

Performance
 変更を提案
変更を提案
NetApp AFXは、パフォーマンスと拡張性を念頭に置いて設計されており、特に高い読み書きスループットを必要とするワークロード向けに特化しており、シンプルで線形的な拡張性を提供します。
ノードごとのパフォーマンス
各NetApp AFXストレージ ノードは、読み取りと書き込みに対して特定のスループット量を提供します。ノードがクラスタに追加されると、パフォーマンスが線形的に向上します。これについては、本書の「ノード パフォーマンスの線形スケーリング」のセクションで説明しています。
現在、ノードの種類は"AFX 1K"で、読み取りと書き込みのスループットは、おおよそ以下の値となります。新しいハードウェアがNetApp AFXで利用可能になると、これらの制限は変更される可能性があります。注:以下の「ベンチマーク結果」セクションに示すように、複数のクライアントが複数のファイルを読み書きすることで、最大のパフォーマンスが得られました。
ノードごとのパフォーマンス推定値
| ノード タイプ | 読み取りパフォーマンス最大 | 書き込みパフォーマンス最大 |
|---|---|---|
AFX 1K |
~35GB/s |
~10GB/s |

|
最新のパフォーマンス予測については、NetApp営業チームにお問い合わせください。 |
シェルフごとのパフォーマンス
各シェルフには、16個の100GBイーサネットポートを備えた高性能シェルフモジュールが搭載されており、RoCEv2通信を利用して、クラスタ内のコンピューティングノードとの間で高帯域幅のストレージ通信を実現します。他の物理的な資源と同様に、これらのシェルフにも達成可能な最大値があります。特にNetApp AFXは、同じディスクセットを指す複数のノードを提示することができます。以下の表は、TLCおよびQLCドライブの場合の、単一シェルフにおける推定最大読み取りおよび書き込み性能を示しています。TLCとQLCの違いに関する詳細については、"TLCとQLC"を参照してください。
シェルフごとのパフォーマンス予測
| シェルフ モジュール タイプ | 読み取りパフォーマンス最大 | 書き込みパフォーマンス最大 |
|---|---|---|
NSM 140 |
140GB/s(TLCおよびQLC) |
70GB/s TLC 35GB/s QLC |
|
|
最新のパフォーマンス予測については、NetApp営業チームにお問い合わせください。 |
パフォーマンス密度
分散型 ONTAP アーキテクチャでストレージ ノードとシェルフを分離することで、より多くのノードがより少ないシェルフにトラフィックをプッシュできるようになり、必要な容量のみで最大のパフォーマンスを得るために必要なデータセンター全体のフットプリントを削減できます。
この「パフォーマンス密度」という概念により、ストレージ管理者はストレージ環境を過剰にプロビジョニングすることなく、既存のハードウェアを最大限に活用できるようになります。
たとえば、統合ONTAPクラスタでは、各ノードに独自のディスクセットがあるため、パフォーマンスはそのノードが所有するディスクのみに向けられます。また、1つのディスクセットには1つのノードしかアクセスできないため、使用可能なディスクを必ずしも飽和状態にして最大のパフォーマンスを達成できるとは限りません。
統一 ONTAP – パフォーマンスの配分方法
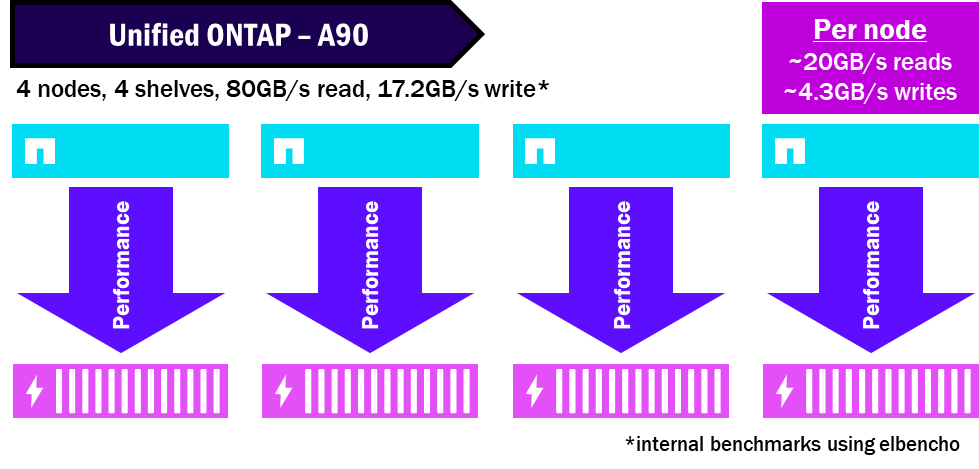
NetApp AFXはすべてのディスクを単一のストレージ可用性ゾーンに統合するため、すべてのノードがすべてのディスクを活用できます。ディスクとノードが分離されているため、同じパフォーマンスを得るために必要なシェルフの数が少なくて済みます。これによりパフォーマンスが凝縮され、シェルフの最大パフォーマンスポテンシャルが最大限に引き出されます。
NetApp AFX – パフォーマンス密度
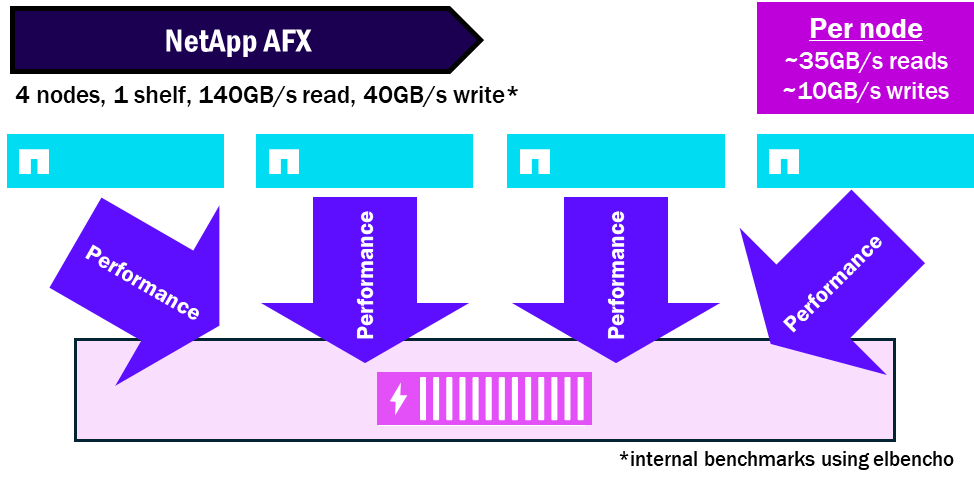
ノードとシェルフの比率
統合ONTAPノードには、ノードごとに少なくとも1セットのディスクが必要であり、1つのノードに複数のシェルフを接続することができる。その結果、単一ノードにおいてパフォーマンスのボトルネックが発生し、自身のディスクを飽和状態にできない可能性がある。
NetApp AFXは、すべてのディスクシェルフをすべてのノードに提示します。各シェルフには、16 x 100GB RoCE対応インターフェイスを備えたモジュールが搭載されており、シェルフあたりに許容される総パフォーマンス量を増加させます。このため、同じディスクセットに対して読み書きを行う複数のノードで単一のシェルフを飽和させることができます。
ONTAP 9.19.1の時点で、ノード:シェルフの飽和比は約4:1です。
ベンチマーク結果
次のセクションでは、以下の構成パラメータを持つNetApp AFXクラスタを使用したベンチマーク結果について説明します。
-
4ノード、4データインターフェイス
-
シェルフ2台(7.6TBドライブ)
-
ONTAP 9.19.1
-
NFSv4.2(pNFS、セッション トランキング)
-
FlexGroupボリューム
-
"ElBencho" ベンチマーク
-
書き込み:elbencho --hosts=x.x.x.[y-z] -d -w -b 1M -t 80 --iodepth 1 --direct -s 600g /fio_vol1/
-
読み取り:elbencho --hosts=x.x.x.[y-z] -r -b 256k -t 80 --lat --iodepth 2 --direct -s 600g --infloop /fio_vol1/
-
4台のCisco C240 M8サーバ、2ポート×200GbE CX-7カード、80スレッド
-
NFSマウントオプション:rw,vers=4.2,rsize=1048576,wsize=1048576,trunkdiscovery,proto=tcp
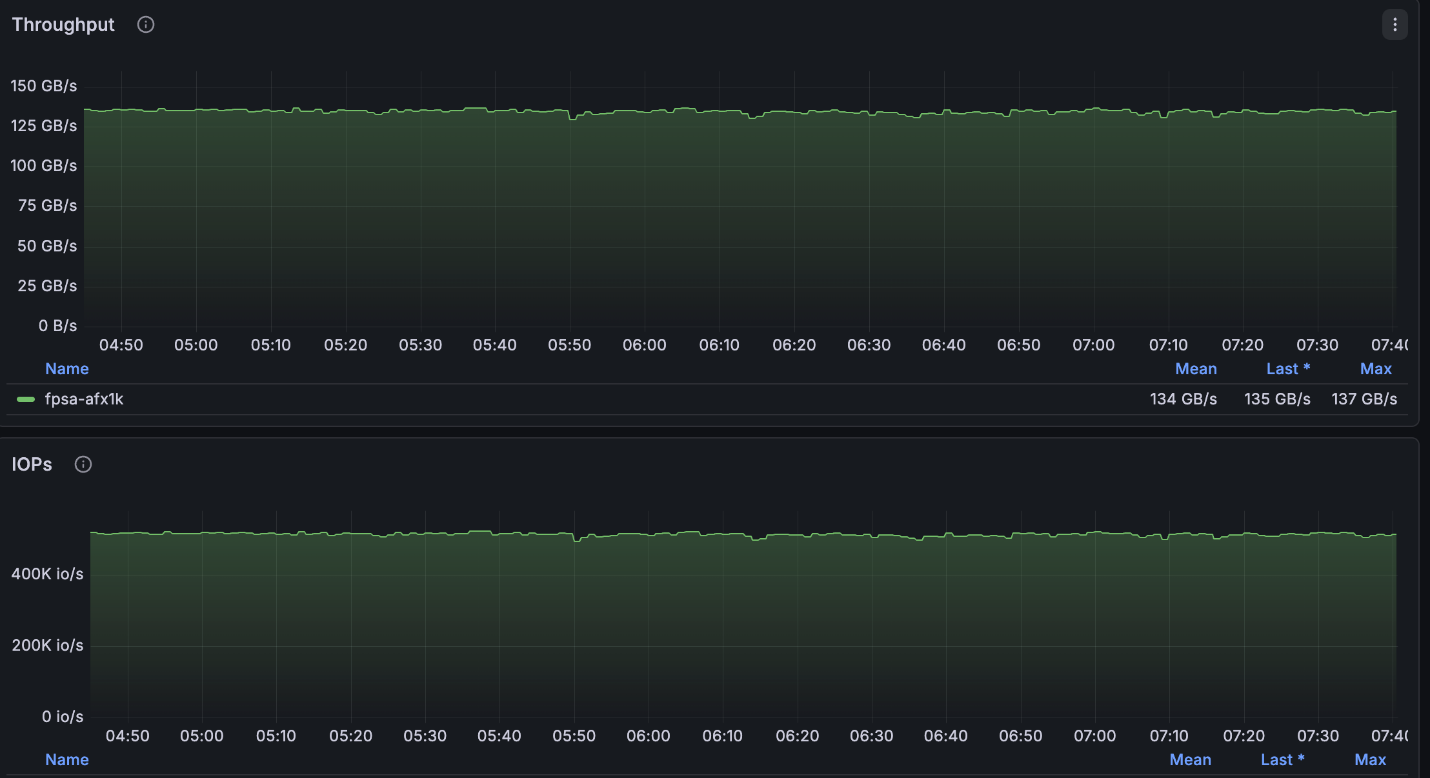
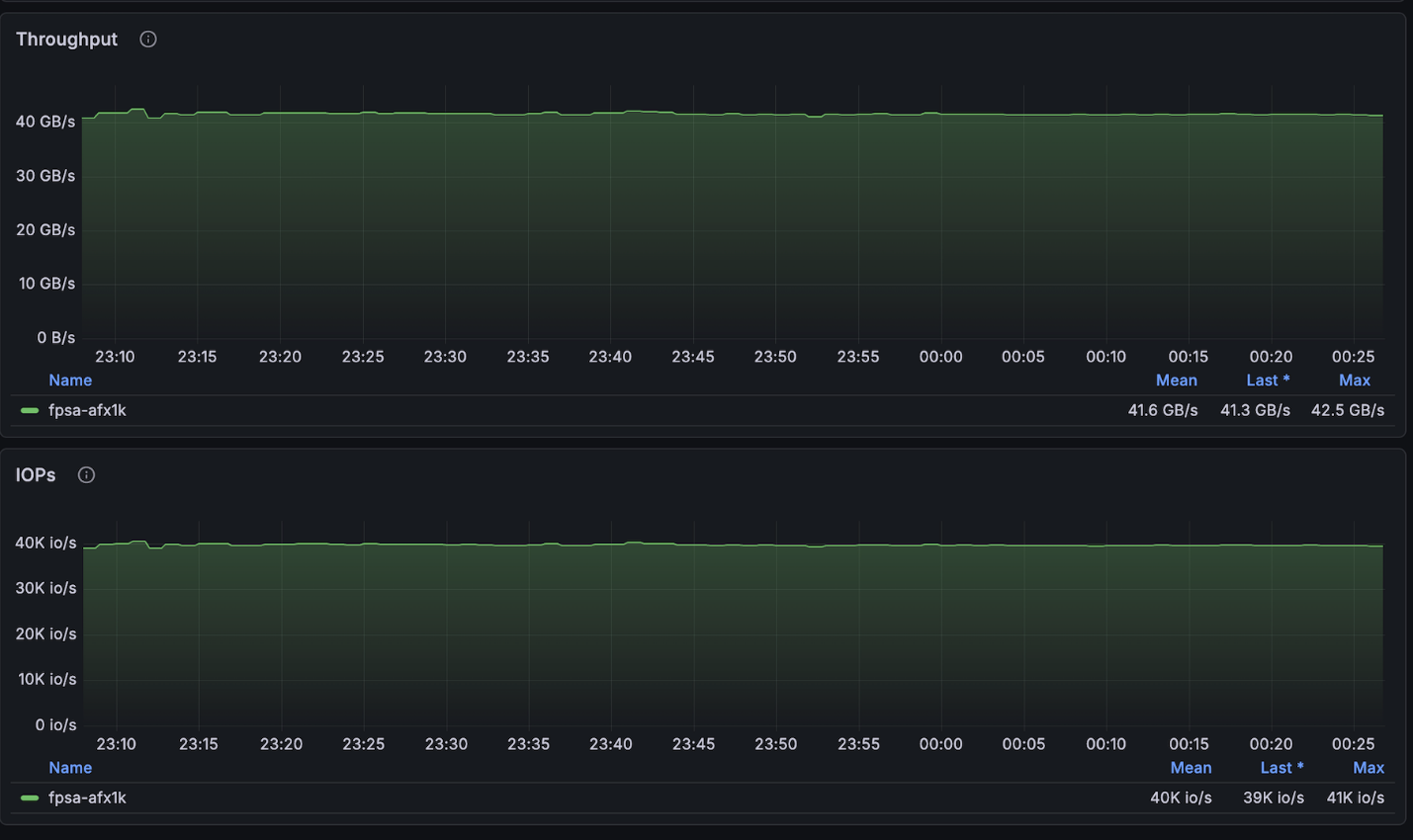
上記の構成では、4ノードクラスタで利用可能な最大読み取り速度(約134GB/秒)に非常に近い値を達成し、ノードあたりに許可されている最大書き込み速度(40GB/秒)にほぼ達しました。
NetApp AFX – ElBencho 読み取りパフォーマンス、4 ノード
NetApp AFX – ElBencho 書き込みパフォーマンス、4 ノード
積極的な先読み
メディアストリーミングのワークロードでは、4K映画はしばしば数万個のファイルに分割され、各ファイルは通常50MBから250MBのサイズになります。各ファイルはフレームを表し、アプリケーションは1回の要求でフレーム全体を読み取ります。バッファリングが目立たず、スムーズで途切れのないストリームを維持するためには、これらのフレーム読み取りはドロップなしで完了する必要があります。
ONTAPでは、これらのワークロードを最適化するためのボリュームレベルのオプション(`-aggressive-readahead-mode`を提供しています。ONTAP 9.19.1以降、類似のファイルタイプ間で予測可能なI/Oパターンを持つワークロード(メディアレンダリングやストリーミングなど)を高速化するために、AFXでアグレッシブな先読み用の新しい `cross_file_sequential_read`モードが導入されました。
cross_file_sequential_read は、ファイル名に基づいて次に読み込むファイルを予測し、クライアントが read 呼び出しを発行する前に、それらのファイルに対して先読みを開始します。予測ロジックは、ディレクトリ内のすべてのファイルが、単調増加する数値の接尾辞(例:file1、file2、file3)を持つ命名パターンに従うことを前提としています。ディレクトリ内のすべてのファイルは、10進数または16進数のいずれかを使用して、このパターンに従う必要があります。ファイル名は最大255文字までです。このロジックは拡張子に依存せず、現在のディレクトリ内の次のファイル名セットを現在のファイル名のみに基づいて生成します。以前に10進数で生成されたファイル名がディレクトリ内に存在しない場合、ファイル名は16進数で再生成されます。生成されたファイル名がどれも存在しない場合、そのセットに対してプリフェッチは実行されません。プリフェッチは、次のクライアント読み取り要求が発行されたときに再開されます。
これらのオプションを有効にすると、"frametest"パフォーマンス ベンチマークでは、30クライアント(NFSv3およびSMB3)と34クライアント(NFSv4.1)で、30フレーム/秒で30,000個の4Kフレームを、フレーム落ちすることなく読み込むことができました。
ファイル間シーケンシャル読み取りは主にメディアワークロード向けに設計されていますが、AIのトレーニングや推論など、アクセスパターンやファイル名が予測可能な、読み取り負荷の高い他のワークロードにもメリットがあります。
考慮事項と注意点
-
共有バッファキャッシュ – アグレッシブリード先読みは、ノード上の他のボリュームと同じバッファキャッシュを使用します。これを有効にすると、そのノード上の他のボリュームの読み取りパフォーマンスに影響を与える可能性があります。
-
基盤となるストレージのパフォーマンス – ファイルの読み取り速度が十分でない場合(たとえば、HDDベースのFASシステムの場合)、キャッシュされたデータがクライアントによる読み取りが行われる前に削除される可能性があり、先読みの利点が失われる場合があります。
-
アクセスパターンの要件:ワークロードの読み取りパターンがシーケンシャルでない場合、またはディレクトリ内のファイルが昇順で命名されていない場合、cross_file_sequential_read の積極的な先読みモードは、意味のあるメリットを提供しません。
NFSv4.xのパフォーマンス向上
NFSバージョン3は、1995年に初めて正式リリースされて以来、数十年にわたりNFSアプリケーションのゴールドスタンダードであり続けている。その優れた性能と堅牢性の組み合わせにより、より新しいNFSバージョンへの移行を検討することが難しいのは、それなりの理由がある。
しかし、NFSv3にも限界がないわけではない。プロトコルのステートレス性は、パフォーマンスの向上やストレージのフェイルオーバー時の障害を最小限に抑えるという点では優れているが、データの一貫性やロック管理という点では必ずしも優れているとは言えない。NFSサーバはロック状態を実際には追跡しないため、障害が発生した場合、NFSサーバはロックを解除する場合もあれば解除しない場合もあり、NFSクライアントはファイルがロックされているかどうかを認識できない場合がある。
Security for NFSv3 is also a bit lacking. The protocol requires multiple open firewall ports to function properly and numeric IDs are sent in plaintext over the wire. Furthermore, NFS does not have robust ACL support, and does not include native file and folder auditing. As a result of these limitations, NFSv4 was created in 2003 via link:https://datatracker.ietf.org/doc/html/rfc3530[RFC-3530^] (obsoleted in 2015 by link:https://datatracker.ietf.org/doc/html/rfc7530[RFC-7530^]). NFSv4.xは20年以上前から存在しているにもかかわらず、いくつかの理由からいまだに広く普及していない。
-
ID管理の複雑さ:多くの環境では、NFSv4.x の名前文字列と Kerberos セキュリティ要件を適切に活用するための名前サービスインフラストラクチャが整備されていません。
-
より新しいNFSクライアントの必要性:NFSv4の最初のリリース日から時間が経つにつれて、今日の最新のNFS環境ではこの懸念はそれほど切迫していません。現在使用されているほとんどすべてのOSには、NFSv4を完全にサポートするNFSクライアントが搭載されていますが、必要なNFSv4.xパッケージを備えていないレガシーシステムもまだ存在します。実際、一部のアプリケーションでは依然として古いNFSバージョンの使用が求められます。
-
「壊れていないなら直す必要はない」という考え方:企業のIT組織は、新しいテクノロジーの導入に関して非常に保守的であることで知られています。たとえ20年以上前から存在するテクノロジーであっても例外ではありません。現在のNFSバージョンが問題なく動作しているなら、なぜ変更する必要があるのでしょうか?
-
パフォーマンスに関する懸念:NFSv4.xのようなステートフルなプロトコルのパフォーマンスは、過去20年間、ステートレスなNFSv3に比べて遅れをとってきました。従来は、NFSv4.xの利点よりもパフォーマンスへの影響の方が大きい場合が多かった。
ONTAP 9.18.1 における AFX を使用した NFSv4.x の改善点
ONTAP のアーキテクチャ上の変更により、NFS 全般に待望のパフォーマンス向上がもたらされ、NFSv4.x のパフォーマンス全般の改善に大きく貢献しました。
以下は、これらの変更点の概要です。
シーケンシャル読み取り性能の向上:NFSv4.1はNFSv3より30%向上
ONTAP 9.18.1では、NFSv4.1によるマルチパスI/Oのサポートが導入されました。WAFLファイルシステムからの読み取りを処理する代わりに、MPIOは読み取り操作をネットワークドメインに移行させ、マルチパスセーフな方法で処理できるようにします。このアプローチはコンテキストスイッチを減らし、シーケンシャル読み取りトラフィックの全体的な並列性を向上させるとともに、WAFLをバイパスすることでバッファ管理のオーバーヘッドを削減します。
FlexGroupボリュームのランダム読み取りの強化:NFSv4.1はNFSv3の7%以内
FlexGroupボリュームとは、複数の構成要素となるボリュームを取り込み、それらを単一の統一された名前空間として提示するボリュームのことです。AFXでは、FlexGroupボリュームにはデフォルトで高度な容量バランス機能が有効になっており、10GBを超えるファイルは複数の構成ボリュームにまたがってマルチパートファイルとして書き込まれます。これらのファイルパーツが遠隔地にあるため、従来、NFSv4.xではランダム読み取りのパフォーマンスが若干劣っていました(NFSv3より約18%低い)。ONTAP 9.18.1では、この問題に対処するため、NFSv4.xを使用したマルチパート読み取りにおけるキャッシュされたI/Oのサポートが導入されました。注:この変更はFlexVolボリュームには適用されません。
シーケンシャル書き込み:以前のリリースから+10%向上
HA フェイルオーバー機能に使用される NVLOG データの複製方法の改善により、NetApp AFX システムの全体的なシーケンシャル書き込みパフォーマンスが向上しました。
メタデータ操作:EDAベンチマークにおいてNFSv3の15%以内のパフォーマンス
NFSv4.1 は従来、すべての OPEN および CLOSE 操作をシリアル化し、クラスタ ノードがネットワークから WAFL に送信する前に 1 つずつ処理します。ONTAP 9.18.1 では、競合状態の解決方法を変更することでネットワークの直列化を排除する Concurrent Open Close(COC)が導入され、以前のリリースで見られた OPEN/CLOSE のボトルネックが解消されます。
これらの変更はすべて、AFXで導入されたアーキテクチャの変更と相まって、ONTAP 9.18.1におけるNFSv4.1の全体的なパフォーマンスを向上させることが可能になりました。
シーケンシャルIO結果
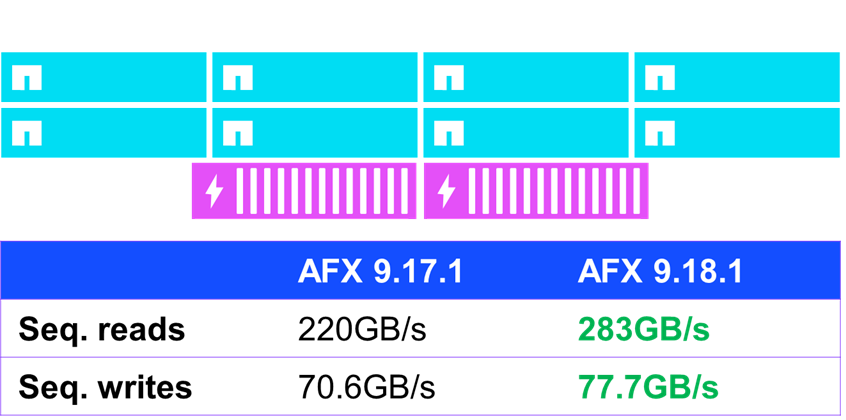
若干のパフォーマンス改善が見られた分野の一つは、シーケンシャルIO(つまり、予測可能で連続して発行されるIO)でした。fioを使用した標準的なパフォーマンステストでは、ONTAP 9.18.1を実行しているAFXは、シーケンシャル読み取りパフォーマンスを約30%、シーケンシャル書き込みパフォーマンスを10%向上させました。
NetApp AFX – NFSv4.1 シーケンシャル IO パフォーマンス ONTAP 9.18.1
メタデータを多く含むワークロードの結果
さらに印象的なのは、NFSv4.xのパフォーマンス上の最大の課題の一つであるメタデータの改善点です。これらはランダムな入出力であり、通常は4Kバイト程度のサイズで、ファイル所有者や属性の管理、ファイルの作成や一覧表示などに使用されます。NFSv4.xはステートフルな性質を持つため、これらの操作はCPUとレイテンシのコストが高くなりがちで、結果として全体的なパフォーマンスが低下します。
AFX ONTAP 9.18.1 の変更により、これらのタイプのワークロードにおける NFSv4.x のパフォーマンスが大幅に向上し、NFSv3 のパフォーマンスとの差が(15%以内に)縮まりました。
当社のパフォーマンスエンジニアリングチームは、標準的なAI画像、EDA、およびソフトウェアビルドのベンチマークのパフォーマンスを比較し、以前のONTAPリリースから大幅な改善を発見しました。
NetApp AFX – ONTAP 9.18.1におけるNFSv4.1メタデータIOパフォーマンス
