

2부 - SageMaker에서 모델 학습을 위한 데이터 소스로 AWS Amazon FSx for NetApp ONTAP (FSx ONTAP) 활용
 변경 제안
변경 제안
이 문서는 SageMaker에서 PyTorch 모델을 학습하기 위해 Amazon FSx for NetApp ONTAP (FSx ONTAP)을 사용하는 방법에 대한 튜토리얼로, 특히 타이어 품질 분류 프로젝트에 대한 내용입니다.
소개
이 튜토리얼에서는 컴퓨터 비전 분류 프로젝트의 실제 사례를 제시하고, SageMaker 환경 내에서 FSx ONTAP 데이터 소스로 활용하는 ML 모델을 구축하는 실무 경험을 제공합니다. 이 프로젝트는 딥러닝 프레임워크인 PyTorch를 사용하여 타이어 이미지를 기반으로 타이어 품질을 분류하는 데 중점을 두고 있습니다. Amazon SageMaker에서 FSx ONTAP 데이터 소스로 사용하여 머신 러닝 모델을 개발하는 데 중점을 둡니다.
FSx ONTAP 무엇입니까?
Amazon FSx ONTAP AWS가 제공하는 완전 관리형 스토리지 솔루션입니다. NetApp의 ONTAP 파일 시스템을 활용하여 안정적이고 고성능의 스토리지를 제공합니다. NFS, SMB, iSCSI와 같은 프로토콜을 지원하므로 다양한 컴퓨팅 인스턴스와 컨테이너에서 원활하게 액세스할 수 있습니다. 이 서비스는 뛰어난 성능을 제공하고 빠르고 효율적인 데이터 작업을 보장하도록 설계되었습니다. 또한 높은 가용성과 내구성을 제공하여 데이터에 항상 접근하고 보호할 수 있습니다. 또한 Amazon FSx ONTAP 의 저장 용량은 확장 가능하므로 필요에 따라 쉽게 조정할 수 있습니다.
필수 조건
네트워크 환경
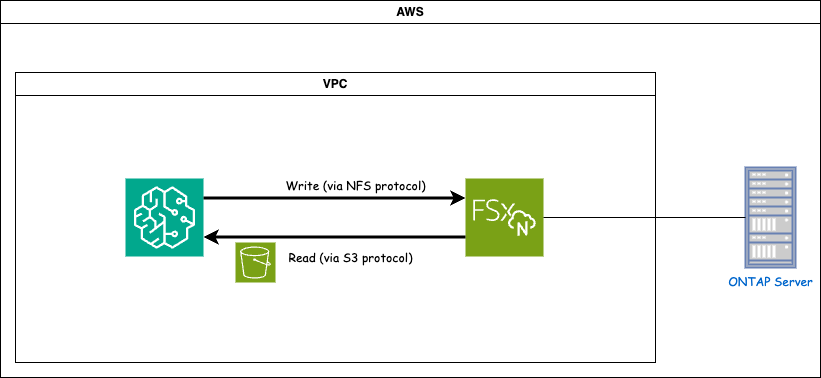
FSx ONTAP (Amazon FSx ONTAP)은 AWS 스토리지 서비스입니다. 여기에는 NetApp ONTAP 시스템에서 실행되는 파일 시스템과 이에 연결되는 AWS 관리 시스템 가상 머신(SVM)이 포함됩니다. 제공된 다이어그램에서 AWS가 관리하는 NetApp ONTAP 서버는 VPC 외부에 있습니다. SVM은 SageMaker와 NetApp ONTAP 시스템 사이의 중개자 역할을 하며, SageMaker로부터 작업 요청을 수신하여 기본 스토리지로 전달합니다. FSx ONTAP 에 액세스하려면 SageMaker가 FSx ONTAP 배포와 동일한 VPC 내에 있어야 합니다. 이 구성은 SageMaker와 FSx ONTAP 간의 통신과 데이터 액세스를 보장합니다.
데이터 액세스
실제 상황에서 데이터 과학자는 일반적으로 FSx ONTAP 에 저장된 기존 데이터를 활용하여 머신 러닝 모델을 구축합니다. 그러나 데모 목적으로, FSx ONTAP 파일 시스템은 생성된 후 처음에는 비어 있으므로 수동으로 교육 데이터를 업로드해야 합니다. 이는 FSx ONTAP SageMaker에 볼륨으로 마운트하여 달성할 수 있습니다. 파일 시스템이 성공적으로 마운트되면 마운트된 위치에 데이터 세트를 업로드하여 SageMaker 환경 내에서 모델을 학습할 수 있습니다. 이 접근 방식을 사용하면 SageMaker를 사용하여 모델을 개발하고 학습하는 동안 FSx ONTAP 의 저장 용량과 기능을 활용할 수 있습니다.
데이터 읽기 프로세스에는 FSx ONTAP 개인 S3 버킷으로 구성하는 작업이 포함됩니다. 자세한 구성 지침을 알아보려면 다음을 참조하세요."1부 - Amazon FSx for NetApp ONTAP (FSx ONTAP)을 AWS SageMaker에 개인 S3 버킷으로 통합"
통합 개요
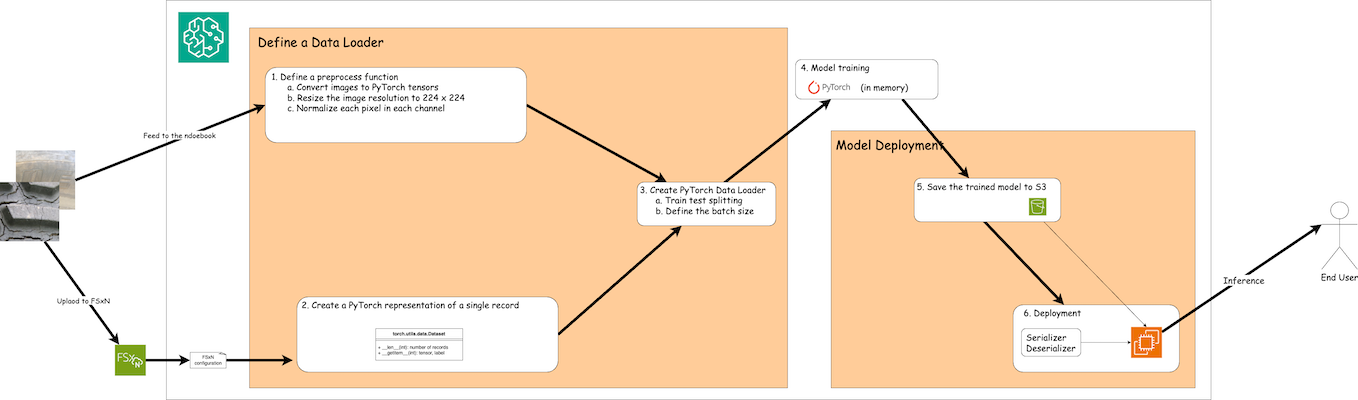
FSx ONTAP 의 학습 데이터를 사용하여 SageMaker에서 딥러닝 모델을 구축하는 워크플로는 데이터 로더 정의, 모델 학습, 배포의 세 가지 주요 단계로 요약할 수 있습니다. 높은 수준에서 이러한 단계는 MLOps 파이프라인의 기반을 형성합니다. 그러나 각 단계에는 포괄적인 구현을 위한 여러 가지 세부적인 하위 단계가 포함됩니다. 이러한 하위 단계에는 데이터 전처리, 데이터 세트 분할, 모델 구성, 하이퍼파라미터 튜닝, 모델 평가, 모델 배포와 같은 다양한 작업이 포함됩니다. 이러한 단계를 거치면 SageMaker 환경 내에서 FSx ONTAP 의 학습 데이터를 사용하여 딥 러닝 모델을 구축하고 배포하는 철저하고 효과적인 프로세스가 보장됩니다.
단계별 통합
데이터 Loader
PyTorch 딥러닝 네트워크를 데이터로 학습시키기 위해, 데이터 공급을 용이하게 하는 데이터 로더가 만들어졌습니다. 데이터 로더는 배치 크기를 정의할 뿐만 아니라 배치 내의 각 레코드를 읽고 사전 처리하는 절차도 결정합니다. 데이터 로더를 구성하면 일괄적으로 데이터를 처리하여 딥 러닝 네트워크를 학습시킬 수 있습니다.
데이터 로더는 3개 부분으로 구성됩니다.
전처리 기능
from torchvision import transforms
preprocess = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((224,224)),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])위의 코드 조각은 torchvision.transforms 모듈을 사용하여 이미지 전처리 변환의 정의를 보여줍니다. 이 튜토리얼에서는 일련의 변환을 적용하기 위해 전처리 객체를 생성합니다. 첫째, ToTensor() 변환은 이미지를 텐서 표현으로 변환합니다. 이후, Resize224,224 변환은 이미지 크기를 224x224픽셀의 고정 크기로 조정합니다. 마지막으로, Normalize() 변환은 각 채널의 평균을 빼고 표준 편차로 나누어 텐서 값을 정규화합니다. 정규화에 사용되는 평균 및 표준 편차 값은 일반적으로 사전 학습된 신경망 모델에 사용됩니다. 전반적으로 이 코드는 이미지 데이터를 텐서로 변환하고, 크기를 조정하고, 픽셀 값을 정규화하여 추가 처리나 사전 학습된 모델에 입력할 수 있도록 이미지 데이터를 준비합니다.
PyTorch 데이터셋 클래스
import torch
from io import BytesIO
from PIL import Image
class FSxNImageDataset(torch.utils.data.Dataset):
def __init__(self, bucket, prefix='', preprocess=None):
self.image_keys = [
s3_obj.key
for s3_obj in list(bucket.objects.filter(Prefix=prefix).all())
]
self.preprocess = preprocess
def __len__(self):
return len(self.image_keys)
def __getitem__(self, index):
key = self.image_keys[index]
response = bucket.Object(key)
label = 1 if key[13:].startswith('defective') else 0
image_bytes = response.get()['Body'].read()
image = Image.open(BytesIO(image_bytes))
if image.mode == 'L':
image = image.convert('RGB')
if self.preprocess is not None:
image = self.preprocess(image)
return image, label이 클래스는 데이터 세트의 총 레코드 수를 얻는 기능을 제공하고 각 레코드에 대한 데이터를 읽는 방법을 정의합니다. getitem 함수 내에서 코드는 boto3 S3 버킷 객체를 활용하여 FSx ONTAP 에서 바이너리 데이터를 검색합니다. FSx ONTAP 에서 데이터에 액세스하는 코드 스타일은 Amazon S3에서 데이터를 읽는 것과 비슷합니다. 이후 설명에서는 개인 S3 객체 *버킷*의 생성 과정에 대해 자세히 설명합니다.
FSx ONTAP 개인 S3 저장소로 사용
seed = 77 # Random seed
bucket_name = '<Your ONTAP bucket name>' # The bucket name in ONTAP
aws_access_key_id = '<Your ONTAP bucket key id>' # Please get this credential from ONTAP
aws_secret_access_key = '<Your ONTAP bucket access key>' # Please get this credential from ONTAP
fsx_endpoint_ip = '<Your FSx ONTAP IP address>' # Please get this IP address from FSXNimport boto3
# Get session info
region_name = boto3.session.Session().region_name
# Initialize Fsxn S3 bucket object
# --- Start integrating SageMaker with FSXN ---
# This is the only code change we need to incorporate SageMaker with FSXN
s3_client: boto3.client = boto3.resource(
's3',
region_name=region_name,
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key,
use_ssl=False,
endpoint_url=f'http://{fsx_endpoint_ip}',
config=boto3.session.Config(
signature_version='s3v4',
s3={'addressing_style': 'path'}
)
)
# s3_client = boto3.resource('s3')
bucket = s3_client.Bucket(bucket_name)
# --- End integrating SageMaker with FSXN ---SageMaker에서 FSx ONTAP 에서 데이터를 읽으려면 S3 프로토콜을 사용하여 FSx ONTAP 저장소를 가리키는 핸들러가 생성됩니다. 이를 통해 FSx ONTAP 개인 S3 버킷으로 처리할 수 있습니다. 핸들러 구성에는 FSx ONTAP SVM의 IP 주소, 버킷 이름 및 필요한 자격 증명을 지정하는 것이 포함됩니다. 이러한 구성 항목을 얻는 것에 대한 포괄적인 설명은 다음 문서를 참조하십시오."1부 - Amazon FSx for NetApp ONTAP (FSx ONTAP)을 AWS SageMaker에 개인 S3 버킷으로 통합" .
위에서 언급한 예에서 버킷 객체는 PyTorch 데이터세트 객체를 인스턴스화하는 데 사용됩니다. 데이터 세트 객체에 대해서는 다음 섹션에서 자세히 설명하겠습니다.
PyTorch 데이터 Loader
from torch.utils.data import DataLoader
torch.manual_seed(seed)
# 1. Hyperparameters
batch_size = 64
# 2. Preparing for the dataset
dataset = FSxNImageDataset(bucket, 'dataset/tyre', preprocess=preprocess)
train, test = torch.utils.data.random_split(dataset, [1500, 356])
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)제공된 예에서는 배치 크기가 64로 지정되어 각 배치에 64개의 레코드가 포함된다는 것을 나타냅니다. PyTorch Dataset 클래스, 전처리 함수, 학습 배치 크기를 결합하여 학습을 위한 데이터 로더를 얻습니다. 이 데이터 로더는 학습 단계 동안 데이터 세트를 일괄적으로 반복하는 과정을 용이하게 합니다.
모델 학습
from torch import nn
class TyreQualityClassifier(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3,32,(3,3)),
nn.ReLU(),
nn.Conv2d(32,32,(3,3)),
nn.ReLU(),
nn.Conv2d(32,64,(3,3)),
nn.ReLU(),
nn.Flatten(),
nn.Linear(64*(224-6)*(224-6),2)
)
def forward(self, x):
return self.model(x)import datetime
num_epochs = 2
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = TyreQualityClassifier()
fn_loss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
model.to(device)
for epoch in range(num_epochs):
for idx, (X, y) in enumerate(data_loader):
X = X.to(device)
y = y.to(device)
y_hat = model(X)
loss = fn_loss(y_hat, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
current_time = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print(f"Current Time: {current_time} - Epoch [{epoch+1}/{num_epochs}]- Batch [{idx + 1}] - Loss: {loss}", end='\r')이 코드는 표준 PyTorch 학습 과정을 구현합니다. 이는 합성곱 계층과 선형 계층을 사용하여 타이어 품질을 분류하는 *TyreQualityClassifier*라는 신경망 모델을 정의합니다. 학습 루프는 데이터 배치를 반복하고, 손실을 계산하고, 역전파와 최적화를 사용하여 모델의 매개변수를 업데이트합니다. 또한 모니터링 목적으로 현재 시간, 에포크, 배치 및 손실을 인쇄합니다.
모델 배포
전개
import io
import os
import tarfile
import sagemaker
# 1. Save the PyTorch model to memory
buffer_model = io.BytesIO()
traced_model = torch.jit.script(model)
torch.jit.save(traced_model, buffer_model)
# 2. Upload to AWS S3
sagemaker_session = sagemaker.Session()
bucket_name_default = sagemaker_session.default_bucket()
model_name = f'tyre_quality_classifier.pth'
# 2.1. Zip PyTorch model into tar.gz file
buffer_zip = io.BytesIO()
with tarfile.open(fileobj=buffer_zip, mode="w:gz") as tar:
# Add PyTorch pt file
file_name = os.path.basename(model_name)
file_name_with_extension = os.path.split(file_name)[-1]
tarinfo = tarfile.TarInfo(file_name_with_extension)
tarinfo.size = len(buffer_model.getbuffer())
buffer_model.seek(0)
tar.addfile(tarinfo, buffer_model)
# 2.2. Upload the tar.gz file to S3 bucket
buffer_zip.seek(0)
boto3.resource('s3') \
.Bucket(bucket_name_default) \
.Object(f'pytorch/{model_name}.tar.gz') \
.put(Body=buffer_zip.getvalue())SageMaker는 배포를 위해 모델을 S3에 저장해야 하므로 이 코드는 PyTorch 모델을 *Amazon S3*에 저장합니다. 모델을 *Amazon S3*에 업로드하면 SageMaker에서 접근할 수 있게 되어 배포된 모델에 대한 배포와 추론이 가능해집니다.
import time
from sagemaker.pytorch import PyTorchModel
from sagemaker.predictor import Predictor
from sagemaker.serializers import IdentitySerializer
from sagemaker.deserializers import JSONDeserializer
class TyreQualitySerializer(IdentitySerializer):
CONTENT_TYPE = 'application/x-torch'
def serialize(self, data):
transformed_image = preprocess(data)
tensor_image = torch.Tensor(transformed_image)
serialized_data = io.BytesIO()
torch.save(tensor_image, serialized_data)
serialized_data.seek(0)
serialized_data = serialized_data.read()
return serialized_data
class TyreQualityPredictor(Predictor):
def __init__(self, endpoint_name, sagemaker_session):
super().__init__(
endpoint_name,
sagemaker_session=sagemaker_session,
serializer=TyreQualitySerializer(),
deserializer=JSONDeserializer(),
)
sagemaker_model = PyTorchModel(
model_data=f's3://{bucket_name_default}/pytorch/{model_name}.tar.gz',
role=sagemaker.get_execution_role(),
framework_version='2.0.1',
py_version='py310',
predictor_cls=TyreQualityPredictor,
entry_point='inference.py',
source_dir='code',
)
timestamp = int(time.time())
pytorch_endpoint_name = '{}-{}-{}'.format('tyre-quality-classifier', 'pt', timestamp)
sagemaker_predictor = sagemaker_model.deploy(
initial_instance_count=1,
instance_type='ml.p3.2xlarge',
endpoint_name=pytorch_endpoint_name
)이 코드는 SageMaker에서 PyTorch 모델을 배포하는 것을 용이하게 합니다. PyTorch 텐서로 입력 데이터를 전처리하고 직렬화하는 사용자 정의 직렬화기인 TyreQualitySerializer*를 정의합니다. *TyreQualityPredictor 클래스는 정의된 직렬화기와 JSONDeserializer*를 활용하는 사용자 정의 예측기입니다. 또한 이 코드는 모델의 S3 위치, IAM 역할, 프레임워크 버전, 추론 진입점을 지정하기 위해 *PyTorchModel 객체를 생성합니다. 이 코드는 타임스탬프를 생성하고 모델과 타임스탬프를 기반으로 엔드포인트 이름을 구성합니다. 마지막으로, 인스턴스 수, 인스턴스 유형, 생성된 엔드포인트 이름을 지정하여 배포 메서드를 사용하여 모델을 배포합니다. 이를 통해 PyTorch 모델을 배포하고 SageMaker에서 추론에 액세스할 수 있습니다.
추론
image_object = list(bucket.objects.filter('dataset/tyre'))[0].get()
image_bytes = image_object['Body'].read()
with Image.open(with Image.open(BytesIO(image_bytes)) as image:
predicted_classes = sagemaker_predictor.predict(image)
print(predicted_classes)이는 배포된 엔드포인트를 사용하여 추론을 수행하는 예입니다.