

MetroCluster 구성에서 클러스터의 동적 성능 이벤트 분석
 변경 제안
변경 제안
Unified Manager를 사용하면 성능 이벤트가 감지된 MetroCluster 구성에서 클러스터를 분석할 수 있습니다. 관련된 클러스터 이름, 이벤트 감지 시간 및 _bully_and_d피해자_작업 부하를 식별할 수 있습니다.
-
필요한 것 *
-
운영자, 애플리케이션 관리자 또는 스토리지 관리자 역할이 있어야 합니다.
-
MetroCluster 구성에 대한 새로운 성능 이벤트, 확인된 이벤트 또는 사용되지 않는 성능 이벤트가 있어야 합니다.
-
MetroCluster 구성의 두 클러스터는 동일한 Unified Manager 인스턴스에서 모니터링해야 합니다.
-
이벤트에 대한 정보를 보려면 * 이벤트 세부 정보 * 페이지를 표시합니다.
-
이벤트 설명을 검토하여 관련된 워크로드의 이름과 관련 워크로드의 수를 확인합니다.
이 예에서 MetroCluster 리소스 아이콘은 빨간색이며 MetroCluster 리소스 경합이 발생했음을 나타냅니다. 아이콘 위에 커서를 놓으면 아이콘에 대한 설명이 표시됩니다.

-
클러스터 이름과 이벤트 감지 시간을 기록해 둡니다. 이 정보를 사용하여 파트너 클러스터의 성능 이벤트를 분석할 수 있습니다.
-
차트에서 _d피해자_워크로드 를 검토하여 응답 시간이 성능 임계값보다 높음을 확인합니다.
이 예에서는 희생자 워크로드가 호버 텍스트에 표시됩니다. 지연 시간 차트는 관련된 피해자 워크로드에 대해 일관된 지연 시간 패턴을 고수준으로 표시합니다. 비정상적인 지연 시간으로 인해 이벤트가 트리거되었지만, 일관된 지연 시간 패턴을 통해 워크로드가 예상 범위 내에서 수행되고 있음을 알 수 있지만 I/O가 급증하면 지연 시간이 늘어나고 이벤트가 트리거됩니다.
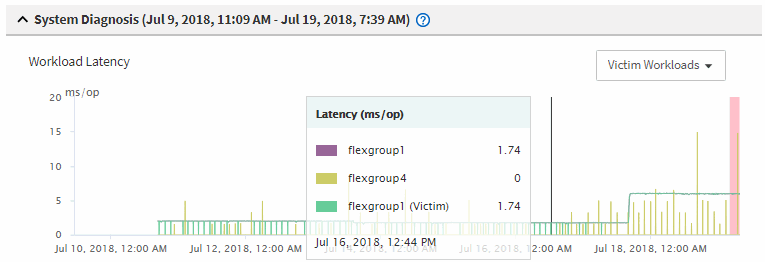
최근에 이러한 볼륨 워크로드에 액세스하는 클라이언트에 애플리케이션을 설치하고 해당 애플리케이션에서 많은 양의 I/O를 보내면 지연 시간이 증가할 것으로 예상할 수 있습니다. 워크로드의 지연 시간이 예상 범위 내로 돌아오며 이벤트 상태가 폐기로 변경되고 30분 이상 이 상태로 지속되면 이벤트를 무시할 수 있습니다. 이벤트가 진행 중이며 새 상태로 남아 있는 경우 더 자세히 조사하여 다른 문제로 인해 이벤트가 발생했는지 여부를 확인할 수 있습니다.
-
워크로드 처리량 차트에서 * Bully Workload * 를 선택하여 워크로드가 불룩한 워크로드를 표시합니다.
대규모 워크로드가 있을 경우 MetroCluster 리소스를 과도하게 활용하여 로컬 클러스터에 있는 하나 이상의 워크로드에 의해 이벤트가 발생했을 수 있습니다. 워크로드가 큰 경우 쓰기 처리량(MB/s)이 편차가 높습니다.
이 차트는 워크로드의 쓰기 처리량(MB/s) 패턴을 높은 수준으로 표시합니다. 쓰기 MB/s 패턴을 검토하여 비정상적인 처리량을 파악할 수 있습니다. 이는 워크로드가 MetroCluster 리소스를 과도하게 활용하고 있음을 나타낼 수 있습니다.
문제가 있는 워크로드가 이벤트와 관련되지 않은 경우, 해당 이벤트는 클러스터 간 연결 상태 문제 또는 파트너 클러스터의 성능 문제로 인해 발생한 것일 수 있습니다. Unified Manager를 사용하여 MetroCluster 구성에서 두 클러스터의 상태를 확인할 수 있습니다. Unified Manager를 사용하여 파트너 클러스터의 성능 이벤트를 확인하고 분석할 수도 있습니다.