

온프레미스 AFF A900 통한 성능 개요 및 검증
 변경 제안
변경 제안
온프레미스에서는 ONTAP 9.12.1RC1과 NetApp AFF A900 스토리지 컨트롤러를 사용하여 Kafka 클러스터의 성능과 확장성을 검증했습니다. 우리는 ONTAP 과 AFF 활용한 이전 계층형 스토리지 모범 사례와 동일한 테스트베드를 사용했습니다.
우리는 Confluent Kafka 6.2.0을 사용하여 AFF A900 평가했습니다. 클러스터는 8개의 브로커 노드와 3개의 주키퍼 노드로 구성됩니다. 성능 테스트를 위해 OMB 작업자 노드 5개를 사용했습니다.
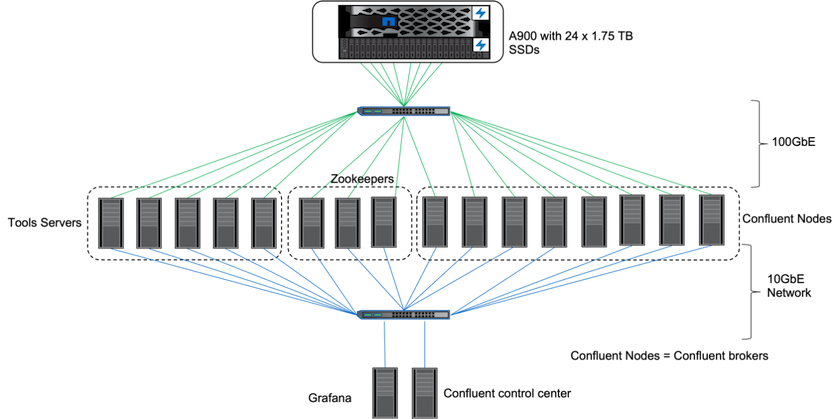
스토리지 구성
NetApp FlexGroups 인스턴스를 사용하여 로그 디렉토리에 대한 단일 네임스페이스를 제공하고, 이를 통해 복구 및 구성을 간소화했습니다. 로그 세그먼트 데이터에 대한 직접 경로 액세스를 제공하기 위해 NFSv4.1과 pNFS를 사용했습니다.
클라이언트 튜닝
각 클라이언트는 다음 명령을 사용하여 FlexGroup 인스턴스를 마운트했습니다.
mount -t nfs -o vers=4.1,nconnect=16 172.30.0.121:/kafka_vol01 /data/kafka_vol01
또한, 우리는 증가했습니다 max_session_slots` 기본값에서 64 에게 180 . 이는 ONTAP 의 기본 세션 슬롯 제한과 일치합니다.
카프카 브로커 튜닝
테스트 중인 시스템의 처리량을 극대화하기 위해 특정 주요 스레드 풀에 대한 기본 매개변수를 크게 늘렸습니다. 대부분의 구성에 대해 Confluent Kafka 모범 사례를 따르는 것이 좋습니다. 이 튜닝은 스토리지에 대한 뛰어난 I/O의 동시성을 극대화하는 데 사용되었습니다. 이러한 매개변수는 브로커의 컴퓨팅 리소스와 스토리지 속성에 맞게 조정할 수 있습니다.
num.io.threads=96 num.network.threads=96 background.threads=20 num.replica.alter.log.dirs.threads=40 num.replica.fetchers=20 queued.max.requests=2000
워크로드 생성기 테스트 방법론
처리량 드라이버와 주제 구성을 위해 클라우드 테스트와 동일한 OMB 구성을 사용했습니다.
-
FlexGroup 인스턴스는 AFF 클러스터에서 Ansible을 사용하여 프로비저닝되었습니다.
--- - name: Set up kafka broker processes hosts: localhost vars: ntap_hostname: 'hostname' ntap_username: 'user' ntap_password: 'password' size: 10 size_unit: tb vserver: vs1 state: present https: true export_policy: default volumes: - name: kafka_fg_vol01 aggr: ["aggr1_a", "aggr2_a", "aggr1_b", "aggr2_b"] path: /kafka_fg_vol01 tasks: - name: Edit volumes netapp.ontap.na_ontap_volume: state: "{{ state }}" name: "{{ item.name }}" aggr_list: "{{ item.aggr }}" aggr_list_multiplier: 8 size: "{{ size }}" size_unit: "{{ size_unit }}" vserver: "{{ vserver }}" snapshot_policy: none export_policy: default junction_path: "{{ item.path }}" qos_policy_group: none wait_for_completion: True hostname: "{{ ntap_hostname }}" username: "{{ ntap_username }}" password: "{{ ntap_password }}" https: "{{ https }}" validate_certs: false connection: local with_items: "{{ volumes }}" -
ONTAP SVM에서 pNFS가 활성화되었습니다.
vserver modify -vserver vs1 -v4.1-pnfs enabled -tcp-max-xfer-size 262144
-
작업 부하는 Cloud Volumes ONTAP 과 동일한 작업 부하 구성을 사용하여 처리량 드라이버로 트리거되었습니다. "섹션을 참조하세요.정상 상태 성능 " 아래에. 작업 부하에는 3의 복제 요소가 사용되었는데, 이는 로그 세그먼트의 3개 사본이 NFS에 유지된다는 것을 의미합니다.
sudo bin/benchmark --drivers driver-kafka/kafka-throughput.yaml workloads/1-topic-100-partitions-1kb.yaml
-
마지막으로, 우리는 소비자들이 최신 메시지를 따라잡을 수 있는 능력을 측정하기 위해 백로그를 활용한 측정을 완료했습니다. OMB는 측정 시작 시 소비자의 활동을 일시 정지시켜 백로그를 구성합니다. 이는 세 가지 뚜렷한 단계를 생성합니다. 백로그 생성(생산자 전용 트래픽), 백로그 드레이닝(소비자가 토픽에서 놓친 이벤트를 따라잡는 소비자 중심 단계), 정상 상태입니다. "섹션을 참조하세요.극한의 성능과 저장 한계 탐색 " 자세한 내용은.
정상 상태 성능
AWS의 Cloud Volumes ONTAP 과 AWS의 DAS에 대한 비교와 유사한 비교를 제공하기 위해 OpenMessaging 벤치마크를 사용하여 AFF A900 평가했습니다. 모든 성능 값은 프로듀서 및 소비자 수준에서의 카프카 클러스터 처리량을 나타냅니다.
Confluent Kafka와 AFF A900 사용한 정상 상태 성능은 제작자와 소비자 모두에서 평균 3.4GBps 이상의 처리량을 달성했습니다. 이는 Kafka 클러스터 전체에 340만 개가 넘는 메시지입니다. BrokerTopicMetrics의 초당 바이트 단위의 지속적인 처리량을 시각화하면 AFF A900 이 지원하는 뛰어난 정상 상태 성능과 트래픽을 확인할 수 있습니다.
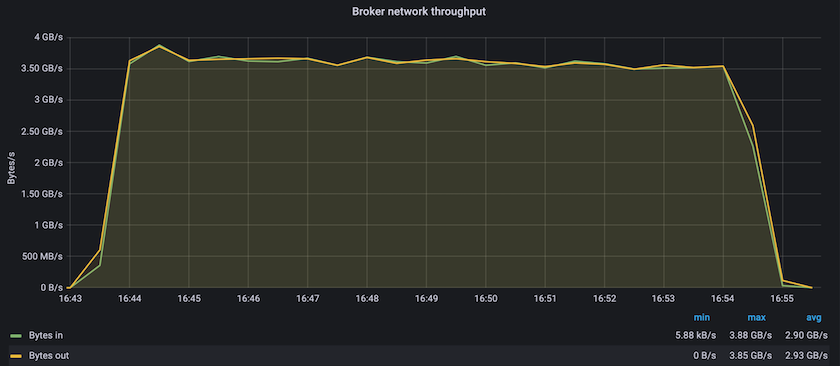
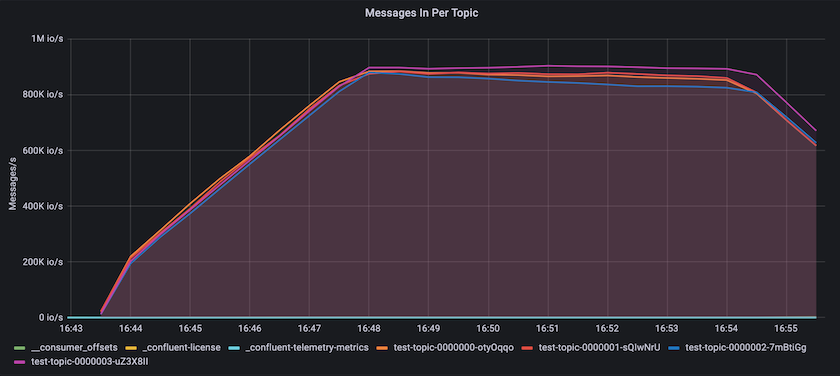
이는 주제별로 전달된 메시지의 관점과 잘 일치합니다. 다음 그래프는 주제별 분석을 제공합니다. 테스트한 구성에서는 4개 주제에 걸쳐 주제당 약 90만 개의 메시지를 확인했습니다.
극한의 성능과 저장 한계 탐색
AFF 의 경우, 백로그 기능을 사용하여 OMB에서도 테스트했습니다. 백로그 기능은 Kafka 클러스터에 이벤트 백로그가 축적되는 동안 소비자 구독을 일시 중지합니다. 이 단계에서는 프로듀서 트래픽만 발생하며, 이를 통해 로그에 커밋되는 이벤트가 생성됩니다. 이는 일괄 처리나 오프라인 분석 워크플로를 가장 밀접하게 에뮬레이션합니다. 이러한 워크플로에서 소비자 구독이 시작되고 브로커 캐시에서 이미 제거된 과거 데이터를 읽어야 합니다.
이 구성에서 소비자 처리량에 대한 저장 제한을 파악하기 위해 생산자 전용 단계를 측정하여 A900이 얼마나 많은 쓰기 트래픽을 흡수할 수 있는지 파악했습니다. 다음 섹션을 참조하세요.사이즈 가이드 "이 데이터를 활용하는 방법을 이해합니다.
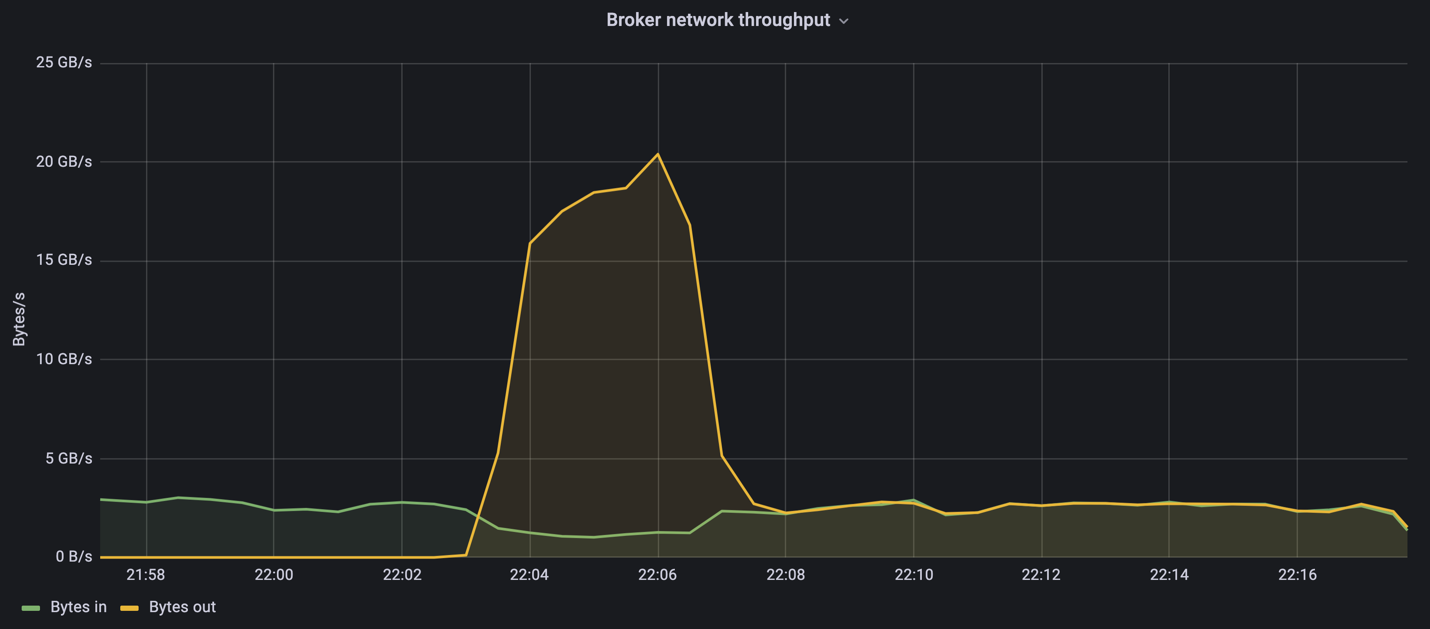
이 측정의 생산자 전용 부분에서 우리는 A900 성능의 한계를 뛰어넘는 높은 피크 처리량을 확인했습니다(생산자 및 소비자 트래픽을 제공하는 다른 브로커 리소스가 포화 상태가 아니었을 때).

|
이 측정에서는 메시지 당 오버헤드를 제한하고 NFS 마운트 지점에 대한 저장 처리량을 극대화하기 위해 메시지 크기를 16k로 늘렸습니다. |
messageSize: 16384 consumerBacklogSizeGB: 4096
Confluent Kafka 클러스터는 최대 프로듀서 처리량 4.03GBps를 달성했습니다.
18:12:23.833 [main] INFO WorkloadGenerator - Pub rate 257759.2 msg/s / 4027.5 MB/s | Pub err 0.0 err/s …
OMB가 이벤트 백로그 채우기를 완료한 후 소비자 트래픽이 다시 시작되었습니다. 백로그 드레이닝을 통한 측정 동안 모든 주제에서 최대 소비자 처리량이 20GBps가 넘는 것을 관찰했습니다. OMB 로그 데이터를 저장하는 NFS 볼륨에 대한 결합 처리량은 ~30GBps에 달했습니다.
사이즈 가이드
Amazon Web Services는 다음을 제공합니다. "사이즈 가이드" 카프카 클러스터 크기 조정 및 확장을 위한 것입니다.
이 크기 조정은 Kafka 클러스터의 스토리지 처리량 요구 사항을 결정하는 데 유용한 공식을 제공합니다.
r의 복제 인자를 사용하여 tcluster의 클러스터에 생성된 집계된 처리량의 경우, 브로커 저장소에서 수신한 처리량은 다음과 같습니다.
t[storage] = t[cluster]/#brokers + t[cluster]/#brokers * (r-1)
= t[cluster]/#brokers * r
이것은 더욱 단순화될 수 있습니다.
max(t[cluster]) <= max(t[storage]) * #brokers/r
이 공식을 사용하면 Kafka 핫 티어 요구 사항에 맞는 적절한 ONTAP 플랫폼을 선택할 수 있습니다.
다음 표는 다양한 복제 요소를 적용한 A900의 예상 생산자 처리량을 설명합니다.
| 복제 인자 | 생산자 처리량(GPps) |
|---|---|
3(측정됨) |
3.4 |
2 |
5.1 |
1 |
10.2 |