테스트 결과
 변경 제안
변경 제안
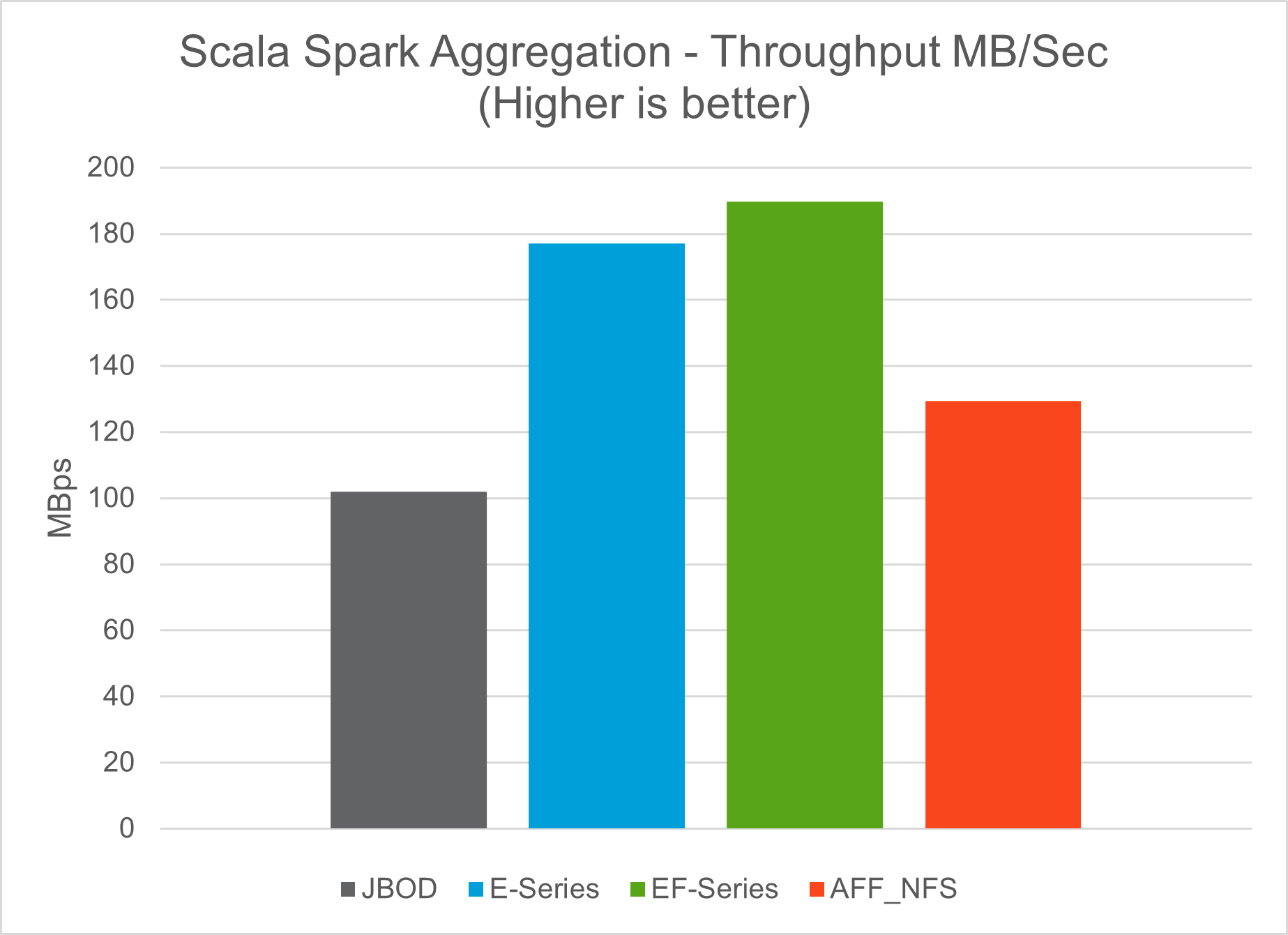
TeraGen 벤치마킹 도구의 TeraSort 및 TeraValidate 스크립트를 사용하여 E5760, E5724 및 AFF-A800 구성으로 Spark 성능 검증을 측정했습니다. 또한, Spark NLP 파이프라인과 TensorFlow 분산 학습, Horovod 분산 학습, DeepFM을 사용한 CTR 예측을 위한 Keras를 사용한 다중 워커 딥 러닝의 세 가지 주요 사용 사례가 테스트되었습니다.
E-Series와 StorageGRID 검증에는 Hadoop 복제 계수 2를 사용했습니다. AFF 검증을 위해 우리는 단 하나의 데이터 소스만 사용했습니다.
다음 표는 Spark 성능 검증을 위한 하드웨어 구성을 나열한 것입니다.
| 유형 | Hadoop 워커 노드 | 구동 유형 | 노드당 드라이브 | 스토리지 컨트롤러 |
|---|---|---|---|---|
SG6060 |
4 |
SAS |
12 |
단일 고가용성(HA) 쌍 |
E5760 |
4 |
SAS |
60 |
단일 HA 쌍 |
E5724 |
4 |
SAS |
24 |
단일 HA 쌍 |
AFF800 |
4 |
SSD |
6 |
단일 HA 쌍 |
다음 표에는 소프트웨어 요구 사항이 나열되어 있습니다.
| 소프트웨어 | 버전 |
|---|---|
RHEL |
7.9 |
OpenJDK 런타임 환경 |
1.8.0 |
OpenJDK 64비트 서버 VM |
25.302 |
깃 |
2.24.1 |
GCC/G++ |
11.2.1 |
불꽃 |
3.2.1 |
파이스파크 |
3.1.2 |
스파크NLP |
3.4.2 |
텐서플로우 |
2.9.0 |
케라스 |
2.9.0 |
호로보드 |
0.24.3 |
금융 심리 분석
우리는 출판했다"TR-4910: NetApp AI를 활용한 고객 커뮤니케이션의 감정 분석" , 종단 간 대화형 AI 파이프라인이 다음을 사용하여 구축되었습니다. "NetApp DataOps 툴킷" , AFF 스토리지 및 NVIDIA DGX 시스템. 파이프라인은 DataOps Toolkit을 활용하여 일괄 오디오 신호 처리, 자동 음성 인식(ASR), 전이 학습 및 감정 분석을 수행합니다. "NVIDIA 리바 SDK" , 그리고 "타오 프레임워크" . 감정 분석 사용 사례를 금융 서비스 산업으로 확장하여 SparkNLP 워크플로를 구축하고, 명명된 엔터티 인식과 같은 다양한 NLP 작업을 위해 세 개의 BERT 모델을 로드하고, NASDAQ 상위 10대 기업의 분기별 실적 전화 회의에 대한 문장 수준의 감정을 얻었습니다.
다음 스크립트 sentiment_analysis_spark. py 다음 표에 표시된 것처럼 FinBERT 모델을 사용하여 HDFS에서 전사본을 처리하고 긍정적, 중립적, 부정적 감정 수를 생성합니다.
-bash-4.2$ time ~/anaconda3/bin/spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_2.12:3.4.3 --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 --conf spark.driver.extraJavaOptions="-Xss10m -XX:MaxPermSize=1024M" --conf spark.executor.extraJavaOptions="-Xss10m -XX:MaxPermSize=512M" /sparkusecase/tr-4570-nlp/sentiment_analysis_spark.py hdfs:///data1/Transcripts/ > ./sentiment_analysis_hdfs.log 2>&1 real13m14.300s user557m11.319s sys4m47.676s
다음 표는 2016년부터 2020년까지 NASDAQ 상위 10개 기업의 수익 발표 및 문장 단위 감정 분석을 나열한 것입니다.
| 감정 수와 백분율 | 10개 회사 모두 | 아에이피엘 | AMD | 아마존 | CSCO | 구글 | 인티씨 | MSFT | 엔비디아 |
|---|---|---|---|---|---|---|---|---|---|
양성 카운트 |
7447 |
1567 |
743 |
290 |
682 |
826 |
824 |
904 |
417 |
중립 카운트 |
64067 |
6856 |
7596 |
5086 |
6650 |
5914 |
6099 |
5715 |
6189 |
음수 카운트 |
1787 |
253 |
213 |
84 |
189 |
97 |
282 |
202 |
89 |
분류되지 않은 카운트 |
196 |
0 |
0 |
76 |
0 |
0 |
0 |
1 |
0 |
(총 개수) |
73497 |
8676 |
8552 |
5536 |
7521 |
6837 |
7205 |
6822 |
6695 |
백분율로 보면, CEO와 CFO가 말한 대부분의 문장은 사실에 기반을 두고 있어 중립적인 감정을 담고 있습니다. 수익 전화 회의에서 분석가들은 긍정적이거나 부정적인 감정을 전달할 수 있는 질문을 합니다. 부정적 또는 긍정적 감정이 거래 당일이나 다음 날의 주가에 어떤 영향을 미치는지 정량적으로 추가 조사해 볼 가치가 있습니다.
다음 표는 NASDAQ 상위 10개 기업의 문장 수준 감정 분석을 백분율로 나타낸 것입니다.
| 감정 비율 | 10개 회사 모두 | 아에이피엘 | AMD | 아마존 | CSCO | 구글 | 인티씨 | MSFT | 엔비디아 |
|---|---|---|---|---|---|---|---|---|---|
긍정적인 |
10.13% |
18.06% |
8.69% |
5.24% |
9.07% |
12.08% |
11.44% |
13.25% |
6.23% |
중립적 |
87.17% |
79.02% |
88.82% |
91.87% |
88.42% |
86.50% |
84.65% |
83.77% |
92.44% |
부정적인 |
2.43% |
2.92% |
2.49% |
1.52% |
2.51% |
1.42% |
3.91% |
2.96% |
1.33% |
분류되지 않음 |
0.27% |
0% |
0% |
1.37% |
0% |
0% |
0% |
0.01% |
0% |
워크플로 런타임 측면에서 우리는 4.78배의 상당한 개선을 보았습니다. local HDFS의 분산 환경으로 모드를 전환하고 NFS를 활용하여 0.14% 더 개선되었습니다.
-bash-4.2$ time ~/anaconda3/bin/spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_2.12:3.4.3 --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 --conf spark.driver.extraJavaOptions="-Xss10m -XX:MaxPermSize=1024M" --conf spark.executor.extraJavaOptions="-Xss10m -XX:MaxPermSize=512M" /sparkusecase/tr-4570-nlp/sentiment_analysis_spark.py file:///sparkdemo/sparknlp/Transcripts/ > ./sentiment_analysis_nfs.log 2>&1 real13m13.149s user537m50.148s sys4m46.173s
다음 그림에서 볼 수 있듯이, 데이터 및 모델 병렬 처리로 데이터 처리와 분산 TensorFlow 모델 추론 속도가 향상되었습니다. NFS에서 데이터를 배치하면 워크플로 병목 현상이 사전 학습된 모델을 다운로드하는 데서 발생하기 때문에 런타임이 약간 더 향상됩니다. 전사본 데이터 세트의 크기를 늘리면 NFS의 장점이 더욱 분명해집니다.
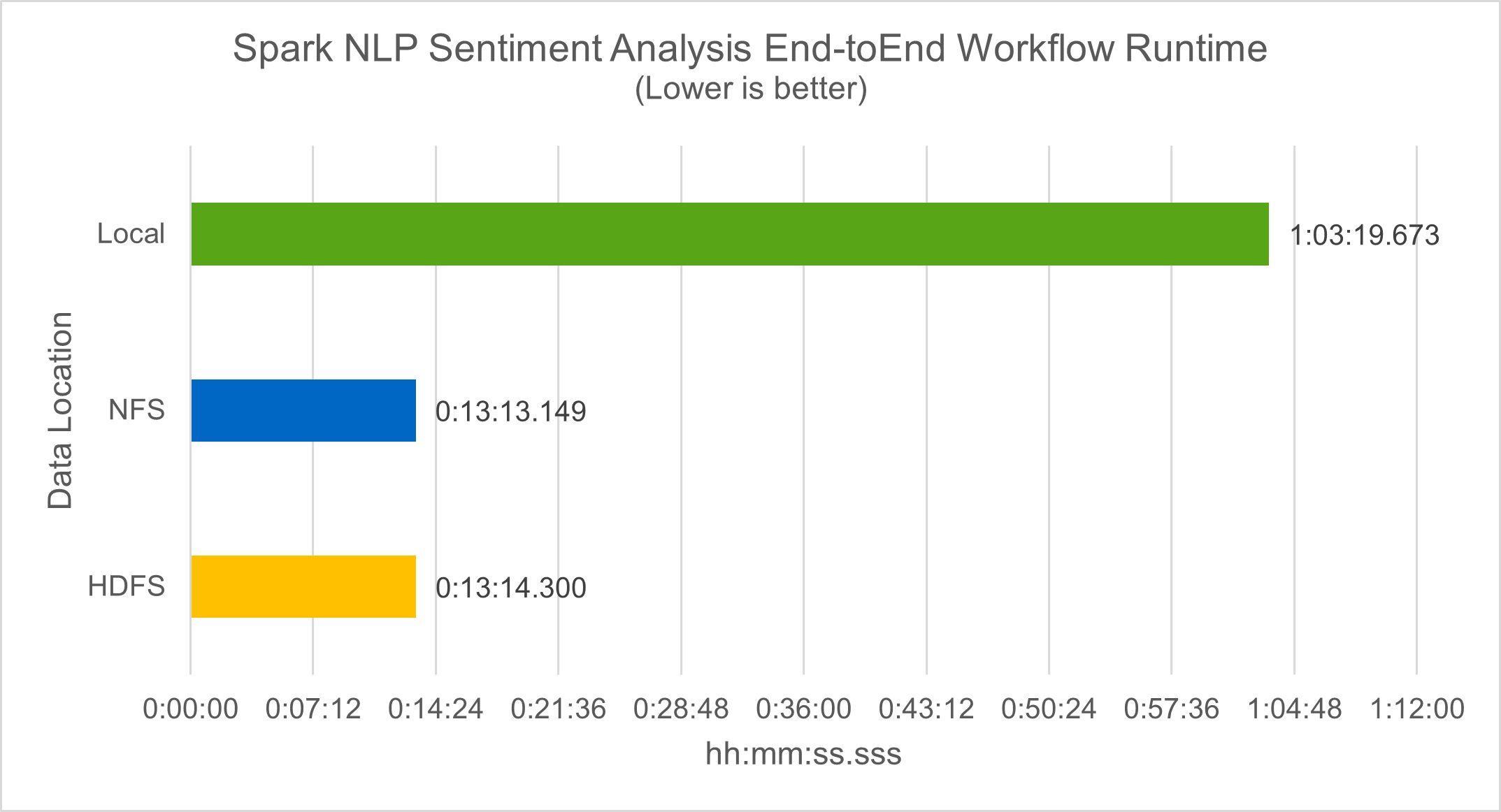
Horovod 성능을 활용한 분산 학습
다음 명령은 단일 명령을 사용하여 Spark 클러스터에서 런타임 정보와 로그 파일을 생성했습니다. master 각각 1개의 코어를 갖춘 160개의 실행자가 있는 노드입니다. 메모리 부족 오류를 방지하기 위해 실행자 메모리는 5GB로 제한되었습니다. 섹션을 참조하세요"각 주요 사용 사례에 대한 Python 스크립트" 데이터 처리, 모델 학습 및 모델 정확도 계산에 대한 자세한 내용은 keras_spark_horovod_rossmann_estimator.py .
(base) [root@n138 horovod]# time spark-submit --master local --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir file:///sparkusecase/horovod --local-submission-csv /tmp/submission_0.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_local. log 2>&1
10개의 학습 에포크를 적용한 결과 런타임은 다음과 같습니다.
real43m34.608s user12m22.057s sys2m30.127s
입력 데이터를 처리하고, DNN 모델을 훈련하고, 정확도를 계산하고, TensorFlow 체크포인트와 예측 결과를 위한 CSV 파일을 생성하는 데 43분 이상 걸렸습니다. 우리는 훈련 에포크의 수를 10으로 제한했는데, 실제로는 만족스러운 모델 정확도를 보장하기 위해 종종 100으로 설정합니다. 일반적으로 학습 시간은 에포크 수에 따라 선형적으로 증가합니다.
다음으로 클러스터에서 사용 가능한 4개의 작업자 노드를 사용하여 동일한 스크립트를 실행했습니다. yarn HDFS에 데이터가 있는 모드:
(base) [root@n138 horovod]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir hdfs:///user/hdfs/tr-4570/experiments/horovod --local-submission-csv /tmp/submission_1.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_yarn.log 2>&1
그 결과 런타임은 다음과 같이 개선되었습니다.
real8m13.728s user7m48.421s sys1m26.063s
Spark에서 Horovod의 모델과 데이터 병렬 처리를 통해 런타임 속도가 5.29배 향상되었습니다. yarn ~ 대 local 10개의 훈련 에포크를 가진 모드. 이는 다음 그림에서 범례와 함께 표시됩니다. HDFS 그리고 Local . 사용 가능한 경우 GPU를 사용하여 기본 TensorFlow DNN 모델 학습을 더욱 가속화할 수 있습니다. 우리는 이 테스트를 수행하고 그 결과를 향후 기술 보고서에 발표할 계획입니다.
다음 테스트에서는 NFS와 HDFS에 있는 입력 데이터를 사용하여 런타임을 비교했습니다. AFF A800 의 NFS 볼륨은 다음에 마운트되었습니다. /sparkdemo/horovod Spark 클러스터의 5개 노드(마스터 1개, 워커 4개)에 걸쳐 있습니다. 우리는 이전 테스트와 유사한 명령을 실행했습니다. --data- dir 이제 NFS 마운트를 가리키는 매개변수:
(base) [root@n138 horovod]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir file:///sparkdemo/horovod --local-submission-csv /tmp/submission_2.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_nfs.log 2>&1
NFS를 사용한 결과 런타임은 다음과 같습니다.
real 5m46.229s user 5m35.693s sys 1m5.615s
다음 그림에서 볼 수 있듯이, 1.43배 더 속도가 향상되었습니다. 따라서 클러스터에 연결된 NetApp 올플래시 스토리지를 통해 고객은 Horovod Spark 워크플로우에서 빠른 데이터 전송 및 배포의 이점을 누릴 수 있으며, 단일 노드에서 실행하는 것보다 7.55배 빠른 속도를 달성할 수 있습니다.
CTR 예측 성능을 위한 딥러닝 모델
CTR을 극대화하도록 설계된 추천 시스템의 경우, 낮은 순위에서 높은 순위까지 수학적으로 계산할 수 있는 사용자 행동의 이면에 있는 정교한 기능 상호작용을 학습해야 합니다. 좋은 딥 러닝 모델에서는 낮은 순서와 높은 순서의 특징 상호작용이 둘 다 똑같이 중요해야 하며, 어느 한쪽에 치우치지 않아야 합니다. 인수분해 머신 기반 신경망인 DeepFM(Deep Factorization Machine)은 추천을 위한 인수분해 머신과 기능 학습을 위한 딥러닝을 새로운 신경망 아키텍처로 결합합니다.
기존의 인수분해 머신은 쌍별 특징 상호작용을 특징 간의 잠재 벡터의 내적으로 모델링하고 이론적으로는 고차 정보를 포착할 수 있지만, 실제로 머신 러닝 실무자는 높은 계산 및 저장 복잡성으로 인해 2차 특징 상호작용만 사용합니다. Google과 같은 딥 신경망 변형 "와이드 딥 모델" 반면에 선형 광역 모델과 심층 모델을 결합하여 하이브리드 네트워크 구조에서 정교한 기능 상호 작용을 학습합니다.
이 Wide & Deep 모델에는 두 가지 입력이 있습니다. 하나는 기본 Wide 모델을 위한 것이고 다른 하나는 Deep 모델을 위한 것입니다. Deep 모델의 후자에는 여전히 전문적인 기능 엔지니어링이 필요하므로 이 기술을 다른 도메인으로 일반화하기는 어렵습니다. Wide & Deep 모델과 달리 DeepFM은 와이드 부분과 딥 부분이 동일한 입력과 임베딩 벡터를 공유하기 때문에 기능 엔지니어링 없이 원시 기능으로 효율적으로 학습할 수 있습니다.
우리는 먼저 Criteo를 처리했습니다. train.txt (11GB) 파일을 CSV 파일로 변환 ctr_train.csv NFS 마운트에 저장됨 /sparkdemo/tr-4570-data 사용 중 run_classification_criteo_spark.py 섹션에서"주요 사용 사례별로 Python 스크립트가 제공됩니다." 이 스크립트 내에서 함수 process_input_file 탭을 제거하고 삽입하기 위해 여러 문자열 메서드를 수행합니다. ',' 구분 기호로 '\n' 줄바꿈으로. 원본만 처리하면 된다는 점에 유의하세요. train.txt 한 번, 코드 블록이 주석으로 표시됩니다.
다양한 DL 모델에 대한 다음 테스트를 위해 다음을 사용했습니다. ctr_train.csv 입력 파일로. 이후 테스트 실행에서 입력 CSV 파일은 스키마가 포함된 Spark DataFrame으로 읽혀졌습니다. 'label' , 정수 밀집 기능 ['I1', 'I2', 'I3', …, 'I13'] , 그리고 희소한 특징 ['C1', 'C2', 'C3', …, 'C26'] . 다음 spark-submit 명령은 입력 CSV를 받고, 교차 검증을 위해 20% 분할로 DeepFM 모델을 학습하고, 10번의 학습 에포크 후에 가장 좋은 모델을 선택하여 테스트 세트에서 예측 정확도를 계산합니다.
(base) [root@n138 ~]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py --data-dir file:///sparkdemo/tr-4570-data > /tmp/run_classification_criteo_spark_local.log 2>&1
데이터 파일 이후에는 ctr_train.csv 11GB가 넘으면 충분한 용량을 설정해야 합니다. spark.driver.maxResultSize 오류를 피하기 위해 데이터 세트 크기보다 크게 설정합니다.
spark = SparkSession.builder \
.master("yarn") \
.appName("deep_ctr_classification") \
.config("spark.jars.packages", "io.github.ravwojdyla:spark-schema-utils_2.12:0.1.0") \
.config("spark.executor.cores", "1") \
.config('spark.executor.memory', '5gb') \
.config('spark.executor.memoryOverhead', '1500') \
.config('spark.driver.memoryOverhead', '1500') \
.config("spark.sql.shuffle.partitions", "480") \
.config("spark.sql.execution.arrow.enabled", "true") \
.config("spark.driver.maxResultSize", "50gb") \
.getOrCreate()
위의 SparkSession.builder 구성도 활성화했습니다 "아파치 애로우" Spark DataFrame을 Pandas DataFrame으로 변환하는 df.toPandas() 방법.
22/06/17 15:56:21 INFO scheduler.DAGScheduler: Job 2 finished: toPandas at /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py:96, took 627.126487 s Obtained Spark DF and transformed to Pandas DF using Arrow.
무작위 분할 후, 훈련 데이터 세트에는 3,600만 개가 넘는 행이 있고 테스트 세트에는 900만 개의 샘플이 있습니다.
Training dataset size = 36672493 Testing dataset size = 9168124
이 기술 보고서는 GPU를 사용하지 않고 CPU 테스트에 초점을 맞추고 있으므로 적절한 컴파일러 플래그로 TensorFlow를 빌드하는 것이 중요합니다. 이 단계에서는 GPU 가속 라이브러리를 호출하지 않고 TensorFlow의 AVX(Advanced Vector Extensions) 및 AVX2 명령어를 최대한 활용합니다. 이러한 기능은 벡터화된 덧셈, 피드포워드 내부의 행렬 곱셈 또는 역전파 DNN 훈련과 같은 선형 대수 계산을 위해 설계되었습니다. AVX2에서 제공하는 256비트 부동 소수점(FP) 레지스터를 사용하는 융합 곱셈 및 덧셈(FMA) 명령어는 정수 코드와 데이터 유형에 이상적이며 최대 2배의 속도 향상을 가져옵니다. FP 코드와 데이터 유형의 경우 AVX2는 AVX보다 8% 더 빠른 속도를 달성합니다.
2022-06-18 07:19:20.101478: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
소스에서 TensorFlow를 빌드하려면 NetApp 다음을 사용하는 것이 좋습니다. "바젤" . 우리 환경에서는 셸 프롬프트에서 다음 명령을 실행하여 설치했습니다. dnf , dnf-plugins , 그리고 바젤.
yum install dnf dnf install 'dnf-command(copr)' dnf copr enable vbatts/bazel dnf install bazel5
RHEL에서 SCL(소프트웨어 컬렉션 라이브러리)을 통해 제공하는 C++17 기능을 빌드 프로세스 중에 사용하려면 GCC 5 이상 버전을 활성화해야 합니다. 다음 명령어를 설치합니다. devtoolset 그리고 RHEL 7.9 클러스터에 GCC 11.2.1이 있습니다.
subscription-manager repos --enable rhel-server-rhscl-7-rpms yum install devtoolset-11-toolchain yum install devtoolset-11-gcc-c++ yum update scl enable devtoolset-11 bash . /opt/rh/devtoolset-11/enable
마지막 두 명령은 다음을 활성화합니다. devtoolset-11 , 사용하는 /opt/rh/devtoolset-11/root/usr/bin/gcc (GCC 11.2.1). 또한 다음을 확인하세요. git 버전이 1.8.3보다 높습니다(RHEL 7.9에 포함됨). 이것을 참조하세요 "기사" 업데이트용 git 2.24.1로.
귀하가 이미 최신 TensorFlow 마스터 저장소를 복제했다고 가정합니다. 그런 다음 생성하세요 workspace 디렉토리 WORKSPACE AVX, AVX2, FMA를 사용하여 소스에서 TensorFlow를 빌드하는 파일입니다. 실행하다 configure 파일을 만들고 올바른 Python 바이너리 위치를 지정합니다. "쿠다" 우리는 GPU를 사용하지 않았기 때문에 테스트를 위해 비활성화되었습니다. 에이 .bazelrc 파일은 귀하의 설정에 따라 생성됩니다. 또한, 우리는 파일을 편집하고 설정했습니다. build --define=no_hdfs_support=false HDFS 지원을 활성화합니다. 참조하다 .bazelrc 섹션에서"각 주요 사용 사례에 대한 Python 스크립트" 설정 및 플래그의 전체 목록을 확인하세요.
./configure bazel build -c opt --copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-mfpmath=both -k //tensorflow/tools/pip_package:build_pip_package
올바른 플래그로 TensorFlow를 빌드한 후 다음 스크립트를 실행하여 Criteo Display Ads 데이터 세트를 처리하고 DeepFM 모델을 학습시키고 예측 점수에서 수신자 조작 특성 곡선 아래의 면적(ROC AUC)을 계산합니다.
(base) [root@n138 examples]# ~/anaconda3/bin/spark-submit --master yarn --executor-memory 15g --executor-cores 1 --num-executors 160 /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py --data-dir file:///sparkdemo/tr-4570-data > . /run_classification_criteo_spark_nfs.log 2>&1
10번의 훈련 에포크 후에 우리는 테스트 데이터 세트에 대한 AUC 점수를 얻었습니다.
Epoch 1/10 125/125 - 7s - loss: 0.4976 - binary_crossentropy: 0.4974 - val_loss: 0.4629 - val_binary_crossentropy: 0.4624 Epoch 2/10 125/125 - 1s - loss: 0.3281 - binary_crossentropy: 0.3271 - val_loss: 0.5146 - val_binary_crossentropy: 0.5130 Epoch 3/10 125/125 - 1s - loss: 0.1948 - binary_crossentropy: 0.1928 - val_loss: 0.6166 - val_binary_crossentropy: 0.6144 Epoch 4/10 125/125 - 1s - loss: 0.1408 - binary_crossentropy: 0.1383 - val_loss: 0.7261 - val_binary_crossentropy: 0.7235 Epoch 5/10 125/125 - 1s - loss: 0.1129 - binary_crossentropy: 0.1102 - val_loss: 0.7961 - val_binary_crossentropy: 0.7934 Epoch 6/10 125/125 - 1s - loss: 0.0949 - binary_crossentropy: 0.0921 - val_loss: 0.9502 - val_binary_crossentropy: 0.9474 Epoch 7/10 125/125 - 1s - loss: 0.0778 - binary_crossentropy: 0.0750 - val_loss: 1.1329 - val_binary_crossentropy: 1.1301 Epoch 8/10 125/125 - 1s - loss: 0.0651 - binary_crossentropy: 0.0622 - val_loss: 1.3794 - val_binary_crossentropy: 1.3766 Epoch 9/10 125/125 - 1s - loss: 0.0555 - binary_crossentropy: 0.0527 - val_loss: 1.6115 - val_binary_crossentropy: 1.6087 Epoch 10/10 125/125 - 1s - loss: 0.0470 - binary_crossentropy: 0.0442 - val_loss: 1.6768 - val_binary_crossentropy: 1.6740 test AUC 0.6337
이전 사용 사례와 유사한 방식으로 Spark 워크플로 런타임을 다양한 위치에 있는 데이터와 비교했습니다. 다음 그림은 Spark 워크플로 런타임에 대한 딥 러닝 CTR 예측을 비교한 것입니다.