

예시 사용 사례 - TensorFlow 학습 작업
 변경 제안
변경 제안
이 섹션에서는 NVIDIA AI Enterprise 환경 내에서 TensorFlow 학습 작업을 실행하기 위해 수행해야 하는 작업에 대해 설명합니다.
필수 조건
이 섹션에 설명된 단계를 수행하기 전에 이미 다음 지침에 따라 게스트 VM 템플릿을 생성했다고 가정합니다."설정" 페이지.
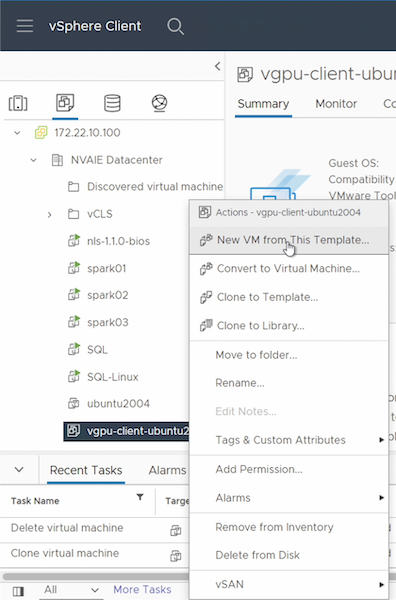
템플릿에서 게스트 VM 만들기
먼저, 이전 섹션에서 만든 템플릿에서 새 게스트 VM을 만들어야 합니다. 템플릿에서 새 게스트 VM을 만들려면 VMware vSphere에 로그인하고 템플릿 이름을 마우스 오른쪽 버튼으로 클릭한 다음 '이 템플릿에서 새 VM…'을 선택하고 마법사를 따르세요.
데이터 볼륨 생성 및 마운트
다음으로, 훈련 데이터 세트를 저장할 새로운 데이터 볼륨을 만들어야 합니다. NetApp DataOps Toolkit을 사용하면 새로운 데이터 볼륨을 빠르게 만들 수 있습니다. 다음 예제 명령은 2TB 용량의 'imagenet'이라는 볼륨을 생성하는 것을 보여줍니다.
$ netapp_dataops_cli.py create vol -n imagenet -s 2TB
데이터 볼륨에 데이터를 채우려면 먼저 게스트 VM 내에서 해당 볼륨을 마운트해야 합니다. NetApp DataOps Toolkit을 사용하면 데이터 볼륨을 빠르게 마운트할 수 있습니다. 다음 예제 명령은 이전 단계에서 생성된 볼륨의 마운트를 보여줍니다.
$ sudo -E netapp_dataops_cli.py mount vol -n imagenet -m ~/imagenet
데이터 볼륨 채우기
새 볼륨이 프로비저닝되고 마운트된 후에는 소스 위치에서 교육 데이터 세트를 검색하여 새 볼륨에 배치할 수 있습니다. 일반적으로 이 작업에는 S3 또는 Hadoop 데이터 레이크에서 데이터를 가져오는 작업이 포함되며, 때로는 데이터 엔지니어의 도움이 필요하기도 합니다.
TensorFlow 학습 작업 실행
이제 TensorFlow 학습 작업을 실행할 준비가 되었습니다. TensorFlow 학습 작업을 실행하려면 다음 작업을 수행하세요.
-
NVIDIA NGC 엔터프라이즈 TensorFlow 컨테이너 이미지를 가져옵니다.
$ sudo docker pull nvcr.io/nvaie/tensorflow-2-1:22.05-tf1-nvaie-2.1-py3
-
NVIDIA NGC 엔터프라이즈 TensorFlow 컨테이너 인스턴스를 실행합니다. 컨테이너에 데이터 볼륨을 연결하려면 '-v' 옵션을 사용하세요.
$ sudo docker run --gpus all -v ~/imagenet:/imagenet -it --rm nvcr.io/nvaie/tensorflow-2-1:22.05-tf1-nvaie-2.1-py3
-
컨테이너 내에서 TensorFlow 학습 프로그램을 실행합니다. 다음 예제 명령은 컨테이너 이미지에 포함된 ResNet-50 학습 프로그램의 실행을 보여줍니다.
$ python ./nvidia-examples/cnn/resnet.py --layers 50 -b 64 -i 200 -u batch --precision fp16 --data_dir /imagenet/data