

본 한국어 번역은 사용자 편의를 위해 제공되는 기계 번역입니다. 영어 버전과 한국어 버전이 서로 어긋나는 경우에는 언제나 영어 버전이 우선합니다.
클러스터 검색 프로세스의 작동 방식
 변경 제안
변경 제안
Unified Manager에 클러스터를 추가하면 서버에서 클러스터 개체를 검색하여 해당 데이터베이스에 추가합니다. 검색 프로세스가 작동하는 방식을 이해하면 조직의 클러스터와 개체를 관리하는 데 도움이 됩니다.
클러스터 구성 정보 수집을 위한 모니터링 간격은 15분입니다. 예를 들어, 클러스터를 추가한 후에는 15분 이내에 Unified Manager UI에 클러스터 객체를 표시할 수 있습니다. 이 기간은 클러스터를 변경할 때도 적용됩니다. 예를 들어, 클러스터의 SVM에 새 볼륨 2개를 추가하는 경우 다음 폴링 간격 후 UI에서 새로운 객체를 볼 수 있으며 이는 최대 15분이 될 수 있습니다.
다음 그림에서는 검색 프로세스를 보여 줍니다.
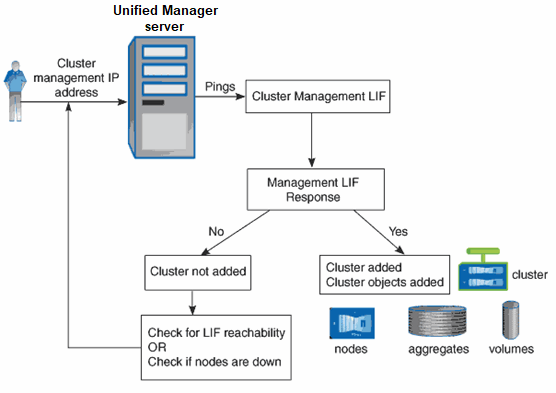
새 클러스터의 모든 객체가 검색된 후 Unified Manager가 이전 15일 동안 기간별 성능 데이터를 수집하기 시작합니다. 이러한 통계는 데이터 연속성 수집 기능을 사용하여 수집됩니다. 이 기능은 클러스터를 추가한 직후 2주 이상의 클러스터 성능 정보를 제공합니다. 데이터 연속성 수집 주기가 완료되면 기본적으로 5분마다 실시간 클러스터 성능 데이터가 수집됩니다.

|
15일간의 성능 데이터 수집은 CPU를 많이 사용하므로 데이터 연속성 수집 폴이 너무 많은 클러스터에서 동시에 실행되지 않도록 새 클러스터를 추가하는 시차를 두는 것이 좋습니다. |