사용 사례 3: 기존 Hadoop 데이터에 DevTest 활성화
 변경 제안
변경 제안
이 사용 사례에서 고객 요구 사항은 DevTest 및 보고 목적으로 동일한 데이터 센터와 원격 위치에서 대량의 분석 데이터가 포함된 기존 Hadoop 클러스터를 기반으로 새로운 Hadoop/Spark 클러스터를 빠르고 효율적으로 구축하는 것입니다.
대본
이 시나리오에서는 대규모 Hadoop 데이터 레이크 구현을 기반으로 온프레미스와 재해 복구 위치에서 여러 개의 Spark/Hadoop 클러스터가 구축됩니다.
요구 사항 및 과제
이 사용 사례에 대한 주요 요구 사항과 과제는 다음과 같습니다.
-
DevTest, QA 또는 동일한 프로덕션 데이터에 액세스해야 하는 다른 목적을 위해 여러 개의 Hadoop 클러스터를 만듭니다. 여기서의 과제는 매우 큰 Hadoop 클러스터를 매우 공간 효율적인 방식으로 즉시 여러 번 복제하는 것입니다.
-
운영 효율성을 위해 Hadoop 데이터를 DevTest 및 보고 팀과 동기화합니다.
-
동일한 자격 증명을 사용하여 Hadoop 데이터를 프로덕션 클러스터와 새 클러스터에 분산합니다.
-
예약된 정책을 사용하면 프로덕션 클러스터에 영향을 주지 않고 효율적으로 QA 클러스터를 만들 수 있습니다.
해결책
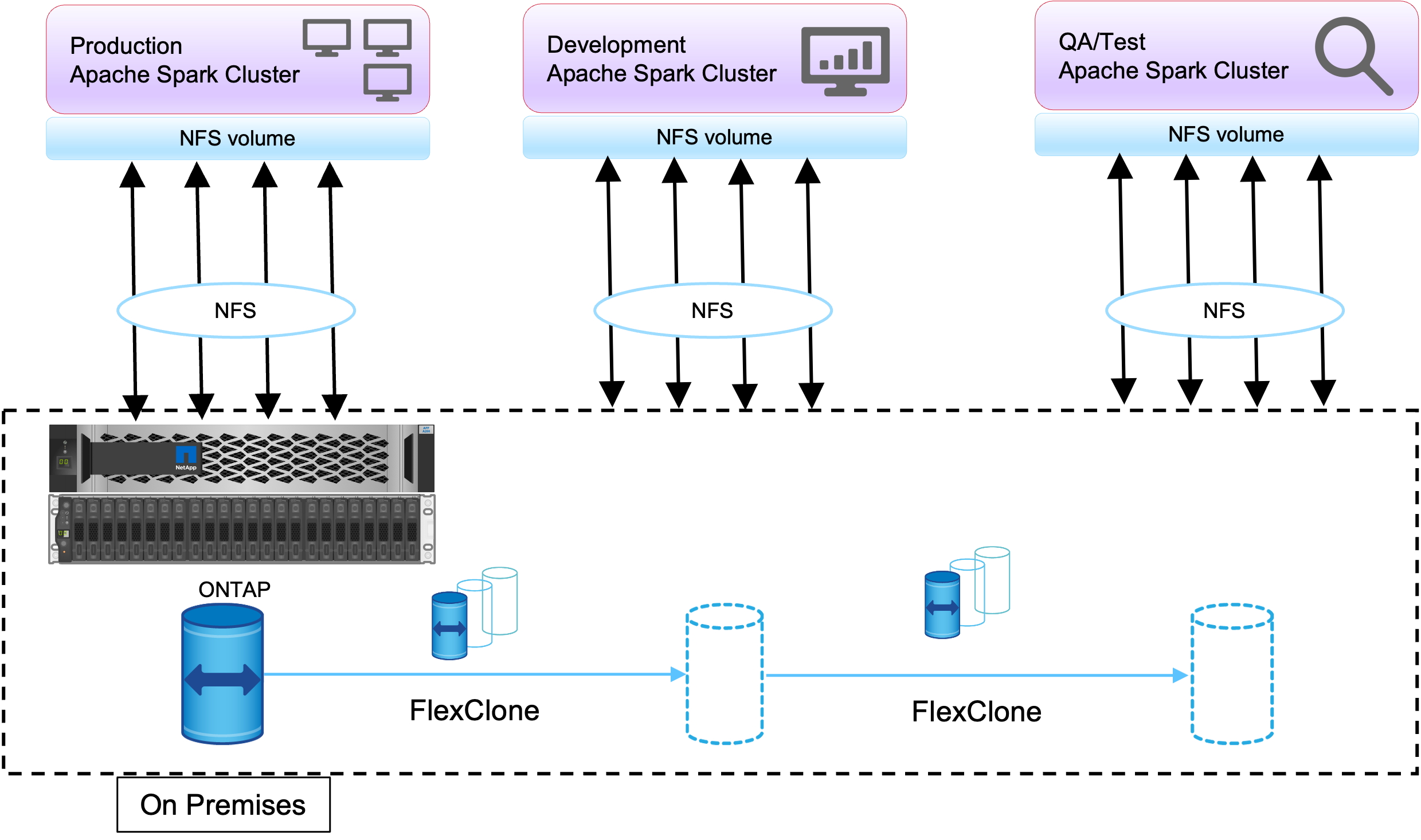
FlexClone 기술은 위에서 설명한 요구 사항에 답하는 데 사용됩니다. FlexClone 기술은 스냅샷 복사본의 읽기/쓰기 복사본입니다. 부모 스냅샷 복사본 데이터에서 데이터를 읽고 새 블록/수정된 블록에 대해서만 추가 공간을 사용합니다. 빠르고 공간 효율적입니다.
먼저, NetApp 일관성 그룹을 사용하여 기존 클러스터의 스냅샷 복사본을 만들었습니다.
NetApp System Manager 또는 스토리지 관리자 프롬프트에서 스냅샷 복사본을 생성합니다. 일관성 그룹 스냅샷 복사본은 애플리케이션 일관성 그룹 스냅샷 복사본이며, FlexClone 볼륨은 일관성 그룹 스냅샷 복사본을 기반으로 생성됩니다. FlexClone 볼륨은 부모 볼륨의 NFS 내보내기 정책을 상속한다는 점을 언급하는 것이 좋습니다. 스냅샷 복사본이 생성된 후에는 아래 그림과 같이 DevTest 및 보고 목적으로 새로운 Hadoop 클러스터를 설치해야 합니다. 새로운 Hadoop 클러스터에서 복제된 NFS 볼륨은 NFS 데이터에 액세스합니다.
이 이미지는 DevTest를 위한 Hadoop 클러스터를 보여줍니다.