
NetAppおよびMLflowによるデータセットからモデルへのトレーサビリティ
 変更を提案
変更を提案
は、 "Kubernetes向けNetApp DataOpsツールキット"コードからデータセット、データセットからモデル、またはワークスペースからモデルへのトレーサビリティを実装するために、MLflowの実験追跡機能と組み合わせて使用できます。
サンプルノートブックでは、次のライブラリが使用されています。
前提条件
code-dataset-modelまたはworkspace-to-modelトレーサビリティを実装するには、次のコード例に示すように、DataOps Toolkitをトレーニングの一部として使用して、データセットまたはワークスペースボリュームのスナップショットを作成します。このコードは、データボリューム名とスナップショット名を、MLflow実験追跡サーバーにロギングする特定のトレーニング実行に関連付けられたタグとして保存します。
...
from netapp_dataops.k8s import cloneJupyterLab, createJupyterLab, deleteJupyterLab, \
listJupyterLabs, createJupyterLabSnapshot, listJupyterLabSnapshots, restoreJupyterLabSnapshot, \
cloneVolume, createVolume, deleteVolume, listVolumes, createVolumeSnapshot, \
deleteVolumeSnapshot, listVolumeSnapshots, restoreVolumeSnapshot
mlflow.set_tracking_uri("<your_tracking_server_uri>>:<port>>")
os.environ['MLFLOW_HTTP_REQUEST_TIMEOUT'] = '500' # Increase to 500 seconds
mlflow.set_experiment(experiment_id)
with mlflow.start_run() as run:
latest_run_id = run.info.run_id
start_time = datetime.now()
# Preprocess the data
preprocess(input_pdf_file_path, to_be_cleaned_input_file_path)
# Print out sensitive data (passwords, SECRET_TOKEN, API_KEY found)
check_pretrain(to_be_cleaned_input_file_path)
# Tokenize the input file
pretrain_tokenization(to_be_cleaned_input_file_path, model_name, tokenized_output_file_path)
# Load the tokenizer and model
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
# Set the pad token
tokenizer.pad_token = tokenizer.eos_token
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
# Encode, generate, and decode the text
with open(tokenized_output_file_path, 'r', encoding='utf-8') as file:
content = file.read()
encode_generate_decode(content, decoded_output_file_path, tokenizer=tokenizer, model=model)
# Save the model
model.save_pretrained(model_save_path)
tokenizer.save_pretrained(model_save_path)
# Finetuning here
with open(decoded_output_file_path, 'r', encoding='utf-8') as file:
content = file.read()
model.finetune(content, tokenizer=tokenizer, model=model)
# Evaluate the model using NLTK
output_set = Dataset.from_dict({"text": [content]})
test_set = Dataset.from_dict({"text": [content]})
scores = nltk_evaluation_gpt(output_set, test_set, model=model, tokenizer=tokenizer)
print(f"Scores: {scores}")
# End time and elapsed time
end_time = datetime.now()
elapsed_time = end_time - start_time
elapsed_minutes = elapsed_time.total_seconds() // 60
elapsed_seconds = elapsed_time.total_seconds() % 60
# Create DOTK snapshots for code, dataset, and model
snapshot = createVolumeSnapshot(pvcName="model-pvc", namespace="default", printOutput=True)
#Log snapshot IDs to MLflow
mlflow.log_param("code_snapshot_id", snapshot)
mlflow.log_param("dataset_snapshot_id", snapshot)
mlflow.log_param("model_snapshot_id", snapshot)
# Log parameters and metrics to MLflow
mlflow.log_param("wf_start_time", start_time)
mlflow.log_param("wf_end_time", end_time)
mlflow.log_param("wf_elapsed_time_minutes", elapsed_minutes)
mlflow.log_param("wf_elapsed_time_seconds", elapsed_seconds)
mlflow.log_artifact(decoded_output_file_path.rsplit('/', 1)[0]) # Remove the filename to log the directory
mlflow.log_artifact(model_save_path) # log the model save path
print(f"Experiment ID: {experiment_id}")
print(f"Run ID: {latest_run_id}")
print(f"Elapsed time: {elapsed_minutes} minutes and {elapsed_seconds} seconds")上記のコードスニペットは、スナップショットIDをMLflow実験追跡サーバーに記録します。このサーバーは、モデルのトレーニングに使用された特定のデータセットとモデルをトレースするために使用できます。これにより、モデルのトレーニングに使用された特定のデータセットとモデル、データの前処理、入力ファイルのトークン化、トークナイザーとモデルのロード、テキストのエンコード、生成、デコード、モデルの保存、モデルの微調整、"NLTK"パープレキシティースコアを使用したモデルの評価、およびハイパーパラメータとメトリクスのMLflowへの記録が可能になります。たとえば、次の図は、さまざまな実験の実行に対するスキキット学習モデルの平均二乗誤差(MSE)を示しています。

データ分析、基幹業務の責任者、経営陣は、特定の制約、設定、期間、その他の状況下でどのモデルが最も優れているかを理解し、推測するのは簡単です。モデルの前処理、トークン化、読み込み、エンコード、生成、デコード、保存、微調整、評価の方法の詳細については、 dotk-mlflow `netapp_dataops.k8s`リポジトリ内のパッケージ化されたPythonの例を参照してください。
データセットまたはJupyterLabワークスペースのスナップショットを作成する方法の詳細については、を参照してください"NetApp DataOps Toolkitページ"。
トレーニングを受けたモデルについては、次のモデルがdotk-mlflowノートブックで使用されました。
モデル
-
"GPT2LMHeadModel":言語モデリングヘッドを上にしたGPT2モデルトランス(入力埋め込みにウェイトを結び付けたリニアレイヤ)。これは、テキストデータの大規模なコーパスで事前にトレーニングされ、特定のデータセットで微調整されたトランスフォーマーモデルです。デフォルトのGPT2モデルを使用して"注意マスク"、選択したモデルに対応するトークナイザーで入力シーケンスをバッチ処理しました。
-
"PHI-2": Phi-2は27億個のパラメータを持つ変圧器です。Phi-1.5と同じデータソースを使用してトレーニングされ、さまざまなNLP合成テキストとフィルタリングされたWebサイトで構成される新しいデータソースが追加されました(安全性と教育的価値のため)。
-
"XLNet(ベースサイズモデル)":英語で事前トレーニングされたXLNetモデル。"XLNet:言語理解のための一般化された自動回帰事前トレーニング"Yang et al.の論文で紹介され、これで最初にリリースされ"リポジトリ"ました。
結果に"MLflowのモデルレジストリ"は、次のランダムフォレストモデル、バージョン、およびタグが含まれます。
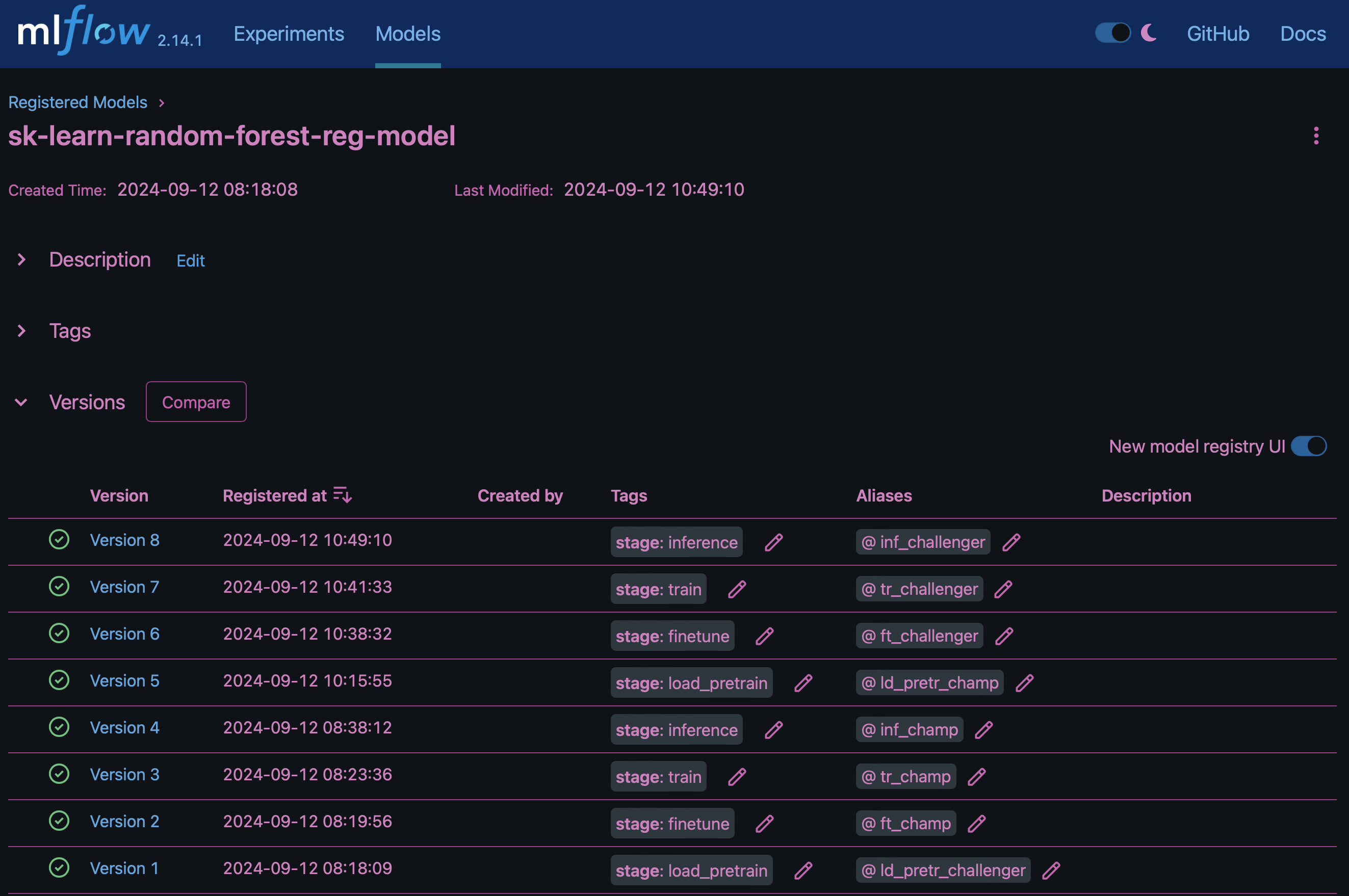
Kubernetes経由で推論サーバにモデルを導入するには、次のJupyter Notebookを実行します。この例では、 `dotk-mlflow`パッケージを使用する代わりに、最初のモデルの平均二乗誤差(MSE)を最小化するようにランダムフォレスト回帰モデルアーキテクチャを変更していることに注意してください。したがって、このようなモデルの複数のバージョンをModel Registryで作成します。
from mlflow.models import Model
mlflow.set_tracking_uri("http://<tracking_server_URI_with_port>")
experiment_id='<your_specified_exp_id>'
# Alternatively, you can load the Model object from a local MLmodel file
# model1 = Model.load("~/path/to/my/MLmodel")
from sklearn.datasets import make_regression
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
import mlflow
import mlflow.sklearn
from mlflow.models import infer_signature
# Create a new experiment and get its ID
experiment_id = mlflow.create_experiment(experiment_id)
# Or fetch the ID of the existing experiment
# experiment_id = mlflow.get_experiment_by_name("<your_specified_exp_id>").experiment_id
with mlflow.start_run(experiment_id=experiment_id) as run:
X, y = make_regression(n_features=4, n_informative=2, random_state=0, shuffle=False)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
params = {"max_depth": 2, "random_state": 42}
model = RandomForestRegressor(**params)
model.fit(X_train, y_train)
# Infer the model signature
y_pred = model.predict(X_test)
signature = infer_signature(X_test, y_pred)
# Log parameters and metrics using the MLflow APIs
mlflow.log_params(params)
mlflow.log_metrics({"mse": mean_squared_error(y_test, y_pred)})
# Log the sklearn model and register as version 1
mlflow.sklearn.log_model(
sk_model=model,
artifact_path="sklearn-model",
signature=signature,
registered_model_name="sk-learn-random-forest-reg-model",
)Jupyter Notebookセルの実行結果は次のようになります。モデルはバージョンとしてモデル `3`レジストリに登録されます。
Registered model 'sk-learn-random-forest-reg-model' already exists. Creating a new version of this model... 2024/09/12 15:23:36 INFO mlflow.store.model_registry.abstract_store: Waiting up to 300 seconds for model version to finish creation. Model name: sk-learn-random-forest-reg-model, version 3 Created version '3' of model 'sk-learn-random-forest-reg-model'.
Model Registryでは、必要なモデル、バージョン、タグを保存した後、モデルのトレーニングに使用された特定のデータセット、モデル、コード、およびデータの処理、トークナイザーとモデルのロード、テキストのエンコード、生成、デコード、モデルの保存、モデルの微調整、NLTK Perplexity Scoreログまたはその他の適切なメトリクスを使用してモデルを評価すること `snapshot_id's and your chosen metrics to MLflow by choosing the corerct experiment under `mlrun`ができます。
同様に phi-2_finetuned_model、 `torch`ライブラリを使用してGPUまたはvGPUを使用して量子化された重みを計算したの場合、次の中間アーティファクトを検査できます。これにより、ワークフロー全体のパフォーマンス最適化、拡張性(スループット/ SLA保証)、コスト削減が可能になります。
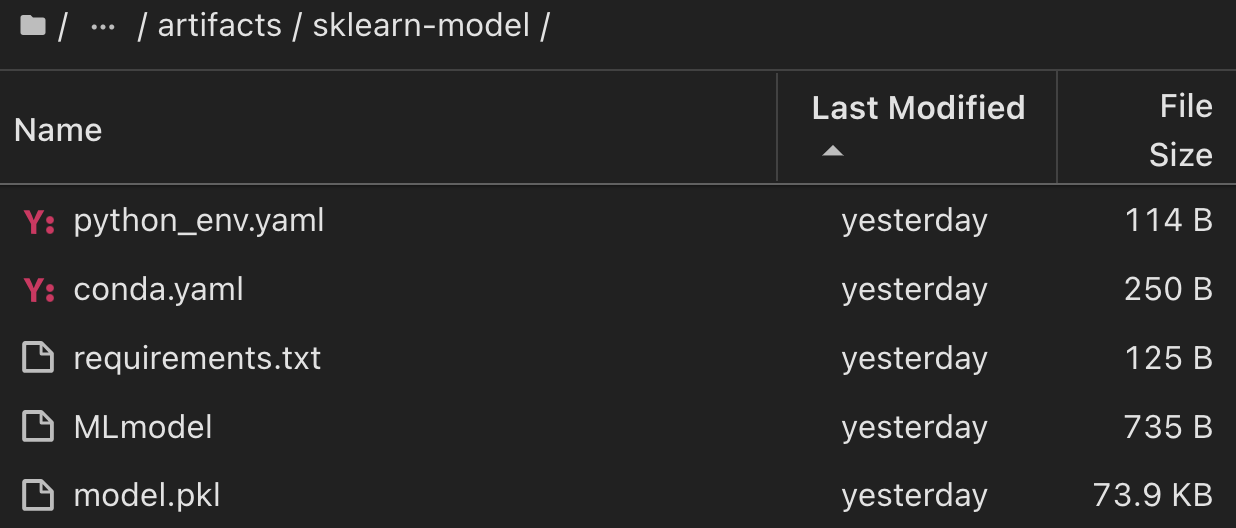
Scikit-LearnとMLflowを使用して1回の実験を実行する場合、次の図は生成されたアーティファクト、 `conda`環境、 `MLmodel`ファイル、 `MLmodel`およびディレクトリを示しています。
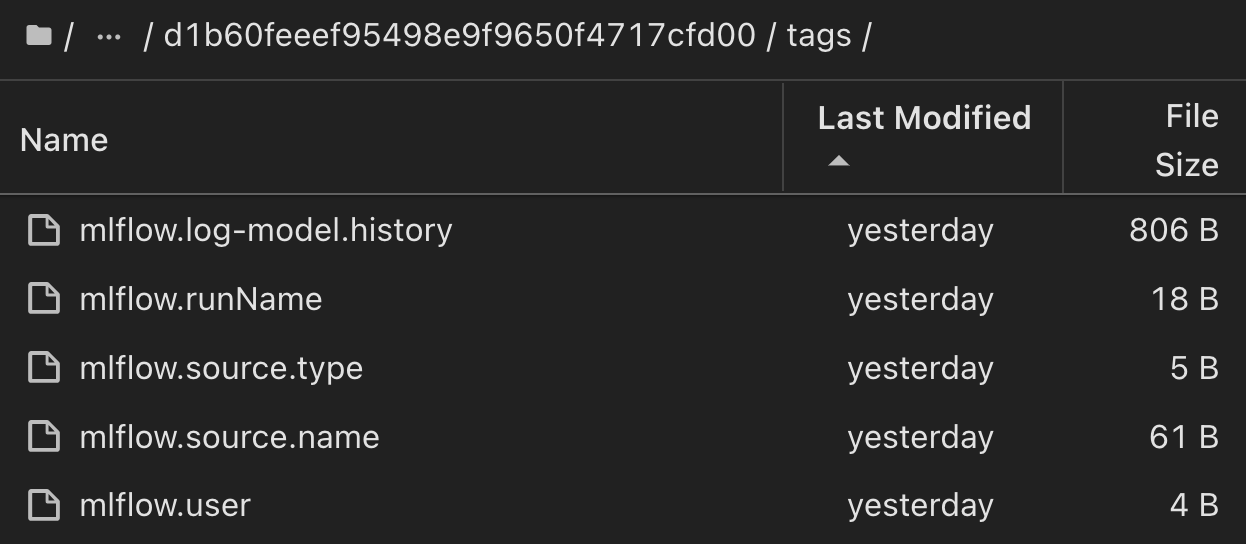
お客様は、「デフォルト」、「ステージ」、「プロセス」、「ボトルネック」などのタグを指定して、AIワークフローのさまざまな特性を整理したり、最新の結果を記録したり、 contributors`データサイエンスチームの開発者の進捗状況を追跡したりすることができます。デフォルトタグ""の場合、 `mlflow.log-model.history mlflow.runName mlflow.source.type mlflow.source.name `mlflow.user`JupyterHubの現在アクティブなファイルナビゲータタブの下に、、、、およびが保存されている場合は、次の手順を実行します。
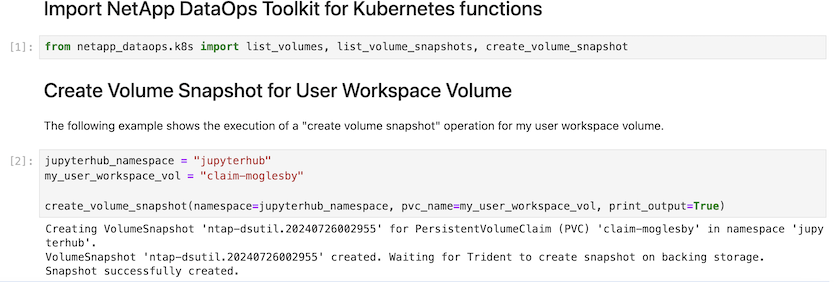
最後に、ユーザは独自に指定されたJupyter Workspaceを使用できます。このワークスペースはバージョン管理され、Kubernetesクラスタ内の永続ボリューム要求(PVC)に格納されます。次の図は、 `netapp_dataops.k8s`Pythonパッケージを含むJupyterワークスペースと、正常に作成されたの結果を示してい `VolumeSnapshot`ます。
業界で実績のあるネットアップのSnapshot®やその他のテクノロジを使用して、エンタープライズレベルのデータ保護、移動、効率的な圧縮を実現しました。その他のAIのユースケースについては、の"NetApp AIPod"ドキュメントを参照してください。