診断を実行します
 変更を提案
変更を提案
問題 のトラブルシューティングを行う場合、テクニカルサポートと協力して StorageGRID システムの診断を実行し、結果を確認します。
-
を使用して Grid Manager にサインインします サポートされている Web ブラウザ。
-
特定のアクセス権限が必要です。
Diagnostics (診断)ページでは、グリッドの現在の状態に対して一連の診断チェックが実行されます。各診断点検には、次の 3 つのいずれかのステータスがあります。
-
 * 標準 * :すべての値が標準範囲内です。
* 標準 * :すべての値が標準範囲内です。 -
 * 注意 * : 1 つ以上の値が正常範囲外です。
* 注意 * : 1 つ以上の値が正常範囲外です。 -
 * 注意 * : 1 つ以上の値が通常の範囲外です。
* 注意 * : 1 つ以上の値が通常の範囲外です。
診断ステータスは現在のアラートとは関係なく、グリッドで発生している処理の問題を示しているとは限りません。たとえば、アラートがトリガーされていない場合でも、診断チェックで警告ステータスが表示されることがあります。
-
サポート * > * ツール * > * 診断 * を選択します。
Diagnostics (診断)ページが表示され、診断チェックごとの結果がリストされます。結果は重大度( [ 注意 ] 、 [ 注意 ] 、 [ 標準 ] )でソートされます。それぞれの重大度の中で、結果はアルファベット順にソートされます。
この例では、すべての診断のステータスは Normal です。

-
特定の診断の詳細については、行の任意の場所をクリックしてください。
診断とその現在の結果の詳細が表示されます。以下の詳細が表示されます。
-
* ステータス * :この診断の現在のステータス。正常、注意、または注意。
-
* Prometheus クエリ * :診断に使用した場合、ステータス値の生成に使用した Prometheus 式。( Prometheus 式は一部の診断には使用されません)。
-
* しきい値 * :診断に使用できる場合は、異常な診断ステータスごとにシステム定義のしきい値。(しきい値はすべての診断に使用されるわけではありません)。

これらのしきい値は変更できません。 -
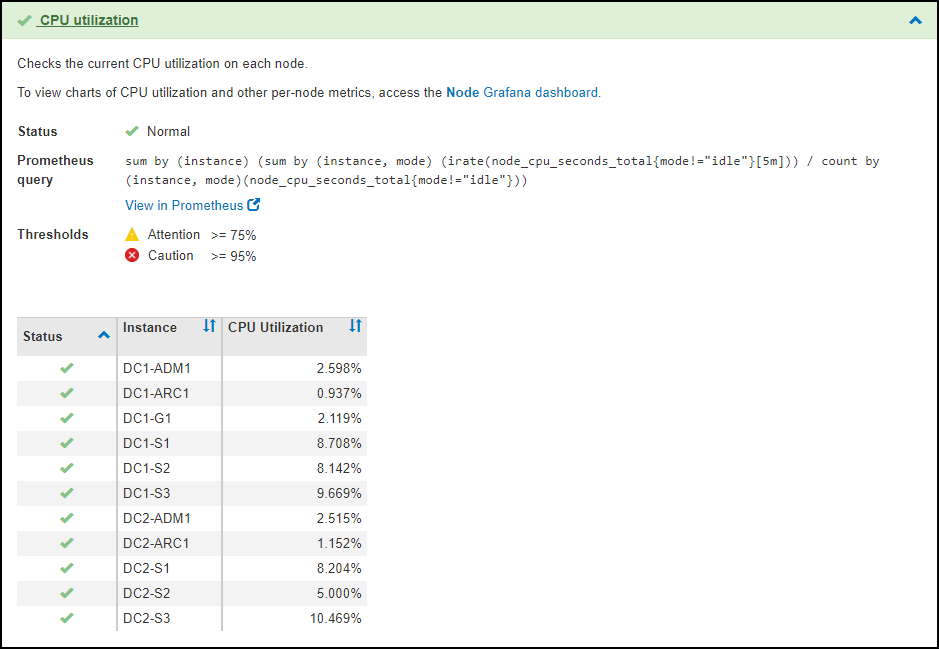
* ステータス値 * : StorageGRID システム全体の診断ステータスと値を示すテーブル。この例では、 StorageGRID システム内のすべてのノードの現在の CPU 利用率が表示されています。すべてのノードの値が警告と警告のしきい値を下回っているため、診断の全体的なステータスは「正常」です。
-
-
* オプション * :この診断に関連した Grafana チャートを表示するには、 * Grafana dashboard dashboard * リンクをクリックします。
このリンクは、すべての診断で表示されるわけではありません。
関連する Grafana ダッシュボードが表示されます。この例では、このノードの CPU 利用率とノードの他の Grafana チャートを示すノードダッシュボードが表示されます。
また、構築済みの Grafana ダッシュボードには、 * support * > * Tools * > * Metrics * ページの Grafana セクションからアクセスできます。 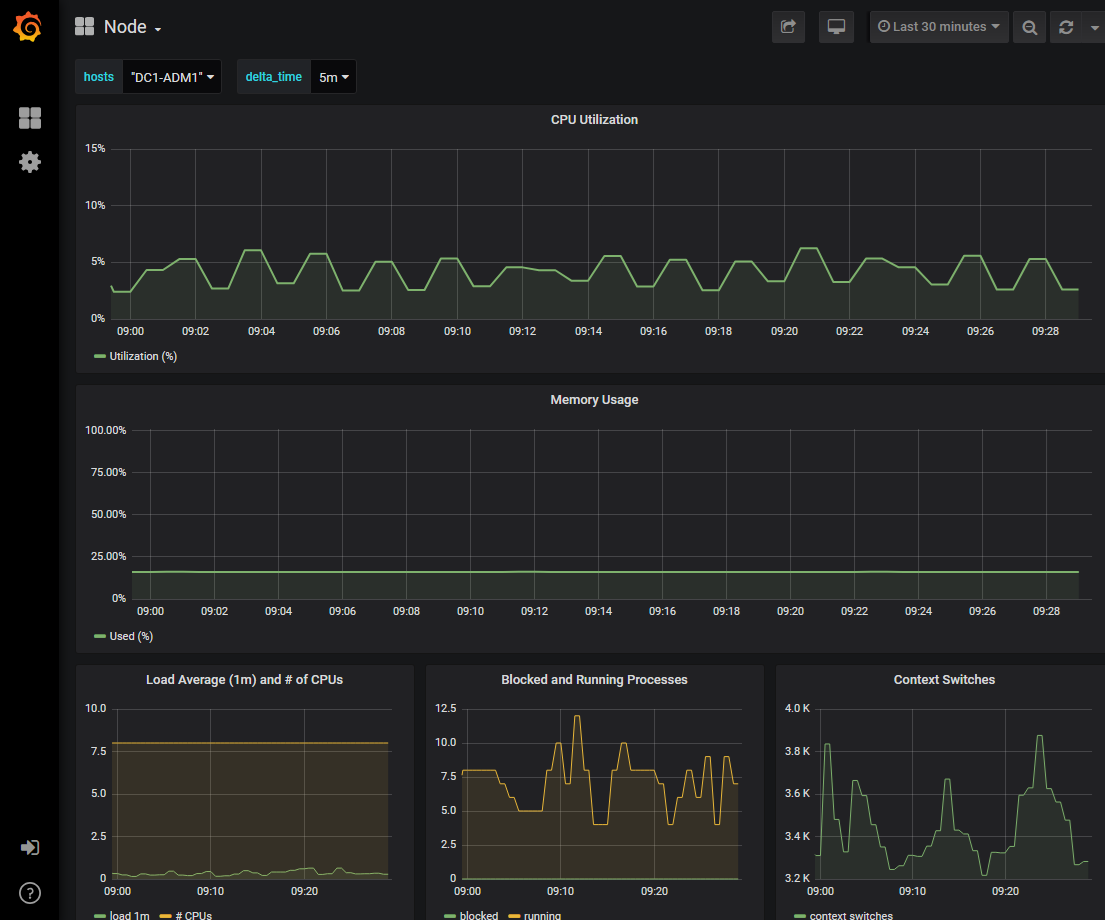
-
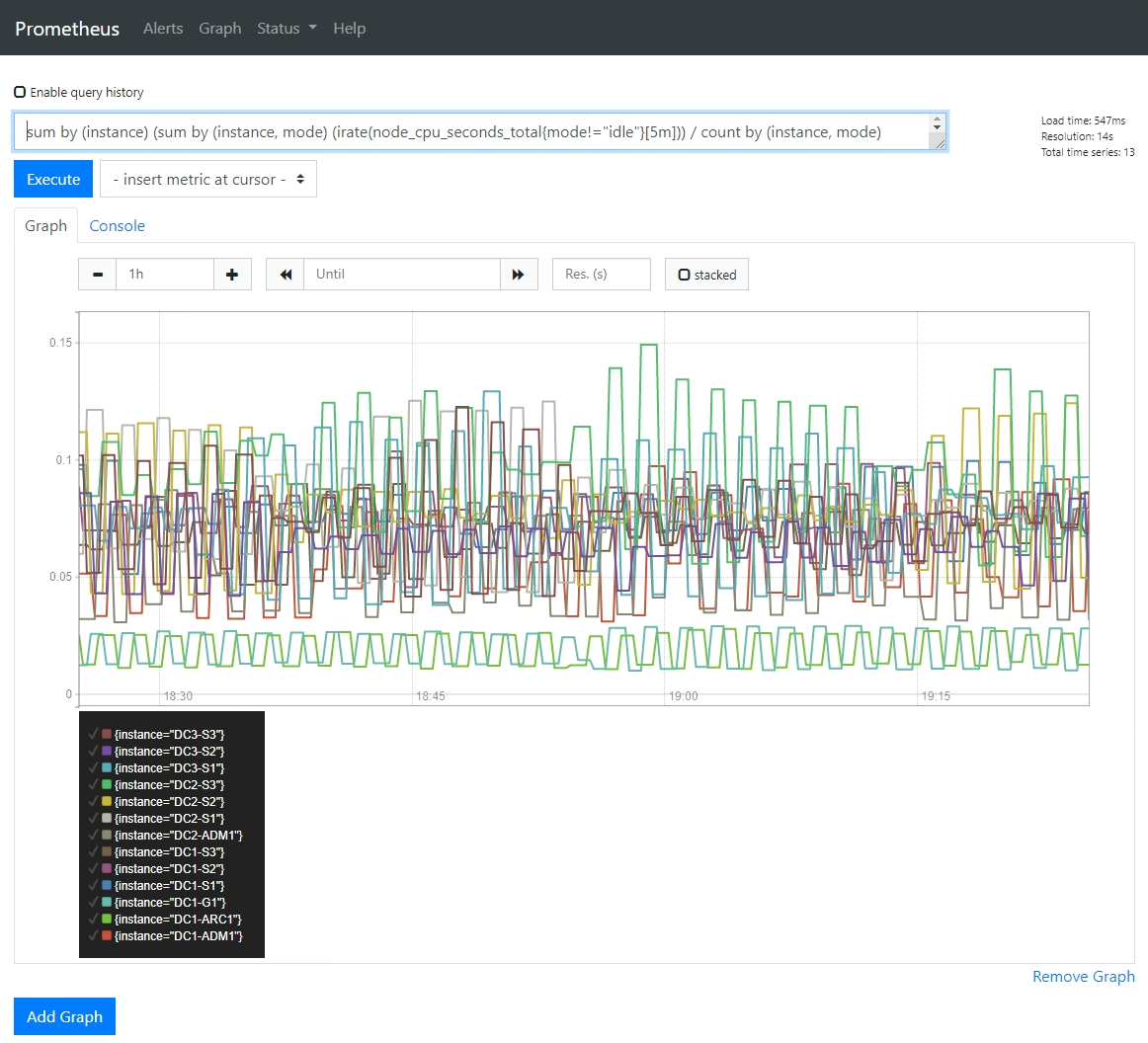
* オプション * :一定の期間にわたる Prometheus 式のチャートを表示するには、 * Prometheus で表示 * をクリックします。
診断に使用された式の Prometheus グラフが表示されます。