

NetApp Cloud Tiering 에서 클러스터의 데이터 계층화 관리
 변경 제안
변경 제안
이제 온프레미스 ONTAP 클러스터에서 데이터 계층화를 설정했으므로 NetApp Cloud Tiering 사용하여 추가 볼륨에서 데이터를 계층화하고, 볼륨의 계층화 정책을 변경하고, 추가 클러스터를 검색하는 등의 작업을 수행할 수 있습니다.
클러스터의 계층화 정보 검토
클라우드 계층, 디스크의 데이터 또는 클러스터 디스크의 핫 데이터와 콜드 데이터의 양을 확인합니다. 또는 클러스터 디스크에서 핫 데이터와 콜드 데이터의 양을 확인하고 싶을 수도 있습니다. 클라우드 티어링은 각 클러스터에 대한 정보를 제공합니다.
-
왼쪽 탐색 메뉴에서 *모빌리티 > 클라우드 계층화*를 선택합니다.
-
클러스터 페이지에서 메뉴 아이콘을 선택하세요.
 클러스터의 경우 *클러스터 정보*를 선택하세요.
클러스터의 경우 *클러스터 정보*를 선택하세요.
-
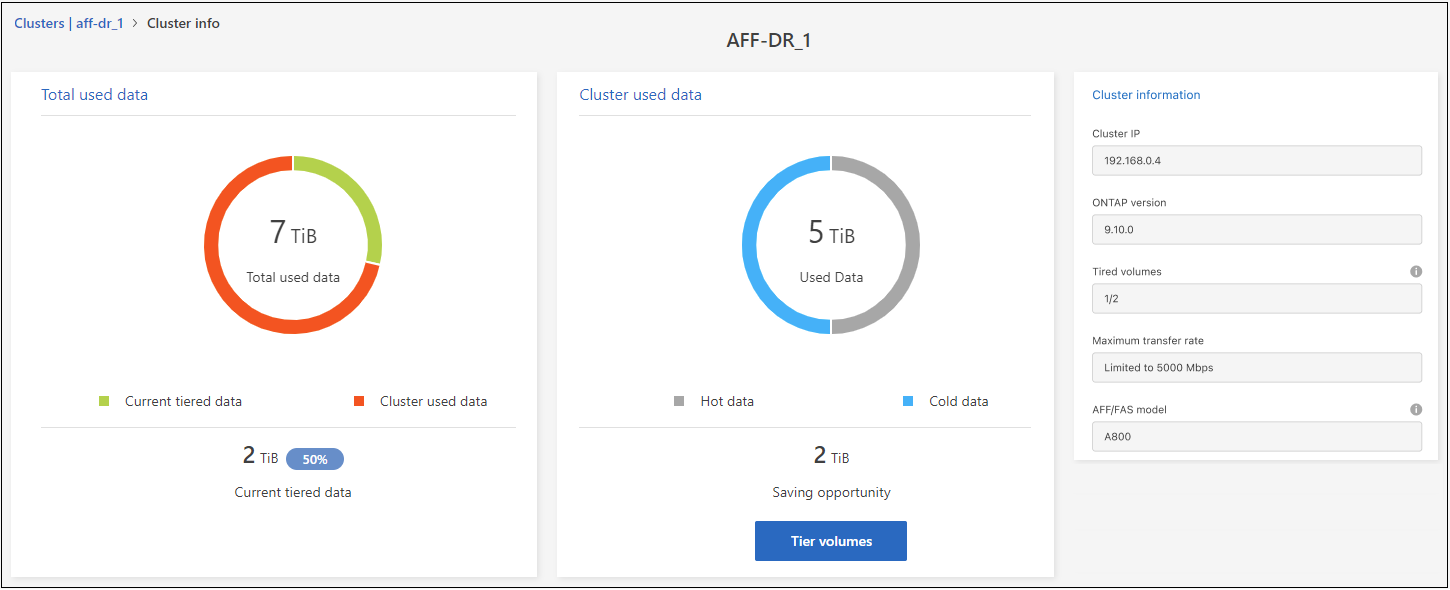
클러스터에 대한 세부 정보를 검토하세요.
예를 들면 다음과 같습니다.
Cloud Volumes ONTAP 시스템의 경우 표시 방식이 다릅니다. Cloud Volumes ONTAP 볼륨은 데이터를 클라우드에 계층화할 수 있지만 Cloud Tiering 서비스는 사용하지 않습니다. "Cloud Volumes ONTAP 시스템에서 비활성 데이터를 저비용 개체 스토리지로 계층화하는 방법을 알아보세요." .
당신도 할 수 있습니다 "Active IQ Digital Advisor ( Digital Advisor 라고도 함)에서 클러스터의 계층화 정보 보기" NetApp 제품에 대해 잘 알고 계시다면. 왼쪽 탐색 창에서 *클라우드 권장 사항*을 선택합니다.
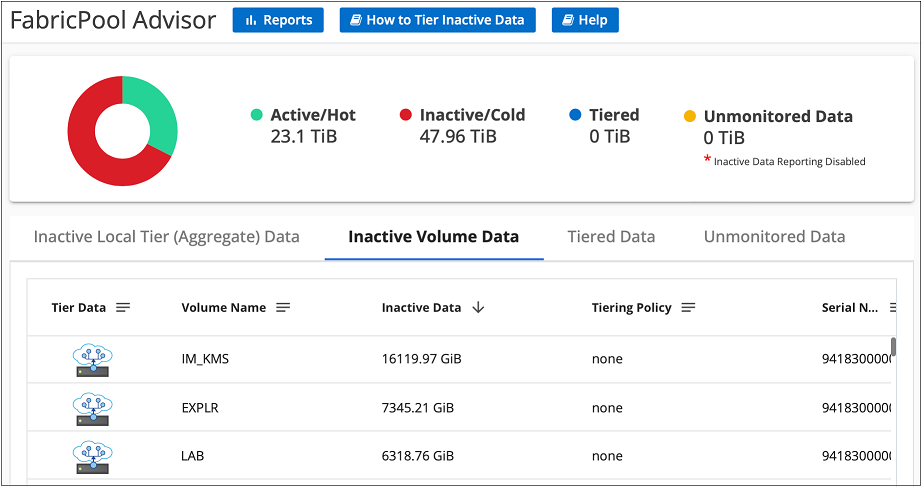
추가 볼륨의 계층 데이터
예를 들어 새 볼륨을 만든 후 등 언제든지 추가 볼륨에 대한 데이터 계층화를 설정할 수 있습니다.

|
클러스터에 대한 계층화를 처음 설정할 때 이미 개체 스토리지가 구성되어 있으므로 개체 스토리지를 구성할 필요가 없습니다. ONTAP 은 추가 볼륨의 비활성 데이터를 동일한 개체 저장소로 계층화합니다. |
-
왼쪽 탐색 메뉴에서 *모빌리티 > 클라우드 계층화*를 선택합니다.
-
클러스터 페이지에서 클러스터의 *계층 볼륨*을 선택합니다.

-
계층 볼륨 페이지에서 계층화를 구성하려는 볼륨을 선택하고 계층화 정책 페이지를 시작합니다.
-
모든 볼륨을 선택하려면 제목 행의 상자를 선택하십시오.
 )을 클릭하고 *볼륨 구성*을 선택합니다.
)을 클릭하고 *볼륨 구성*을 선택합니다. -
여러 볼륨을 선택하려면 각 볼륨의 상자를 선택하십시오.
 )을 클릭하고 *볼륨 구성*을 선택합니다.
)을 클릭하고 *볼륨 구성*을 선택합니다. -
단일 볼륨을 선택하려면 행을 선택하세요(또는
 볼륨에 대한 아이콘)입니다.
볼륨에 대한 아이콘)입니다.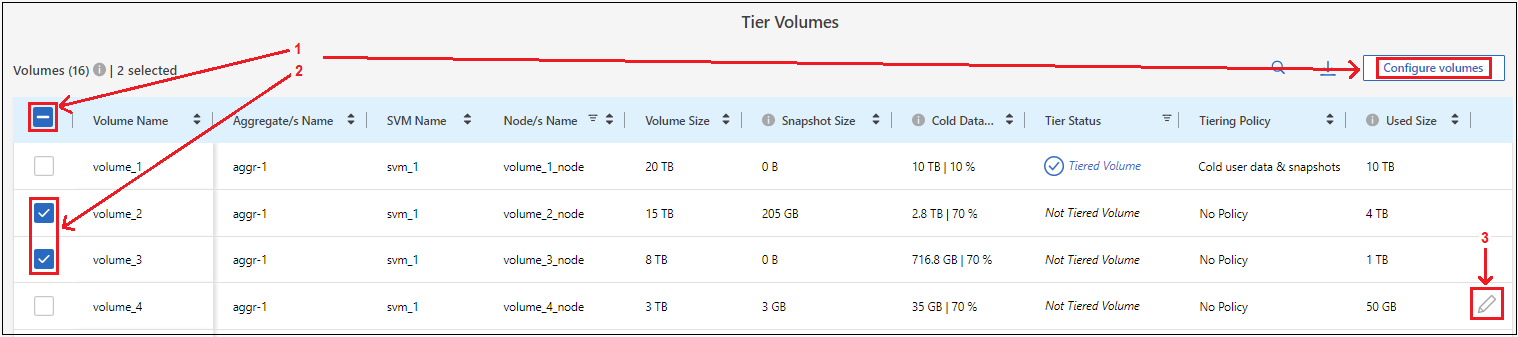
-
-
계층화 정책 대화 상자에서 계층화 정책을 선택하고, 선택적으로 선택한 볼륨에 대한 냉각 일수를 조정하고, *적용*을 선택합니다.
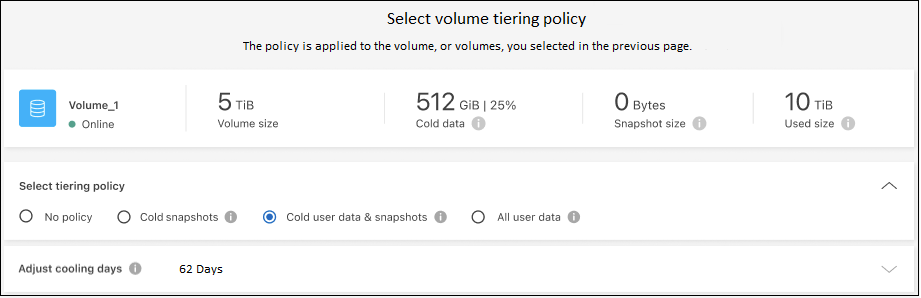
ONTAP 선택된 볼륨의 데이터를 클라우드로 계층화하기 시작합니다.
볼륨의 계층화 정책 변경
볼륨의 계층화 정책을 변경하면 ONTAP 콜드 데이터를 개체 스토리지에 계층화하는 방식이 변경됩니다. 변경은 정책을 변경하는 순간부터 시작됩니다. 이는 볼륨에 대한 후속 계층화 동작만 변경하며, 데이터를 소급적으로 클라우드 계층으로 이동하지는 않습니다.
-
왼쪽 탐색 메뉴에서 *모빌리티 > 클라우드 티어링*을 선택합니다.
-
클러스터 페이지에서 클러스터의 *계층 볼륨*을 선택합니다.
-
볼륨에 대한 행을 클릭하고 계층화 정책을 선택하고, 선택적으로 냉각 일수를 조정한 다음 *적용*을 선택합니다.

|
"계층화된 데이터 검색" 옵션이 표시되면 다음을 참조하세요.클라우드 계층에서 성능 계층으로 데이터를 다시 마이그레이션합니다. 자세한 내용은. |
ONTAP 계층화 정책을 변경하고 새로운 정책에 따라 데이터 계층화를 시작합니다.
비활성 데이터를 개체 스토리지에 업로드하는 데 사용 가능한 네트워크 대역폭을 변경합니다.
클러스터에 대해 Cloud Tiering을 활성화하면 기본적으로 ONTAP 무제한 대역폭을 사용하여 시스템 볼륨의 비활성 데이터를 개체 스토리지로 전송할 수 있습니다. 트래픽 계층화가 사용자 작업 부하에 영향을 미치는 경우 전송 중에 사용되는 네트워크 대역폭을 제한합니다. 최대 전송 속도는 1~10,000Mbps 사이에서 선택할 수 있습니다.
-
왼쪽 탐색 메뉴에서 *모빌리티 > 계층화*를 선택합니다.
-
클러스터 페이지에서 메뉴 아이콘을 선택하세요.
클러스터의 경우 *최대 전송 속도*를 선택합니다.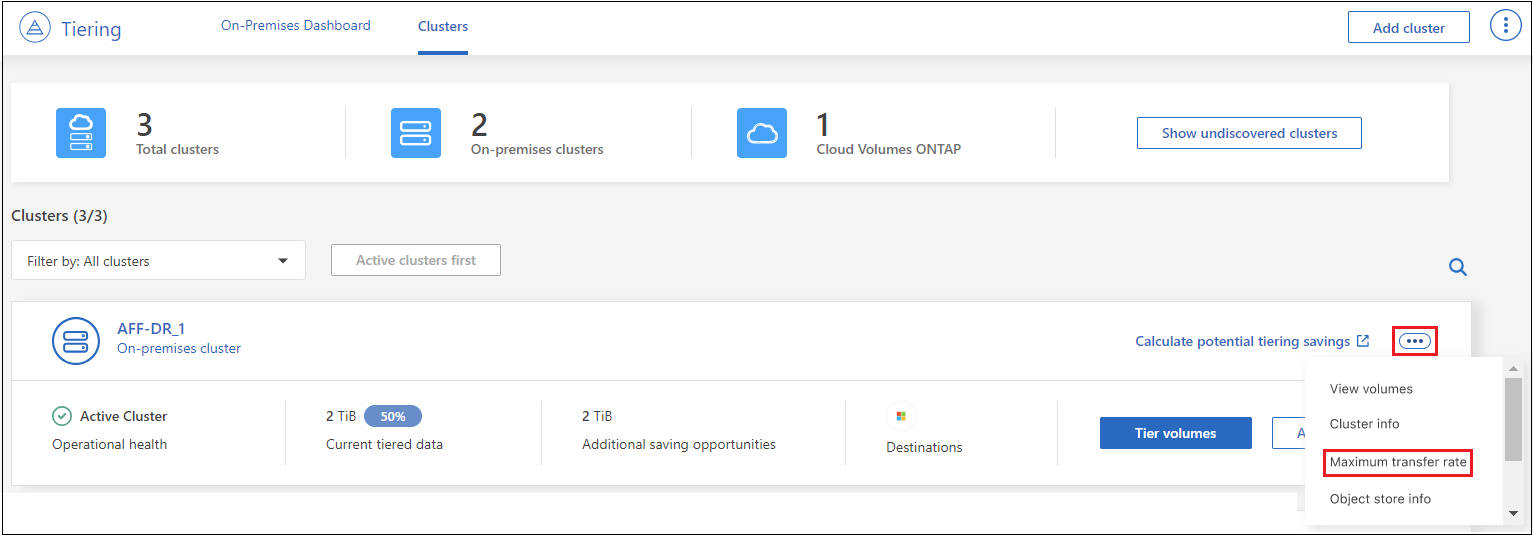
-
최대 전송 속도 페이지에서 제한됨 라디오 버튼을 선택하고 사용 가능한 최대 대역폭을 입력하거나, *무제한*을 선택하여 제한이 없음을 나타냅니다. 그런 다음 *적용*을 선택하세요.
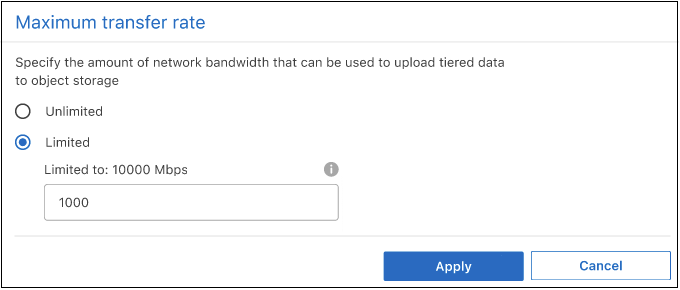
이 설정은 데이터를 계층화하는 다른 클러스터에 할당된 대역폭에는 영향을 미치지 않습니다.
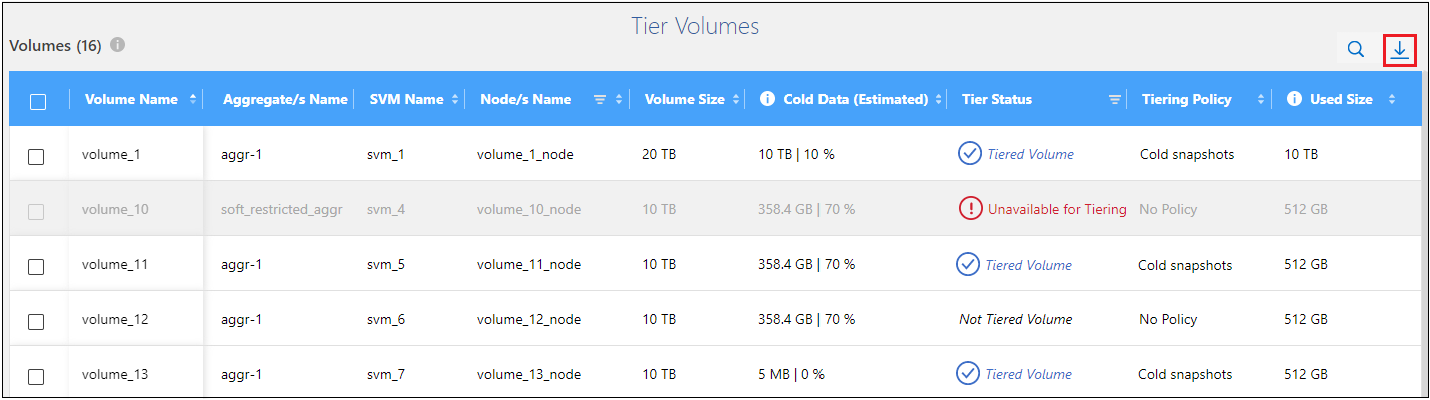
볼륨에 대한 계층화 보고서를 다운로드하세요
클러스터에서 관리하는 모든 볼륨의 계층화 상태를 검토할 수 있도록 계층 볼륨 페이지 보고서를 다운로드하세요. 그냥 선택하세요 단추. 클라우드 티어링은 필요에 따라 검토하고 다른 그룹으로 보낼 수 있는 .CSV 파일을 생성합니다. .CSV 파일에는 최대 10,000개 행의 데이터가 포함됩니다.
단추. 클라우드 티어링은 필요에 따라 검토하고 다른 그룹으로 보낼 수 있는 .CSV 파일을 생성합니다. .CSV 파일에는 최대 10,000개 행의 데이터가 포함됩니다.
클라우드 계층에서 성능 계층으로 데이터를 다시 마이그레이션합니다.
클라우드에서 액세스하는 계층화된 데이터는 "다시 가열"되어 성능 계층으로 다시 이동될 수 있습니다. 하지만 클라우드 계층에서 성능 계층으로 데이터를 사전에 승격하려면 계층화 정책 대화 상자에서 이 작업을 수행할 수 있습니다. 이 기능은 ONTAP 9.8 이상을 사용할 때 사용할 수 있습니다.
볼륨에서 계층화를 사용하지 않으려는 경우나 모든 사용자 데이터는 성능 계층에 보관하고 스냅샷 사본은 클라우드 계층에 보관하려는 경우 이 작업을 수행할 수 있습니다.
두 가지 옵션이 있습니다.
| 옵션 | 설명 | 계층화 정책에 대한 영향 |
|---|---|---|
모든 데이터를 다시 가져오세요 |
클라우드에 계층화된 모든 볼륨 데이터와 스냅샷 복사본을 검색하여 성능 계층으로 승격시킵니다. |
티어링 정책이 "정책 없음"으로 변경되었습니다. |
활성 파일 시스템 다시 가져오기 |
클라우드에 계층화된 활성 파일 시스템 데이터만 검색하여 성능 계층으로 승격합니다(스냅샷 사본은 클라우드에 남아 있음). |
티어링 정책이 "콜드 스냅샷"으로 변경되었습니다. |
|
|
클라우드 제공업체는 클라우드에서 전송된 데이터 양에 따라 요금을 청구할 수 있습니다. |
클라우드에서 다시 가져온 데이터를 저장할 수 있는 충분한 공간이 성능 계층에 있는지 확인하세요.
-
왼쪽 탐색 메뉴에서 *모빌리티 > 클라우드 계층화*를 선택합니다.
-
클러스터 페이지에서 클러스터의 *계층 볼륨*을 선택합니다.
-
클릭
볼륨의 아이콘을 클릭하고, 사용하려는 검색 옵션을 선택한 다음 *적용*을 선택합니다.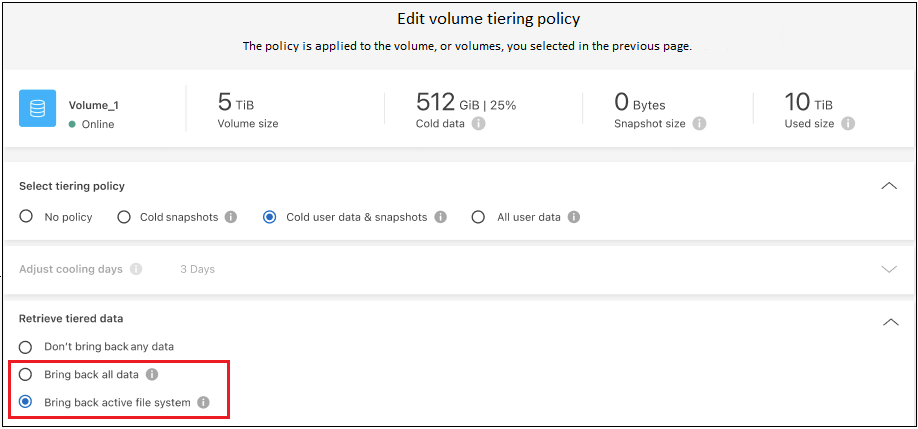
계층화 정책이 변경되고 계층화된 데이터가 성능 계층으로 다시 마이그레이션되기 시작합니다. 클라우드에 저장된 데이터의 양에 따라 전송 과정에 시간이 걸릴 수 있습니다.
집계에 대한 계층화 설정 관리
온프레미스 ONTAP 시스템의 각 집계에는 조정할 수 있는 두 가지 설정이 있습니다. 계층화 완전성 임계값과 비활성 데이터 보고가 활성화되어 있는지 여부입니다.
- 계층화 충만도 임계값
-
임계값을 낮은 숫자로 설정하면 계층화가 이루어지기 전에 성능 계층에 저장해야 하는 데이터 양이 줄어듭니다. 이 기능은 활성 데이터가 거의 없는 대규모 집계에 유용할 수 있습니다.
임계값을 더 높은 숫자로 설정하면 계층화가 이루어지기 전에 성능 계층에 저장해야 하는 데이터 양이 늘어납니다. 이 기능은 집계가 최대 용량에 가까울 때만 계층화하도록 설계된 솔루션에 유용할 수 있습니다.
- 비활성 데이터 보고
-
비활성 데이터 보고(IDR)는 31일 쿨링 기간을 사용하여 어떤 데이터가 비활성으로 간주되는지 결정합니다. 계층화된 콜드 데이터의 양은 볼륨에 설정된 계층화 정책에 따라 달라집니다. 이 양은 IDR이 31일 냉각 기간을 사용하여 감지한 저온 데이터의 양과 다를 수 있습니다.
비활성 데이터와 비용 절감 기회를 파악하는 데 도움이 되므로 IDR을 활성화해 두는 것이 가장 좋습니다. 집계에서 데이터 계층화가 활성화된 경우 IDR을 활성화된 상태로 유지해야 합니다.
-
클러스터 페이지에서 선택한 클러스터에 대해 *고급 설정*을 선택합니다.

-
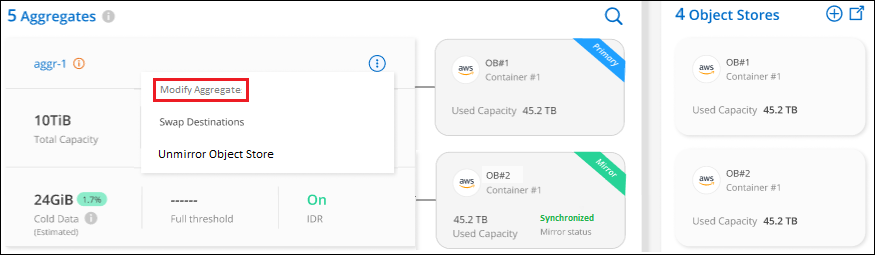
고급 설정 페이지에서 집계에 대한 메뉴 아이콘을 선택하고 *집계 수정*을 선택합니다.
-
표시되는 대화 상자에서 충만도 임계값을 수정하고 비활성 데이터 보고를 활성화할지 비활성화할지 선택합니다.

-
*적용*을 클릭하세요.
운영 상태 수정
장애가 발생하면 Cloud Tiering은 클러스터 대시보드에 "실패" 운영 상태를 표시합니다. 상태는 ONTAP 시스템과 NetApp Console 의 상태를 반영합니다.
-
운영 상태가 "실패"인 클러스터를 식별합니다.
-
정보 "i" 아이콘 위에 마우스를 올려 놓으면 실패 이유를 확인할 수 있습니다.
-
문제를 해결하세요:
-
ONTAP 클러스터가 작동 중인지, 개체 스토리지 공급자에 대한 인바운드 및 아웃바운드 연결이 있는지 확인하세요.
-
콘솔에 Cloud Tiering 서비스, 개체 저장소 및 검색된 ONTAP 클러스터에 대한 아웃바운드 연결이 있는지 확인합니다.
-
Cloud Tiering에서 추가 클러스터를 검색하세요
발견되지 않은 온프레미스 ONTAP 클러스터를 Tiering_Cluster_ 페이지에서 콘솔에 추가하여 클러스터에 대한 계층화를 활성화할 수 있습니다.
추가 클러스터를 검색할 수 있는 버튼이 Tiering On-Prem 대시보드 페이지에도 표시됩니다.
-
클라우드 티어링에서 클러스터 탭을 선택합니다.
-
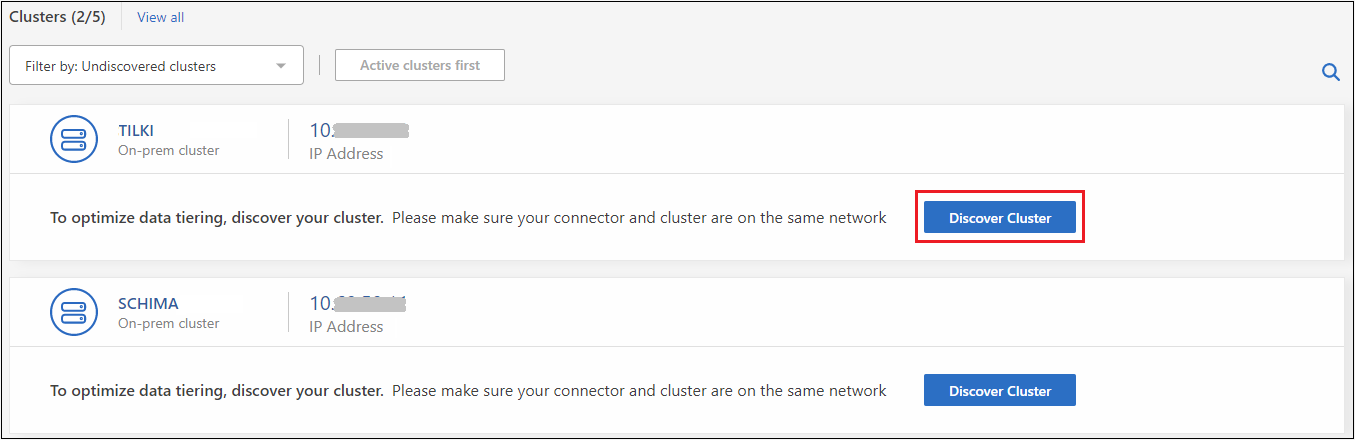
발견되지 않은 클러스터를 보려면 *발견되지 않은 클러스터 표시*를 선택하세요.

NSS 자격 증명이 콘솔에 저장된 경우 계정의 클러스터가 목록에 표시됩니다.
NSS 자격 증명이 저장되지 않은 경우 검색되지 않은 클러스터를 보려면 먼저 자격 증명을 추가하라는 메시지가 표시됩니다.
-
콘솔을 통해 관리하고 데이터 계층화를 구현하려는 클러스터에 대해 *클러스터 검색*을 클릭합니다.
-
클러스터 세부 정보 페이지에서 관리자 사용자 계정의 비밀번호를 입력하고 *검색*을 선택합니다.
클러스터 관리 IP 주소는 NSS 계정의 정보를 기반으로 채워집니다.
-
세부 정보 및 자격 증명 페이지에서 클러스터 이름이 시스템 이름으로 추가되므로 *이동*을 선택합니다.
콘솔은 클러스터를 검색하고 클러스터 이름을 시스템 이름으로 사용하여 시스템 페이지에 추가합니다.
오른쪽 패널에서 이 클러스터에 대한 계층화 서비스나 다른 서비스를 활성화할 수 있습니다.
모든 콘솔 에이전트에서 클러스터 검색
환경 내 모든 스토리지를 관리하기 위해 여러 에이전트를 사용하는 경우, 계층화를 구현하려는 일부 클러스터가 다른 에이전트에 있을 수 있습니다. 특정 클러스터를 관리하는 에이전트가 무엇인지 확실하지 않은 경우 Cloud Tiering을 사용하여 모든 에이전트를 검색할 수 있습니다.
-
클라우드 티어링 메뉴 표시줄에서 작업 메뉴를 선택하고 *모든 에이전트에서 클러스터 검색*을 선택합니다.

-
표시된 검색 대화 상자에서 클러스터 이름을 입력하고 *검색*을 선택합니다.
Cloud Tiering은 클러스터를 찾을 수 있는 경우 에이전트의 이름을 표시합니다.