

I/Oモジュールの交換- FAS9000
 変更を提案
変更を提案
I/O モジュールを交換するには、特定の順序でタスクを実行する必要があります。
-
この手順は、システムでサポートされるすべてのバージョンの ONTAP で使用できます
-
システムのその他のコンポーネントがすべて正常に動作している必要があります。問題がある場合は、必ずテクニカルサポートにお問い合わせください。
手順 1 :障害のあるコントローラをシャットダウンします
ストレージシステムのハードウェア構成に応じた手順を使用して、障害のあるコントローラをシャットダウンまたはテイクオーバーできます。
障害のあるコントローラーを引き継いで停止し、正常なコントローラーが障害のあるコントローラーのストレージからデータを引き続き提供できるようにします。これを行うには、AutoSupportで自動ケース作成を抑制し、自動ギブバックを無効にして、障害のあるコントローラをLOADERプロンプトに切り替えます。LOADERプロンプトは、FRUを交換できる安全な停止状態です。
-
SANシステムを使用している場合は、障害コントローラのSCSIブレードのイベントメッセージを確認しておく必要があり `cluster kernel-service show`ます)。コマンド(priv advancedモードから)を実行すると、 `cluster kernel-service show`そのノードのノード名、そのノードの可用性ステータス、およびそのノードの動作ステータスが表示され"クォーラムステータス"ます。
各 SCSI ブレードプロセスは、クラスタ内の他のノードとクォーラムを構成している必要があります。交換を進める前に、すべての問題を解決しておく必要があります。
-
ノードが 3 つ以上あるクラスタは、クォーラムを構成している必要があります。クラスタがクォーラムを構成していない場合、または正常なコントローラで適格性と正常性についてfalseと表示される場合は、障害のあるコントローラをシャットダウンする前に問題 を修正する必要があります。を参照してください "ノードをクラスタと同期します"。
-
AutoSupportが有効になっている場合は、AutoSupportメッセージを呼び出してケースの自動作成を停止します。
system node autosupport invoke -node * -type all -message MAINT=<number of hours down>hこれにより、計画メンテナンス期間中に自動的にサポートケースが開かれるのを防ぎます。最大抑制時間は72時間です。メンテナンスが予定より早く完了した場合は、AutoSupportメッセージを `MAINT=END`で呼び出すことでケース作成を再度有効にできます。詳細については、 "How to suppress automatic case creation during scheduled maintenance windows"を参照してください。
次のAutoSupport メッセージは、ケースの自動作成を2時間停止します。
cluster1:> system node autosupport invoke -node * -type all -message MAINT=2h -
自動ギブバックを無効にする:
-
正常なコントローラのコンソールから次のコマンドを入力します。
storage failover modify -node impaired_node_name -auto-giveback false -
入力
y「自動ギブバックを無効にしますか?」というプロンプトが表示されたら、
-
-
障害のあるコントローラに LOADER プロンプトを表示します。
障害のあるコントローラの表示 作業 LOADER プロンプト
次の手順に進みます。
ギブバックを待っています
Ctrl キーを押しながら C キーを押し ' プロンプトが表示されたら y と入力します
システムプロンプトまたはパスワードプロンプト
正常なコントローラから障害コントローラをテイクオーバーまたは停止します。
storage failover takeover -ofnode impaired_node_name -halt true_-halt true _パラメータを指定すると、Loaderプロンプトが表示されます。
障害のあるコントローラをシャットダウンするには、コントローラのステータスを確認し、必要に応じて正常なコントローラが障害のあるコントローラストレージからデータを引き続き提供できるようにコントローラをスイッチオーバーする必要があります。
-
正常なコントローラに電力を供給するために、この手順 の最後で電源装置をオンのままにしておく必要があります。
-
MetroCluster ステータスをチェックして、障害のあるコントローラが正常なコントローラに自動的にスイッチオーバーしたかどうかを確認します。「 MetroCluster show 」
-
自動スイッチオーバーが発生したかどうかに応じて、次の表に従って処理を進めます。
障害のあるコントローラの状況 作業 自動的にスイッチオーバーした
次の手順に進みます。
自動的にスイッチオーバーしていない
正常なコントローラから計画的なスイッチオーバー操作を実行します : MetroCluster switchover
スイッチオーバーは自動的には行われておらず、 MetroCluster switchover コマンドを使用してスイッチオーバーを試みたが、スイッチオーバーは拒否された
拒否メッセージを確認し、可能であれば問題を解決してやり直します。問題を解決できない場合は、テクニカルサポートにお問い合わせください。
-
サバイバークラスタから MetroCluster heal-phase aggregates コマンドを実行して、データアグリゲートを再同期します。
controller_A_1::> metrocluster heal -phase aggregates [Job 130] Job succeeded: Heal Aggregates is successful.
修復が拒否された場合は '-override-vetoes パラメータを指定して MetroCluster heal コマンドを再実行できますこのオプションパラメータを使用すると、修復処理を妨げるソフトな拒否はすべて無視されます。
-
MetroCluster operation show コマンドを使用して、処理が完了したことを確認します。
controller_A_1::> metrocluster operation show Operation: heal-aggregates State: successful Start Time: 7/25/2016 18:45:55 End Time: 7/25/2016 18:45:56 Errors: - -
「 storage aggregate show 」コマンドを使用して、アグリゲートの状態を確認します。
controller_A_1::> storage aggregate show Aggregate Size Available Used% State #Vols Nodes RAID Status --------- -------- --------- ----- ------- ------ ---------------- ------------ ... aggr_b2 227.1GB 227.1GB 0% online 0 mcc1-a2 raid_dp, mirrored, normal...
-
「 MetroCluster heal-phase root-aggregates 」コマンドを使用して、ルートアグリゲートを修復します。
mcc1A::> metrocluster heal -phase root-aggregates [Job 137] Job succeeded: Heal Root Aggregates is successful
修復が拒否された場合は '-override-vetoes パラメータを指定して MetroCluster heal' コマンドを再実行できますこのオプションパラメータを使用すると、修復処理を妨げるソフトな拒否はすべて無視されます。
-
デスティネーションクラスタで「 MetroCluster operation show 」コマンドを使用して、修復処理が完了したことを確認します。
mcc1A::> metrocluster operation show Operation: heal-root-aggregates State: successful Start Time: 7/29/2016 20:54:41 End Time: 7/29/2016 20:54:42 Errors: - -
障害のあるコントローラモジュールで、電源装置の接続を解除します。
手順 2 : I/O モジュールを交換します
I/O モジュールを交換するには、シャーシ内で I/O モジュールの場所を確認し、特定の順序で手順を実行します。
-
接地対策がまだの場合は、自身で適切に実施します。
-
ターゲットの I/O モジュールに接続されているケーブルをすべて取り外します。
元の場所がわかるように、ケーブルにラベルを付けておいてください。
-
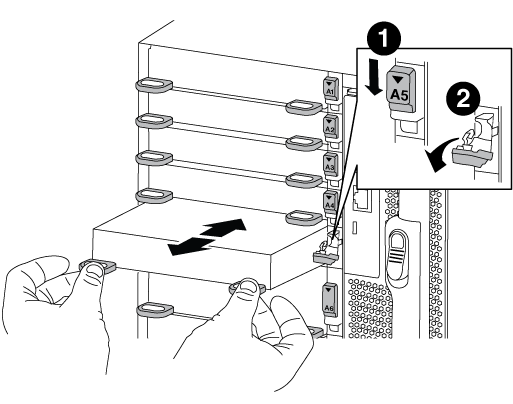
ターゲットの I/O モジュールをシャーシから取り外します。
-
文字と数字が記載されたカムボタンを押し下げます。
カムボタンがシャーシから離れます。
-
カムラッチを下に回転させて水平にします。
I/O モジュールがシャーシから外れ、 I/O スロットから約 1/2 インチアウトします。
-
I/O モジュール前面の両側にあるプルタブを引いて、 I/O モジュールをシャーシから取り外します。
I/O モジュールが取り付けられていたスロットを記録しておいてください。

文字と数字が記載された I/O カムラッチ

ロックが完全に解除された I/O カムラッチ
-
-
I/O モジュールを脇へ置きます。
-
交換用 I/O モジュールを I/O モジュールをスロットにそっと挿入し、文字と数字が記載された I/O カムラッチを上に押してモジュールを所定の位置にロックし、 I/O モジュールをシャーシに取り付けます。
-
必要に応じて、 I/O モジュールにケーブルを再接続します。
手順 3 : I/O モジュールの交換後にコントローラをリブートします
I/O モジュールを交換したら、コントローラモジュールをリブートする必要があります。

|
新しいI/Oモジュールが障害の発生したモジュールと同じモデルでない場合は、最初にBMCをリブートする必要があります。 |
-
交換用モジュールのモデルが古いモジュールと同じでない場合は、BMCをリブートします。
-
LOADERプロンプトから、advanced権限モードに切り替えます。「priv set advanced」
-
BMCを再起動します:「SP reboot
-
-
LOADERプロンプトからノードをリブートします。bye
これにより、PCIeカードおよびその他のコンポーネントが再初期化され、ノードがリブートされます。 -
システムが、 40 GbE NIC またはオンボードポート上で 10 GbE クラスタインターコネクトおよびデータ接続をサポートするように構成されている場合、メンテナンスモードから「 nicadmin convert 」コマンドを使用して、これらのポートを 10 GbE 接続に変換します。
変換が完了したら必ずメンテナンスモードを終了してください。 -
ノードを通常動作に戻します。storage failover giveback -ofnode impaired_node_name _
-
自動ギブバックを無効にした場合は、再度有効にします。「 storage failover modify -node local-auto-giveback true 」
システムが2ノードMetroCluster 構成の場合は、次の手順で説明するようにアグリゲートをスイッチバックする必要があります。
手順 4 : 2 ノード MetroCluster 構成のアグリゲートをスイッチバックする
このタスクでは、環境の 2 ノード MetroCluster 構成のみを実行します。
-
すべてのノードの状態が「 enabled 」であることを確認します。 MetroCluster node show
cluster_B::> metrocluster node show DR Configuration DR Group Cluster Node State Mirroring Mode ----- ------- -------------- -------------- --------- -------------------- 1 cluster_A controller_A_1 configured enabled heal roots completed cluster_B controller_B_1 configured enabled waiting for switchback recovery 2 entries were displayed. -
すべての SVM で再同期が完了したことを確認します。「 MetroCluster vserver show 」
-
修復処理によって実行される LIF の自動移行が正常に完了したことを確認します。 MetroCluster check lif show
-
サバイバークラスタ内の任意のノードから MetroCluster switchback コマンドを使用して、スイッチバックを実行します。
-
スイッチバック処理が完了したことを確認します MetroCluster show
クラスタの状態が waiting-for-switchback の場合は、スイッチバック処理がまだ実行中です。
cluster_B::> metrocluster show Cluster Configuration State Mode -------------------- ------------------- --------- Local: cluster_B configured switchover Remote: cluster_A configured waiting-for-switchback
クラスタが「 normal 」状態のとき、スイッチバック処理は完了しています。
cluster_B::> metrocluster show Cluster Configuration State Mode -------------------- ------------------- --------- Local: cluster_B configured normal Remote: cluster_A configured normal
スイッチバックが完了するまでに時間がかかる場合は、「 MetroCluster config-replication resync-status show 」コマンドを使用することで、進行中のベースラインのステータスを確認できます。
-
SnapMirror 構成または SnapVault 構成があれば、再確立します。
手順 5 :障害が発生したパーツをネットアップに返却する
障害が発生したパーツは、キットに付属のRMA指示書に従ってNetAppに返却してください。 "パーツの返品と交換"詳細については、ページを参照してください。