기능 검증 - 어리석은 이름 바꾸기 수정
 변경 제안
변경 제안
기능적 검증을 위해, 저장소로 NFSv3를 마운트한 Kafka 클러스터는 파티션 재분배와 같은 Kafka 작업을 수행하지 못하는 반면, 수정 사항을 적용한 NFSv4에 마운트된 다른 클러스터는 아무런 중단 없이 동일한 작업을 수행할 수 있음을 보여주었습니다.
검증 설정
설정은 AWS에서 실행됩니다. 다음 표는 검증에 사용된 다양한 플랫폼 구성 요소와 환경 구성을 보여줍니다.
| 플랫폼 구성 요소 | 환경 구성 |
|---|---|
Confluent 플랫폼 버전 7.2.1 |
|
모든 노드의 운영 체제 |
RHEL8.7 이상 |
NetApp Cloud Volumes ONTAP 인스턴스 |
단일 노드 인스턴스 – M5.2xLarge |
다음 그림은 이 솔루션의 아키텍처 구성을 보여줍니다.
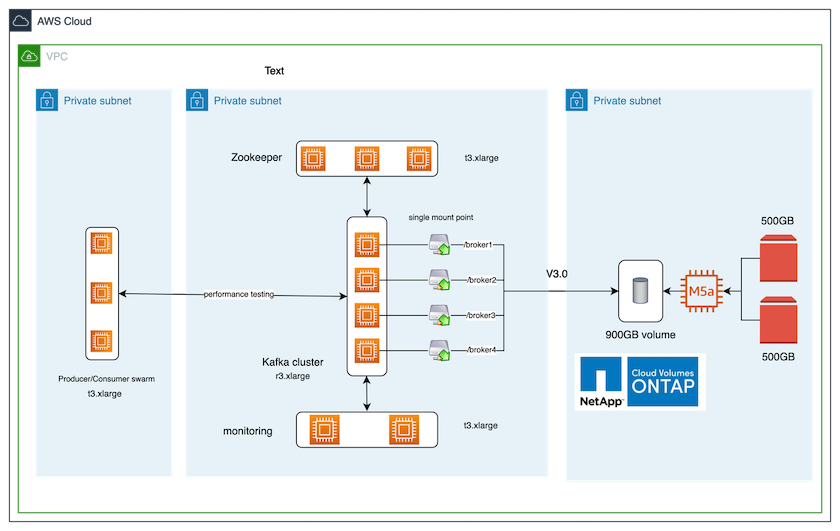
건축 흐름
-
계산합니다. 우리는 전용 서버에서 실행되는 3노드 Zookeeper 앙상블과 함께 4노드 Kafka 클러스터를 사용했습니다.
-
모니터링. 우리는 Prometheus-Grafana 조합을 위해 두 개의 노드를 사용했습니다.
-
작업량. 워크로드를 생성하기 위해 Kafka 클러스터에서 워크로드를 생산하고 소비할 수 있는 별도의 3노드 클러스터를 사용했습니다.
-
저장. 우리는 두 개의 500GB GP2 AWS-EBS 볼륨이 인스턴스에 연결된 단일 노드 NetApp Cloud Volumes ONTAP 인스턴스를 사용했습니다. 이러한 볼륨은 LIF를 통해 단일 NFSv4.1 볼륨으로 Kafka 클러스터에 노출되었습니다.
모든 서버에 대해 Kafka의 기본 속성이 선택되었습니다. 동물원 관리인 떼에도 똑같은 일이 이루어졌습니다.
테스트 방법론
-
업데이트
-is-preserve-unlink-enabled true카프카 볼륨에 다음과 같이 표시됩니다.aws-shantanclastrecall-aws::*> volume create -vserver kafka_svm -volume kafka_fg_vol01 -aggregate kafka_aggr -size 3500GB -state online -policy kafka_policy -security-style unix -unix-permissions 0777 -junction-path /kafka_fg_vol01 -type RW -is-preserve-unlink-enabled true [Job 32] Job succeeded: Successful
-
두 개의 유사한 Kafka 클러스터가 다음과 같은 차이점을 가지고 생성되었습니다.
-
클러스터 1. 프로덕션에 바로 사용할 수 있는 ONTAP 버전 9.12.1을 실행하는 백엔드 NFS v4.1 서버는 NetApp CVO 인스턴스에 의해 호스팅되었습니다. 브로커에 RHEL 8.7/RHEL 9.1이 설치되었습니다.
-
클러스터 2. 백엔드 NFS 서버는 수동으로 생성된 일반 Linux NFSv3 서버였습니다.
-
-
두 Kafka 클러스터 모두에 데모 주제가 생성되었습니다.
클러스터 1:

클러스터 2:

-
두 클러스터 모두의 새로 생성된 주제에 데이터가 로드되었습니다. 이 작업은 기본 Kafka 패키지에 포함된 producer-perf-test 툴킷을 사용하여 수행되었습니다.
./kafka-producer-perf-test.sh --topic __a_demo_topic --throughput -1 --num-records 3000000 --record-size 1024 --producer-props acks=all bootstrap.servers=172.30.0.160:9092,172.30.0.172:9092,172.30.0.188:9092,172.30.0.123:9092
-
Telnet을 사용하여 각 클러스터의 브로커-1에 대한 상태 점검을 수행했습니다.
-
텔넷
172.30.0.160 9092 -
텔넷
172.30.0.198 9092다음 스크린샷에는 두 클러스터의 브로커에 대한 성공적인 상태 검사가 표시됩니다.
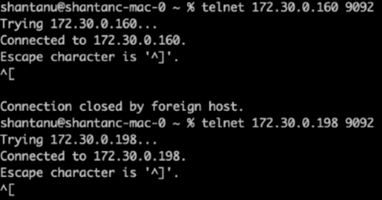
-
-
NFSv3 스토리지 볼륨을 사용하는 Kafka 클러스터가 충돌하는 오류 조건을 트리거하기 위해 두 클러스터 모두에서 파티션 재할당 프로세스를 시작했습니다. 파티션 재할당은 다음을 사용하여 수행되었습니다.
kafka-reassign-partitions.sh. 자세한 과정은 다음과 같습니다.-
Kafka 클러스터의 주제에 대한 파티션을 재할당하기 위해 제안된 재할당 구성 JSON을 생성했습니다(이 작업은 두 클러스터 모두에서 수행되었습니다).
kafka-reassign-partitions --bootstrap-server=172.30.0.160:9092,172.30.0.172:9092,172.30.0.188:9092,172.30.0.123:9092 --broker-list "1,2,3,4" --topics-to-move-json-file /tmp/topics.json --generate
-
생성된 재할당 JSON은 다음에 저장되었습니다.
/tmp/reassignment- file.json. -
실제 파티션 재할당 프로세스는 다음 명령에 의해 트리거되었습니다.
kafka-reassign-partitions --bootstrap-server=172.30.0.198:9092,172.30.0.163:9092,172.30.0.221:9092,172.30.0.204:9092 --reassignment-json-file /tmp/reassignment-file.json –execute
-
-
재할당이 완료된 후 몇 분 후에 브로커에서 실시한 또 다른 상태 점검에서 NFSv3 스토리지 볼륨을 사용하는 클러스터가 어리석은 이름 바꾸기 문제에 부딪혀 충돌했지만, 수정된 NetApp ONTAP NFSv4.1 스토리지 볼륨을 사용하는 클러스터 1은 중단 없이 작업을 계속 진행한 것으로 나타났습니다.
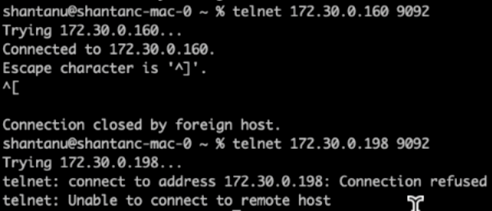
-
Cluster1-Broker-1은 활성화되어 있습니다.
-
Cluster2-broker-1이 죽었습니다.
-
-
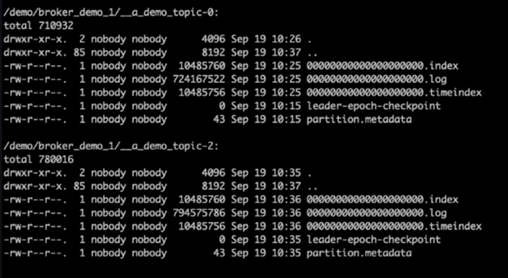
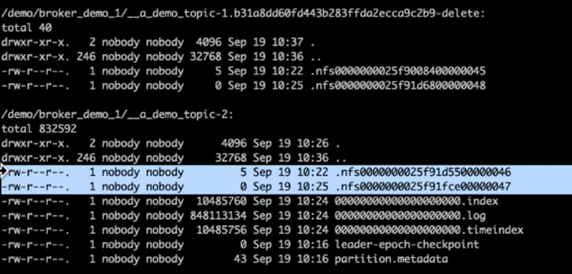
Kafka 로그 디렉터리를 확인한 결과, NetApp ONTAP NFSv4.1 스토리지 볼륨을 수정하여 사용하는 클러스터 1은 파티션이 깔끔하게 할당되었지만, 일반 NFSv3 스토리지를 사용하는 클러스터 2는 어리석은 이름 변경 문제로 인해 파티션이 깔끔하게 할당되지 않아 충돌이 발생한 것이 분명했습니다. 다음 그림은 클러스터 2의 파티션 재조정을 보여주는데, 이로 인해 NFSv3 스토리지에서 어리석은 이름 변경 문제가 발생했습니다.
다음 그림은 NetApp NFSv4.1 스토리지를 사용하여 클러스터 1의 깔끔한 파티션 재조정을 보여줍니다.