

벡터 데이터베이스 성능 검증
 변경 제안
변경 제안
이 섹션에서는 벡터 데이터베이스에서 수행된 성능 검증을 강조합니다.
성능 검증
성능 검증은 벡터 데이터베이스와 저장 시스템 모두에서 중요한 역할을 하며, 최적의 운영과 효율적인 리소스 활용을 보장하는 핵심 요소로 작용합니다. 고차원 데이터를 처리하고 유사성 검색을 실행하는 것으로 알려진 벡터 데이터베이스는 복잡한 쿼리를 빠르고 정확하게 처리하기 위해 높은 성능 수준을 유지해야 합니다. 성능 검증은 병목 현상을 파악하고, 구성을 미세하게 조정하고, 시스템이 서비스 저하 없이 예상되는 부하를 처리할 수 있는지 확인하는 데 도움이 됩니다. 마찬가지로 저장 시스템에서도 성능 검증은 데이터가 효율적으로 저장되고 검색되며, 전반적인 시스템 성능에 영향을 줄 수 있는 지연 문제나 병목 현상이 발생하지 않도록 하는 데 필수적입니다. 또한, 스토리지 인프라의 필요한 업그레이드나 변경에 대한 정보에 입각한 결정을 내리는 데 도움이 됩니다. 따라서 성능 검증은 시스템 관리의 중요한 측면이며, 높은 서비스 품질, 운영 효율성, 전반적인 시스템 안정성을 유지하는 데 크게 기여합니다.
이 섹션에서는 Milvus 및 pgvecto.rs와 같은 벡터 데이터베이스의 성능 검증을 자세히 살펴보고, LLM 수명 주기 내에서 RAG 및 추론 워크로드를 지원하는 I/O 프로필 및 netapp 스토리지 컨트롤러 동작과 같은 스토리지 성능 특성에 중점을 둡니다. 이러한 데이터베이스를 ONTAP 스토리지 솔루션과 결합하면 성능상의 차이점을 평가하고 파악할 것입니다. 당사의 분석은 초당 처리되는 쿼리 수(QPS)와 같은 핵심 성과 지표를 기반으로 진행됩니다.
아래에서 밀부스와 진행 상황에 사용된 방법론을 확인하세요.
세부 |
Milvus(독립형 및 클러스터) |
Postgres(pgvecto.rs) # |
버전 |
2.3.2 |
0.2.0 |
파일 시스템 |
iSCSI LUN의 XFS |
|
워크로드 생성기 |
"VectorDB-벤치"– v0.0.5 |
|
데이터 세트 |
LAION 데이터 세트 * 1,000만 개의 임베딩 * 768개의 차원 * ~300GB 데이터 세트 크기 |
|
스토리지 컨트롤러 |
AFF 800 * 버전 – 9.14.1 * 4 x 100GbE – milvus용 및 2 x 100GbE – postgres용 * iscsi |
Milvus 독립형 클러스터가 포함된 VectorDB-Bench
우리는 vectorDB-Bench를 사용하여 milvus 독립형 클러스터에서 다음과 같은 성능 검증을 수행했습니다. milvus 독립형 클러스터의 네트워크 및 서버 연결성은 아래와 같습니다.
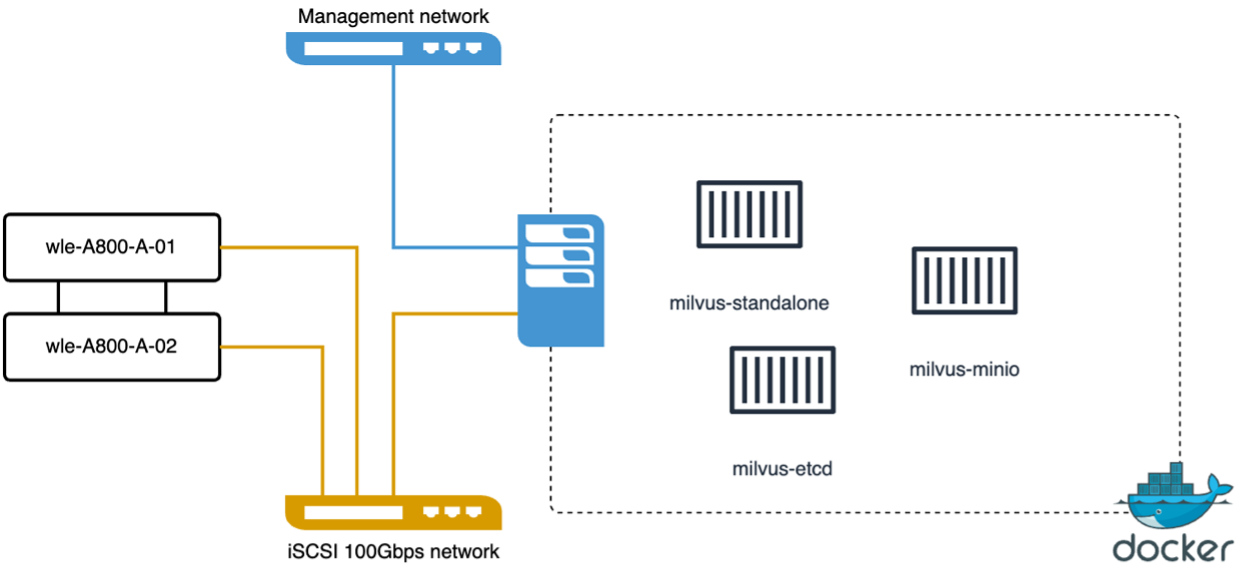
이 섹션에서는 Milvus 독립형 데이터베이스를 테스트하여 얻은 관찰 결과와 결과를 공유합니다. . 우리는 이러한 테스트의 인덱스 유형으로 DiskANN을 선택했습니다. . 약 100GB 규모의 데이터 세트를 수집, 최적화하고 인덱스를 생성하는 데 약 5시간이 걸렸습니다. 이 기간의 대부분 동안, 하이퍼스레딩이 활성화된 경우 40개의 vcpu에 해당하는 20개의 코어를 갖춘 Milvus 서버는 최대 CPU 용량인 100%로 작동했습니다. DiskANN은 시스템 메모리 크기를 초과하는 대규모 데이터 세트에 특히 중요하다는 것을 발견했습니다. . 쿼리 단계에서 우리는 0.9987의 회수율로 초당 쿼리 수(QPS) 10.93을 관찰했습니다. 쿼리에 대한 99번째 백분위수 지연 시간은 708.2밀리초로 측정되었습니다.
저장 관점에서 볼 때, 데이터베이스는 수집, 삽입 후 최적화, 인덱스 생성 단계에서 초당 약 1,000개의 작업을 실행했습니다. 쿼리 단계에서는 초당 32,000개의 작업이 요구되었습니다.
다음 섹션에서는 스토리지 성능 측정 항목을 소개합니다.
| 작업 부하 단계 | 미터법 | 가치 |
|---|---|---|
데이터 수집 및 삽입 후 최적화 |
아이옵스 |
< 1,000 |
숨어 있음 |
< 400유초 |
|
작업량 |
읽기/쓰기 혼합, 주로 쓰기 |
|
IO 크기 |
64KB |
|
질문 |
아이옵스 |
최고 32,000 |
숨어 있음 |
< 400유초 |
|
작업량 |
100% 캐시된 읽기 |
|
IO 크기 |
대부분 8KB |
vectorDB-bench 결과는 아래와 같습니다.
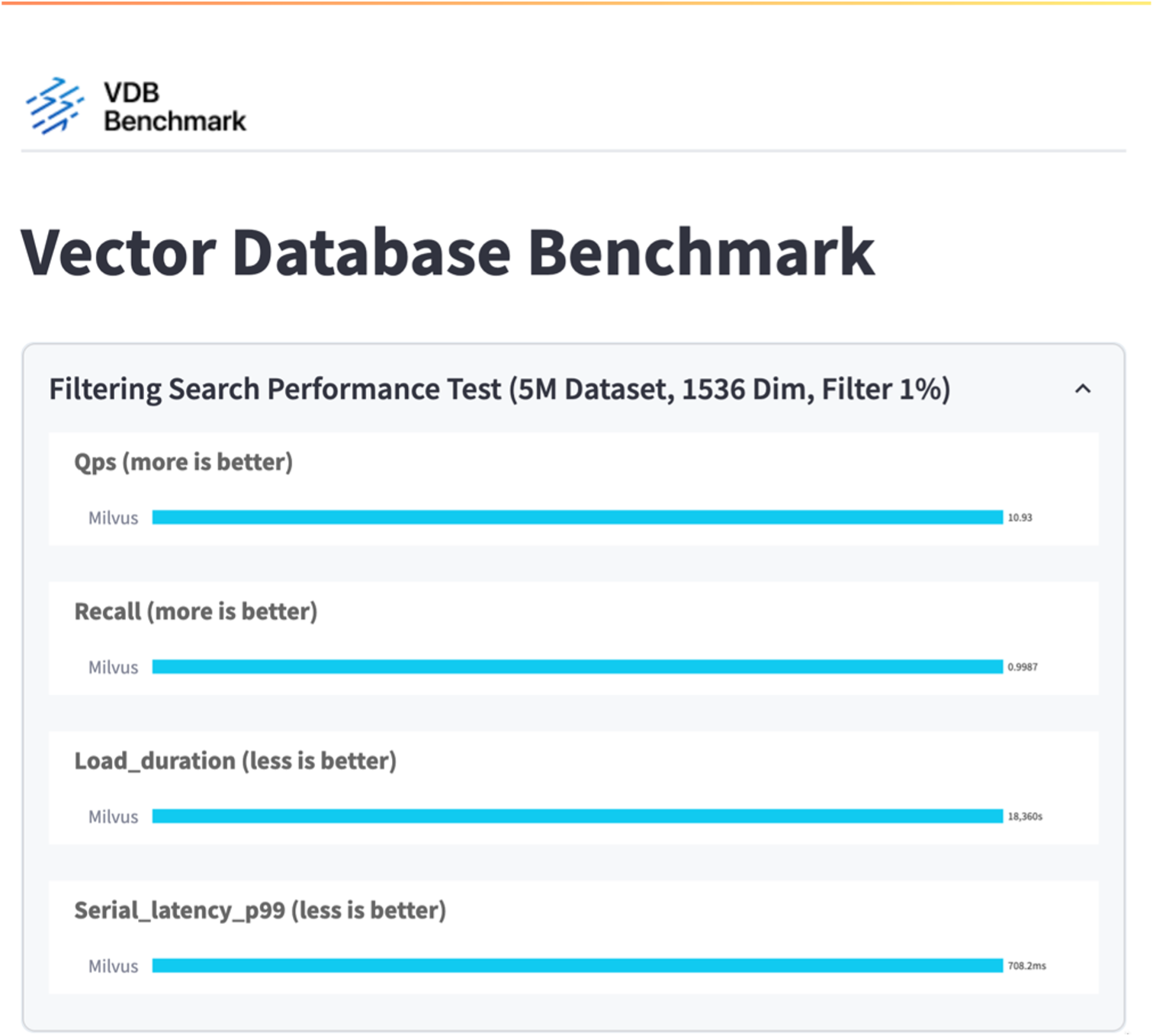
독립형 Milvus 인스턴스의 성능 검증을 통해, 현재 설정은 1536차원의 500만 개 벡터 데이터 세트를 지원하기에 부족하다는 것이 분명해졌습니다. 저장소에 충분한 리소스가 있으며 시스템에 병목 현상을 일으키지 않는다는 것을 확인했습니다.
Milvus 클러스터가 포함된 VectorDB-Bench
이 섹션에서는 Kubernetes 환경 내에서 Milvus 클러스터를 배포하는 방법에 대해 설명합니다. 이 Kubernetes 설정은 Kubernetes 마스터 및 워커 노드를 호스팅하는 VMware vSphere 배포를 기반으로 구성되었습니다.
다음 섹션에서는 VMware vSphere 및 Kubernetes 배포에 대한 세부 정보를 제공합니다.
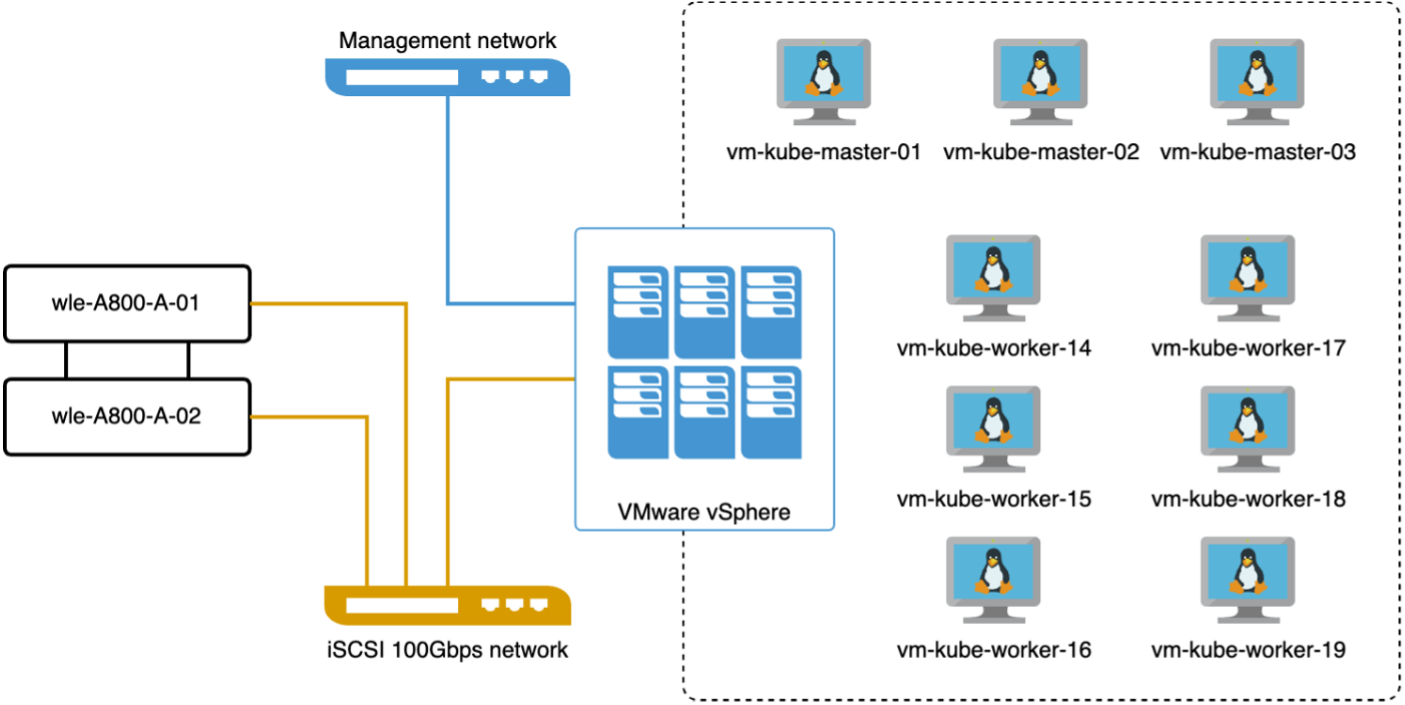
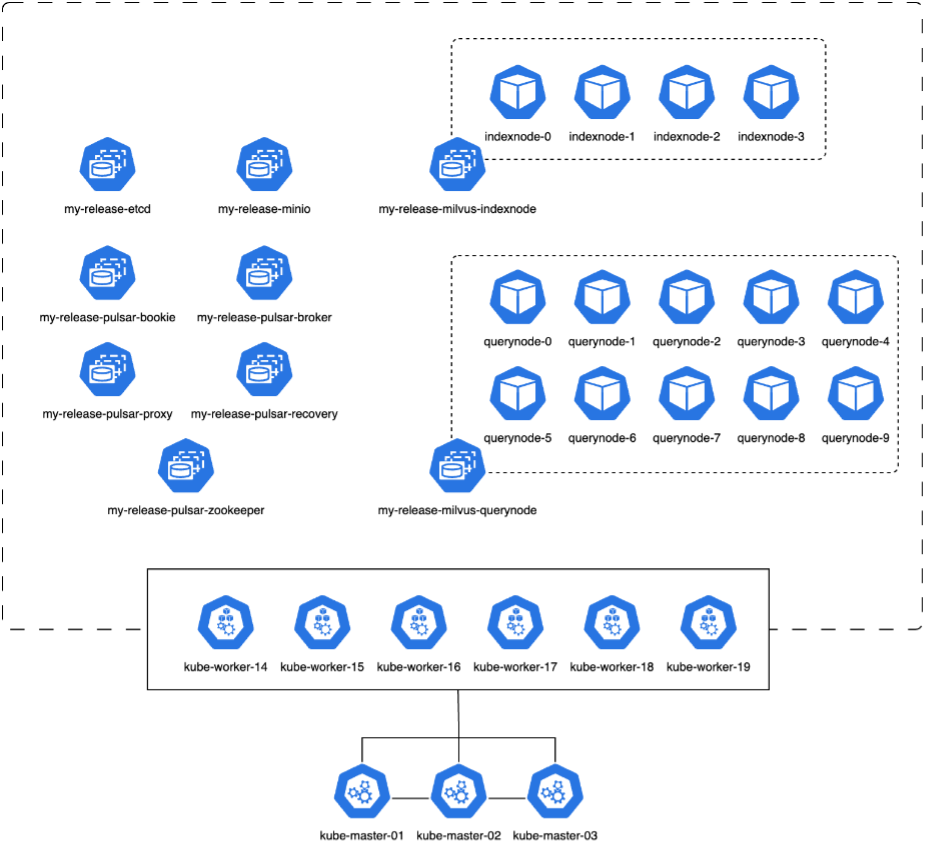
이 섹션에서는 Milvus 데이터베이스 테스트에서 얻은 관찰 결과와 결과를 제시합니다. * 사용된 인덱스 유형은 DiskANN입니다. * 아래 표는 1536차원에서 500만 개의 벡터로 작업할 때 독립 실행형 배포와 클러스터 배포를 비교한 것입니다. 클러스터 배포에서는 데이터 수집과 삽입 후 최적화에 걸리는 시간이 더 짧은 것을 확인했습니다. 클러스터 배포에서는 독립 실행형 설정에 비해 쿼리의 99번째 백분위수 지연 시간이 6배나 단축되었습니다. * 클러스터 배포 시 초당 쿼리 수(QPS)는 더 높았지만 원하는 수준은 아니었습니다.

아래 이미지는 스토리지 클러스터 지연 시간과 총 IOPS(초당 입출력 작업)를 포함한 다양한 스토리지 측정 항목을 보여줍니다.
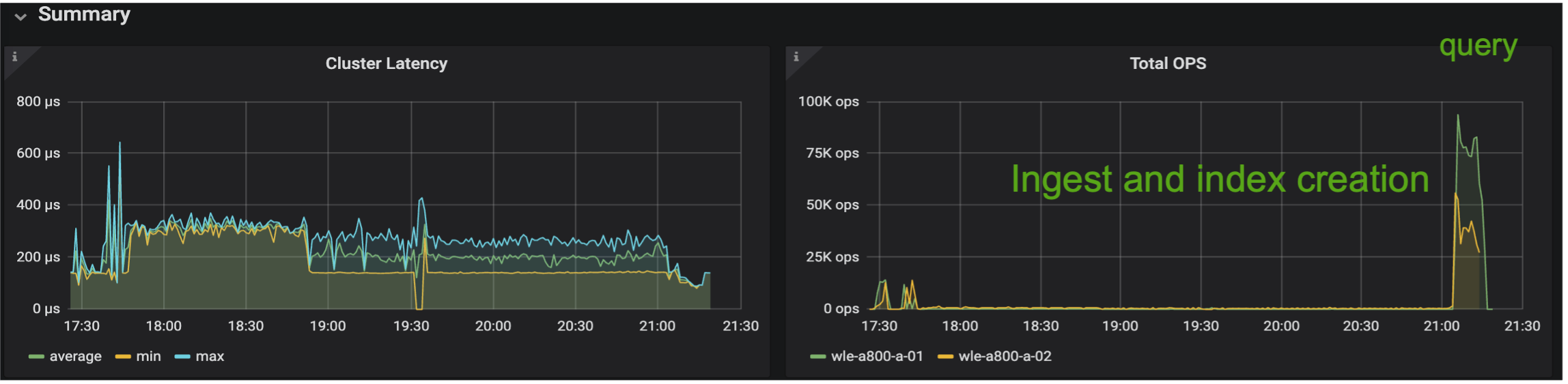
다음 섹션에서는 주요 스토리지 성능 지표를 소개합니다.
| 작업 부하 단계 | 미터법 | 가치 |
|---|---|---|
데이터 수집 및 삽입 후 최적화 |
아이옵스 |
< 1,000 |
숨어 있음 |
< 400유초 |
|
작업량 |
읽기/쓰기 혼합, 주로 쓰기 |
|
IO 크기 |
64KB |
|
질문 |
아이옵스 |
최고치 147,000 |
숨어 있음 |
< 400유초 |
|
작업량 |
100% 캐시된 읽기 |
|
IO 크기 |
대부분 8KB |
독립형 Milvus와 Milvus 클러스터의 성능 검증을 바탕으로 스토리지 I/O 프로필에 대한 세부 정보를 제시합니다. * 독립 실행형과 클러스터 배포 모두에서 I/O 프로필이 일관되게 유지되는 것을 확인했습니다. * 관찰된 최대 IOPS의 차이는 클러스터 배포에 포함된 클라이언트 수가 더 많은 데 기인할 수 있습니다.
Postgres를 사용한 vectorDB-Bench(pgvecto.rs)
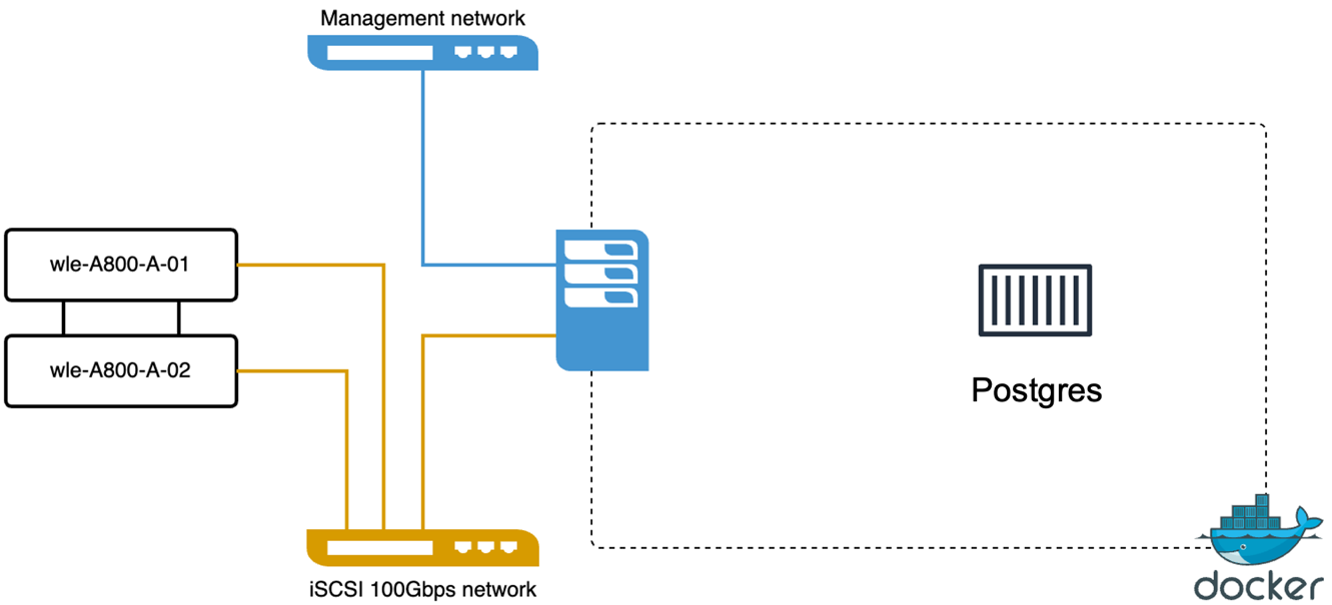
VectorDB-Bench를 사용하여 PostgreSQL(pgvecto.rs)에서 다음 작업을 수행했습니다. PostgreSQL(특히 pgvecto.rs)의 네트워크 및 서버 연결에 대한 세부 정보는 다음과 같습니다.
이 섹션에서는 pgvecto.rs를 사용하여 PostgreSQL 데이터베이스를 테스트한 결과와 관찰 내용을 공유합니다. * 테스트 당시 pgvecto.rs에서 DiskANN을 사용할 수 없었기 때문에 이러한 테스트의 인덱스 유형으로 HNSW를 선택했습니다. * 데이터 수집 단계에서는 768차원의 1,000만 개의 벡터로 구성된 Cohere 데이터 세트를 로드했습니다. 이 과정은 약 4.5시간이 걸렸습니다. * 쿼리 단계에서 우리는 0.6344의 회수율로 초당 쿼리 수(QPS) 1,068을 관찰했습니다. 쿼리에 대한 99번째 백분위수 지연 시간은 20밀리초로 측정되었습니다. 대부분의 런타임 동안 클라이언트 CPU는 100% 용량으로 작동했습니다.
아래 이미지는 스토리지 클러스터 지연 총 IOPS(초당 입출력 작업)를 포함한 다양한 스토리지 측정 항목을 보여줍니다.

The following section presents the key storage performance metrics. image:pgvecto-storage-perf-metrics.png["입력/출력 대화 상자 또는 서면 내용을 나타내는 그림"]
벡터 DB 벤치에서 milvus와 postgres의 성능 비교
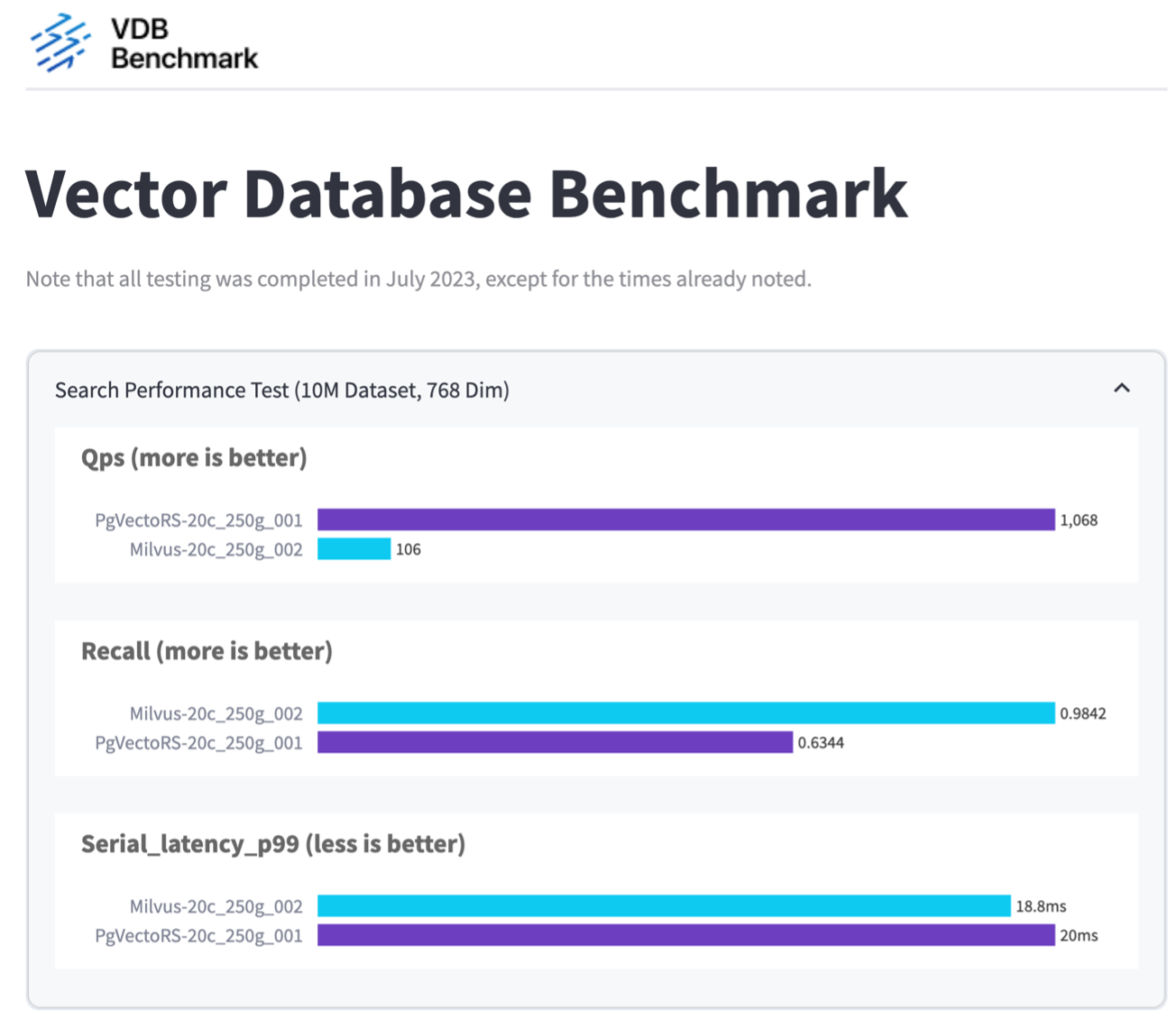
VectorDBBench를 사용하여 Milvus와 PostgreSQL의 성능을 검증한 결과, 다음과 같은 결과가 관찰되었습니다.
-
인덱스 유형: HNSW
-
데이터 세트: 768차원의 1,000만 개 벡터로 구성된 Cohere
pgvecto.rs는 0.6344의 재현율로 초당 쿼리 수(QPS) 1,068을 달성한 반면, Milvus는 0.9842의 재현율로 초당 쿼리 수 106을 달성한 것으로 나타났습니다.
질의의 정확도를 높이는 것이 우선순위라면 Milvus는 pgvecto.rs보다 우수한 성능을 보이는데, 이는 질의당 관련 항목의 비율이 더 높기 때문입니다. 하지만 초당 쿼리 수가 더 중요한 요소라면 pgvecto.rs가 Milvus를 능가합니다. 하지만 pgvecto.rs를 통해 검색된 데이터의 품질이 낮다는 점을 알아두는 것이 중요합니다. 검색 결과의 약 37%가 관련성이 없는 항목입니다.
성과 검증을 기반으로 한 관찰 결과:
성과 검증을 바탕으로 다음과 같은 관찰 결과를 얻었습니다.
Milvus에서 I/O 프로필은 Oracle SLOB에서 볼 수 있는 것과 같은 OLTP 작업 부하와 매우 유사합니다. 벤치마크는 데이터 수집, 사후 최적화, 쿼리의 세 단계로 구성됩니다. 초기 단계는 주로 64KB 쓰기 작업을 특징으로 하는 반면, 쿼리 단계는 주로 8KB 읽기 작업을 포함합니다. ONTAP 이 Milvus I/O 부하를 효율적으로 처리할 것으로 기대합니다.
PostgreSQL I/O 프로필은 까다로운 스토리지 작업 부하를 나타내지 않습니다. 현재 진행 중인 메모리 내 구현을 고려하면 쿼리 단계에서 디스크 I/O가 관찰되지 않았습니다.
DiskANN은 스토리지 차별화를 위한 핵심 기술로 부상하고 있습니다. 시스템 메모리 경계를 넘어 벡터 DB 검색을 효율적으로 확장할 수 있습니다. 그러나 HNSW와 같은 메모리 내 벡터 DB 인덱스를 사용하여 스토리지 성능 차별화를 확립하기는 어려울 것입니다.
또한 인덱스 유형이 HSNW인 경우 쿼리 단계에서 저장소가 중요한 역할을 하지 않는다는 점도 주목할 만합니다. HSNW는 RAG 애플리케이션을 지원하는 벡터 데이터베이스의 가장 중요한 운영 단계입니다. 여기서 의미하는 바는 저장 성능이 이러한 애플리케이션의 전반적인 성능에 큰 영향을 미치지 않는다는 것입니다.