

솔루션 기술
 변경 제안
변경 제안
Apache Spark는 Hadoop 분산 파일 시스템(HDFS)과 직접 작동하는 Hadoop 애플리케이션을 작성하기 위한 인기 있는 프로그래밍 프레임워크입니다. Spark는 프로덕션에 바로 사용할 수 있으며, 스트리밍 데이터 처리를 지원하며 MapReduce보다 빠릅니다. Spark는 효율적인 반복을 위해 구성 가능한 메모리 내 데이터 캐싱 기능을 갖추고 있으며, Spark 셸은 데이터를 학습하고 탐색하기 위해 대화형으로 작동합니다. Spark를 사용하면 Python, Scala 또는 Java로 애플리케이션을 만들 수 있습니다. Spark 애플리케이션은 하나 이상의 작업을 포함하는 하나 이상의 작업으로 구성됩니다.
모든 Spark 애플리케이션에는 Spark 드라이버가 있습니다. YARN-Client 모드에서는 드라이버가 클라이언트에서 로컬로 실행됩니다. YARN-클러스터 모드에서 드라이버는 애플리케이션 마스터의 클러스터에서 실행됩니다. 클러스터 모드에서는 클라이언트가 연결을 끊더라도 애플리케이션은 계속 실행됩니다.
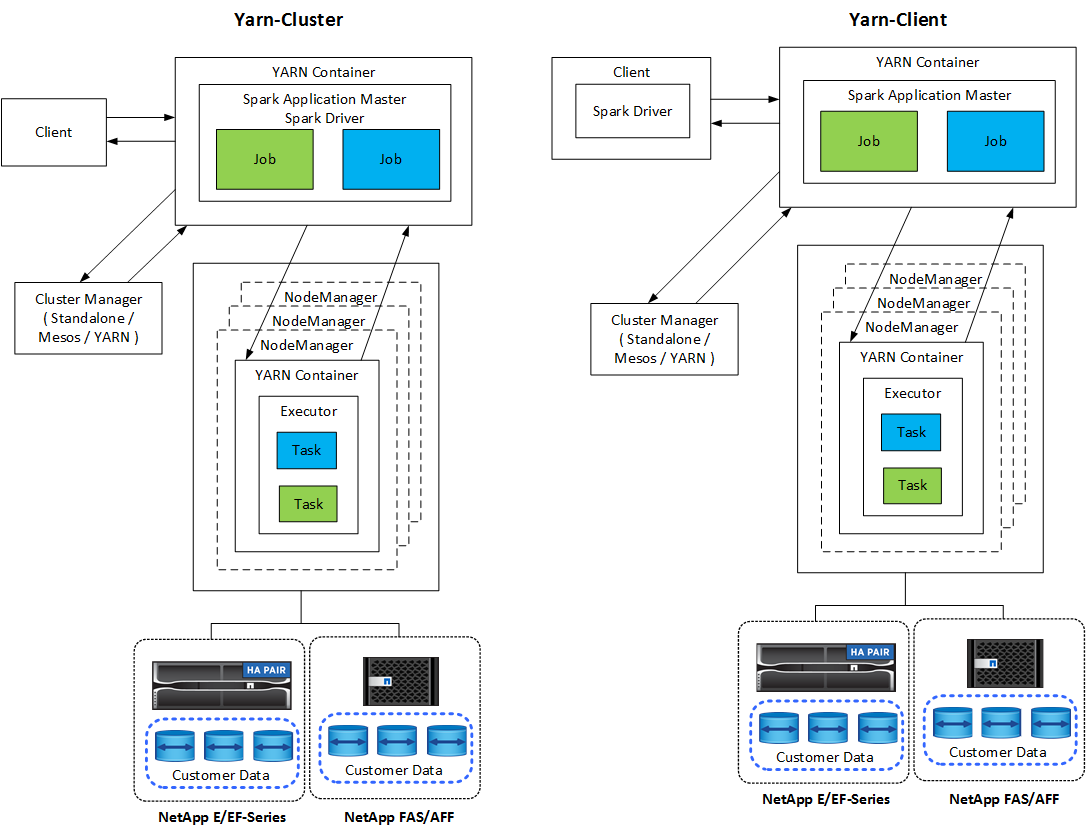
클러스터 관리자는 세 가지가 있습니다.
-
독립형. 이 관리자는 Spark의 일부로, 클러스터를 쉽게 설정할 수 있도록 해줍니다.
-
아파치 메소스. 이는 MapReduce 및 기타 애플리케이션을 실행하는 일반 클러스터 관리자입니다.
-
하둡 YARN. 이는 Hadoop 3의 리소스 관리자입니다.
탄력적 분산 데이터 세트(RDD)는 Spark의 주요 구성 요소입니다. RDD는 클러스터의 메모리에 저장된 데이터에서 손실되거나 누락된 데이터를 다시 생성하고 파일에서 나오거나 프로그래밍 방식으로 생성된 초기 데이터를 저장합니다. RDD는 파일, 메모리의 데이터 또는 다른 RDD로부터 생성됩니다. Spark 프로그래밍은 변환과 동작이라는 두 가지 작업을 수행합니다. 변형은 기존 RDD를 기반으로 새로운 RDD를 생성합니다. 액션은 RDD에서 값을 반환합니다.
변환과 작업은 Spark Datasets와 DataFrames에도 적용됩니다. 데이터 세트는 RDD(강력한 타이핑, 람다 함수 사용)의 이점과 Spark SQL의 최적화된 실행 엔진의 이점을 모두 제공하는 분산된 데이터 컬렉션입니다. 데이터 세트는 JVM 객체로부터 구성된 다음 함수 변환(map, flatMap, filter 등)을 사용하여 조작될 수 있습니다. DataFrame은 이름이 지정된 열로 구성된 데이터 집합입니다. 개념적으로는 관계형 데이터베이스의 테이블이나 R/Python의 데이터 프레임과 동일합니다. DataFrames는 구조화된 데이터 파일, Hive/HBase의 테이블, 온프레미스 또는 클라우드의 외부 데이터베이스, 기존 RDD 등 다양한 소스에서 구성할 수 있습니다.
Spark 애플리케이션에는 하나 이상의 Spark 작업이 포함됩니다. 작업은 실행자에서 작업을 실행하고 실행자는 YARN 컨테이너에서 실행됩니다. 각 실행자는 단일 컨테이너에서 실행되며 실행자는 애플리케이션의 수명 동안 존재합니다. 실행자는 애플리케이션이 시작된 후에 고정되고, YARN은 이미 할당된 컨테이너의 크기를 조정하지 않습니다. 실행자는 메모리 내 데이터에서 동시에 작업을 실행할 수 있습니다.