Kafka 워크로드에 NetApp NFS를 사용해야 하는 이유는 무엇입니까?
 변경 제안
변경 제안
이제 Kafka를 사용하여 NFS 스토리지의 어리석은 이름 변경 문제에 대한 솔루션이 있으므로 Kafka 워크로드에 NetApp ONTAP 스토리지를 활용하는 강력한 배포를 만들 수 있습니다. 이렇게 하면 운영 오버헤드가 크게 줄어들 뿐만 아니라, Kafka 클러스터에 다음과 같은 이점도 제공됩니다.
-
Kafka 브로커의 CPU 사용률이 감소했습니다. 분산된 NetApp ONTAP 스토리지를 사용하면 디스크 I/O 작업이 브로커에서 분리되어 CPU 사용량이 줄어듭니다.
-
더 빠른 브로커 복구 시간. 분산된 NetApp ONTAP 스토리지는 Kafka 브로커 노드 전체에서 공유되므로, 기존 Kafka 배포에 비해 데이터를 다시 빌드하지 않고도 새로운 컴퓨팅 인스턴스가 언제든지 잘못된 브로커를 대체할 수 있는 시간이 훨씬 단축됩니다.
-
저장 효율성. 이제 애플리케이션의 스토리지 계층이 NetApp ONTAP 통해 프로비저닝되므로 고객은 인라인 데이터 압축, 중복 제거, 압축과 같은 ONTAP 이 제공하는 모든 스토리지 효율성 이점을 활용할 수 있습니다.
이러한 이점은 이 섹션에서 자세히 설명하는 테스트 사례에서 테스트되고 검증되었습니다.
Kafka 브로커의 CPU 사용률 감소
기술 사양은 동일하지만 저장 기술이 다른 두 개의 별도의 Kafka 클러스터에서 유사한 작업 부하를 실행했을 때, 전반적인 CPU 사용률이 DAS 대응 제품보다 낮다는 것을 발견했습니다. Kafka 클러스터가 ONTAP 스토리지를 사용하면 전반적인 CPU 사용률이 낮을 뿐만 아니라 CPU 사용률의 증가 폭도 DAS 기반 Kafka 클러스터보다 완만했습니다.
건축적 설정
다음 표는 CPU 사용률을 낮추는 데 사용된 환경 구성을 보여줍니다.
| 플랫폼 구성 요소 | 환경 구성 |
|---|---|
Kafka 3.2.3 벤치마킹 도구: OpenMessaging |
|
모든 노드의 운영 체제 |
RHEL 8.7 이상 |
NetApp Cloud Volumes ONTAP 인스턴스 |
단일 노드 인스턴스 – M5.2xLarge |
벤치마킹 도구
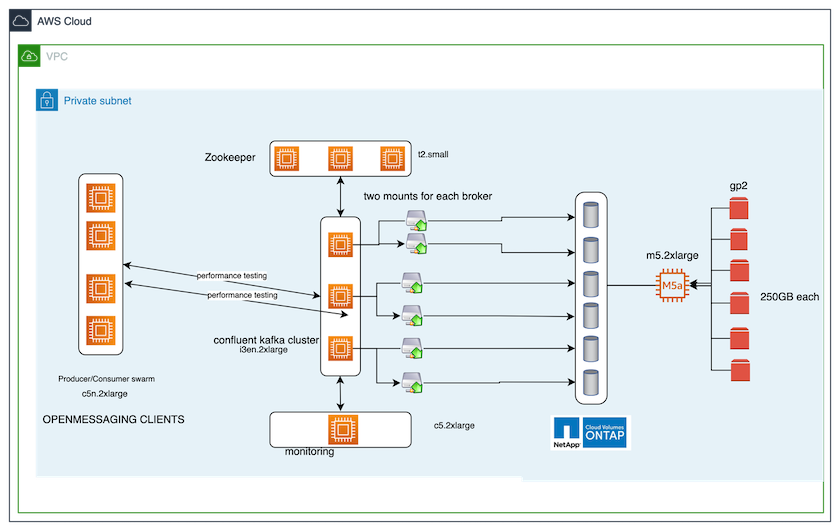
이 테스트 케이스에서 사용된 벤치마킹 도구는 다음과 같습니다. "오픈메시징" 뼈대. OpenMessaging은 공급업체와 언어에 구애받지 않습니다. 금융, 전자상거래, IoT, 빅데이터에 대한 산업 가이드라인을 제공하며, 이기종 시스템과 플랫폼에서 메시징 및 스트리밍 애플리케이션을 개발하는 데 도움이 됩니다. 다음 그림은 OpenMessaging 클라이언트와 Kafka 클러스터의 상호작용을 보여줍니다.
-
계산합니다. 우리는 전용 서버에서 실행되는 3노드 Zookeeper 앙상블과 함께 3노드 Kafka 클러스터를 사용했습니다. 각 브로커는 전용 LIF를 통해 NetApp CVO 인스턴스의 단일 볼륨에 대한 두 개의 NFSv4.1 마운트 포인트를 가졌습니다.
-
모니터링. 우리는 Prometheus-Grafana 조합을 위해 두 개의 노드를 사용했습니다. 워크로드를 생성하기 위해 Kafka 클러스터에서 워크로드를 생산하고 소비할 수 있는 별도의 3노드 클러스터가 있습니다.
-
저장. 6개의 250GB GP2 AWS-EBS 볼륨이 인스턴스에 마운트된 단일 노드 NetApp Cloud Volumes ONTAP 인스턴스를 사용했습니다. 이러한 볼륨은 전용 LIF를 통해 6개의 NFSv4.1 볼륨으로 Kafka 클러스터에 노출되었습니다.
-
구성. 이 테스트 사례에서 구성 가능한 두 가지 요소는 Kafka 브로커와 OpenMessaging 워크로드였습니다.
-
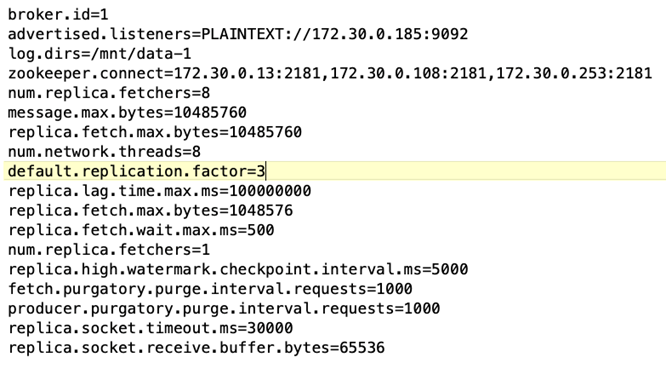
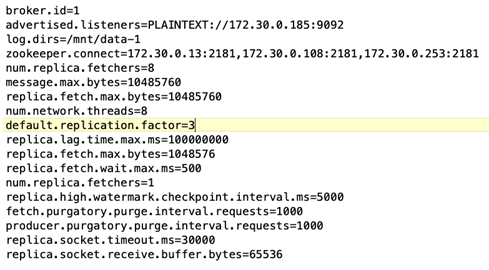
브로커 구성. 다음은 Kafka 브로커에 대해 선택된 사양입니다. 아래에 강조된 것처럼 모든 측정에 대해 복제 계수 3을 사용했습니다.
-
-
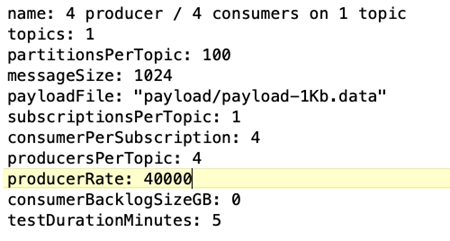
OpenMessaging 벤치마크(OMB) 워크로드 구성. 다음과 같은 사양이 제공되었습니다. 우리는 아래에 강조된 목표 생산자 요율을 지정했습니다.
테스트 방법론
-
두 개의 유사한 클러스터가 생성되었으며, 각각 고유한 벤치마킹 클러스터 군집이 있습니다.
-
클러스터 1. NFS 기반 카프카 클러스터.
-
클러스터 2. DAS 기반 카프카 클러스터.
-
-
OpenMessaging 명령을 사용하여 각 클러스터에서 유사한 작업 부하가 트리거되었습니다.
sudo bin/benchmark --drivers driver-kafka/kafka-group-all.yaml workloads/1-topic-100-partitions-1kb.yaml
-
생산율 구성은 4번의 반복을 거쳐 증가하였고, Grafana를 사용하여 CPU 사용률을 기록했습니다. 생산율은 다음 수준으로 설정되었습니다.
-
10,000
-
40,000
-
80,000
-
100,000
-
관찰
Kafka와 함께 NetApp NFS 스토리지를 사용하면 두 가지 주요 이점이 있습니다.
-
CPU 사용량을 약 1/3까지 줄일 수 있습니다. 유사한 작업 부하에서 NFS의 전반적인 CPU 사용량은 DAS SSD보다 낮았습니다. 생성률이 낮을수록 절감 효과가 5%, 생성률이 높을수록 절감 효과가 32%에 달했습니다.
-
생산 속도가 높을수록 CPU 사용률 변동이 3배 감소합니다. 예상대로, 생산율이 증가함에 따라 CPU 활용도가 위쪽으로 증가했습니다. 그러나 DAS를 사용하는 Kafka 브로커의 CPU 사용률은 낮은 생성률의 경우 31%에서 높은 생성률의 경우 70%로 39% 증가했습니다. 하지만 NFS 스토리지 백엔드를 사용하면 CPU 사용률이 26%에서 38%로 12% 증가했습니다.
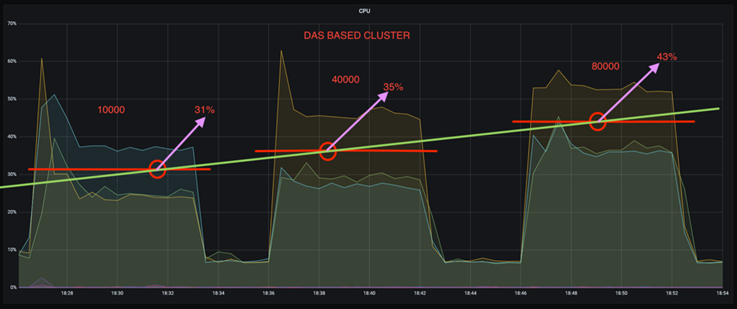
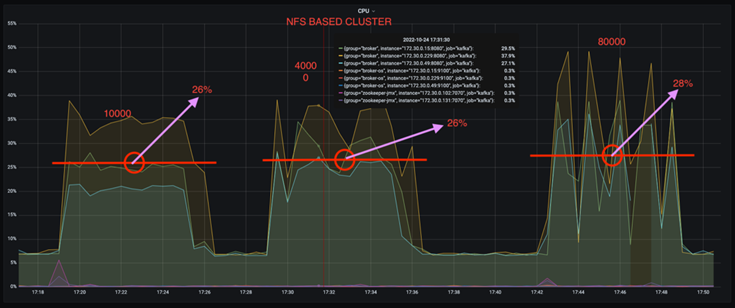
또한 100,000개의 메시지에서 DAS는 NFS 클러스터보다 CPU 사용률이 더 높습니다.
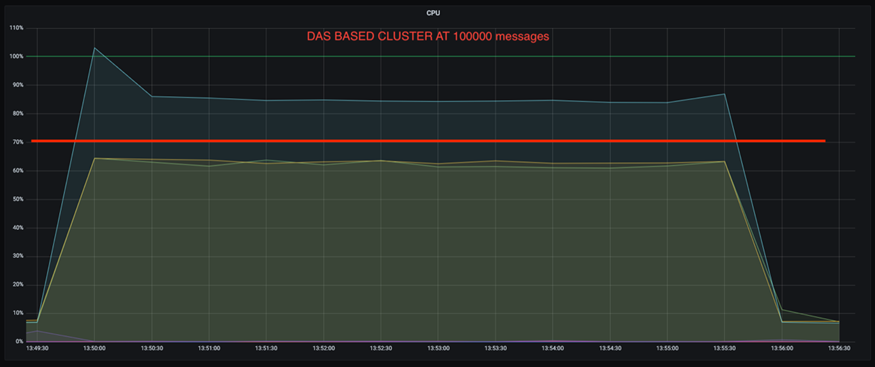
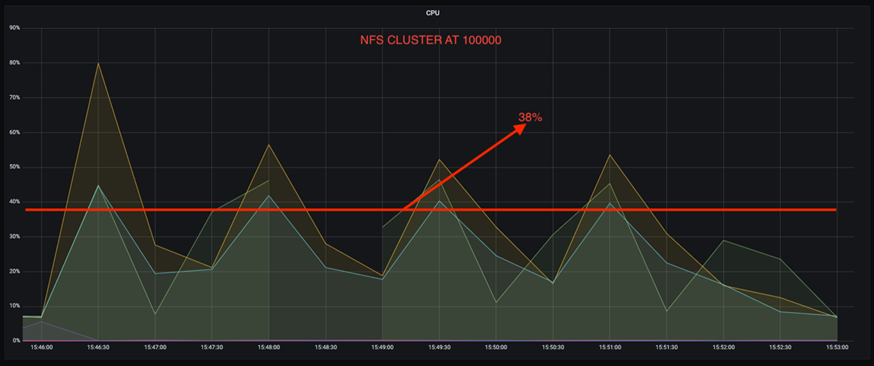
더 빠른 브로커 회복
Kafka 브로커가 공유 NetApp NFS 스토리지를 사용할 경우 복구 속도가 더 빨라진다는 것을 발견했습니다. Kafka 클러스터에서 브로커가 충돌하는 경우, 이 브로커는 동일한 브로커 ID를 가진 정상적인 브로커로 교체될 수 있습니다. 이 테스트 사례를 수행한 결과, DAS 기반 Kafka 클러스터의 경우 클러스터가 새로 추가된 정상적인 브로커에서 데이터를 다시 구축하는데, 이는 시간이 많이 소요되는 작업이라는 것을 발견했습니다. NetApp NFS 기반 Kafka 클러스터의 경우, 교체 브로커는 이전 로그 디렉토리에서 데이터를 계속 읽고 훨씬 빠르게 복구합니다.
건축적 설정
다음 표는 NAS를 사용하는 Kafka 클러스터의 환경 구성을 보여줍니다.
| 플랫폼 구성 요소 | 환경 구성 |
|---|---|
카프카 3.2.3 |
|
모든 노드의 운영 체제 |
RHEL8.7 이상 |
NetApp Cloud Volumes ONTAP 인스턴스 |
단일 노드 인스턴스 – M5.2xLarge |
다음 그림은 NAS 기반 Kafka 클러스터의 아키텍처를 보여줍니다.
-
계산합니다. 전용 서버에서 실행되는 3노드 Zookeeper 앙상블을 갖춘 3노드 Kafka 클러스터입니다. 각 브로커는 전용 LIF를 통해 NetApp CVO 인스턴스의 단일 볼륨에 대한 두 개의 NFS 마운트 지점을 갖습니다.
-
모니터링. Prometheus-Grafana 조합을 위한 두 개의 노드. 워크로드를 생성하기 위해 이 Kafka 클러스터에서 워크로드를 생성하고 소비할 수 있는 별도의 3노드 클러스터를 사용합니다.
-
저장. 6개의 250GB GP2 AWS-EBS 볼륨이 인스턴스에 마운트된 단일 노드 NetApp Cloud Volumes ONTAP 인스턴스입니다. 이러한 볼륨은 전용 LIF를 통해 6개의 NFS 볼륨으로 Kafka 클러스터에 노출됩니다.
-
브로커 구성. 이 테스트 사례에서 구성 가능한 요소 중 하나는 Kafka 브로커입니다. 다음은 Kafka 브로커에 대해 선택된 사양입니다. 그만큼
replica.lag.time.mx.ms특정 노드가 ISR 목록에서 얼마나 빨리 제거되는지를 결정하기 때문에 높은 값으로 설정됩니다. 불량 노드와 정상 노드 사이를 전환할 때 해당 브로커 ID가 ISR 목록에서 제외되는 것을 원하지 않을 것입니다.
테스트 방법론
-
두 개의 유사한 클러스터가 생성되었습니다.
-
EC2 기반 합류 클러스터.
-
NetApp NFS 기반 합류 클러스터.
-
-
원래 Kafka 클러스터의 노드와 동일한 구성을 가진 대기 Kafka 노드 하나가 생성되었습니다.
-
각 클러스터에서 샘플 토픽이 생성되었고, 각 브로커에 약 110GB의 데이터가 채워졌습니다.
-
EC2 기반 클러스터. Kafka 브로커 데이터 디렉토리는 다음에 매핑됩니다.
/mnt/data-2(다음 그림에서 cluster1의 Broker-1[왼쪽 터미널]). -
* NetApp NFS 기반 클러스터.* Kafka 브로커 데이터 디렉토리는 NFS 지점에 마운트됩니다.
/mnt/data(다음 그림에서 클러스터2의 Broker-1[오른쪽 터미널]).
-
-
각 클러스터에서 Broker-1이 종료되어 실패한 브로커 복구 프로세스가 시작되었습니다.
-
브로커가 종료된 후 브로커 IP 주소는 대기 브로커의 보조 IP로 할당되었습니다. 이는 Kafka 클러스터의 브로커가 다음으로 식별되기 때문에 필요했습니다.
-
IP 주소. 실패한 브로커 IP를 대기 브로커에 재할당하여 할당됩니다.
-
브로커 ID. 이는 대기 브로커에서 구성되었습니다.
server.properties.
-
-
IP 할당 시, 대기 브로커에서 Kafka 서비스가 시작되었습니다.
-
얼마 후, 클러스터의 교체 노드에서 데이터를 빌드하는 데 걸리는 시간을 확인하기 위해 서버 로그를 뽑았습니다.
관찰
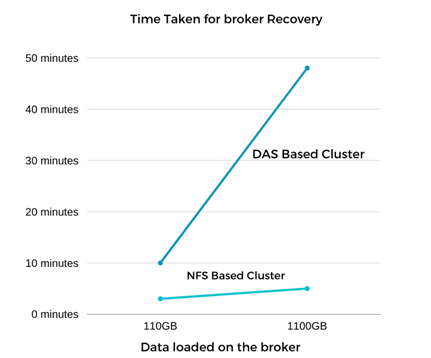
카프카 브로커 복구가 거의 9배 더 빨랐습니다. Kafka 클러스터에서 DAS SSD를 사용하는 것보다 NetApp NFS 공유 스토리지를 사용하면 실패한 브로커 노드를 복구하는 데 걸리는 시간이 훨씬 빠른 것으로 나타났습니다. 1TB의 주제 데이터에 대해 DAS 기반 클러스터의 복구 시간은 48분이었고, NetApp-NFS 기반 Kafka 클러스터의 경우 5분 미만이었습니다.
EC2 기반 클러스터는 새로운 브로커 노드에서 110GB의 데이터를 재구축하는 데 10분이 걸렸지만, NFS 기반 클러스터는 3분 만에 복구를 완료했습니다. 또한 EC2의 파티션에 대한 소비자 오프셋이 0인 반면, NFS 클러스터에서는 소비자 오프셋이 이전 브로커에서 수집된 것을 로그에서 확인했습니다.
[2022-10-31 09:39:17,747] INFO [LogLoader partition=test-topic-51R3EWs-0000-55, dir=/mnt/kafka-data/broker2] Reloading from producer snapshot and rebuilding producer state from offset 583999 (kafka.log.UnifiedLog$) [2022-10-31 08:55:55,170] INFO [LogLoader partition=test-topic-qbVsEZg-0000-8, dir=/mnt/data-1] Loading producer state till offset 0 with message format version 2 (kafka.log.UnifiedLog$)
DAS 기반 클러스터
-
백업 노드는 08:55:53,730에 시작되었습니다.

-
데이터 재구축 프로세스는 09:05:24,860에 종료되었습니다. 110GB의 데이터를 처리하는 데 약 10분이 걸렸습니다.

NFS 기반 클러스터
-
백업 노드는 09:39:17,213에 시작되었습니다. 시작 로그 항목은 아래에 강조 표시되어 있습니다.

-
데이터 재구축 프로세스는 09:42:29,115에 종료되었습니다. 110GB의 데이터를 처리하는 데 약 3분이 걸렸습니다.

약 1TB의 데이터를 담고 있는 브로커에 대해 테스트를 반복한 결과, DAS의 경우 약 48분, NFS의 경우 3분이 걸렸습니다. 결과는 다음 그래프에 나타나 있습니다.
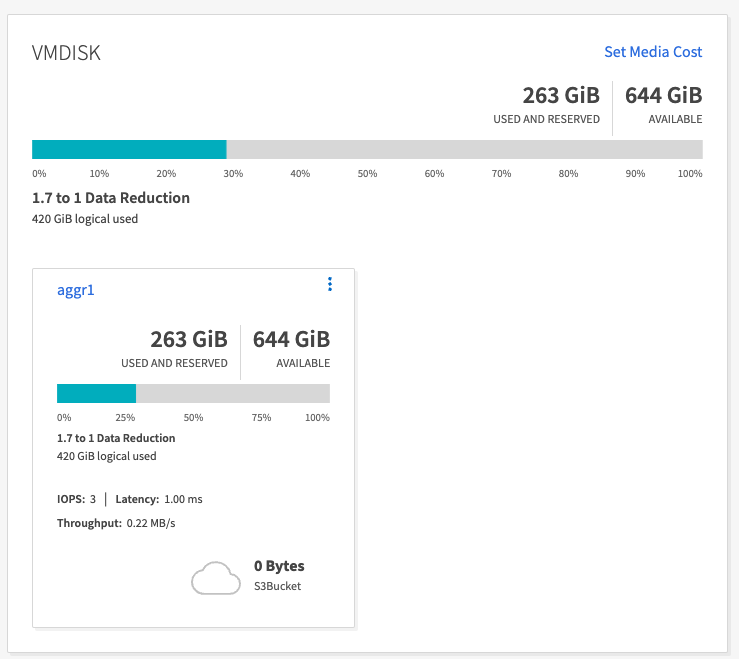
스토리지 효율성
Kafka 클러스터의 스토리지 계층은 NetApp ONTAP 통해 프로비저닝되었기 때문에 ONTAP 의 모든 스토리지 효율성 기능을 얻을 수 있었습니다. 이는 Cloud Volumes ONTAP 에 프로비저닝된 NFS 스토리지를 사용하여 Kafka 클러스터에서 상당한 양의 데이터를 생성하여 테스트되었습니다. ONTAP 기능으로 인해 상당한 공간 감소가 발생했음을 알 수 있었습니다.
건축적 설정
다음 표는 NAS를 사용하는 Kafka 클러스터의 환경 구성을 보여줍니다.
| 플랫폼 구성 요소 | 환경 구성 |
|---|---|
카프카 3.2.3 |
|
모든 노드의 운영 체제 |
RHEL8.7 이상 |
NetApp Cloud Volumes ONTAP 인스턴스 |
단일 노드 인스턴스 – M5.2xLarge |
다음 그림은 NAS 기반 Kafka 클러스터의 아키텍처를 보여줍니다.
-
계산합니다. 우리는 전용 서버에서 실행되는 3노드 Zookeeper 앙상블과 함께 3노드 Kafka 클러스터를 사용했습니다. 각 브로커는 전용 LIF를 통해 NetApp CVO 인스턴스의 단일 볼륨에 대한 두 개의 NFS 마운트 지점을 갖고 있었습니다.
-
모니터링. 우리는 Prometheus-Grafana 조합을 위해 두 개의 노드를 사용했습니다. 워크로드를 생성하기 위해 이 Kafka 클러스터에서 워크로드를 생성하고 소비할 수 있는 별도의 3노드 클러스터를 사용했습니다.
-
저장. 우리는 6개의 250GB GP2 AWS-EBS 볼륨이 인스턴스에 마운트된 단일 노드 NetApp Cloud Volumes ONTAP 인스턴스를 사용했습니다. 이러한 볼륨은 전용 LIF를 통해 6개의 NFS 볼륨으로 Kafka 클러스터에 노출되었습니다.
-
구성. 이 테스트 사례에서 구성 가능한 요소는 Kafka 브로커였습니다.
생산자 측에서는 압축을 해제하여 생산자가 높은 처리량을 창출할 수 있게 했습니다. 대신 저장 효율성은 컴퓨팅 계층에서 처리되었습니다.
테스트 방법론
-
카프카 클러스터는 위에 언급된 사양에 따라 제공되었습니다.
-
클러스터에서는 OpenMessaging 벤치마킹 도구를 사용하여 약 350GB의 데이터가 생성되었습니다.
-
작업 부하가 완료된 후 ONTAP System Manager와 CLI를 사용하여 스토리지 효율성 통계를 수집했습니다.
관찰
OMB 도구를 사용하여 생성된 데이터의 경우 저장 효율성 비율이 1.70:1로 약 33%의 공간 절약 효과를 보였습니다. 다음 그림에서 볼 수 있듯이, 생성된 데이터가 사용하는 논리적 공간은 420.3GB이고, 데이터를 보관하는 데 사용된 물리적 공간은 281.7GB였습니다.