

EC2 및 FSx Oracle 데이터베이스 관리
 변경 제안
변경 제안
Oracle 환경에서는 AWS EC2 및 FSx 관리 콘솔 외에도 Ansible 제어 노드와 SnapCenter UI 도구가 데이터베이스 관리를 위해 배포됩니다.
Ansible 제어 노드는 Oracle 환경 구성을 관리하는 데 사용할 수 있으며, 커널 또는 패치 업데이트를 위해 기본 인스턴스와 대기 인스턴스를 동기화된 상태로 유지하는 병렬 업데이트를 제공합니다. NetApp Automation Toolkit을 사용하면 장애 조치, 재동기화, 장애 복구를 자동화하여 Ansible을 통해 빠른 애플리케이션 복구와 가용성을 보관할 수 있습니다. 일부 반복 가능한 데이터베이스 관리 작업은 플레이북을 사용하여 실행하여 인적 오류를 줄일 수 있습니다.
SnapCenter UI 도구는 Oracle 데이터베이스용 SnapCenter 플러그인을 사용하여 데이터베이스 스냅샷 백업, 특정 시점 복구, 데이터베이스 복제 등을 수행할 수 있습니다. Oracle 플러그인 기능에 대한 자세한 내용은 다음을 참조하세요."Oracle Database용 SnapCenter 플러그인 개요" .
다음 섹션에서는 SnapCenter UI를 사용하여 Oracle 데이터베이스 관리의 주요 기능을 수행하는 방법에 대한 자세한 내용을 제공합니다.
-
데이터베이스 스냅샷 백업
-
데이터베이스 시점 복원
-
데이터베이스 복제본 생성
데이터베이스 복제는 논리적 데이터 오류나 손상이 발생할 경우 데이터를 복구하기 위해 별도의 EC2 호스트에 기본 데이터베이스의 복제본을 생성하며, 복제본은 애플리케이션 테스트, 디버깅, 패치 검증 등에도 사용할 수 있습니다.
스냅샷 찍기
EC2/FSx Oracle 데이터베이스는 사용자가 구성한 간격으로 정기적으로 백업됩니다. 사용자는 언제든지 일회성 스냅샷 백업을 수행할 수도 있습니다. 이는 전체 데이터베이스 스냅샷 백업과 아카이브 로그 전용 스냅샷 백업 모두에 적용됩니다.
전체 데이터베이스 스냅샷 찍기
전체 데이터베이스 스냅샷에는 데이터 파일, 제어 파일, 보관 로그 파일을 포함한 모든 Oracle 파일이 포함됩니다.
-
SnapCenter UI에 로그인하고 왼쪽 메뉴에서 리소스를 클릭합니다. 보기 드롭다운에서 리소스 그룹 보기로 변경합니다.
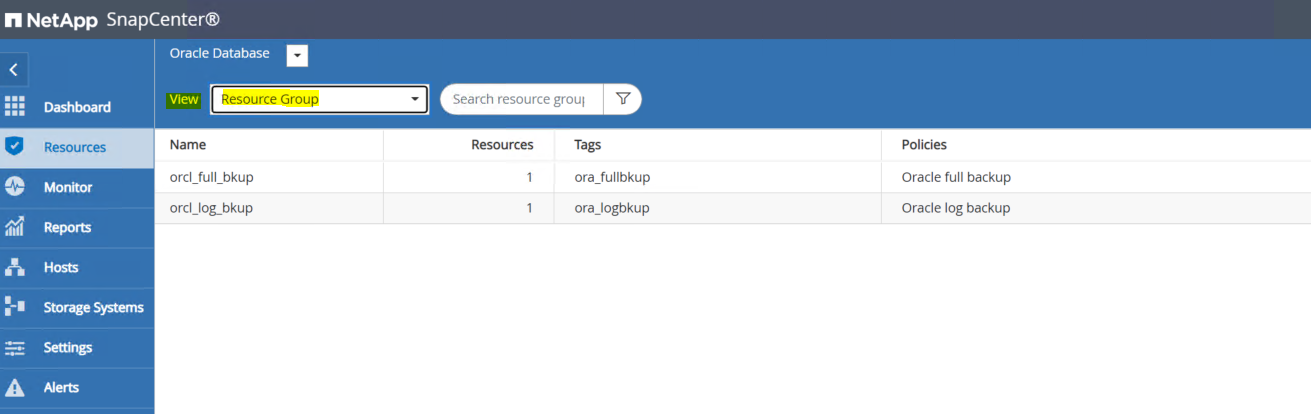
-
전체 백업 리소스 이름을 클릭한 다음 지금 백업 아이콘을 클릭하여 추가 백업을 시작합니다.
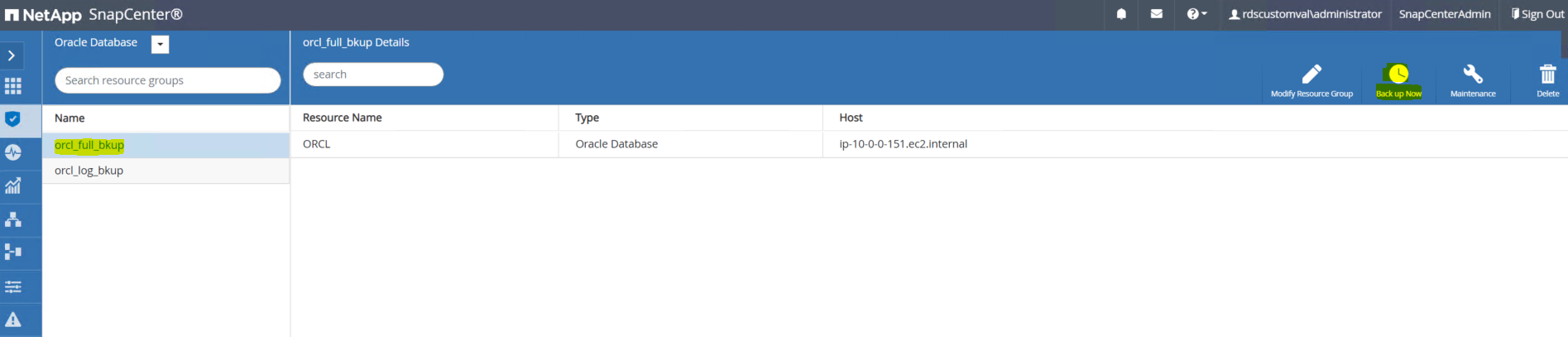
-
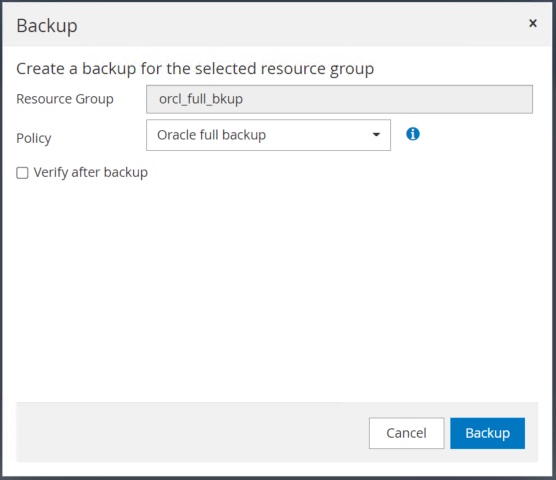
백업을 클릭한 다음 백업을 확인하여 전체 데이터베이스 백업을 시작합니다.
데이터베이스의 리소스 뷰에서 데이터베이스 관리 백업 복사본 페이지를 열어 일회성 백업이 성공적으로 완료되었는지 확인합니다. 전체 데이터베이스 백업은 두 개의 스냅샷을 생성합니다. 하나는 데이터 볼륨에 대한 것이고 다른 하나는 로그 볼륨에 대한 것입니다.
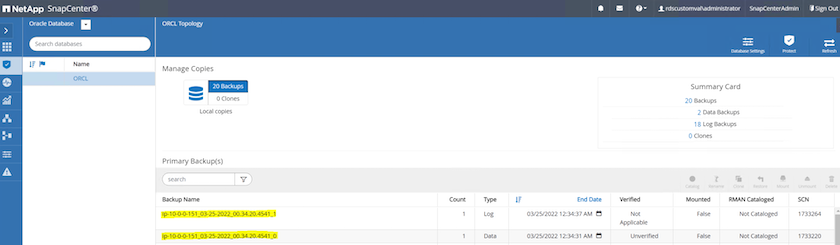
아카이브 로그 스냅샷 찍기
아카이브 로그 스냅샷은 Oracle 아카이브 로그 볼륨에 대해서만 생성됩니다.
-
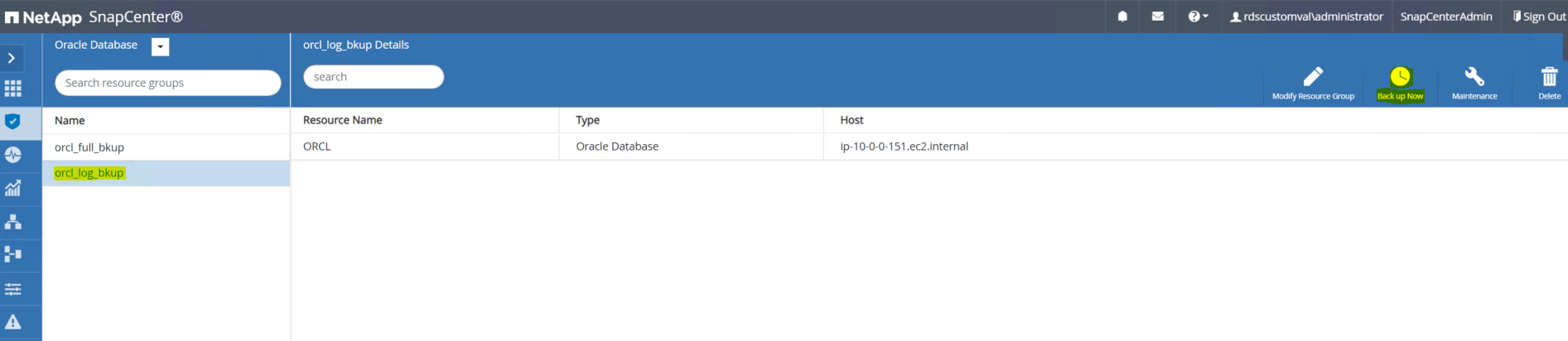
SnapCenter UI에 로그인하고 왼쪽 메뉴 막대에서 리소스 탭을 클릭합니다. 보기 드롭다운에서 리소스 그룹 보기로 변경합니다.
-
로그 백업 리소스 이름을 클릭한 다음 지금 백업 아이콘을 클릭하여 보관 로그에 대한 추가 백업을 시작합니다.
-
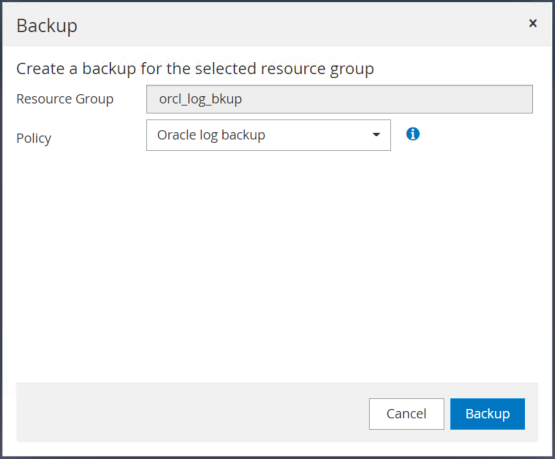
백업을 클릭한 다음 백업을 확인하여 보관 로그 백업을 시작합니다.
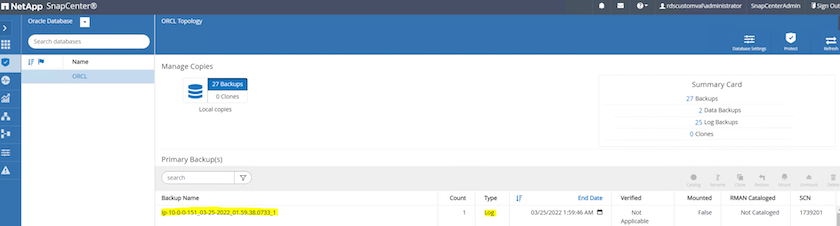
데이터베이스의 리소스 뷰에서 데이터베이스 관리 백업 복사본 페이지를 열어 일회성 보관 로그 백업이 성공적으로 완료되었는지 확인합니다. 보관 로그 백업은 로그 볼륨에 대한 스냅샷 하나를 생성합니다.
특정 시점으로 복원
SnapCenter 기반 복원은 동일한 EC2 인스턴스 호스트에서 실행됩니다. 복원을 수행하려면 다음 단계를 완료하세요.
-
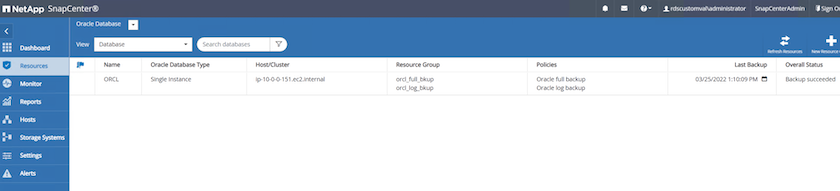
SnapCenter 리소스 탭 > 데이터베이스 보기에서 데이터베이스 이름을 클릭하여 데이터베이스 백업을 엽니다.
-
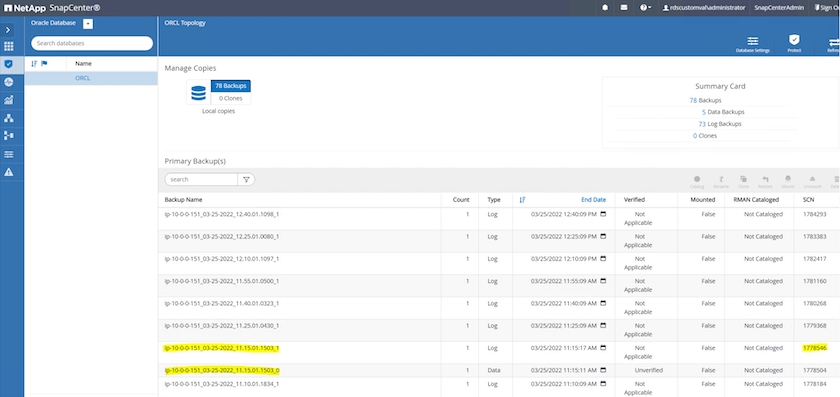
데이터베이스 백업 사본과 복원할 원하는 시점을 선택하세요. 또한 해당 시점에 해당하는 SCN 번호를 기록해 두세요. 특정 시점 복원은 시간이나 SCN을 사용하여 수행할 수 있습니다.
-
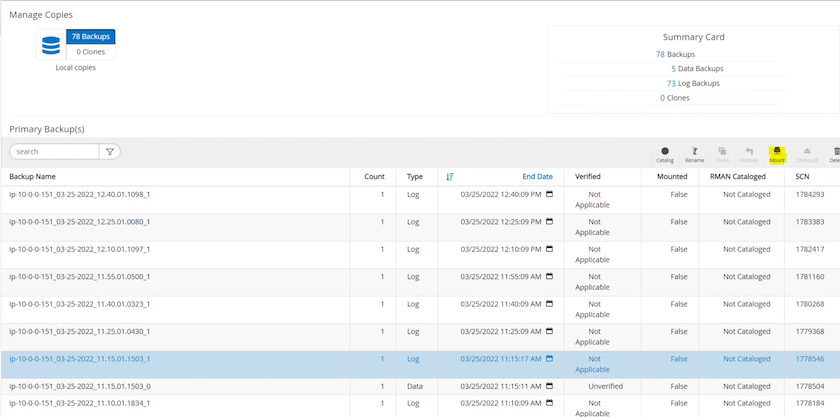
로그 볼륨 스냅샷을 강조 표시하고 마운트 버튼을 클릭하여 볼륨을 마운트합니다.
-
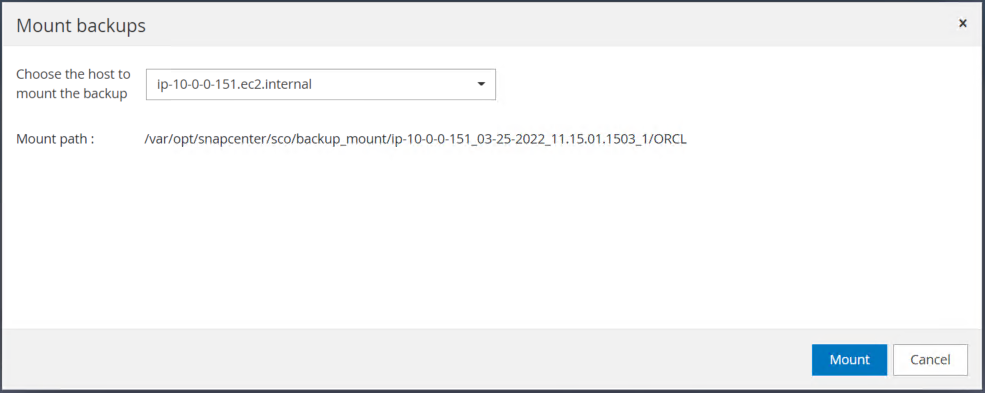
로그 볼륨을 마운트할 기본 EC2 인스턴스를 선택합니다.
-
마운트 작업이 성공적으로 완료되는지 확인하세요. EC2 인스턴스 호스트에서도 해당 로그 볼륨이 마운트되었는지, 마운트 지점 경로도 확인하세요.


-
마운트된 로그 볼륨에서 현재 보관 로그 디렉터리로 보관 로그를 복사합니다.
[ec2-user@ip-10-0-0-151 ~]$ cp /var/opt/snapcenter/sco/backup_mount/ip-10-0-0-151_03-25-2022_11.15.01.1503_1/ORCL/1/db/ORCL_A/arch/*.arc /ora_nfs_log/db/ORCL_A/arch/
-
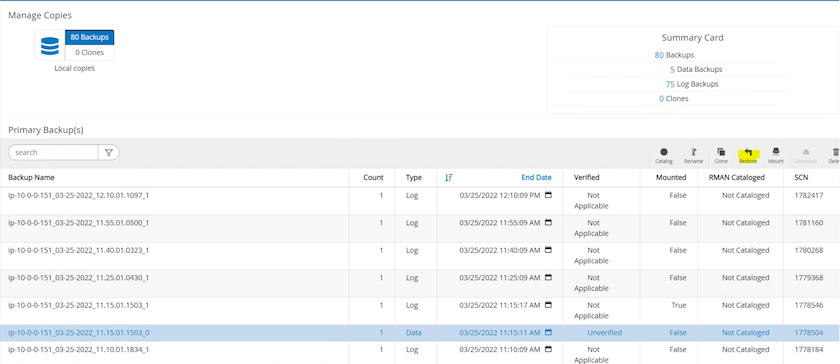
SnapCenter 리소스 탭 > 데이터베이스 백업 페이지로 돌아가서 데이터 스냅샷 복사본을 강조 표시하고 복원 버튼을 클릭하여 데이터베이스 복원 워크플로를 시작합니다.
-
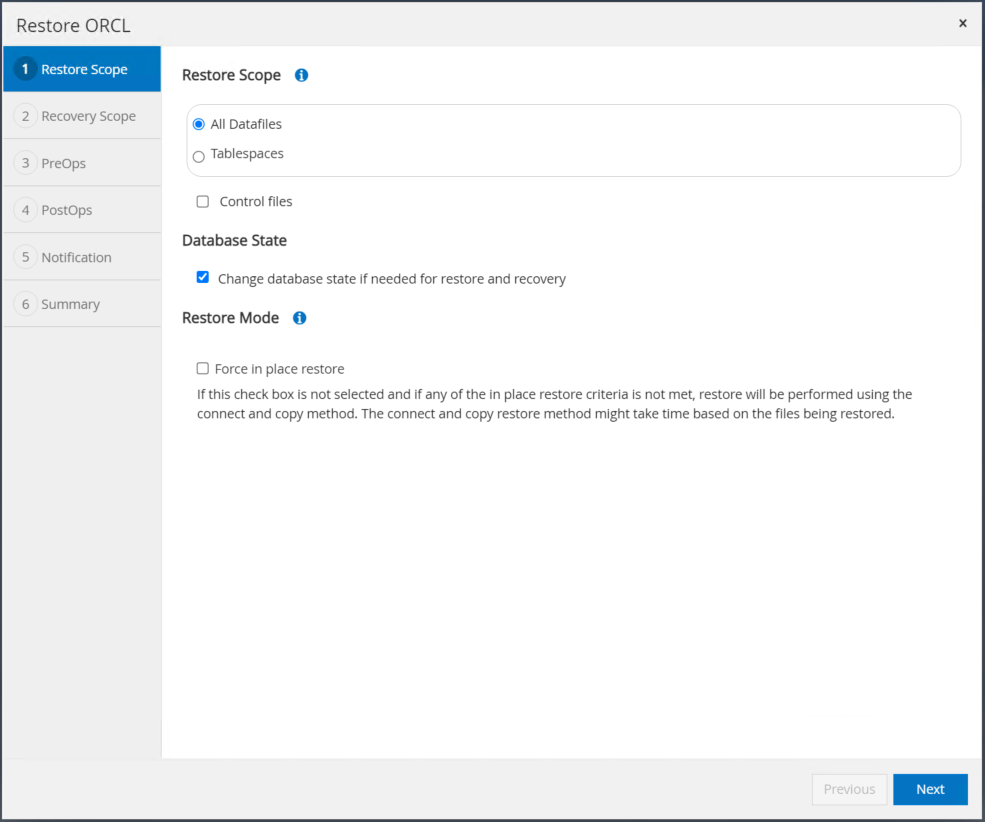
"모든 데이터 파일"과 "복원 및 복구에 필요한 경우 데이터베이스 상태 변경"을 선택하고 다음을 클릭합니다.
-
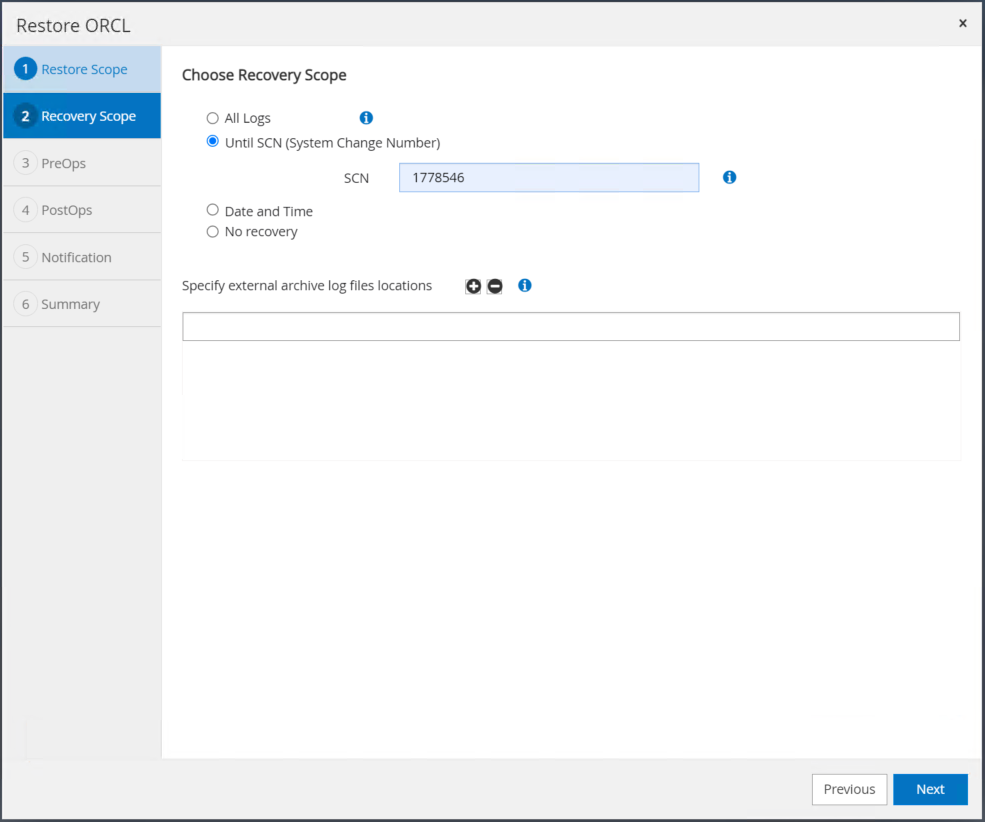
SCN이나 시간을 사용하여 원하는 복구 범위를 선택합니다. 6단계에서 설명한 대로 마운트된 보관 로그를 현재 로그 디렉터리에 복사하는 대신, 복구를 위해 마운트된 보관 로그 경로를 "외부 보관 로그 파일 위치 지정"에 나열할 수 있습니다.
-
필요한 경우 실행할 선택적 처방을 지정하세요.
-
필요한 경우 실행할 선택적 afterscript를 지정합니다. 복구 후 열려 있는 데이터베이스를 확인하세요.
-
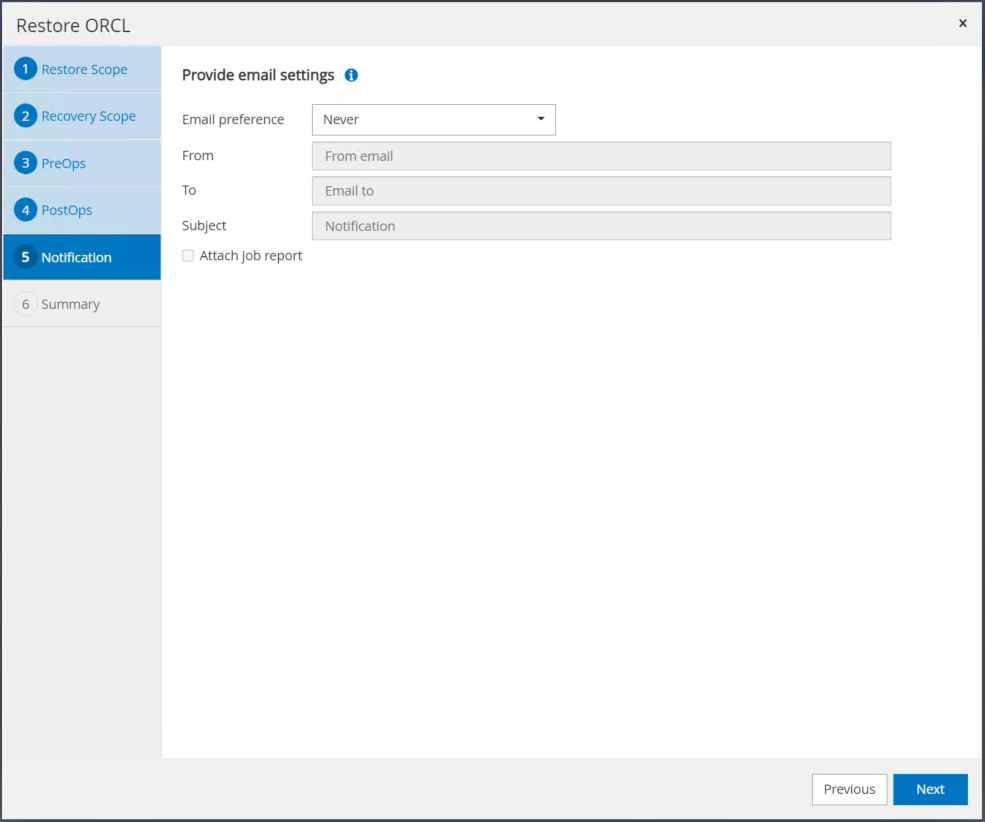
작업 알림이 필요한 경우 SMTP 서버와 이메일 주소를 제공하세요.
-
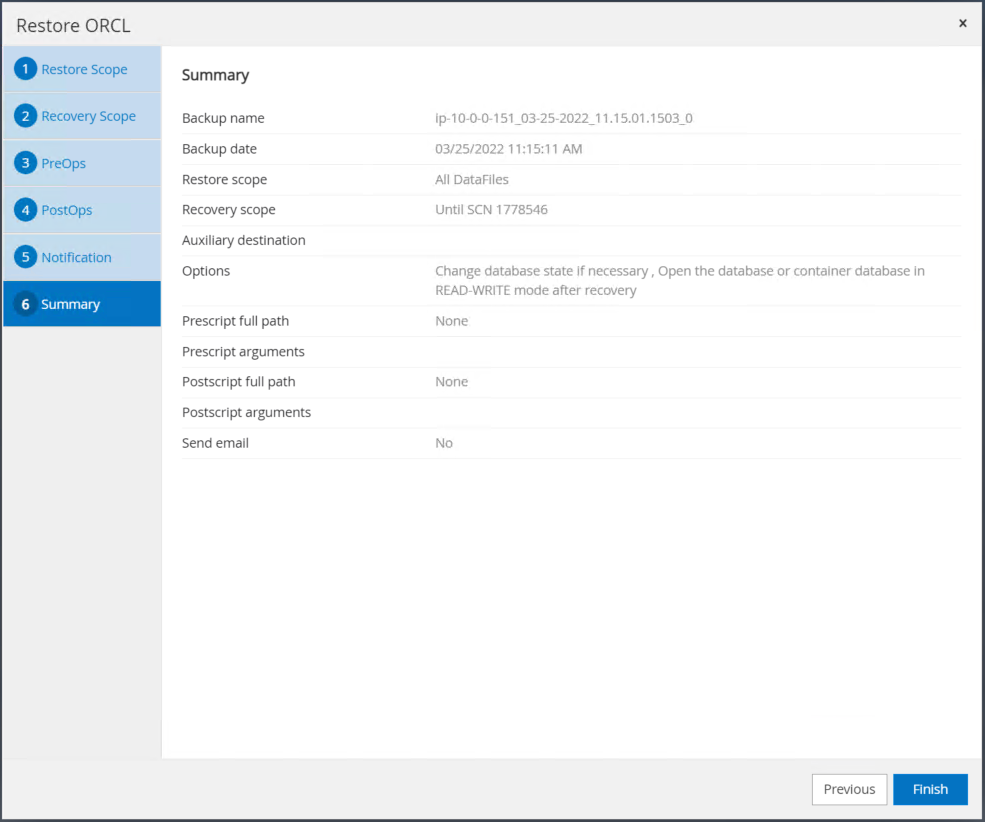
작업 요약을 복원합니다. 마침을 클릭하면 복원 작업이 시작됩니다.
-
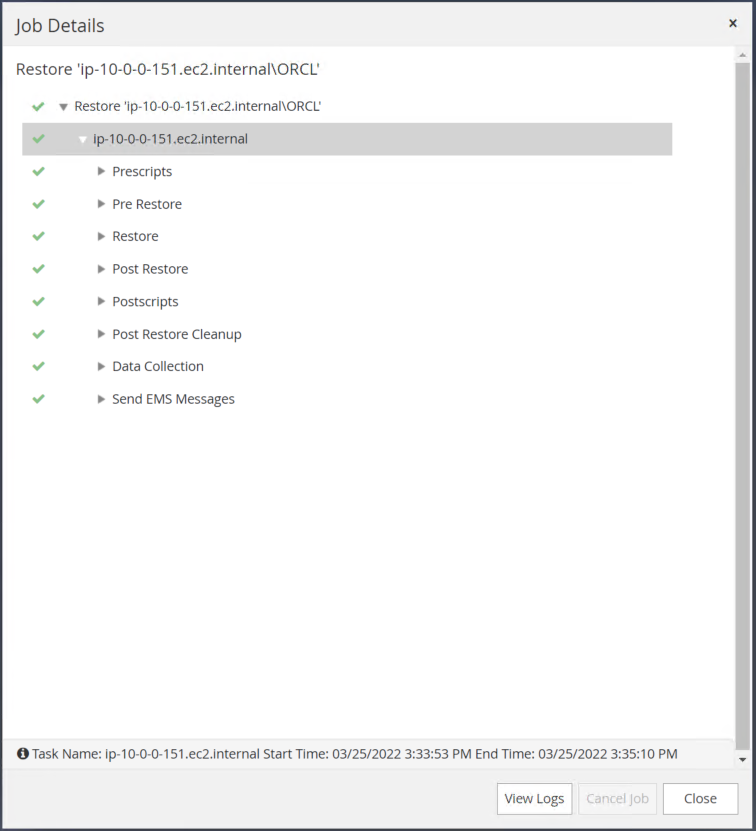
SnapCenter 에서 복원을 검증합니다.
-
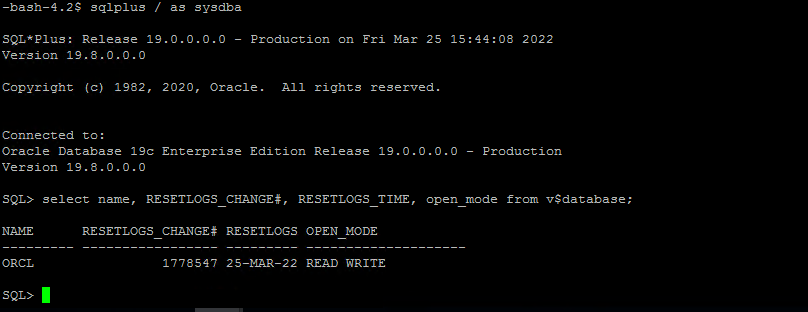
EC2 인스턴스 호스트에서 복원을 검증합니다.
-
복구 로그 볼륨을 마운트 해제하려면 4단계의 단계를 반대로 수행합니다.
데이터베이스 복제본 생성
다음 섹션에서는 SnapCenter 복제 워크플로를 사용하여 기본 데이터베이스에서 대기 EC2 인스턴스로 데이터베이스 복제본을 만드는 방법을 보여줍니다.
-
SnapCenter 에서 전체 백업 리소스 그룹을 사용하여 기본 데이터베이스의 전체 스냅샷 백업을 수행합니다.
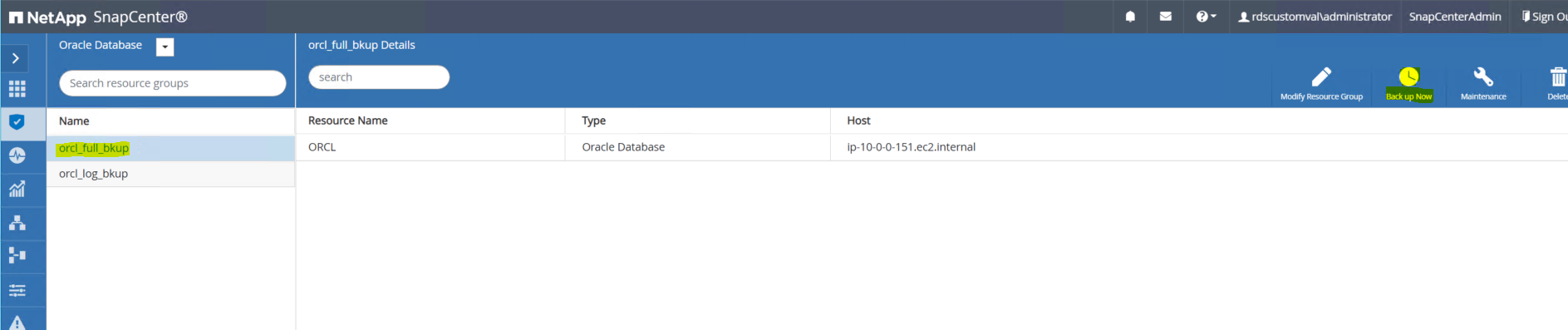
-
SnapCenter 리소스 탭 > 데이터베이스 보기에서 복제본을 생성할 기본 데이터베이스에 대한 데이터베이스 백업 관리 페이지를 엽니다.
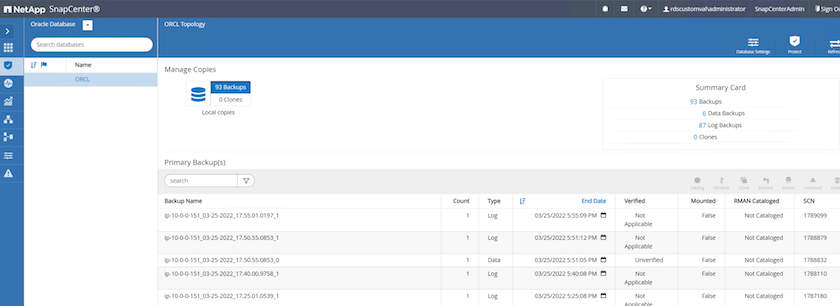
-
4단계에서 만든 로그 볼륨 스냅샷을 대기 EC2 인스턴스 호스트에 마운트합니다.
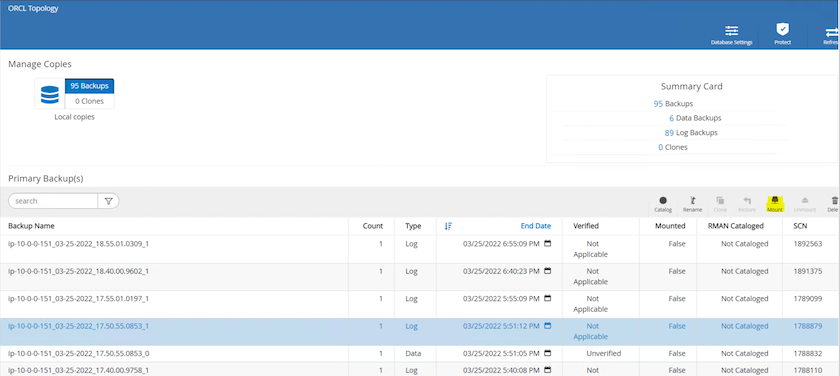
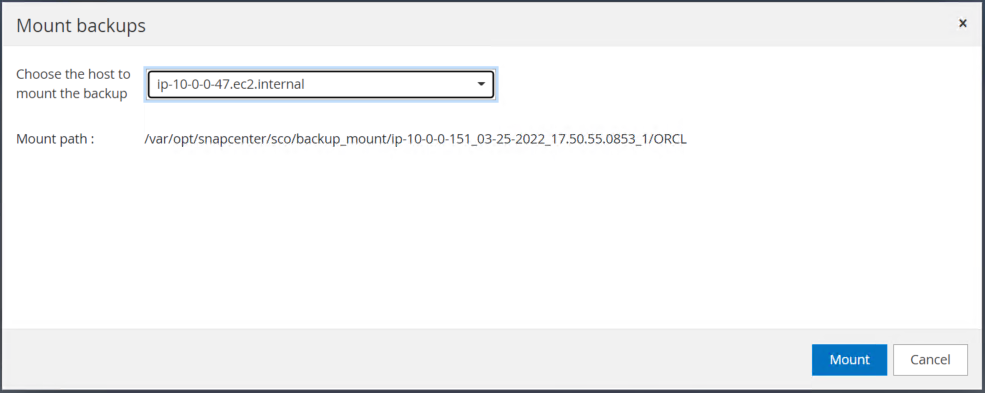
-
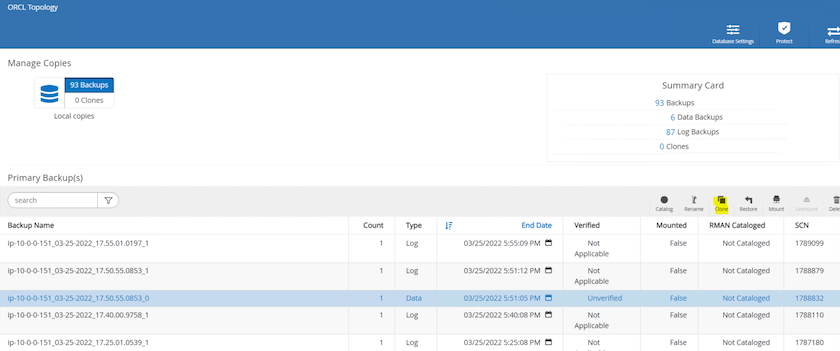
복제본에 복제할 스냅샷 복사본을 강조 표시하고 복제 버튼을 클릭하여 복제 절차를 시작합니다.
-
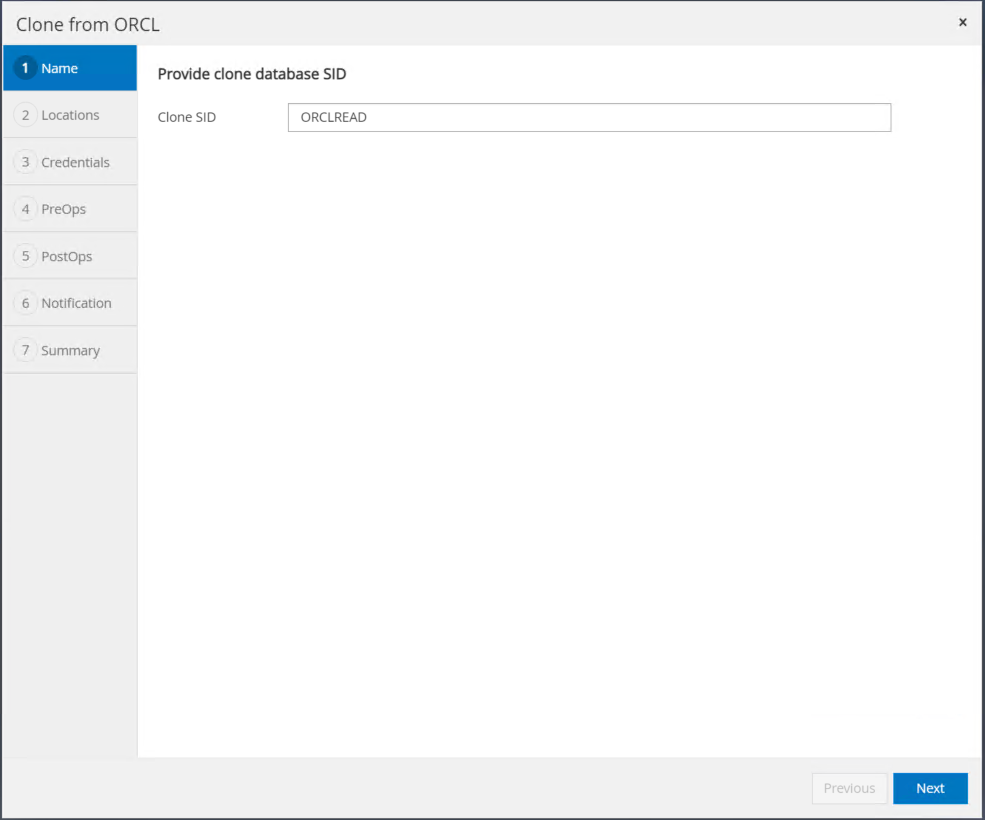
복제본 복사본 이름을 기본 데이터베이스 이름과 다르게 변경합니다. 다음을 클릭하세요.
-
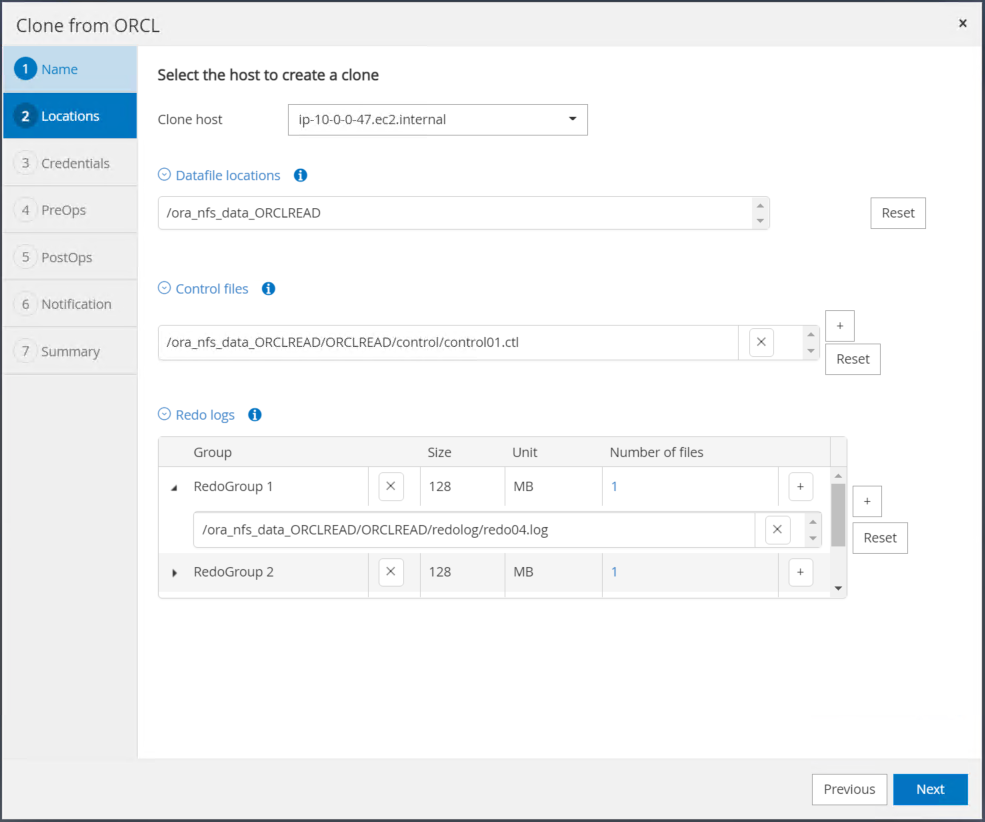
복제 호스트를 대기 EC2 호스트로 변경하고 기본 이름을 그대로 적용한 후 다음을 클릭합니다.
-
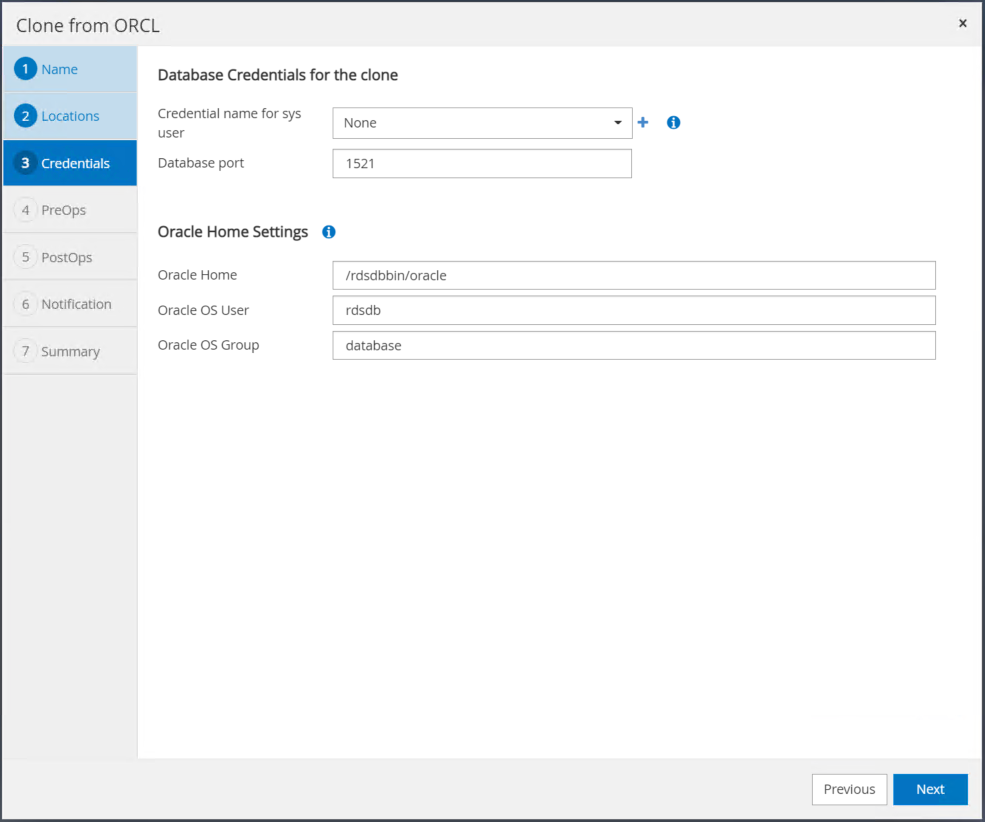
대상 Oracle 서버 호스트에 구성된 설정과 일치하도록 Oracle 홈 설정을 변경하고 다음을 클릭합니다.
-
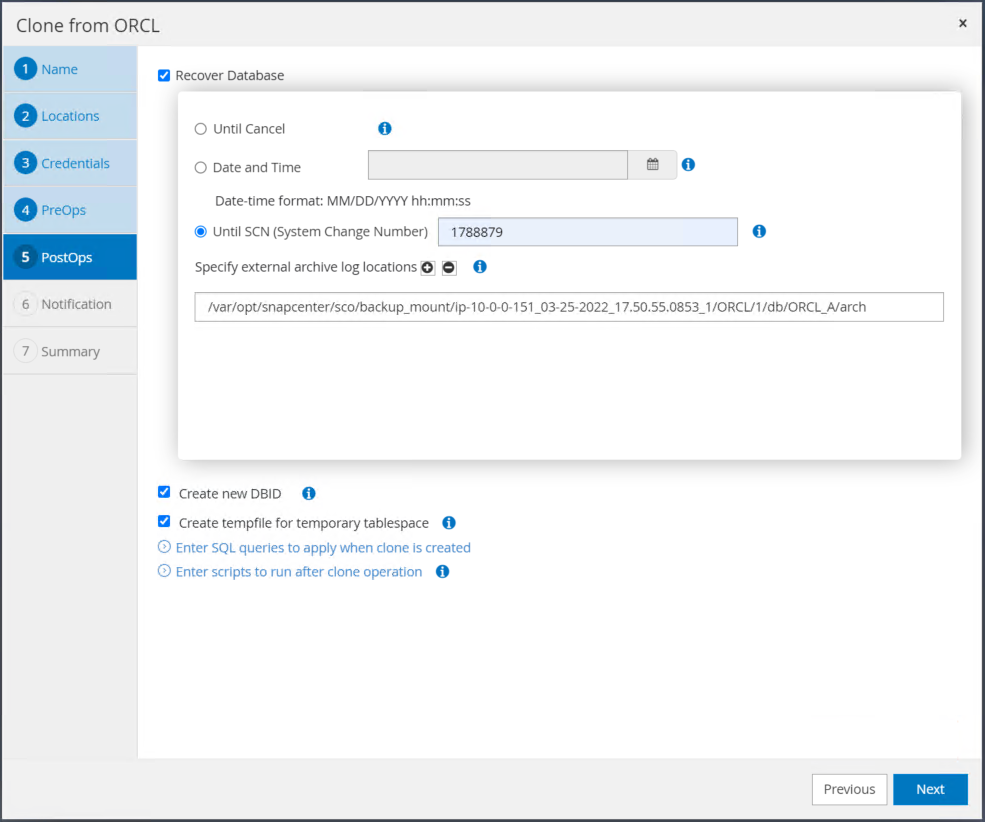
시간이나 SCN 및 마운트된 아카이브 로그 경로를 사용하여 복구 지점을 지정합니다.
-
필요한 경우 SMTP 이메일 설정을 보내세요.
-
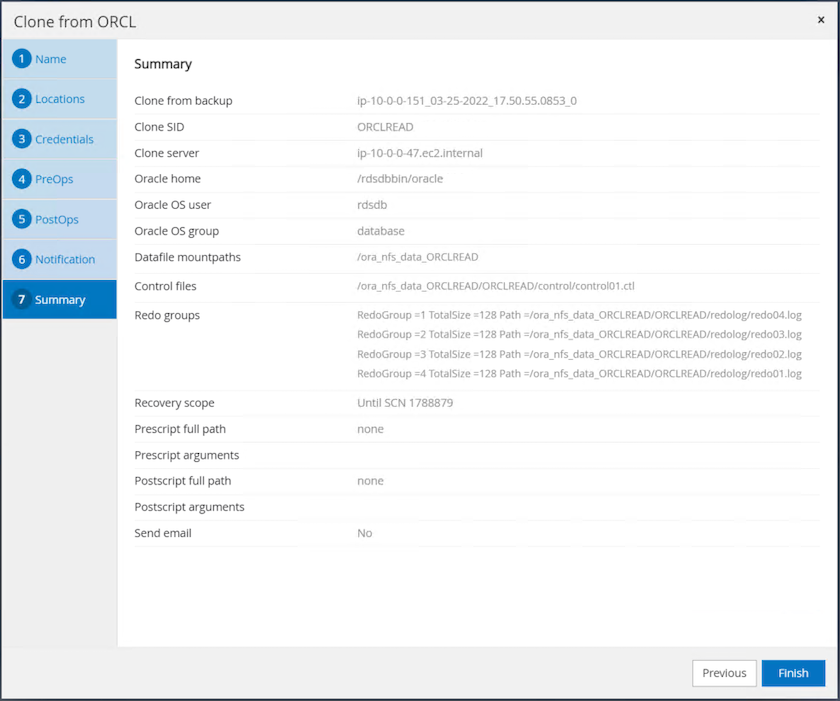
작업 요약을 복제하고 마침을 클릭하여 복제 작업을 시작합니다.
-
복제 작업 로그를 검토하여 복제본 복제본의 유효성을 검사합니다.
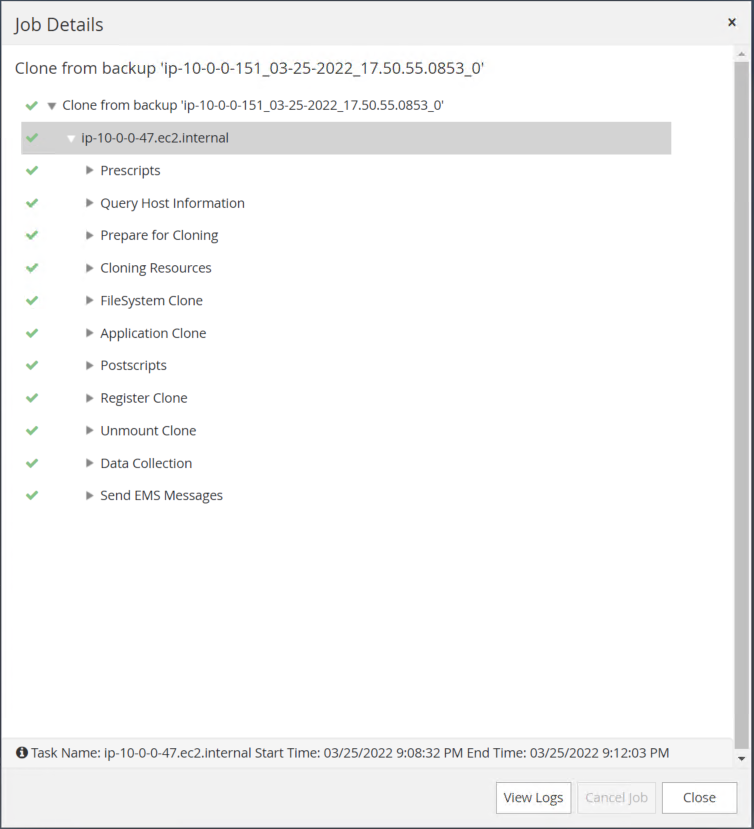
복제된 데이터베이스는 SnapCenter 에 즉시 등록됩니다.
-
Oracle 아카이브 로그 모드를 끕니다. EC2 인스턴스에 Oracle 사용자로 로그인하고 다음 명령을 실행합니다.
sqlplus / as sysdbashutdown immediate;startup mount;alter database noarchivelog;alter database open;

|
기본 Oracle 백업 사본 대신, 동일한 절차를 통해 대상 FSx 클러스터의 복제된 보조 백업 사본에서 복제본을 만들 수도 있습니다. |
HA 페일오버를 대기 모드로 전환하고 다시 동기화합니다.
대기 Oracle HA 클러스터는 컴퓨팅 계층이나 스토리지 계층에서 기본 사이트에 장애가 발생하는 경우 높은 가용성을 제공합니다. 이 솔루션의 가장 큰 이점은 사용자가 언제든지, 원하는 빈도로 인프라를 테스트하고 검증할 수 있다는 것입니다. 장애 조치는 사용자가 시뮬레이션하거나 실제 장애로 인해 트리거될 수 있습니다. 장애 조치 프로세스는 동일하며 빠른 애플리케이션 복구를 위해 자동화할 수 있습니다.
다음 장애 조치 절차 목록을 참조하세요.
-
시뮬레이션된 장애 조치의 경우 섹션에서 설명한 대로 최신 트랜잭션을 대기 사이트로 플러시하기 위해 로그 스냅샷 백업을 실행합니다.아카이브 로그 스냅샷 찍기 . 실제 장애로 인해 발생한 장애 조치의 경우, 마지막으로 복구 가능한 데이터는 마지막으로 성공적으로 예약된 로그 볼륨 백업과 함께 대기 사이트에 복제됩니다.
-
기본 FSx 클러스터와 대기 FSx 클러스터 간의 SnapMirror 끊습니다.
-
복제된 대기 데이터베이스 볼륨을 대기 EC2 인스턴스 호스트에 마운트합니다.
-
복제된 Oracle 바이너리가 Oracle 복구에 사용되는 경우 Oracle 바이너리를 다시 연결합니다.
-
대기 Oracle 데이터베이스를 마지막으로 사용 가능한 보관 로그로 복구합니다.
-
애플리케이션과 사용자 액세스를 위해 대기 Oracle 데이터베이스를 엽니다.
-
실제 기본 사이트 장애가 발생하는 경우, 대기 Oracle 데이터베이스가 이제 새로운 기본 사이트의 역할을 맡고 데이터베이스 볼륨을 사용하여 역방향 SnapMirror 방법을 통해 장애가 발생한 기본 사이트를 새로운 대기 사이트로 재구축할 수 있습니다.
-
테스트나 검증을 위해 시뮬레이션된 기본 사이트 장애의 경우, 테스트가 완료된 후 대기 Oracle 데이터베이스를 종료합니다. 그런 다음 대기 EC2 인스턴스 호스트에서 대기 데이터베이스 볼륨을 마운트 해제하고 기본 사이트에서 대기 사이트로 복제를 다시 동기화합니다.
이러한 절차는 공개 NetApp GitHub 사이트에서 다운로드할 수 있는 NetApp Automation Toolkit을 사용하여 수행할 수 있습니다.
git clone https://github.com/NetApp-Automation/na_ora_hadr_failover_resync.git설정 및 장애 조치 테스트를 시도하기 전에 README 지침을 주의 깊게 읽으세요.