

솔루션 검증 시나리오
 변경 제안
변경 제안
FlexPod Datacenter SM-BC 솔루션은 다양한 단일 장애 지점 시나리오와 사이트 재해에서 데이터 서비스를 보호합니다. 각 사이트에 구현된 이중화 설계는 고가용성을 제공하며, 사이트 간 동기식 데이터 복제를 통해 SM-BC를 구현하면 한 사이트의 사이트 전체에 걸친 재해 발생 시 데이터 서비스를 보호할 수 있습니다. 배포된 솔루션은 원하는 솔루션 기능 및 솔루션이 보호되도록 설계된 다양한 장애 시나리오에 대해 검증되었습니다.
솔루션 기능 검증
솔루션 기능을 검증하고 부분 및 전체 사이트 장애 시나리오를 시뮬레이션하기 위해 다양한 테스트 사례가 사용됩니다. Cisco Validated Design Program의 기존 FlexPod 데이터 센터 솔루션에서 이미 수행된 테스트의 중복을 최소화하기 위해 이 보고서의 중점 내용은 솔루션의 SM-BC 관련 측면에 있습니다. 실무자가 구현 검증을 위해 거쳐야 하는 일반적인 FlexPod 유효성 검사가 몇 가지 포함되어 있습니다.
솔루션 검증을 위해 ESXi 호스트당 하나의 Windows 10 가상 머신이 두 사이트의 모든 ESXi 호스트에 생성되었습니다. IOMeter 도구가 설치되어 공유 로컬 iSCSI 데이터 저장소에서 매핑된 두 개의 가상 데이터 디스크에 대한 I/O를 생성하는 데 사용되었습니다. 구성된 IOMeter 워크로드 매개 변수는 8KB I/O, 75% 읽기 및 50% 랜덤으로 각 데이터 디스크에 대해 8개의 탁월한 I/O 명령을 구성했습니다. 수행되는 대부분의 테스트 시나리오에서 IOMeter I/O를 계속 수행하면 해당 시나리오에서 데이터 서비스 중단이 발생하지는 않았음을 알 수 있습니다.
SM-BC는 데이터베이스 서버와 같은 비즈니스 애플리케이션에 매우 중요하기 때문에 Windows Server 2022의 가상 머신에 있는 Microsoft SQL Server 2019 인스턴스는 로컬 사이트의 스토리지를 사용할 수 없고 애플리케이션 없이 원격 사이트 스토리지에서 데이터 서비스가 재개될 때 애플리케이션이 계속 실행되는지 확인하기 위한 테스트의 일부로 포함되어 있었습니다 운영 중단:
ESXi 호스트 iSCSI SAN 부팅 테스트입니다
솔루션의 ESXi 호스트는 iSCSI SAN에서 부팅하도록 구성됩니다. SAN 부트를 사용하면 추가 구성 변경 없이 IT가 부팅할 수 있도록 서버의 서비스 프로필을 새 서버와 연결할 수 있으므로 서버 교체 시 서버 관리가 간소화됩니다.
로컬 iSCSI 부트 LUN에서 사이트에 있는 ESXi 호스트를 부팅하는 것 외에도 로컬 스토리지 컨트롤러가 Takeover 상태에 있거나 로컬 스토리지 클러스터를 완전히 사용할 수 없을 때 ESXi 호스트를 부팅하기 위해 테스트가 수행되었습니다. 이러한 검증 시나리오에서는 ESXi 호스트가 설계별로 올바르게 구성되어 있는지 확인하고 스토리지 유지 보수 또는 재해 복구 시나리오에서 부팅하여 비즈니스 연속성을 제공합니다.
SM-BC 정합성 보장 그룹 관계가 구성되기 전에 스토리지 컨트롤러 HA 쌍에서 호스팅되는 iSCSI LUN의 경로가 4개(Best Practice 구현을 기반으로 각 iSCSI 패브릭을 통해 2개)입니다. 호스트는 2개의 iSCSI VLAN/패브릭을 통해 LUN 호스팅 컨트롤러에 연결할 수 있고 컨트롤러의 고가용성 파트너를 통해 LUN에 연결할 수 있습니다.
SM-BC 정합성 보장 그룹 관계가 구성되고 미러링된 LUN이 이니시에이터에 제대로 매핑되면 LUN의 경로 수가 두 배가 됩니다. 이 구축 환경에서는 2개의 활성/최적화 경로와 2개의 활성/최적화 경로를 갖는 것에서부터 2개의 활성/최적화 경로와 6개의 활성/비최적화 경로를 갖는 것까지 모두 포함됩니다.
다음 그림에서는 LUN 0과 같이 ESXi 호스트가 LUN을 액세스하는 데 사용할 수 있는 경로를 보여 줍니다. LUN이 사이트 A 컨트롤러 01에 연결되므로 해당 컨트롤러를 통해 LUN에 직접 액세스하는 2개의 경로만 액티브/최적화되고 나머지 6개 경로만 액티브/비최적화되어 있습니다.
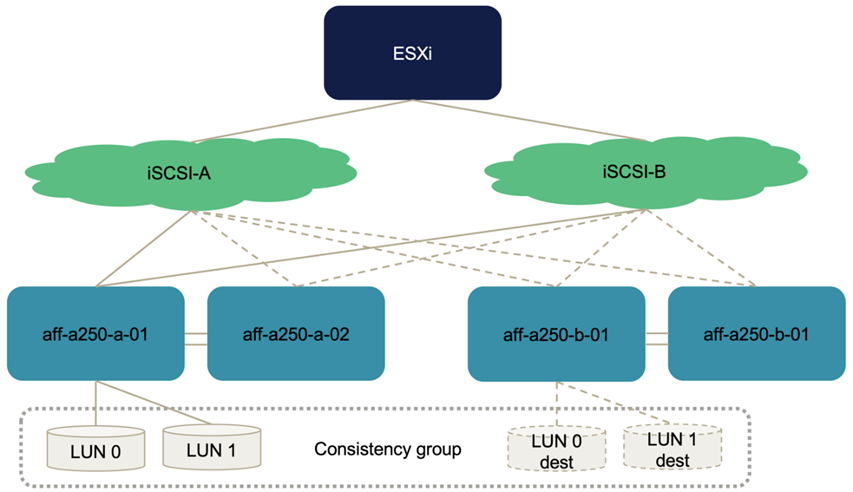
다음 스토리지 디바이스 경로 정보 스크린샷은 ESXi 호스트에서 두 가지 유형의 디바이스 경로를 보는 방법을 보여 줍니다. 두 개의 Active/Optimized Path는 Active(I/O) Path 상태를 가지고 있는 것으로 표시되며, 6개의 Active/Non-Optimized Path는 Active로 표시됩니다. 또한 Target 열에는 두 개의 iSCSI 타겟과 타겟에 액세스할 수 있는 각 iSCSI LIF IP 주소가 표시됩니다.
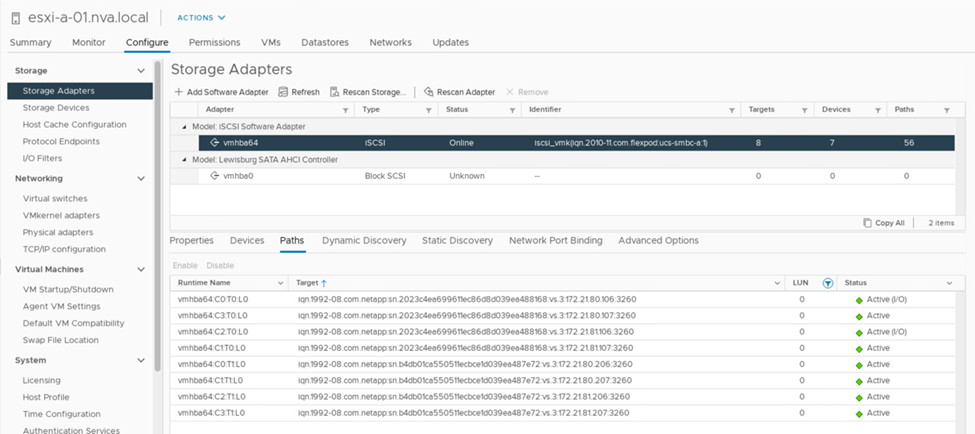
스토리지 컨트롤러 중 하나가 유지보수 또는 업그레이드를 위해 중단되면 다운 컨트롤러에 연결되는 두 개의 경로를 더 이상 사용할 수 없으며 대신 경로 상태가 'dad'로 표시됩니다.
정합성 보장 그룹의 페일오버가 수동 페일오버 테스트 또는 자동 재해 페일오버로 인해 운영 스토리지 클러스터에서 발생하는 경우, 보조 스토리지 클러스터는 SM-BC 정합성 보장 그룹의 LUN에 대한 데이터 서비스를 계속 제공합니다. LUN ID는 보존되고 데이터는 동기식으로 복제되므로 SM-BC 정합성 보장 그룹에 의해 보호되는 모든 ESXi 호스트 부팅 LUN은 원격 스토리지 클러스터에서 계속 사용할 수 있습니다.
VMware vMotion 및 VM/호스트 선호도 테스트
일반 FlexPod VMware 데이터 센터 솔루션은 FC, iSCSI, NVMe 및 NFS와 같은 멀티 프로토콜을 지원하지만 FlexPod SM-BC 솔루션 기능은 일반적으로 비즈니스 크리티컬 솔루션에 사용되는 FC 및 iSCSI SAN 프로토콜을 지원합니다. 이 검증에서는 iSCSI 프로토콜 기반 데이터 저장소와 iSCSI SAN 부팅만 사용합니다.
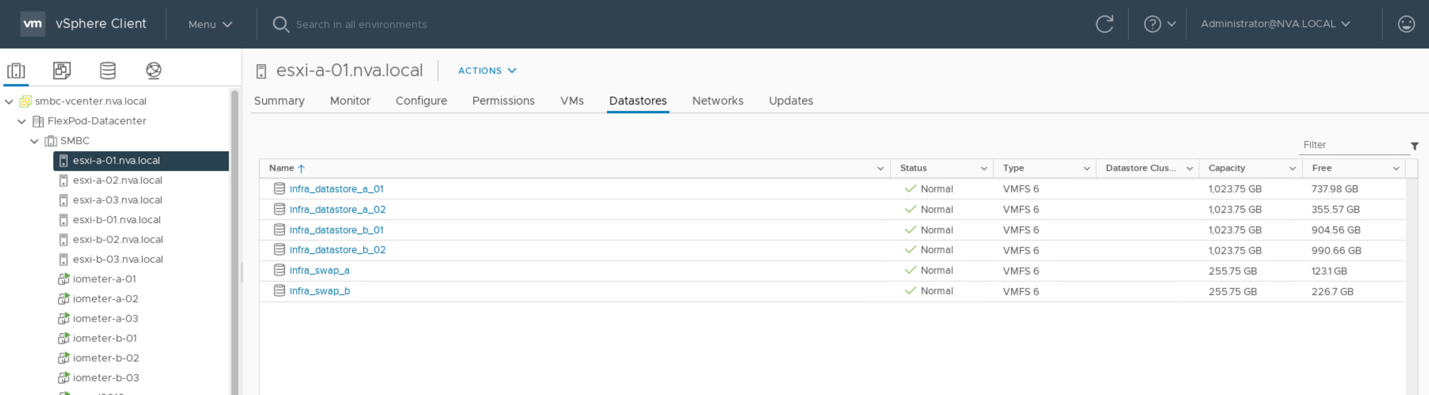
가상 머신이 SM-BC 사이트 중 하나에서 스토리지 서비스를 사용할 수 있도록 하려면 두 사이트의 iSCSI 데이터 저장소를 클러스터의 모든 호스트에서 마운트해야 두 사이트 간에 가상 머신을 마이그레이션할 수 있고 재해 페일오버 시나리오를 수행할 수 있습니다.
사이트 간 SM-BC 정합성 보장 그룹 보호가 필요하지 않은 가상 인프라에서 실행되는 애플리케이션의 경우 NFS 프로토콜 및 NFS 데이터 저장소도 사용할 수 있습니다. 이 경우 비즈니스 크리티컬 애플리케이션이 SM-BC 정합성 보장 그룹에 의해 보호되는 SAN 데이터 저장소를 제대로 사용하여 비즈니스 연속성을 제공하도록 VM용 스토리지를 할당할 때는 주의해야 합니다.
다음 스크린샷은 호스트가 두 사이트에서 iSCSI 데이터 저장소를 마운트하도록 구성되어 있음을 보여 줍니다.
다음 그림과 같이 두 사이트에서 사용 가능한 iSCSI 데이터 저장소 간에 가상 시스템 디스크를 마이그레이션할 수 있습니다. 성능을 고려하려면 로컬 스토리지 클러스터의 스토리지를 사용하여 가상 시스템에 대해 디스크 I/O 지연 시간을 줄이는 것이 좋습니다. 특히 100km 거리당 약 1ms의 물리적 왕복 거리 지연 시간 때문에 두 사이트가 서로 떨어져 있는 경우 더욱 그렇습니다.
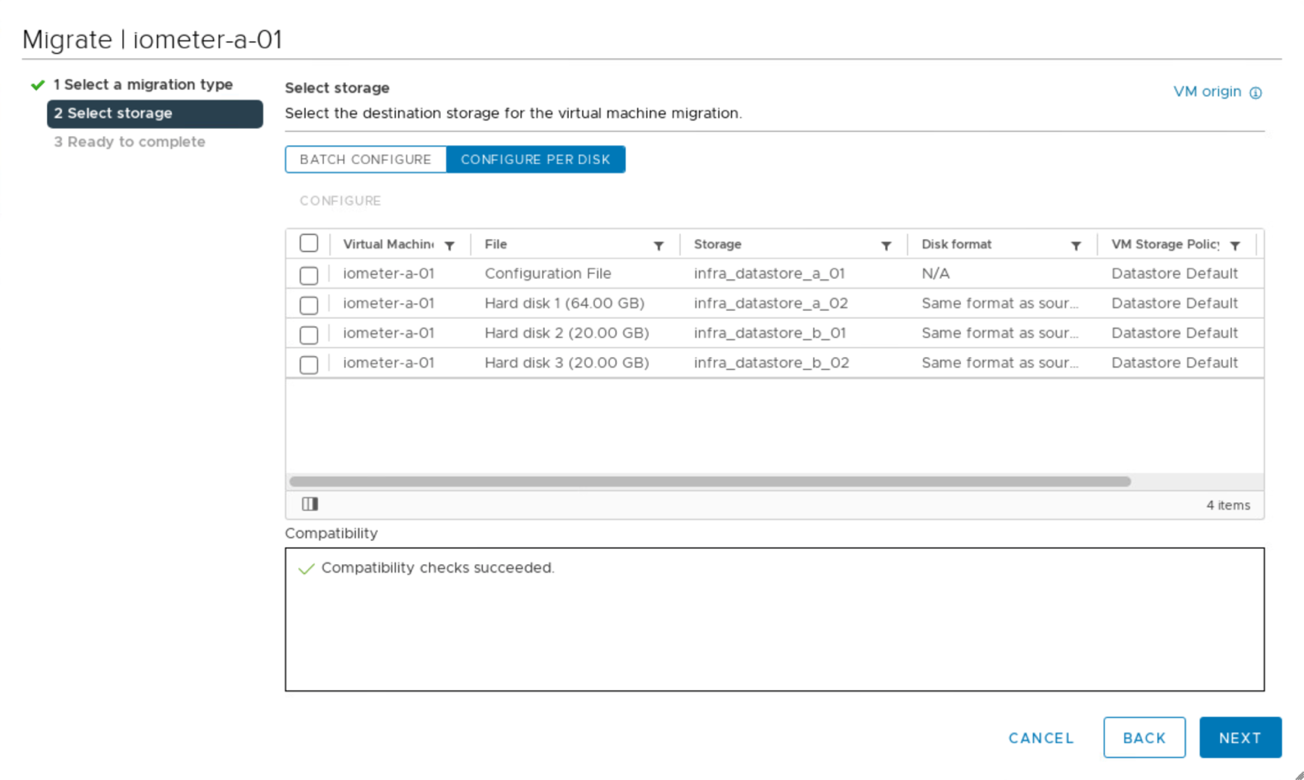
사이트 간 및 동일한 사이트의 다른 호스트에 대한 가상 머신의 vMotion 테스트가 수행되어 성공했습니다. 사이트 간에 가상 머신을 수동으로 마이그레이션한 후에는 VM/호스트 선호도 규칙이 가상 머신을 정상 조건 하에 있는 그룹으로 활성화하고 다시 마이그레이션합니다.
계획된 스토리지 페일오버
스토리지 페일오버 후 솔루션이 제대로 작동하는지 확인하려면 초기 구성 후 솔루션에 대해 계획된 스토리지 페일오버 작업을 수행해야 합니다. 이 테스트는 I/O 중단을 일으킬 수 있는 연결 또는 구성 문제를 식별하는 데 도움이 될 수 있습니다. 연결 또는 구성 문제를 정기적으로 테스트하고 해결하면 실제 사이트 재해가 발생할 때 중단 없는 데이터 서비스를 제공하는 데 도움이 됩니다. 계획된 스토리지 페일오버는 예약된 스토리지 유지보수 작업 전에 사용할 수 있으므로 영향을 받지 않는 사이트에서 데이터 서비스를 제공할 수 있습니다.
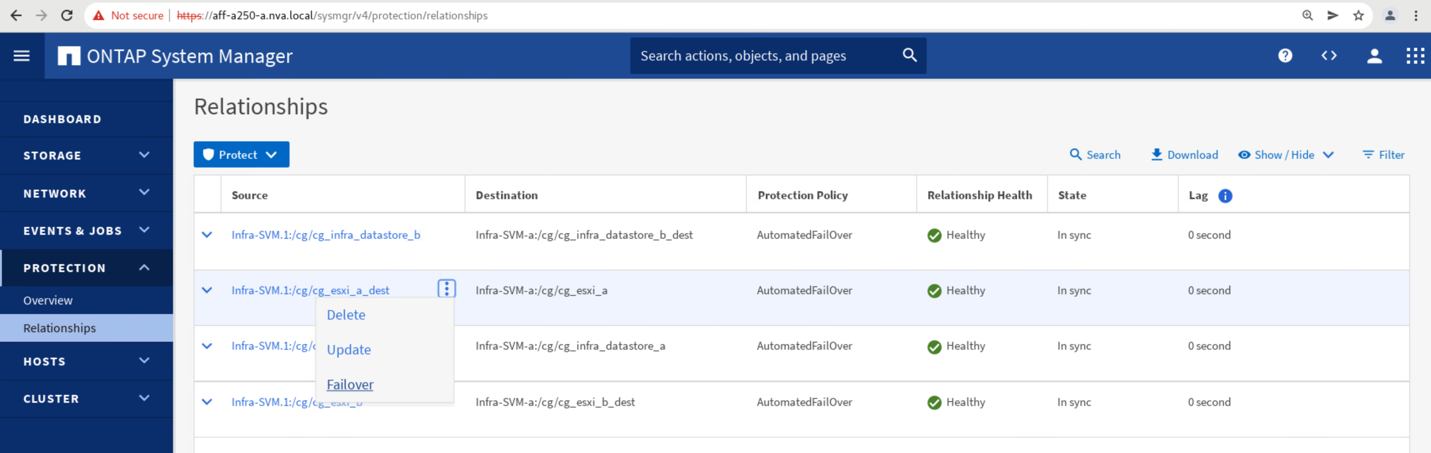
사이트 A 스토리지 데이터 서비스의 수동 페일오버를 사이트 B에 시작하려면 사이트 B ONTAP 시스템 관리자를 사용하여 작업을 수행할 수 있습니다.
-
보호 > 관계 화면으로 이동하여 정합성 보장 그룹 관계 상태가 '동기화 중'인지 확인합니다. 아직 동기화 중인 상태라면 장애 조치를 수행하기 전에 동기화 중 상태가 될 때까지 기다립니다.
-
소스 이름 옆의 점을 확장하고 장애 조치를 클릭합니다.
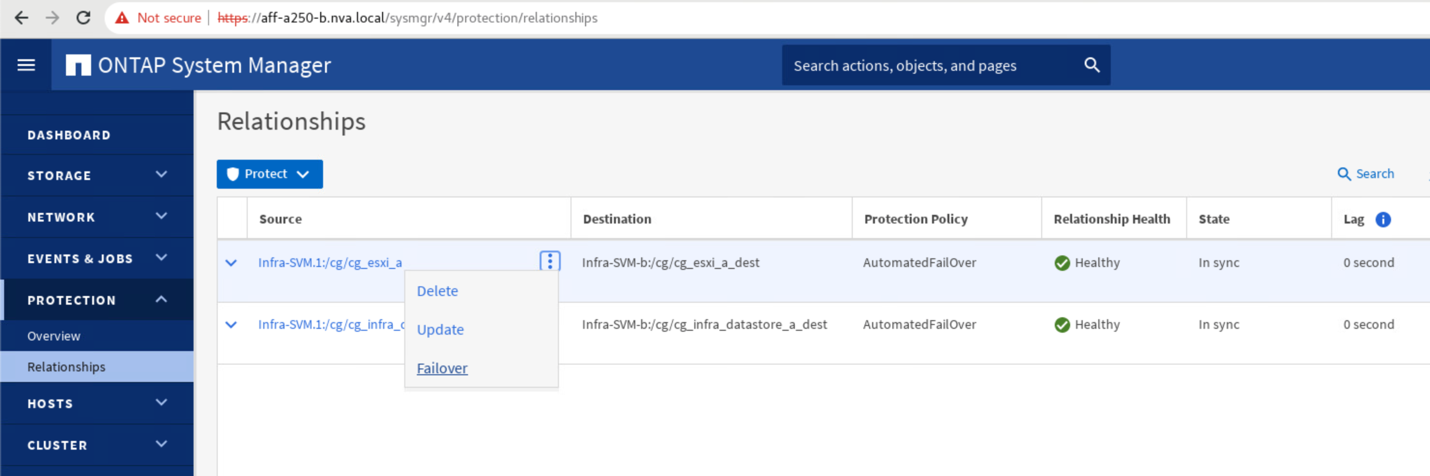
-
작업을 시작할 대체 작동을 확인합니다.
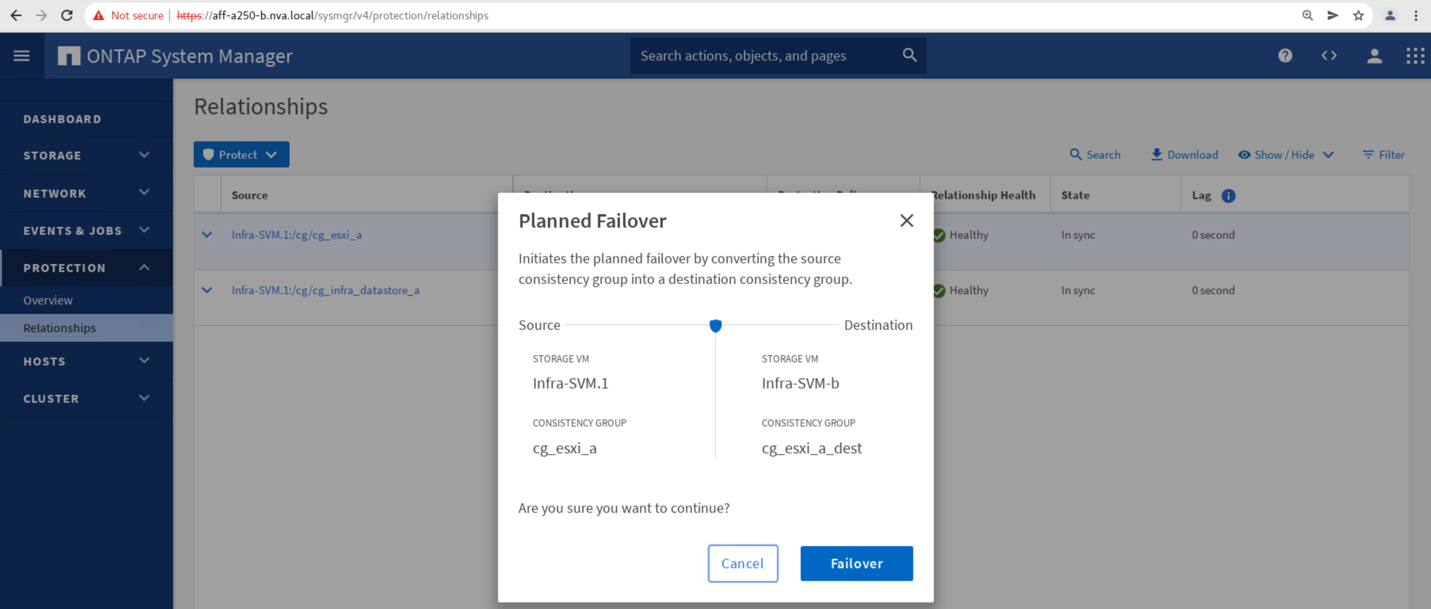
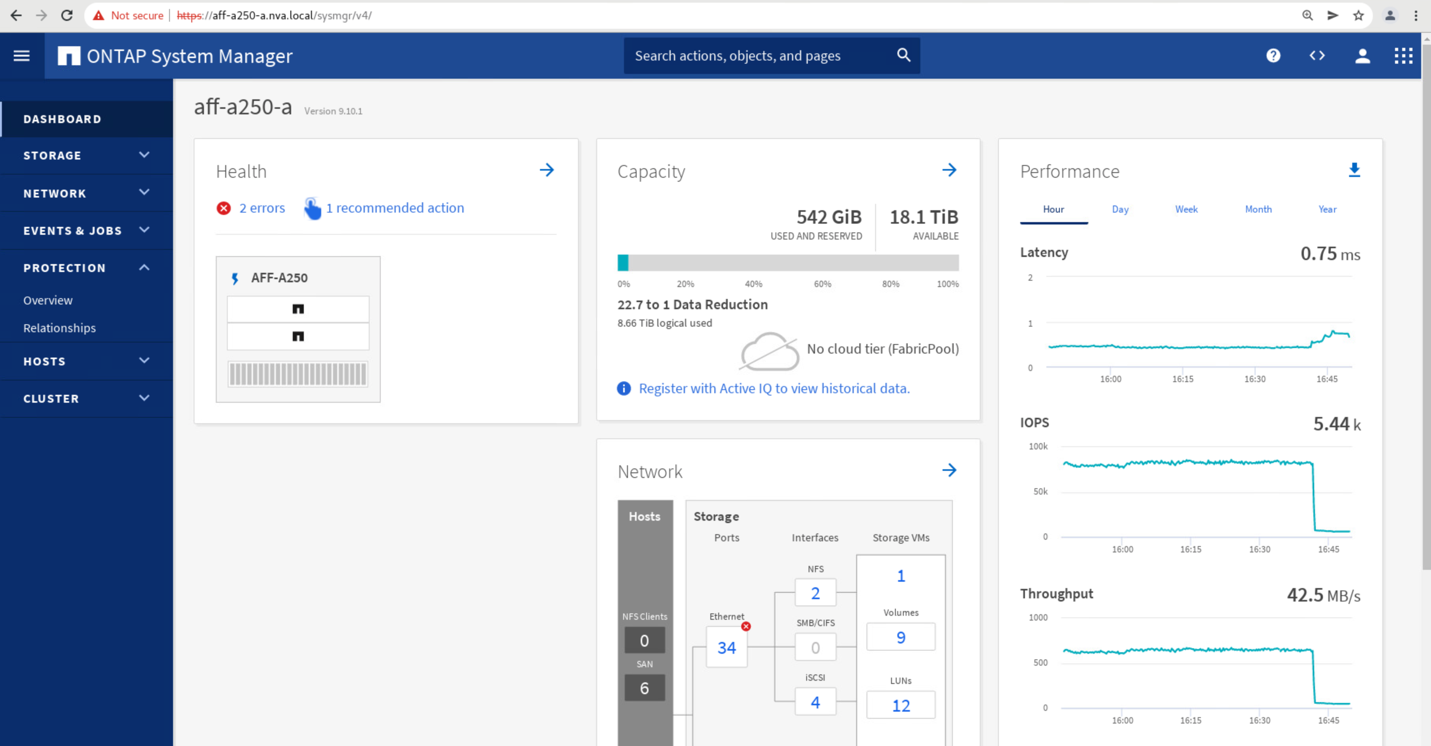
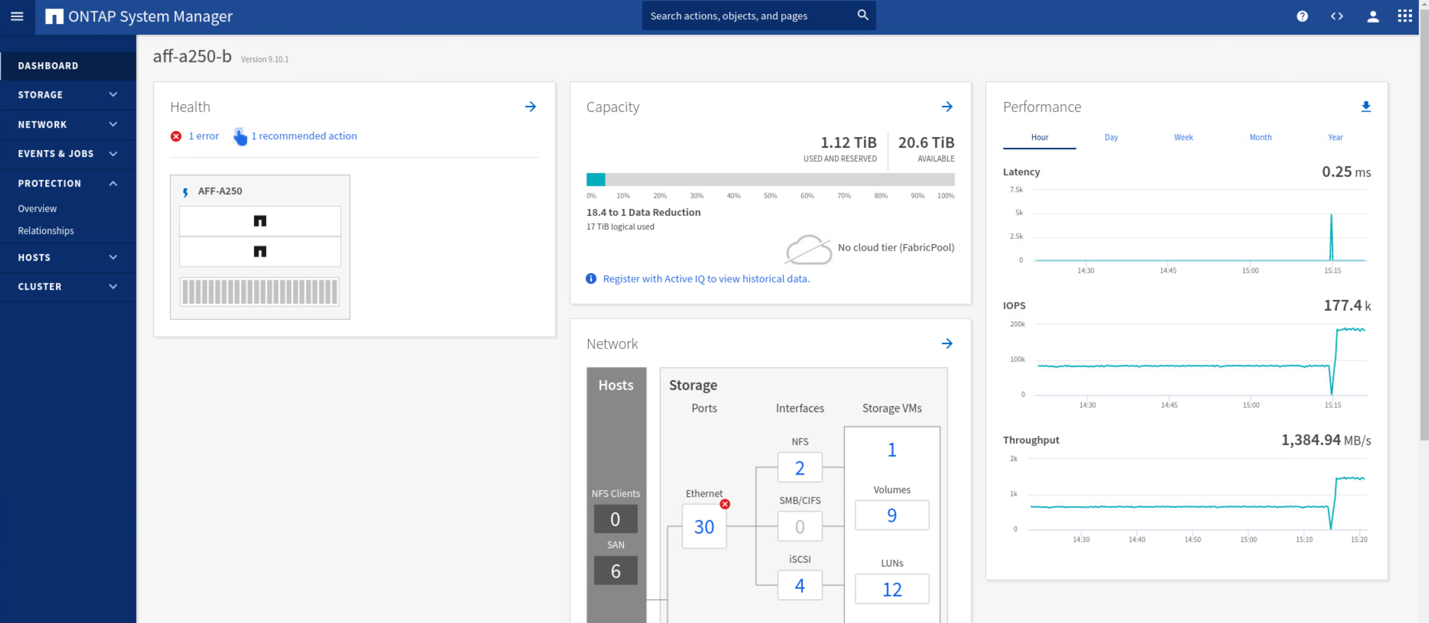
사이트 B System Manager GUI에서 두 정합성 보장 그룹 CG_ESXi_A와 CG_infra_datastore_A의 페일오버를 시작한 직후 사이트 A에서 두 정합성 보장 그룹을 사이트 B로 이동했습니다 그 결과, 사이트의 I/O가 System Manager 성능 창에 표시된 것처럼 크게 감소했습니다.
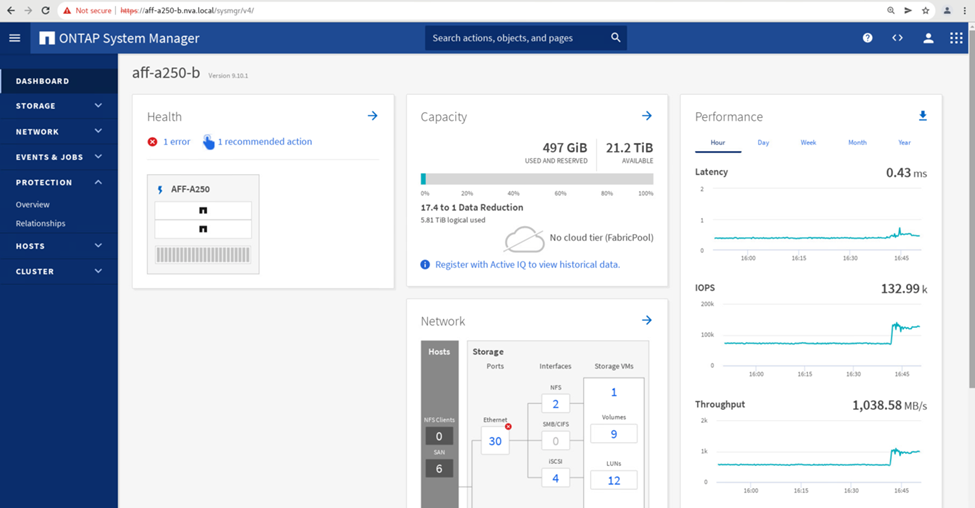
반면, 사이트 B System Manager 대시보드의 성능 창에는 사이트 A에서 약 130K IOP로 이동하는 추가 I/O 덕분에 IOP가 크게 증가한 것으로 표시됩니다. 약 1GB/s의 처리량과 1밀리초 미만의 I/O 지연 시간을 유지했습니다.
I/O가 사이트 A에서 사이트 B로 투명하게 마이그레이션되면 예약된 유지 관리를 위해 사이트 A 스토리지 컨트롤러를 가져올 수 있습니다. 유지 관리 작업 또는 테스트가 완료되고 사이트 A 스토리지 클러스터가 백업 및 작동 가능으로 전환된 후 장애 조치를 수행하기 전에 정합성 보장 그룹 보호 상태가 다시 "동기화 중"으로 바뀔 때까지 기다린 후 사이트 B의 페일오버 입출력을 사이트 A로 되돌립니다 유지 관리 또는 테스트를 위해 사이트가 다운되는 시간이 길어질수록 데이터가 동기화되고 정합성 보장 그룹이 '동기화 중' 상태로 되돌아가는 데 시간이 더 오래 걸립니다.
계획되지 않은 스토리지 페일오버
계획되지 않은 스토리지 페일오버는 실제 재해가 발생하거나 재해 시뮬레이션 중에 발생할 수 있습니다. 예를 들어 사이트 A의 스토리지 시스템에서 정전이 발생하거나, 계획되지 않은 스토리지 페일오버가 트리거되고, 사이트 A LUN에 대한 데이터 서비스가 SM-BC 관계에 의해 보호되면 사이트 B에서 계속 이어지는 그림을 참조하십시오
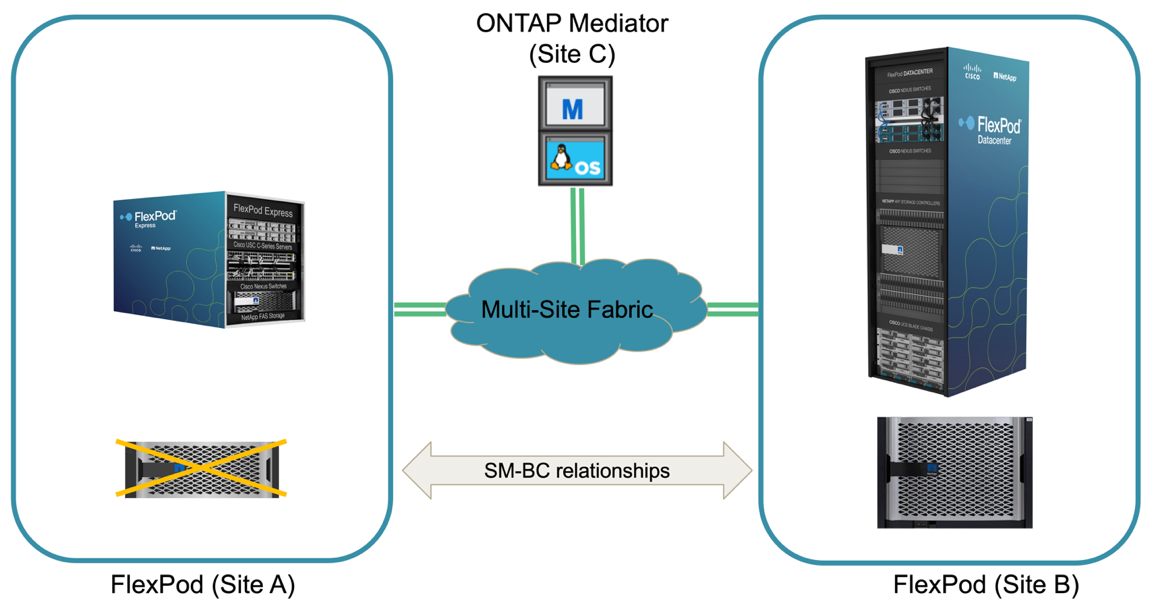
사이트 A에서 스토리지 재해를 시뮬레이션하기 위해 전원 스위치를 물리적으로 끄고 컨트롤러에 대한 전원 공급을 중단하면 사이트 A의 두 스토리지 컨트롤러의 전원을 끌 수 있습니다. 또는 스토리지 컨트롤러 서비스 프로세서의 시스템 전원 관리 명령을 사용하여 컨트롤러의 전원을 끕니다.
사이트의 스토리지 클러스터에 손실이 발생할 경우 사이트 A 스토리지 클러스터에서 데이터 서비스가 갑자기 중지됩니다. 그런 다음, 세 번째 사이트에서 SM-BC 솔루션을 모니터링하는 ONTAP 중재자가 사이트의 스토리지 장애 상태를 감지하고 SM-BC 솔루션에서 자동화된 계획되지 않은 페일오버를 수행할 수 있도록 합니다. 이를 통해 사이트 B 스토리지 컨트롤러는 사이트 A와의 SM-BC 정합성 보장 그룹 관계에 구성된 LUN에 대해 데이터 서비스를 계속할 수 있습니다
애플리케이션 측면에서 운영 체제가 LUN의 경로 상태를 확인한 후 남아 있는 사이트 B 스토리지 컨트롤러에 대한 사용 가능한 경로에서 입출력을 재개하는 동안 데이터 서비스가 잠시 일시 중지됩니다.
검증 테스트 중에 두 사이트의 VM에 있는 IOMeter 툴은 로컬 데이터 저장소에 대한 입출력을 생성합니다. 사이트 A 클러스터의 전원이 꺼진 후 입출력이 잠시 일시 중지되었다가 나중에 다시 시작됩니다. 각 사이트에서 약 80k IOPS와 600MB/s 처리량을 보여 주는 재해 전에 사이트 A와 사이트 B의 스토리지 클러스터 대시보드에 대한 다음 두 그림을 참조하십시오.
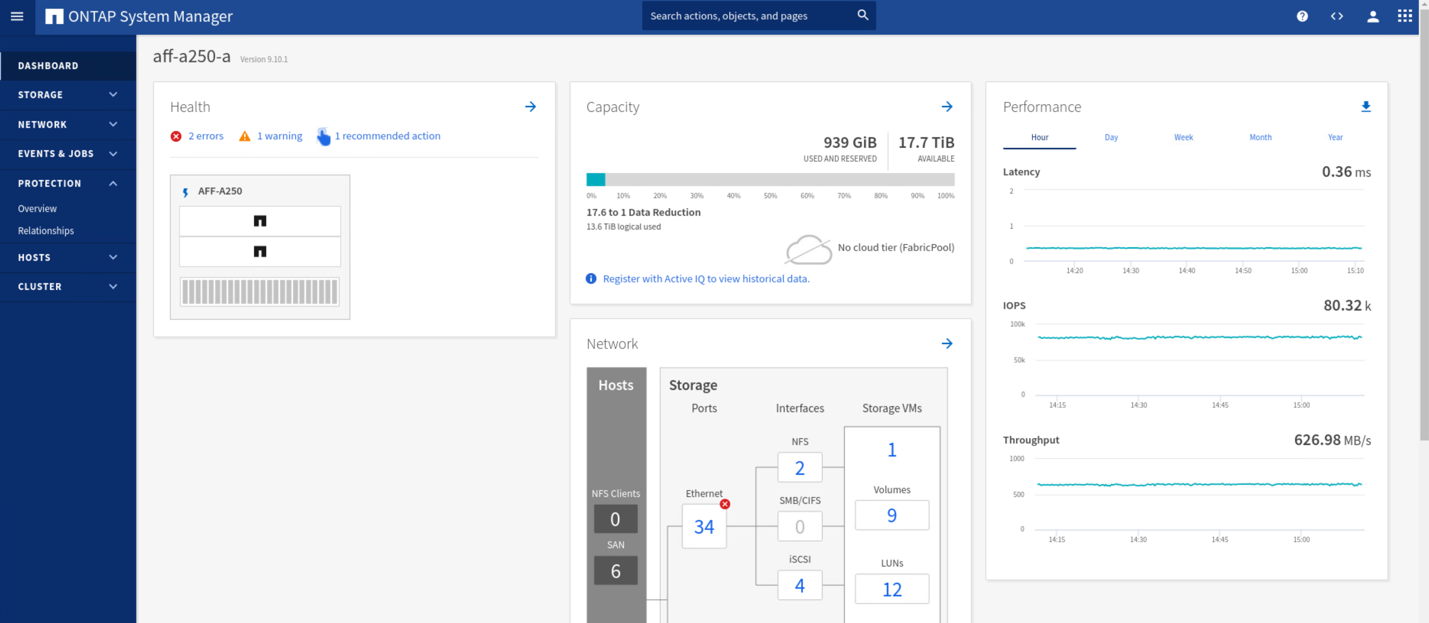
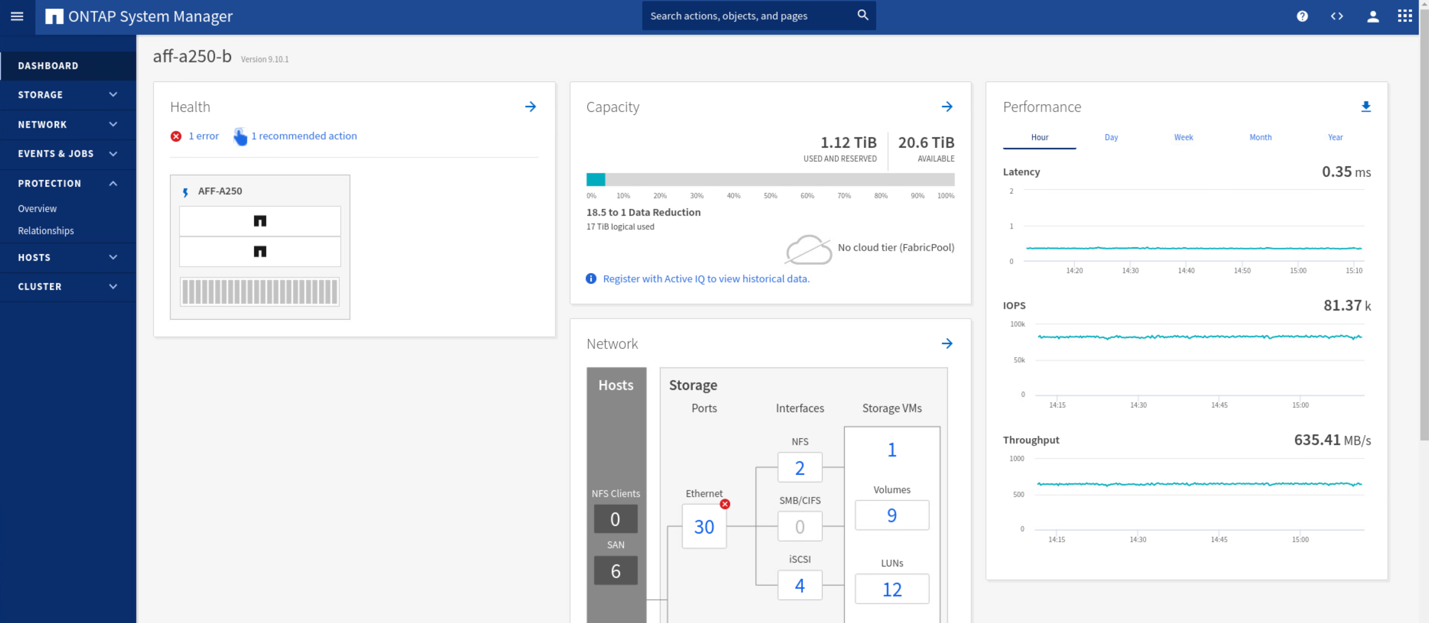
사이트 A에서 스토리지 컨트롤러의 전원을 끈 후 사이트 B 스토리지 컨트롤러 I/O가 급격히 증가하여 사이트 A를 대신하여 추가 데이터 서비스를 제공하는지를 육안으로 확인할 수 있습니다(다음 그림 참조). 또한 IOMeter VM의 GUI는 사이트 A 스토리지 클러스터 중단에도 불구하고 I/O가 계속 유지된다는 것을 보여 주었습니다. SM-BC 관계에 의해 보호되지 않는 LUN에서 백업한 추가 데이터 저장소가 있는 경우 스토리지 재해가 발생할 때 해당 데이터 저장소에 더 이상 액세스할 수 없습니다. 따라서 다양한 애플리케이션 데이터의 비즈니스 요구 사항을 평가하고 비즈니스 연속성을 제공하기 위해 이를 SM-BC 관계에 의해 보호되는 데이터 저장소에 적절히 배치하는 것이 중요합니다.
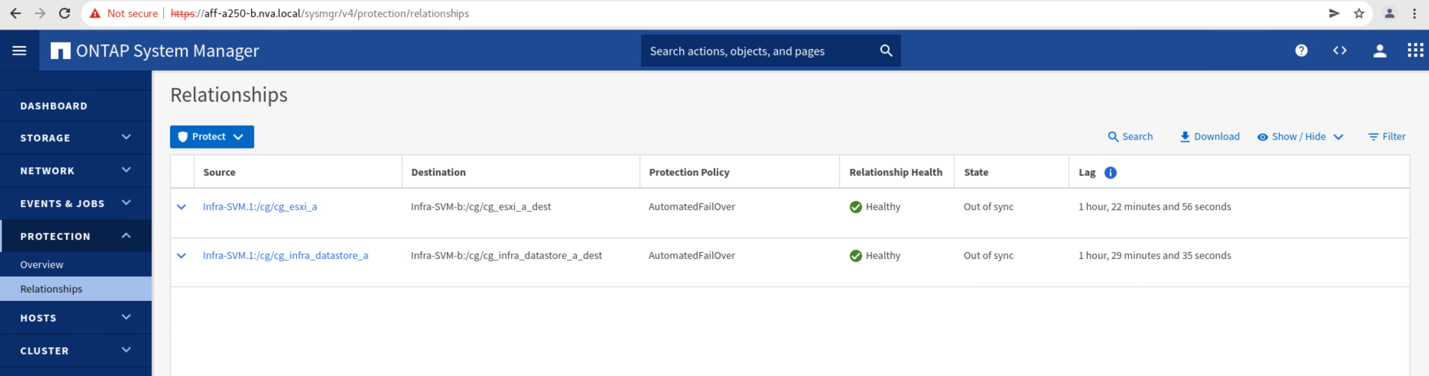
사이트 A 클러스터가 다운된 상태에서 정합성 보장 그룹의 관계는 다음 그림과 같이 동기화 중단 상태로 표시됩니다. 사이트 A의 스토리지 컨트롤러에 대한 전원을 다시 켜면 스토리지 클러스터가 부팅되고 사이트 A와 사이트 B 간의 데이터 동기화가 자동으로 수행됩니다.
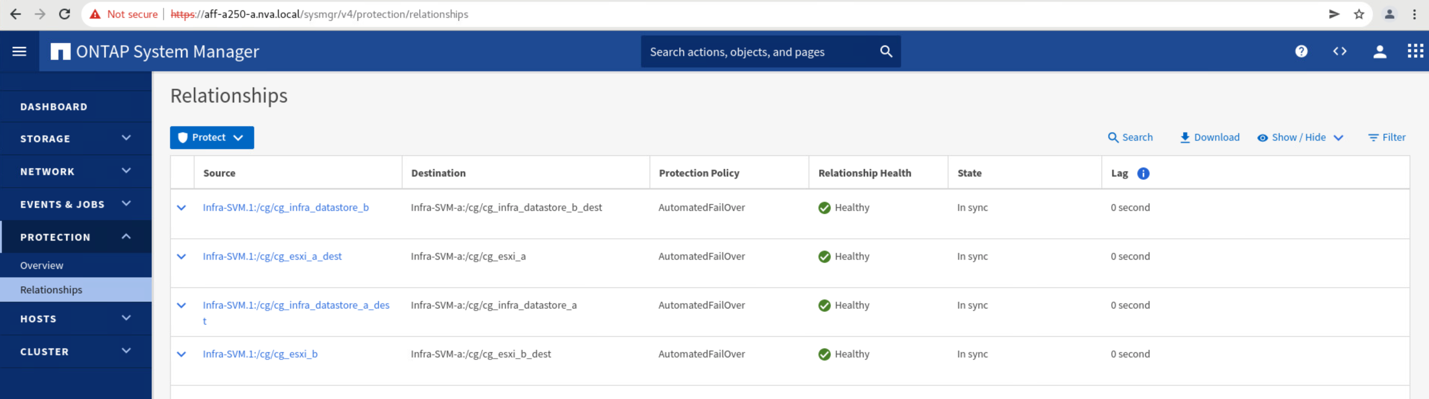
사이트 B의 데이터 서비스를 사이트 A로 다시 반환하기 전에 사이트 A System Manager를 확인하고 SM-BC 관계가 제대로 인식되었는지, 그리고 상태가 다시 동기화되었는지 확인해야 합니다. 정합성 보장 그룹이 동기화 중임을 확인한 후 수동 페일오버 작업을 시작하여 정합성 보장 그룹 관계의 데이터 서비스를 사이트 A로 다시 반환할 수 있습니다
사이트 유지 관리 또는 사이트 장애 완료
현장에 현장 유지 보수, 전력 손실 또는 허리케인이나 지진과 같은 자연 재해로 인한 영향이 있을 수 있습니다. 따라서 FlexPod SM-BC 솔루션이 모든 비즈니스 크리티컬 애플리케이션 및 데이터 서비스에 대해 이러한 장애를 극복할 수 있도록 적절히 구성되도록 계획되었거나 계획되지 않은 사이트 장애 시나리오를 실행하는 것이 중요합니다. 다음 사이트 관련 시나리오가 검증되었습니다.
-
가상 시스템 및 중요 데이터 서비스를 다른 사이트로 마이그레이션하여 사이트 유지 관리 시나리오를 계획했습니다
-
재해 시뮬레이션을 위해 서버 및 스토리지 컨트롤러의 전원을 꺼서 계획되지 않은 사이트 중단 시나리오
계획된 사이트 유지 관리를 위해 사이트를 준비하려면 영향을 받는 가상 시스템을 vMotion과 함께 사이트 외부로 마이그레이션하고, 가상 머신 및 중요 데이터 서비스를 대체 사이트로 마이그레이션하려면 SM-BC 정합성 보장 그룹 관계의 수동 페일오버가 필요합니다. 테스트는 두 가지 다른 순서로 수행되었습니다. 먼저 vMotion을 실행한 후 SM-BC 페일오버 및 SM-BC 페일오버 후에 vMotion을 먼저 실행하여 가상 머신이 계속 실행되고 데이터 서비스가 중단되지 않는지 확인했습니다.
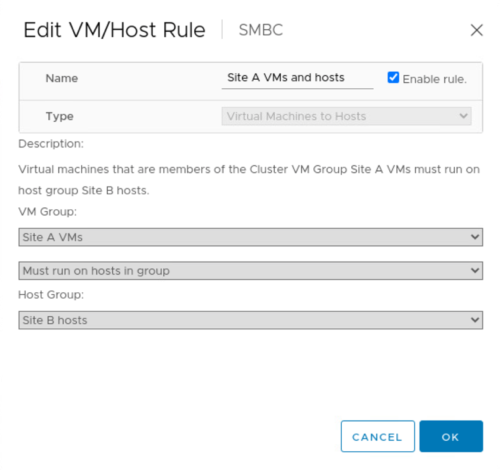
계획된 마이그레이션을 수행하기 전에 VM/호스트 선호도 규칙을 업데이트하여 현재 사이트에서 실행 중인 VM이 유지 보수 중인 사이트에서 자동으로 마이그레이션되도록 합니다. 다음 스크린샷은 사이트 A에서 사이트 B로 자동으로 마이그레이션할 VM에 대한 사이트 A VM/호스트 선호도 규칙을 수정하는 예를 보여 줍니다. 이제 사이트 B에서 VM을 실행해야 하는 대신 VM을 수동으로 마이그레이션할 수 있도록 선호도 규칙을 일시적으로 비활성화할 수도 있습니다.
가상 머신 및 스토리지 서비스를 마이그레이션한 후에는 서버, 스토리지 컨트롤러, 디스크 쉘프 및 스위치의 전원을 끄고 필요한 사이트 유지 관리 작업을 수행할 수 있습니다. 사이트 유지 관리가 완료되고 FlexPod 인스턴스가 백업되면 VM에 대한 호스트 그룹 선호도를 변경하여 원래 사이트로 돌아갈 수 있습니다. 그런 다음 "그룹의 호스트에서 실행해야 함" VM/호스트 사이트 선호도 규칙을 다시 "그룹의 호스트에서 실행해야 함"으로 변경하여 재해가 발생할 경우 다른 사이트의 호스트에서 가상 시스템을 실행할 수 있도록 해야 합니다. 검증 테스트를 위해 모든 가상 시스템이 다른 사이트로 성공적으로 마이그레이션되었으며, SM-BC 관계에 대한 페일오버를 수행한 후에도 데이터 서비스가 문제 없이 계속됩니다.
계획되지 않은 사이트 재해 시뮬레이션의 경우 서버 및 스토리지 컨트롤러의 전원을 꺼서 사이트 재해를 시뮬레이션했습니다. VMware HA 기능은 다운된 가상 시스템을 감지하고 정상 작동하는 사이트에서 해당 가상 시스템을 다시 시작합니다. 또한 세 번째 사이트에서 실행 중인 ONTAP 중재자가 사이트 장애를 감지하고 정상 작동하는 사이트가 페일오버를 시작하고 필요에 따라 중단 사이트에 데이터 서비스를 제공하기 시작합니다.
다음 스크린샷은 사이트의 스토리지 재해 시뮬레이션을 위해 스토리지 컨트롤러의 서비스 프로세서 CLI를 사용하여 사이트의 전원을 갑자기 끄는 것을 보여 줍니다.
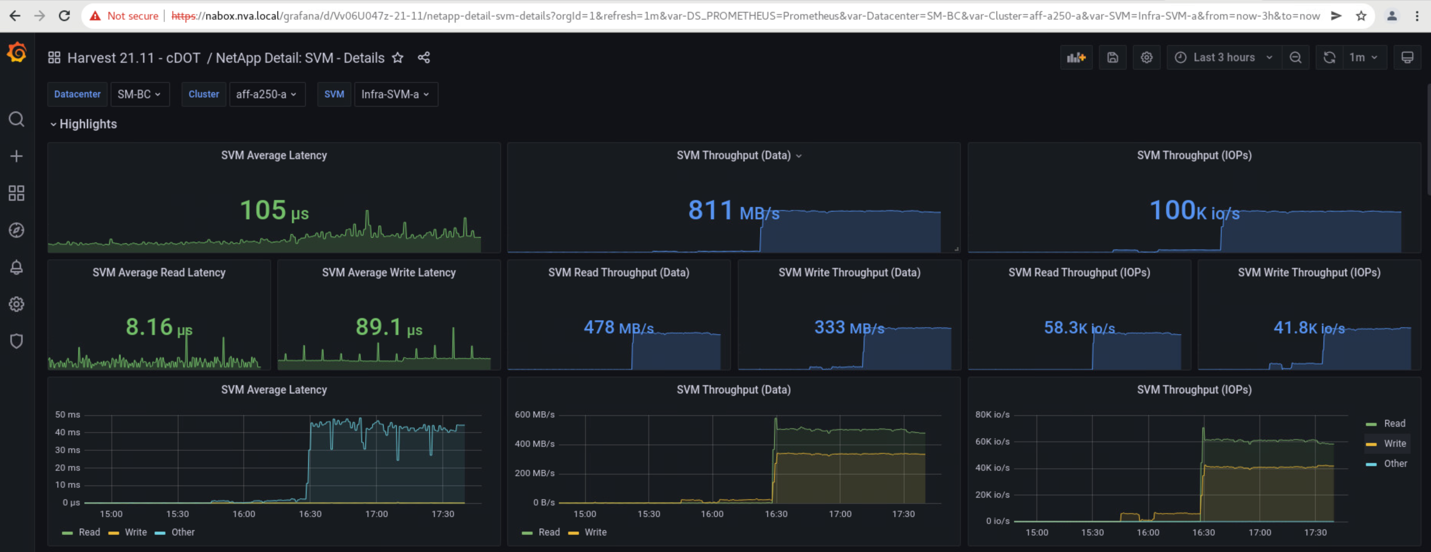
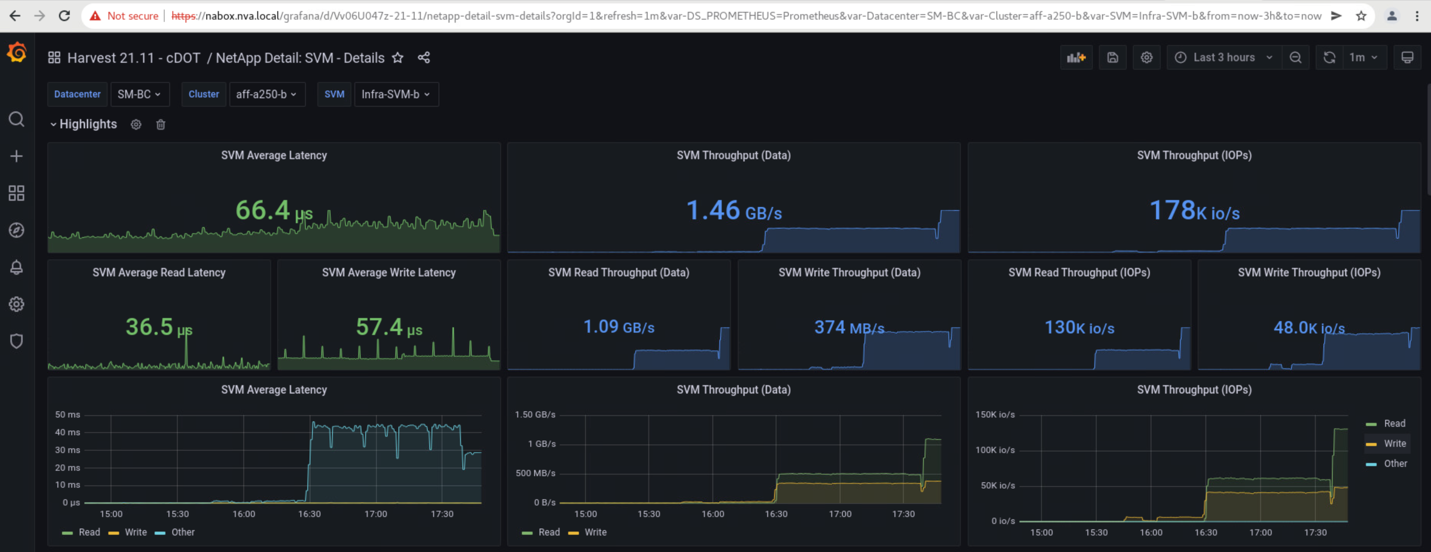
NetApp Harvest 데이터 수집 툴에서 캡처되고 NAbox 모니터링 도구의 Grafana 대시보드에 표시되는 스토리지 클러스터의 스토리지 가상 머신 대시보드는 다음 두 개의 스크린샷에 나와 있습니다. IOPS 및 처리량 그래프의 오른쪽에서 볼 수 있듯이, 사이트 B 클러스터는 사이트 A 클러스터가 다운된 직후 클러스터 A 스토리지 워크로드를 선택합니다.
Microsoft SQL Server를 참조하십시오
Microsoft SQL Server는 엔터프라이즈 IT를 위해 널리 채택되고 배포된 데이터베이스 플랫폼입니다. Microsoft SQL Server 2019 릴리스는 관계형 및 분석 엔진에 많은 새로운 기능과 향상된 기능을 제공합니다. 이 솔루션은 사내, 클라우드에서 실행되는 애플리케이션과 하이브리드 퍼블릭 클라우드 모두에서 2가지 워크로드를 지원합니다. 또한 Windows, Linux 및 컨테이너를 포함한 여러 플랫폼에 배포할 수 있습니다.
FlexPod SM-BC 솔루션의 비즈니스 크리티컬 워크로드 검증에 따라, Windows Server 2022 VM에 설치된 Microsoft SQL Server 2019가 SM-BC 계획 및 계획되지 않은 스토리지 페일오버 테스트를 위한 IOMeter VM과 함께 포함됩니다. Windows Server 2022 VM에서는 SQL Server를 관리하기 위해 SQL Server Management Studio가 설치됩니다. 테스트를 위해 HammerDB 데이터베이스 도구를 사용하여 데이터베이스 트랜잭션을 생성합니다.
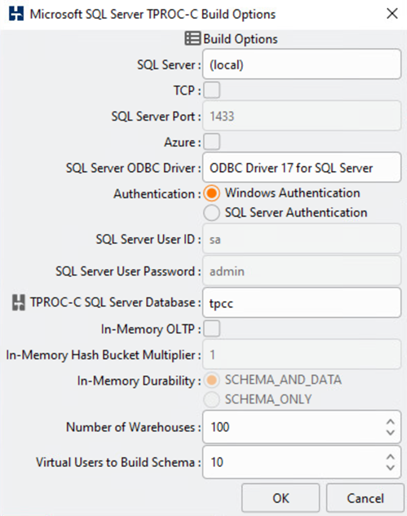
Microsoft SQL Server TPROC-C 워크로드를 사용하여 테스트하도록 HammerDB 데이터베이스 테스트 도구를 구성했습니다. 스키마 빌드 구성의 경우 다음 스크린샷과 같이 10명의 가상 사용자가 있는 100개의 웨어하우스를 사용하도록 옵션이 업데이트되었습니다.
스키마 빌드 옵션이 업데이트된 후 스키마 빌드 프로세스가 시작되었습니다. 몇 분 후에 시스템 프로세서 CLI 명령을 사용하여 두 노드 AFF A250 스토리지 클러스터의 두 노드 전원을 동시에 꺼서 예정되지 않은 사이트 B 스토리지 클러스터 장애가 발생했습니다.
데이터베이스 트랜잭션을 잠시 일시 중지한 후 재해 복구를 위한 자동 페일오버가 시작되고 트랜잭션이 다시 시작되었습니다. 다음 스크린샷은 해당 시간에 대한 HammerDB 트랜잭션 카운터 스크린샷을 보여 줍니다. Microsoft SQL Server의 데이터베이스는 일반적으로 사이트 B 스토리지 클러스터에 상주하므로 사이트 B의 스토리지가 다운된 후 트랜잭션이 잠시 일시 중지되었다가 자동 페일오버가 발생한 후 다시 시작됩니다.
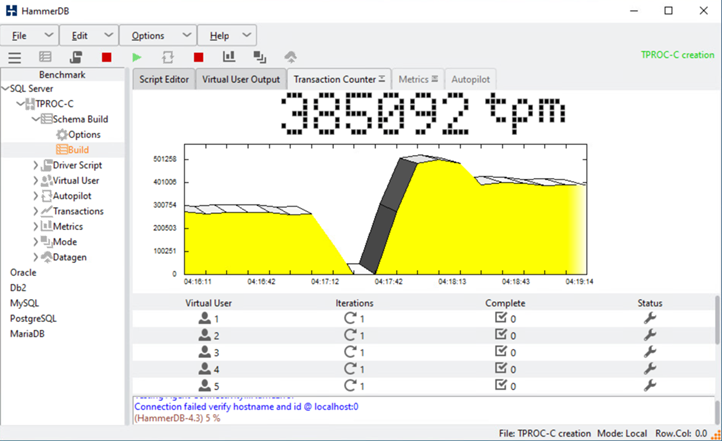
Storge 클러스터 메트릭은 NetApp Harvest 모니터링 툴이 설치된 NAbox 툴을 사용하여 캡처되었습니다. 결과는 스토리지 가상 머신 및 기타 스토리지 개체에 대한 사전 정의된 Grafana 대시보드에 표시됩니다. 대시보드는 사이트 B와 사이트 A에 대해 분리된 읽기 및 쓰기 통계와 함께 지연 시간, 처리량, IOPS 및 추가 세부 정보에 대한 매트릭스를 제공합니다
이 스크린샷은 사이트 B 스토리지 클러스터에 대한 NAbox Grafana 성능 대시보드를 보여줍니다.
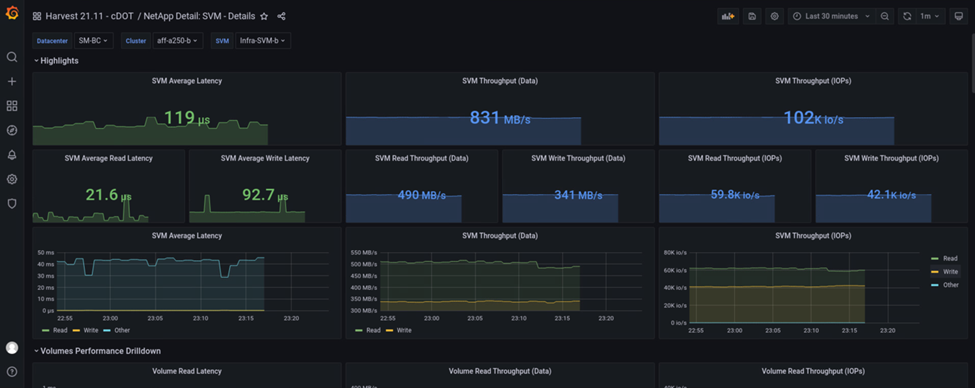
사이트 B 스토리지 클러스터의 IOPS는 재해가 발생하기 전에 약 100K IOPS 였습니다. 그런 다음, 성능 메트릭이 재해로 인해 그래프 오른쪽에서 0으로 급격히 하락하는 것을 보였습니다. 사이트 B 스토리지 클러스터가 다운되었기 때문에 재해가 발생한 후 사이트 B 클러스터에서 아무것도 수집되지 않았습니다.
반면 사이트 A 스토리지 클러스터의 IOPS는 자동 페일오버 후 사이트 B에서 추가 워크로드를 선택했습니다. 다음 스크린샷에서는 IOPS 및 처리량 그래프의 오른쪽에 추가 워크로드를 쉽게 볼 수 있습니다. 이 그래프에는 사이트 A 스토리지 클러스터의 NAbox Grafana 성능 대시보드가 나와 있습니다.
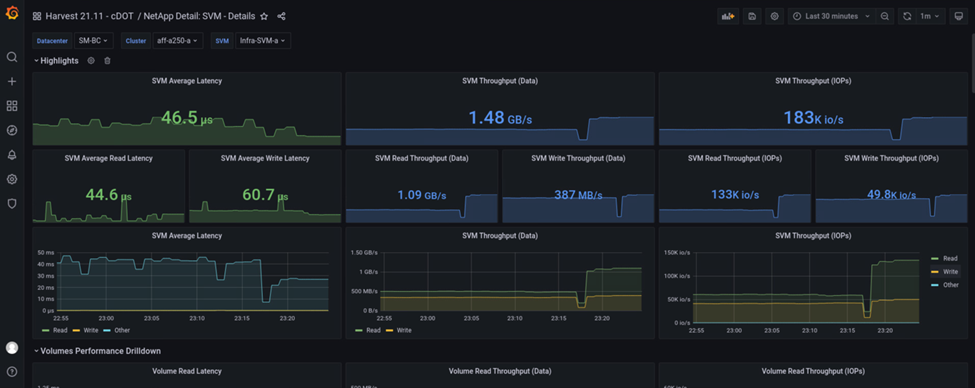
위의 스토리지 재해 테스트 시나리오에서는 데이터베이스가 상주하는 사이트 B에서 Microsoft SQL Server 워크로드가 전체 스토리지 클러스터 중단 시에도 계속 유지될 수 있다는 것이 확인되었습니다. 애플리케이션은 재해가 감지되고 페일오버가 발생한 후 사이트에서 스토리지 클러스터로 제공되는 데이터 서비스를 투명하게 사용했습니다.
컴퓨팅 계층에서 특정 사이트에서 실행 중인 VM에 호스트 장애가 발생하면 VM은 VMware HA 기능을 통해 자동으로 다시 시작하도록 설계되어 있습니다. 전체 사이트 컴퓨팅 중단을 위해 VM/호스트 선호도 규칙을 통해 남아 있는 사이트에서 VM을 다시 시작할 수 있습니다. 하지만 비즈니스 크리티컬 애플리케이션에서 무중단 서비스를 제공하려면 애플리케이션 다운타임을 방지하기 위해 Microsoft Failover Cluster 또는 Kubernetes 컨테이너 기반 애플리케이션 아키텍처와 같은 애플리케이션 기반 클러스터링이 필요합니다. 이 기술 보고서의 범위를 벗어나는 애플리케이션 기반 클러스터링의 구현 방법은 관련 문서를 참조하십시오.