き、最初の SQL Server インスタンスに接続します。
-
オブジェクト エクスプローラー で、データベース を右クリックし、新しいデータベース を選択します。
-
データベース名を入力し(例:
MyDB1)、OK をクリックします。 -
データベース リカバリ モードをフルに設定:
ALTER DATABASE MyDB1 SET RECOVERY FULL; GO
可用性グループの作成と設定
同期コミットと自動フェールオーバーを備えた Always On 可用性グループを作成して、SQL Server データベースに高可用性を提供します。
-
データベースのフル バックアップとトランザクション ログ バックアップの両方を作成します。
-- Full backup BACKUP DATABASE MyDB1 TO DISK = 'F:\MSSQL\Backup\MyDB1_Full.bak' WITH INIT, COMPRESSION; -- Transaction log backup BACKUP LOG MyDB1 TO DISK = 'F:\MSSQL\Backup\MyDB1_Log.trn' WITH INIT, COMPRESSION; -
バックアップ ファイルを 2 番目の SQL Server インスタンスにコピーし、NORECOVERY を使用して復元します。
-- Restore full backup RESTORE DATABASE MyDB1 FROM DISK = 'F:\MSSQL\Backup\MyDB1_Full.bak' WITH NORECOVERY; -- Restore log backup RESTORE LOG MyDB1 FROM DISK = 'F:\MSSQL\Backup\MyDB1_Log.trn' WITH NORECOVERY; -
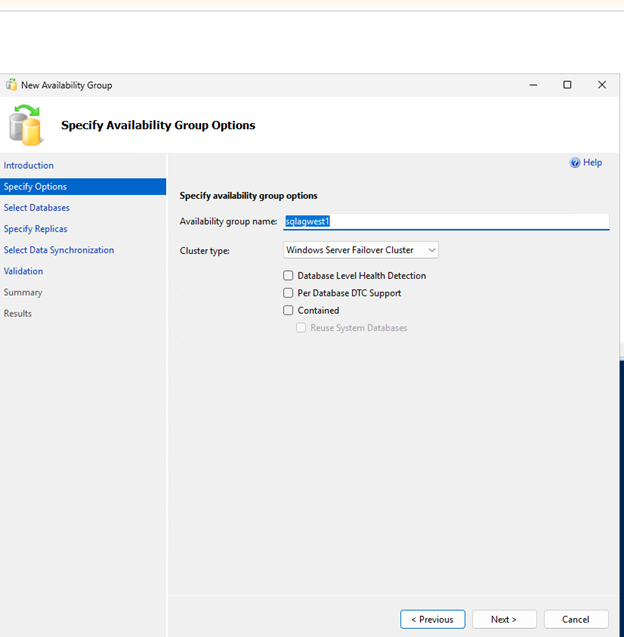
同期コミット、自動フェイルオーバー、読み取り可能なセカンダリ レプリカを備えた可用性グループを作成します:
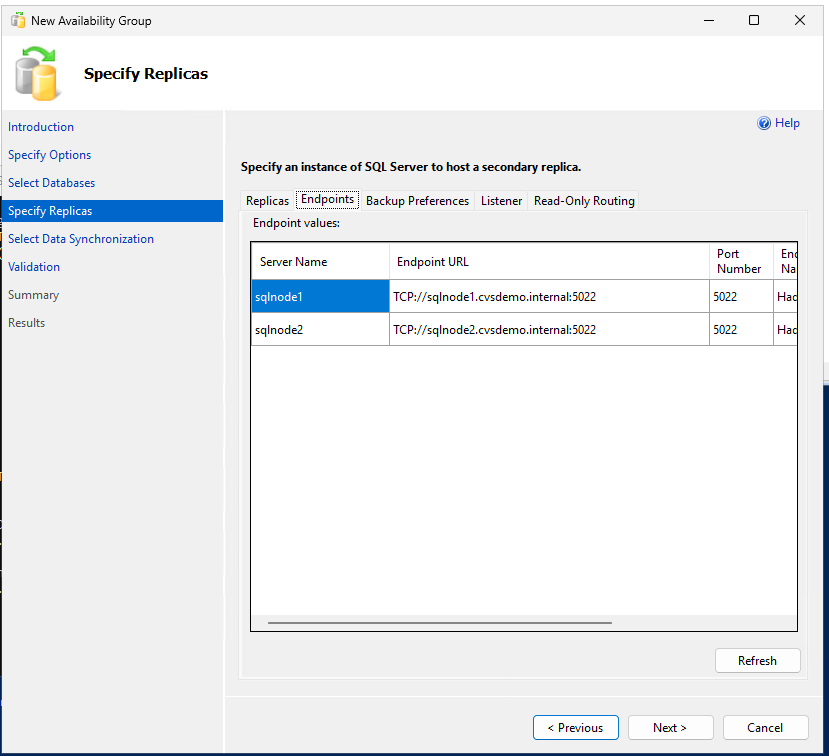
-- Run on primary replica CREATE AVAILABILITY GROUP sqlagwest1 WITH (AUTOMATED_BACKUP_PREFERENCE = SECONDARY) FOR DATABASE MyDB1 REPLICA ON N'SQLNODE1' WITH ( ENDPOINT_URL = N'TCP://sqlnode1.cvsdemo.internal:5022', AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, FAILOVER_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = YES) ), N'SQLNODE2' WITH ( ENDPOINT_URL = N'TCP://sqlnode2.cvsdemo.internal:5022', AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, FAILOVER_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = YES) ); GO -
Availability Group Wizardを使用して可用性グループを作成します。
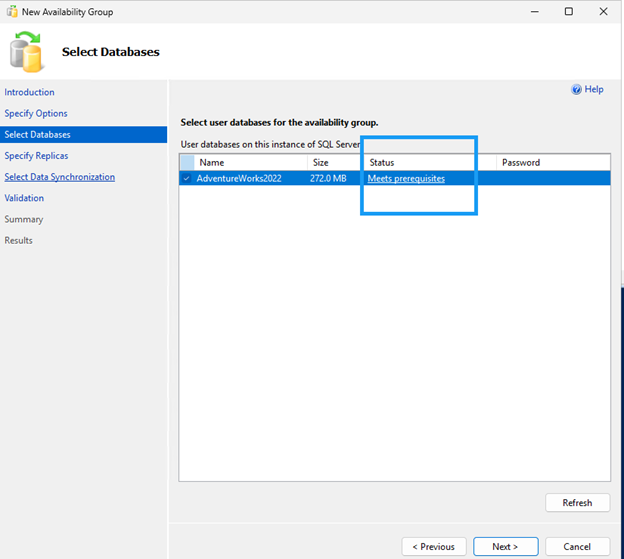

両方の SQL ノードでファイアウォール ポート 5022 が許可されていることを確認します。 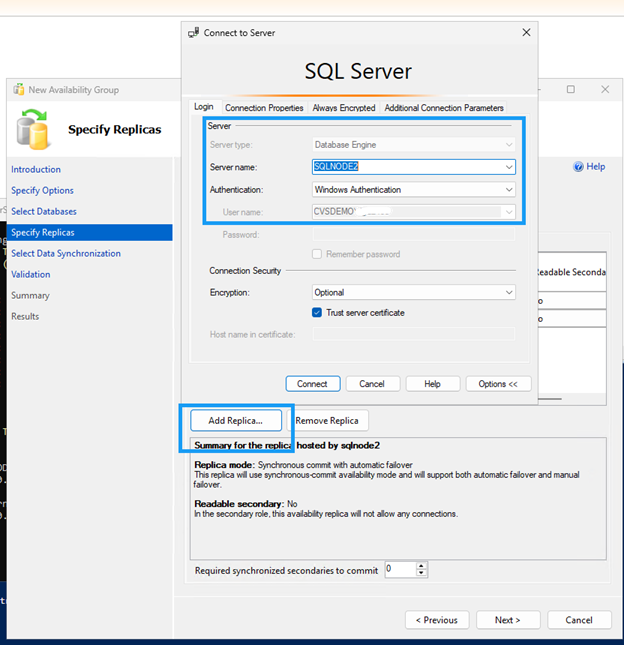
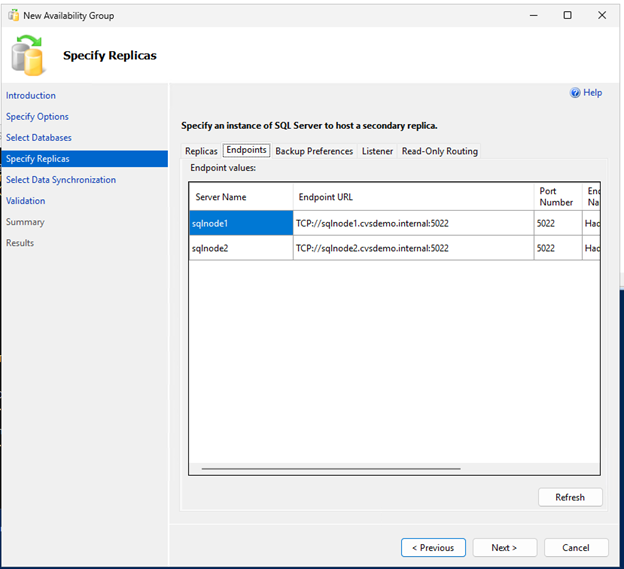
DNN リスナー リソースを作成する
ロード バランサーを必要とせずにトラフィックを適切なクラスター化されたリソースにルーティングするための分散ネットワーク名(DNN)リスナーを作成します。
PowerShellを使用してDNNリソースを作成します。
$Ag = "sqlagwest1"
$Dns = "AOAGDNN"
$Port = "1433"
# Add DNN resource
Add-ClusterResource -Name $Dns -ResourceType "Distributed Network Name" -Group $Ag
# Set DNN properties
Get-ClusterResource -Name $Dns | Set-ClusterParameter -Name DnsName -Value $Dns
Get-ClusterResource -Name $Dns | Set-ClusterParameter -Name Port -Value $Port
# Start DNN resource
Start-ClusterResource -Name $Dns
# Add dependency
$AagResource = Get-ClusterResource | Where-Object {$_.ResourceType -eq "SQL Server Availability Group" -and $_.OwnerGroup -eq $Ag}
Set-ClusterResourceDependency -Resource $AagResource -Dependency "[$Dns]"可能な所有者を設定する
デフォルトでは、クラスタは DNN DNS 名をすべてのノードにバインドします。可用性グループに参加していないノードを除外します:
-
フェイルオーバー クラスタ マネージャで、DNN リソースを見つけます。
-
DNN リソースを右クリックし、* プロパティ * を選択します。
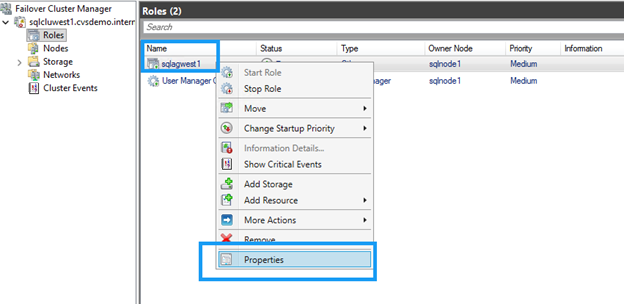
-
可用性グループに参加していないノードのチェックボックスをオフにします。
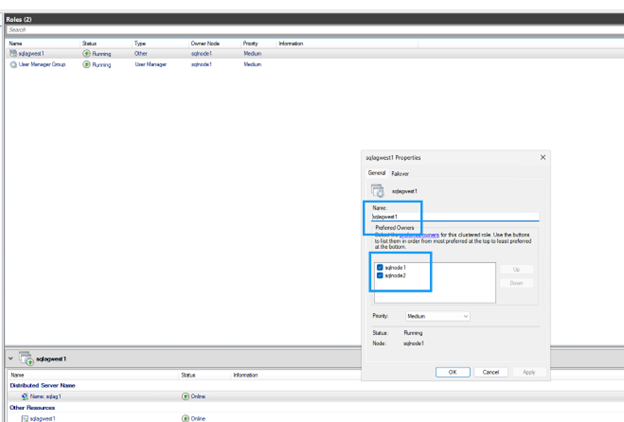
-
設定を保存するには、*OK*をクリックします。
アプリケーション接続文字列を更新する
DNNリスナー名を使用するように接続文字列を更新し、 `MultiSubnetFailover=True`パラメータを含めます:
Server=AOAGDNN,1433;Database=MyDB1;MultiSubnetFailover=True;
|
|
クライアントが MultiSubnetFailover パラメータをサポートしていない場合、DNN と互換性がありません。 |
テスト フェイルオーバー
可用性グループの構成を確認し、フェイルオーバーをテストして、ノード間で自動フェイルオーバーが正しく機能することを確認します。
-
可用性グループの構成を確認するには、任意のレプリカで次のコマンドを実行します。
両方のレプリカには、可用性モードに
SYNCHRONOUS_COMMIT、フェイルオーバー モードに `AUTOMATIC`が表示されます。これにより、自動フェイルオーバー中にデータ損失がゼロになることが保証されます。SELECT ag.name AS AG_Name, ars.primary_replica FROM sys.dm_hadr_availability_group_states AS ars JOIN sys.availability_groups AS ag ON ag.group_id = ars.group_id; -- Check replica configuration SELECT replica_server_name, availability_mode_desc, failover_mode_desc FROM sys.availability_replicas WHERE group_id = (SELECT group_id FROM sys.availability_groups WHERE name = N'sqlagwest1');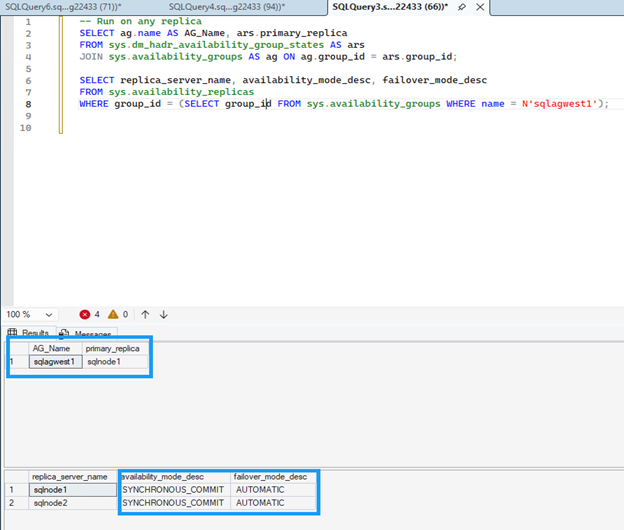
-
フェイルオーバーを開始するには、セカンダリ ノードで次のコマンドを実行します:
ALTER AVAILABILITY GROUP sqlagwest1 FAILOVER; GO -
接続ターゲットが新しいプライマリに切り替わったことを確認します:
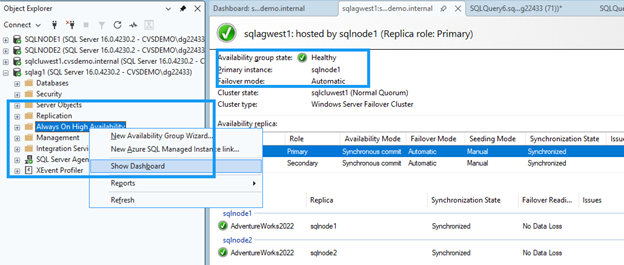
-- SELECT @@SERVERNAME AS NowPrimary;SSMS で、可用性グループ ノードを展開し、Always On High Availability を右クリックして、ダッシュボードの表示 を選択します。
ダッシュボードには、両方のノードが正常な状態であることが表示され、フェイルオーバー モードが確認されます。
リソースをクリーンアップする
チュートリアルを完了したら、追加料金が発生しないように、作成したリソースを削除します。
-
Compute Engine インスタンス(sqlnode1、sqlnode2)を削除します
-
Google Cloud NetApp Volumes を削除(ボリューム、ストレージ プール、ホスト グループ)
-
このチュートリアル専用に作成された VPC とネットワーク リソースを削除します
-
該当する場合はファイル共有監視サーバーを削除します
"Google Cloud NetApp Volumes のドキュメント"および"Google Compute Engine ドキュメント"を参照して、リソースを削除する詳細な手順を確認してください。
詳細情報の入手方法
Google Cloud上のNetAppストレージを使用したSQL Serverの詳細については、次のドキュメントを確認してください: