TR-4912: NetApp 사용한 Confluent Kafka 계층형 스토리지에 대한 모범 사례 가이드라인
 변경 제안
변경 제안
Karthikeyan Nagalingam, Joseph Kandatilparambil, NetApp Rankesh Kumar, Confluent
Apache Kafka는 하루에 수조 개의 이벤트를 처리할 수 있는 커뮤니티 분산형 이벤트 스트리밍 플랫폼입니다. 처음에는 메시징 큐로 구상되었지만, 카프카는 분산 커밋 로그의 추상화를 기반으로 합니다. 카프카는 2011년 LinkedIn에서 개발되어 오픈 소스로 공개된 이후 메시지 큐에서 본격적인 이벤트 스트리밍 플랫폼으로 발전했습니다. Confluent는 Confluent Platform을 통해 Apache Kafka를 배포합니다. Confluent 플랫폼은 Kafka에 커뮤니티 및 상용 기능을 추가하여 대규모 프로덕션 환경에서 운영자와 개발자 모두의 스트리밍 경험을 향상시키도록 설계되었습니다.
이 문서에서는 NetApp의 개체 스토리지 제품에서 Confluent Tiered Storage를 사용하기 위한 모범 사례 가이드라인을 설명하며, 다음과 같은 내용을 제공합니다.
-
NetApp Object Storage를 통한 Confluent 검증 – NetApp StorageGRID
-
계층형 스토리지 성능 테스트
-
NetApp 스토리지 시스템에서 Confluent를 위한 모범 사례 가이드라인
Confluent Tiered Storage를 선택해야 하는 이유는 무엇인가요?
Confluent는 특히 빅데이터, 분석 및 스트리밍 워크로드를 위한 다양한 애플리케이션의 기본 실시간 스트리밍 플랫폼이 되었습니다. 계층형 스토리지를 사용하면 사용자가 Confluent 플랫폼에서 컴퓨팅과 스토리지를 분리할 수 있습니다. 이를 통해 데이터 저장의 비용 효율성이 높아지고, 사실상 무한한 양의 데이터를 저장하고 필요에 따라 작업 부하를 확장(또는 축소)할 수 있으며, 데이터 및 테넌트 재조정과 같은 관리 작업이 더 쉬워집니다. S3 호환 스토리지 시스템은 이러한 모든 기능을 활용하여 모든 이벤트를 한곳에서 관리함으로써 데이터를 민주화하고 복잡한 데이터 엔지니어링의 필요성을 없앨 수 있습니다. Kafka에 계층형 스토리지를 사용해야 하는 이유에 대한 자세한 내용은 다음을 확인하세요."Confluent의 이 기사" .
NetApp instaclustr는 3.8.1 버전부터 계층형 스토리지를 사용하는 Kafka도 지원합니다. 자세한 내용은 여기를 확인하세요. "Kafka 계층형 스토리지를 사용하는 Instaclust"
계층형 스토리지에 NetApp StorageGRID 사용해야 하는 이유는 무엇인가요?
StorageGRID 는 NetApp 이 제공하는 업계 최고의 객체 스토리지 플랫폼입니다. StorageGRID Amazon Simple Storage Service(S3) API를 비롯한 업계 표준 객체 API를 지원하는 소프트웨어 정의 객체 기반 스토리지 솔루션입니다. StorageGRID 대규모로 비정형 데이터를 저장하고 관리하여 안전하고 내구성 있는 객체 스토리지를 제공합니다. 콘텐츠는 적절한 위치, 적절한 시간, 적절한 저장 계층에 배치되어 워크플로를 최적화하고 전 세계적으로 분산된 리치 미디어의 비용을 절감합니다.
StorageGRID 의 가장 큰 차별화 요소는 정책 기반의 데이터 수명 주기 관리를 지원하는 정보 수명 주기 관리(ILM) 정책 엔진입니다. 정책 엔진은 메타데이터를 사용하여 데이터가 수명 동안 저장되는 방식을 관리하여 초기에는 성능을 최적화하고, 데이터가 오래됨에 따라 비용과 내구성을 자동으로 최적화할 수 있습니다.
Confluent 계층형 스토리지 활성화
계층형 스토리지의 기본 아이디어는 데이터 저장 작업과 데이터 처리를 분리하는 것입니다. 이러한 분리를 통해 데이터 저장 계층과 데이터 처리 계층이 독립적으로 확장하기가 훨씬 쉬워집니다.
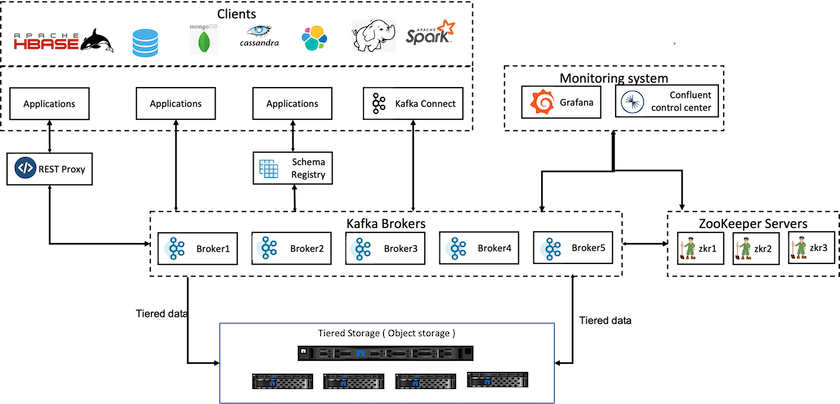
Confluent의 계층형 스토리지 솔루션은 두 가지 요소를 고려해야 합니다. 첫째, LIST 작업의 불일치나 가끔씩 발생하는 객체 사용 불가 등 공통적인 객체 저장소의 일관성 및 가용성 속성을 해결하거나 방지해야 합니다. 둘째, 계층형 스토리지와 카프카의 복제 및 장애 허용 모델 간의 상호 작용을 올바르게 처리해야 하며, 여기에는 좀비 리더가 계속해서 계층 오프셋 범위를 유지할 가능성이 포함됩니다. NetApp 개체 스토리지는 일관된 개체 가용성과 HA 모델을 모두 제공하여 피곤한 스토리지를 계층 오프셋 범위에 사용할 수 있도록 합니다. NetApp 개체 스토리지는 일관된 개체 가용성과 HA 모델을 제공하여 소모된 스토리지를 계층 오프셋 범위에 사용할 수 있도록 합니다.
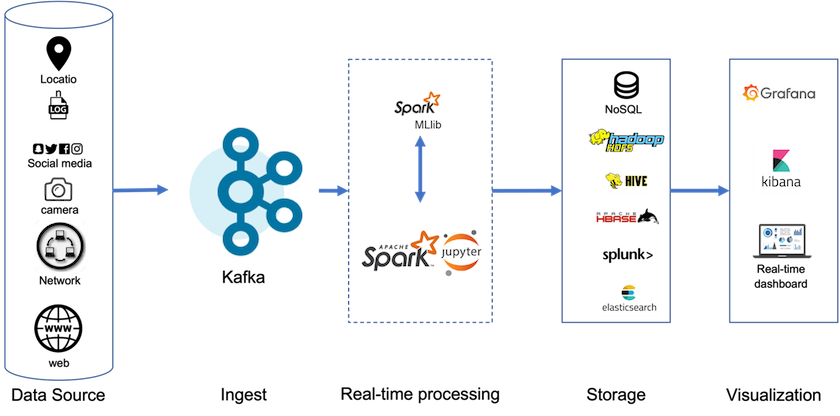
계층형 스토리지를 사용하면 스트리밍 데이터의 끝부분에 가까운 저지연 읽기 및 쓰기에 고성능 플랫폼을 사용할 수 있으며, 높은 처리량의 과거 읽기에 NetApp StorageGRID 와 같은 저렴하고 확장 가능한 개체 저장소를 사용할 수도 있습니다. 또한 NetApp 스토리지 컨트롤러를 갖춘 Spark에 대한 기술 솔루션도 있으며 자세한 내용은 여기에서 확인하세요. 다음 그림은 Kafka가 실시간 분석 파이프라인에 어떻게 적용되는지 보여줍니다.
다음 그림은 NetApp StorageGRID Confluent Kafka의 객체 스토리지 계층으로 어떻게 적용되는지 보여줍니다.