AWS EC2 및 FSx에서의 단계별 Oracle 배포 절차
 변경 제안
변경 제안
이 섹션에서는 FSx 스토리지를 사용하여 Oracle RDS 사용자 정의 데이터베이스를 배포하는 절차를 설명합니다.
EC2 콘솔을 통해 Oracle용 EC2 Linux 인스턴스 배포
AWS를 처음 사용하는 경우 먼저 AWS 환경을 설정해야 합니다. AWS 웹사이트 랜딩 페이지의 설명서 탭에는 AWS EC2 콘솔을 통해 Oracle 데이터베이스를 호스팅하는 데 사용할 수 있는 Linux EC2 인스턴스를 배포하는 방법에 대한 EC2 지침 링크가 제공됩니다. 다음 섹션에서는 이러한 단계를 요약했습니다. 자세한 내용은 링크된 AWS EC2 관련 문서를 참조하세요.
AWS EC2 환경 설정
EC2 및 FSx 서비스에서 Oracle 환경을 실행하는 데 필요한 리소스를 프로비저닝하려면 AWS 계정을 만들어야 합니다. 다음 AWS 문서에는 필요한 세부 정보가 나와 있습니다.
주요 주제:
-
AWS에 가입하세요.
-
키 쌍을 생성합니다.
-
보안 그룹을 만듭니다.
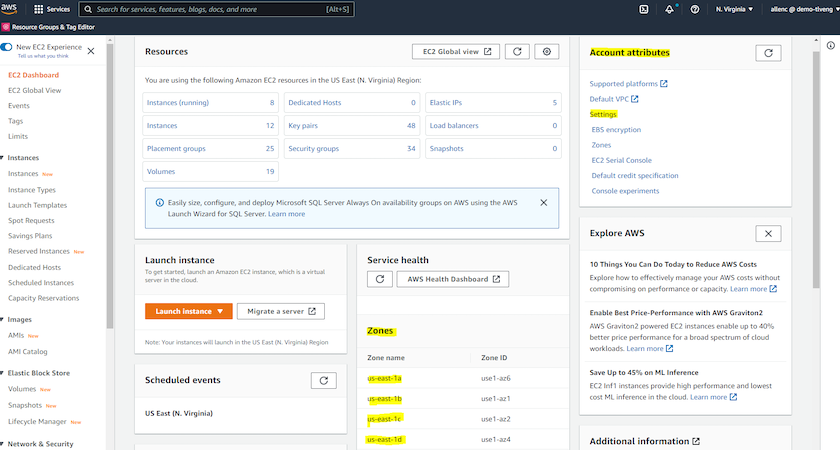
AWS 계정 속성에서 여러 가용성 영역 활성화
아키텍처 다이어그램에 표시된 대로 Oracle 고가용성 구성의 경우, 한 지역에서 최소 4개의 가용성 영역을 활성화해야 합니다. 여러 가용성 구역은 재해 복구에 필요한 거리를 충족하기 위해 서로 다른 지역에 위치할 수도 있습니다.
Oracle 데이터베이스 호스팅을 위한 EC2 인스턴스 생성 및 연결
튜토리얼을 보세요"Amazon EC2 Linux 인스턴스 시작하기" 단계별 배포 절차와 모범 사례를 확인하세요.
주요 주제:
-
개요.
-
필수 조건
-
1단계: 인스턴스 시작
-
2단계: 인스턴스에 연결합니다.
-
3단계: 인스턴스 정리
다음 스크린샷은 Oracle을 실행하기 위해 EC2 콘솔을 사용하여 m5 유형 Linux 인스턴스를 배포하는 방법을 보여줍니다.
-
EC2 대시보드에서 노란색 인스턴스 시작 버튼을 클릭하여 EC2 인스턴스 배포 워크플로를 시작합니다.
-
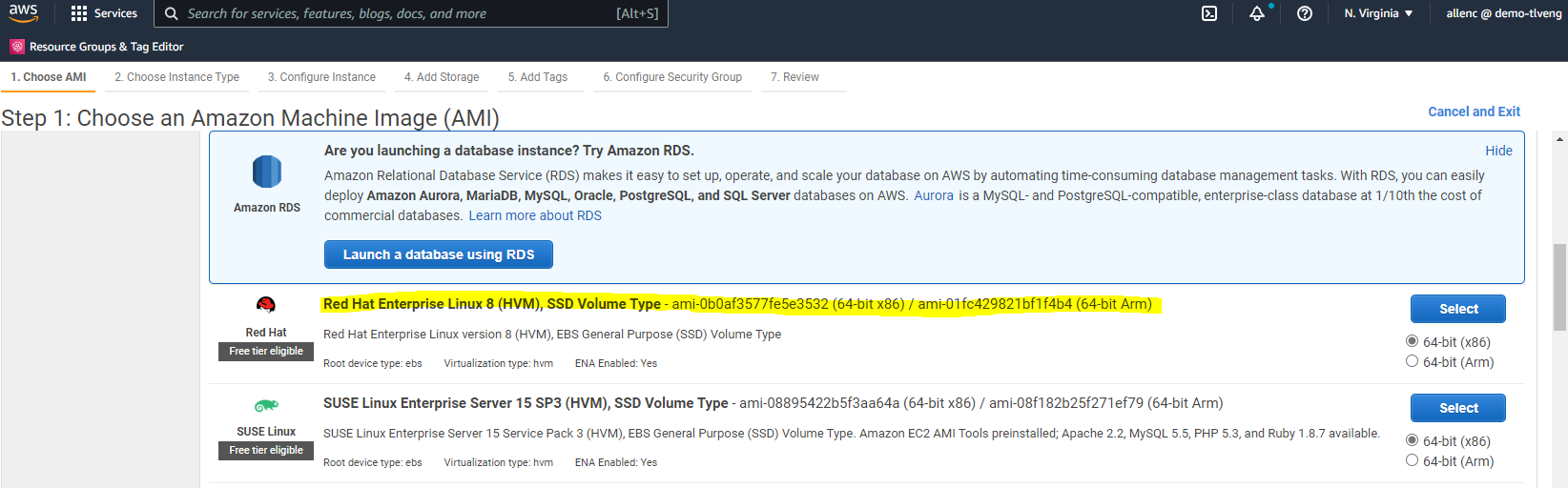
1단계에서 "Red Hat Enterprise Linux 8(HVM), SSD 볼륨 유형 - ami-0b0af3577fe5e3532(64비트 x86) / ami-01fc429821bf1f4b4(64비트 Arm)"를 선택합니다.
-
2단계에서는 Oracle 데이터베이스 작업 부하에 따라 적절한 CPU 및 메모리 할당을 갖춘 m5 인스턴스 유형을 선택합니다. "다음: 인스턴스 세부 정보 구성"을 클릭합니다.
-
3단계에서는 인스턴스가 배치될 VPC와 서브넷을 선택하고 공용 IP 할당을 활성화합니다. "다음: 저장소 추가"를 클릭하세요.
-
4단계에서는 루트 디스크에 충분한 공간을 할당합니다. 스왑을 추가하려면 공간이 필요할 수도 있습니다. 기본적으로 EC2 인스턴스는 스왑 공간을 0으로 할당하는데, 이는 Oracle을 실행하기에 최적이 아닙니다.
-
5단계에서는 필요한 경우 인스턴스 식별을 위한 태그를 추가합니다.
-
6단계에서는 기존 보안 그룹을 선택하거나 인스턴스에 대한 원하는 인바운드 및 아웃바운드 정책으로 새 보안 그룹을 만듭니다.
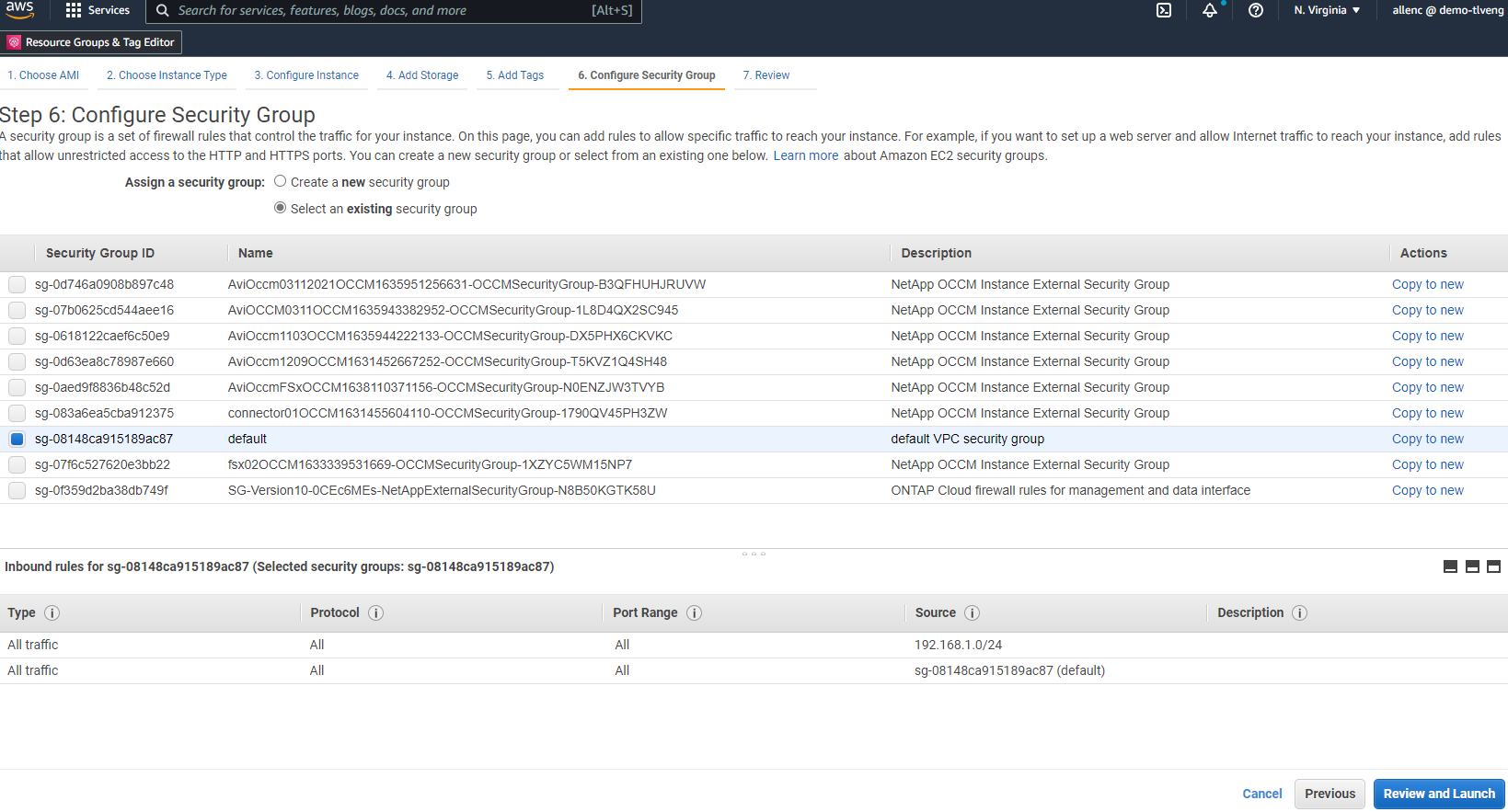
-
7단계에서는 인스턴스 구성 요약을 검토하고 시작을 클릭하여 인스턴스 배포를 시작합니다. 인스턴스에 액세스하려면 키 쌍을 만들거나 키 쌍을 선택하라는 메시지가 표시됩니다.
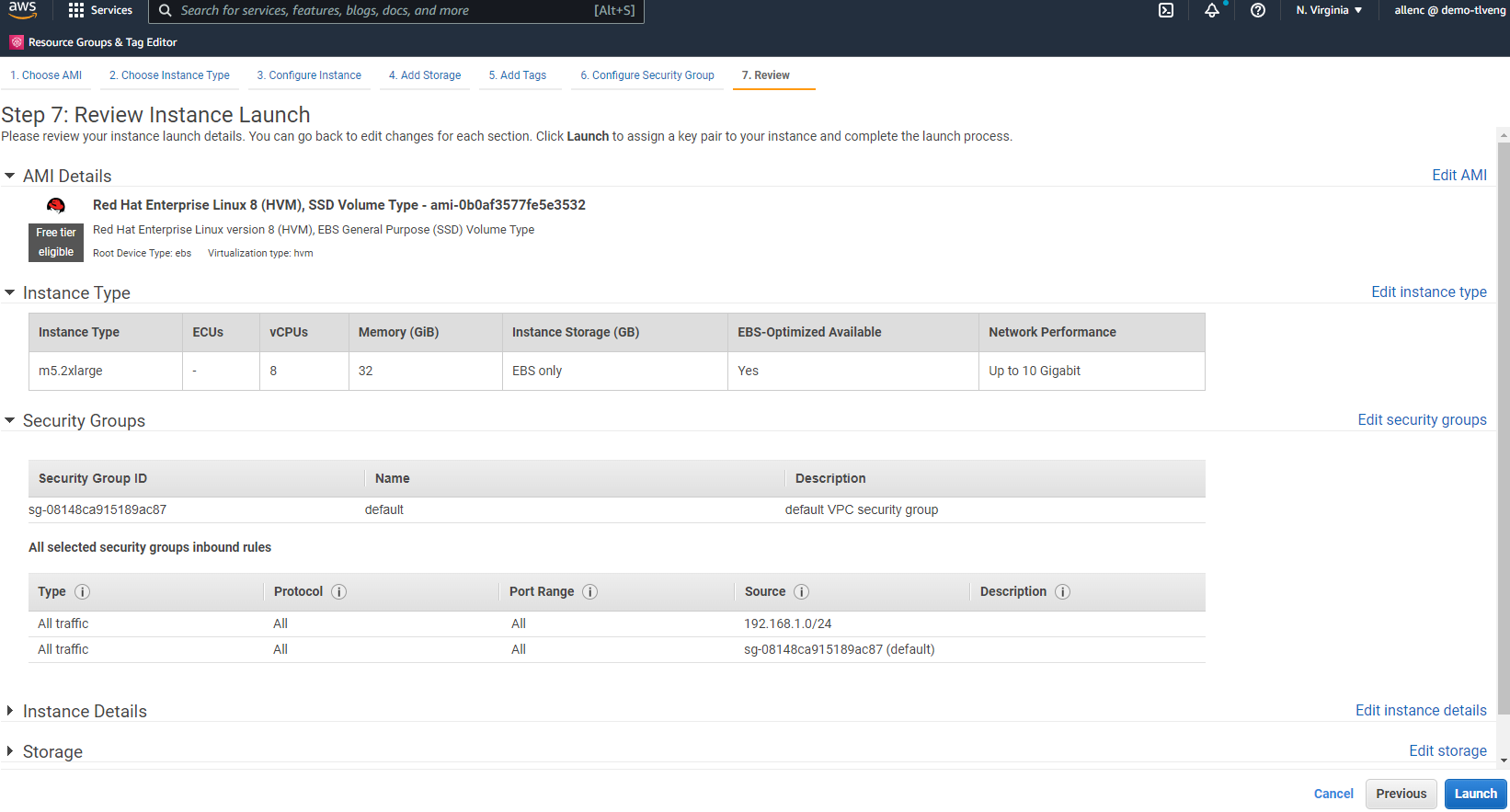
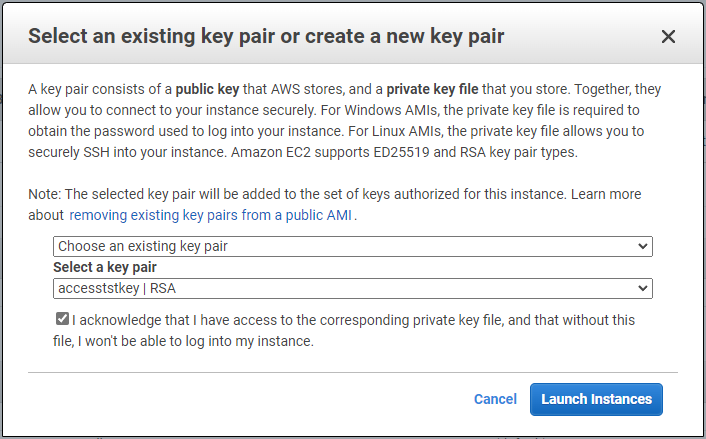
-
SSH 키 쌍을 사용하여 EC2 인스턴스에 로그인합니다. 키 이름과 인스턴스 IP 주소를 적절하게 변경하세요.
ssh -i ora-db1v2.pem ec2-user@54.80.114.77
아키텍처 다이어그램에 표시된 대로 지정된 가용성 영역에서 기본 및 대기 Oracle 서버로 두 개의 EC2 인스턴스를 만들어야 합니다.
Oracle 데이터베이스 스토리지를 위한 FSx ONTAP 파일 시스템 제공
EC2 인스턴스 배포는 OS에 대한 EBS 루트 볼륨을 할당합니다. FSx ONTAP 파일 시스템은 Oracle 바이너리, 데이터, 로그 볼륨을 포함한 Oracle 데이터베이스 저장 볼륨을 제공합니다. FSx 스토리지 NFS 볼륨은 AWS FSx 콘솔이나 Oracle 설치에서 프로비저닝할 수 있으며, 사용자가 자동화 매개변수 파일에서 구성한 대로 볼륨을 할당하는 구성 자동화가 가능합니다.
FSx ONTAP 파일 시스템 생성
이 문서를 참조했습니다 "FSx ONTAP 파일 시스템 관리" FSx ONTAP 파일 시스템을 만드는 데 사용됩니다.
주요 고려 사항:
-
SSD 저장 용량. 최소 1024GiB, 최대 192TiB.
-
프로비저닝된 SSD IOPS. 작업 부하 요구 사항에 따라 파일 시스템당 최대 80,000 SSD IOPS입니다.
-
처리량 용량.
-
관리자 fsxadmin/vsadmin 비밀번호를 설정합니다. FSx 구성 자동화에 필요합니다.
-
백업 및 유지관리. 자동 일일 백업을 비활성화합니다. 데이터베이스 저장소 백업은 SnapCenter 스케줄링을 통해 실행됩니다.
-
SVM 세부 정보 페이지에서 SVM 관리 IP 주소와 프로토콜별 액세스 주소를 검색합니다. FSx 구성 자동화에 필요합니다.
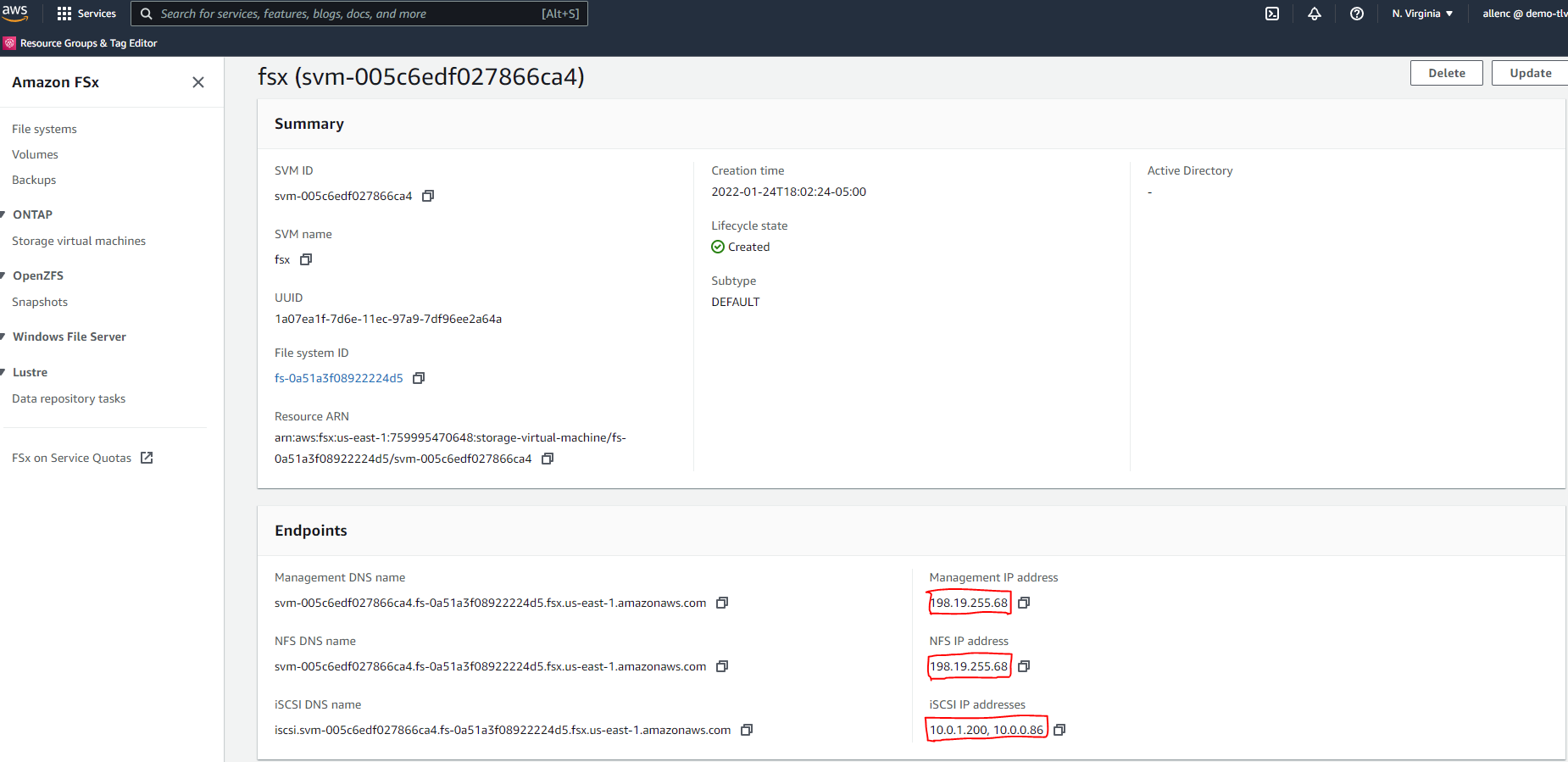
기본 또는 대기 HA FSx 클러스터를 설정하기 위한 다음 단계별 절차를 참조하세요.
-
FSx 콘솔에서 파일 시스템 만들기를 클릭하여 FSx 프로비저닝 워크플로를 시작합니다.
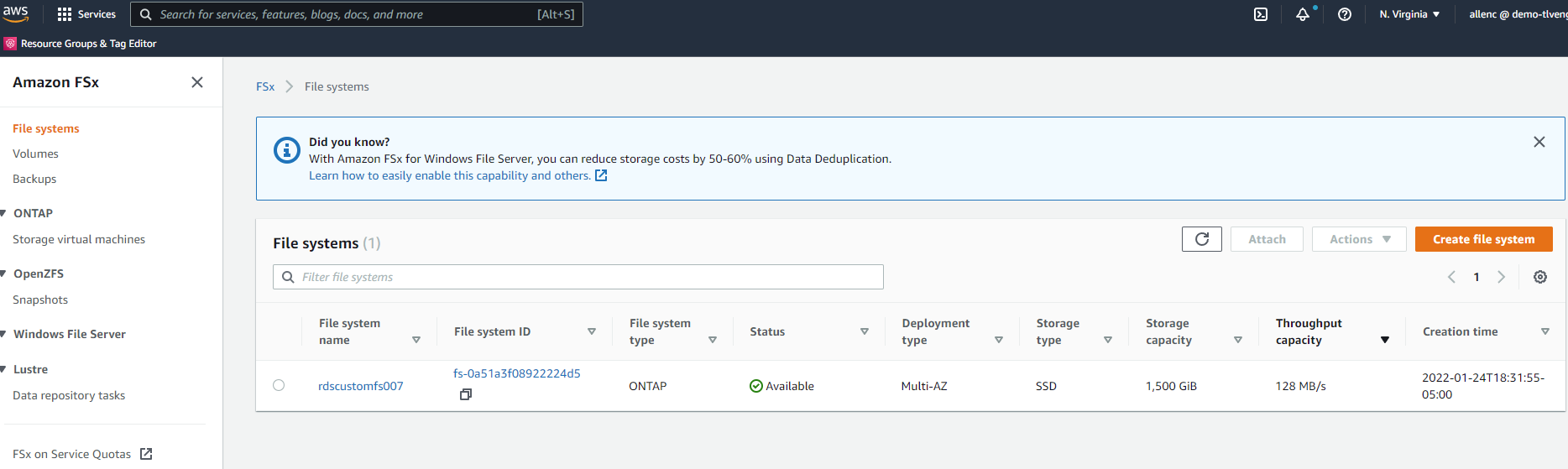
-
Amazon FSx ONTAP 선택하세요. 그런 다음 다음을 클릭합니다.
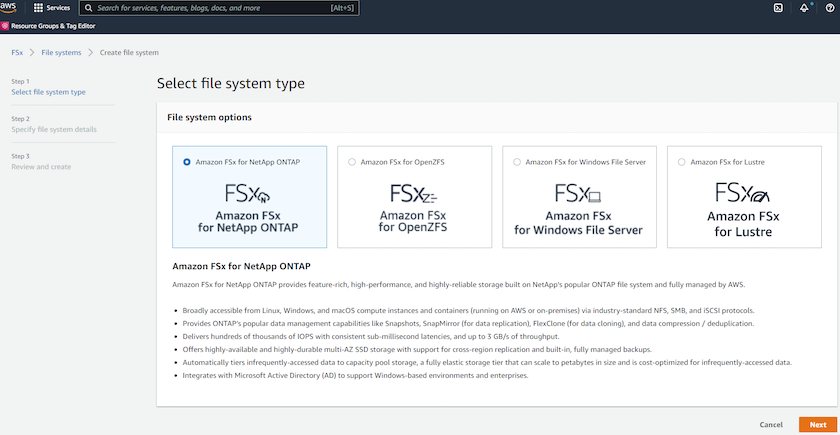
-
표준 생성을 선택하고 파일 시스템 세부 정보에서 파일 시스템의 이름을 Multi-AZ HA로 지정합니다. 데이터베이스 작업 부하에 따라 최대 80,000 SSD IOPS까지 자동 또는 사용자 프로비저닝 IOPS를 선택하세요. FSx 스토리지는 백엔드에 최대 2TiB NVMe 캐싱을 제공하여 더욱 높은 측정 IOPS를 제공할 수 있습니다.
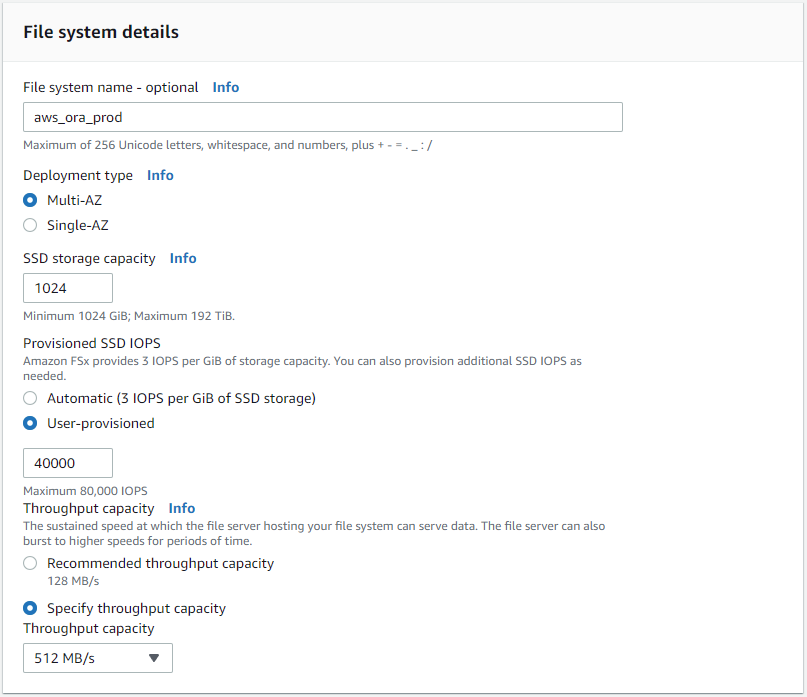
-
네트워크 및 보안 섹션에서 VPC, 보안 그룹 및 서브넷을 선택합니다. FSx 배포 전에 만들어야 합니다. FSx 클러스터의 역할(기본 또는 대기)에 따라 FSx 스토리지 노드를 적절한 영역에 배치합니다.
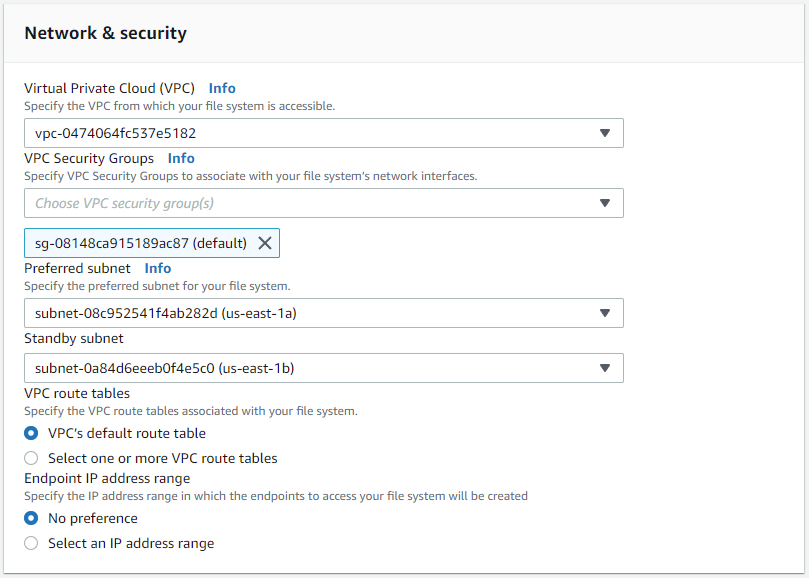
-
보안 및 암호화 섹션에서 기본값을 수락하고 fsxadmin 비밀번호를 입력합니다.
-
SVM 이름과 vsadmin 비밀번호를 입력하세요.
-
볼륨 구성을 비워두세요. 이 시점에서는 볼륨을 만들 필요가 없습니다.
-
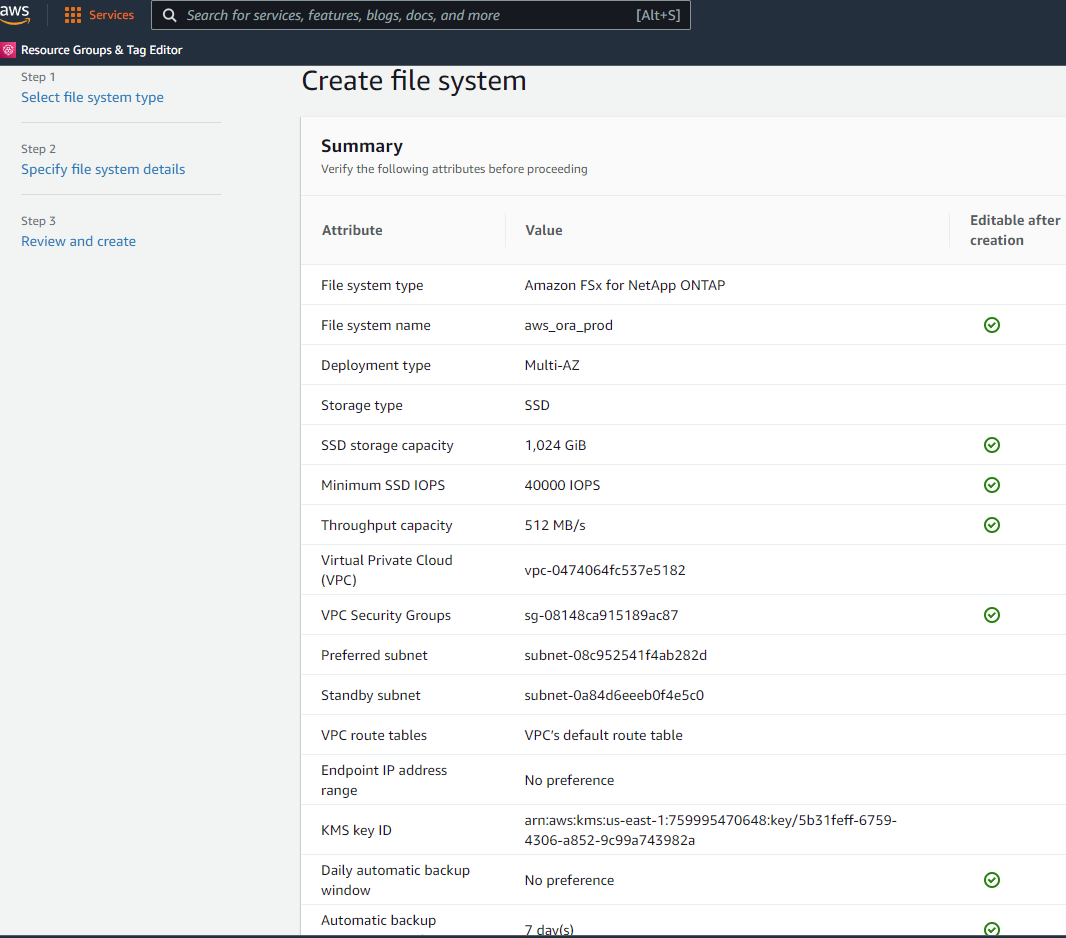
요약 페이지를 검토하고 파일 시스템 만들기를 클릭하여 FSx 파일 시스템 프로비저닝을 완료합니다.
Oracle 데이터베이스를 위한 데이터베이스 볼륨 프로비저닝
보다"FSx ONTAP 볼륨 관리 - 볼륨 생성" 자세한 내용은.
주요 고려 사항:
-
데이터베이스 볼륨 크기를 적절하게 조정합니다.
-
성능 구성을 위한 용량 풀 계층화 정책을 비활성화합니다.
-
NFS 스토리지 볼륨에 대해 Oracle dNFS를 활성화합니다.
-
iSCSI 스토리지 볼륨에 대한 다중 경로 설정.
FSx 콘솔에서 데이터베이스 볼륨 생성
AWS FSx 콘솔에서 Oracle 데이터베이스 파일 스토리지에 대한 세 개의 볼륨을 만들 수 있습니다. 하나는 Oracle 바이너리용, 하나는 Oracle 데이터용, 하나는 Oracle 로그용입니다. 적절한 식별을 위해 볼륨 이름이 Oracle 호스트 이름(자동화 툴킷의 호스트 파일에 정의됨)과 일치하는지 확인하세요. 이 예에서는 EC2 인스턴스의 일반적인 IP 주소 기반 호스트 이름 대신 db1을 EC2 Oracle 호스트 이름으로 사용합니다.
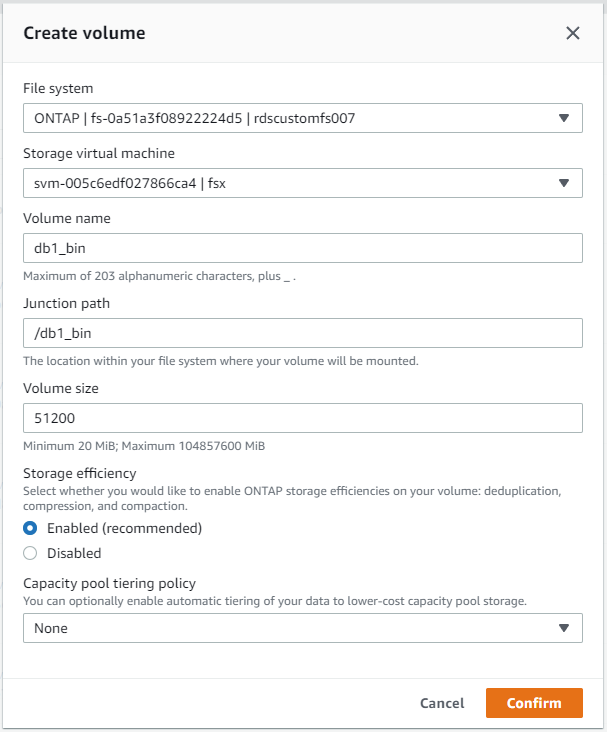
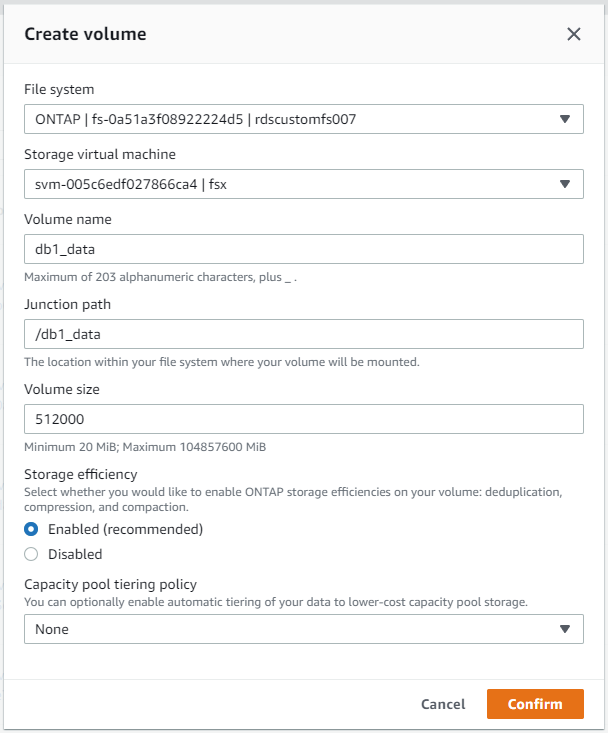
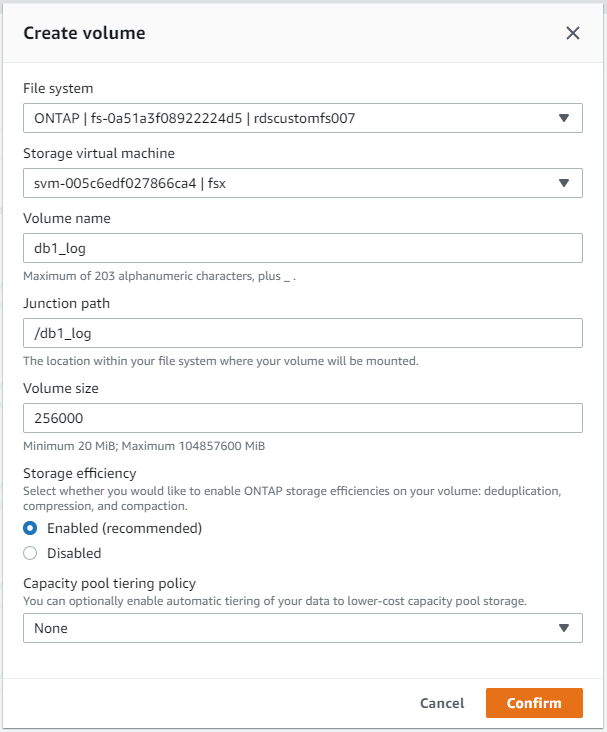

|
현재 FSx 콘솔에서는 iSCSI LUN 생성이 지원되지 않습니다. Oracle에 대한 iSCSI LUN 배포의 경우, NetApp Automation Toolkit을 사용하여 ONTAP 자동화를 사용하여 볼륨과 LUN을 생성할 수 있습니다. |
FSx 데이터베이스 볼륨이 있는 EC2 인스턴스에 Oracle 설치 및 구성
NetApp 자동화 팀은 모범 사례에 따라 EC2 인스턴스에서 Oracle 설치 및 구성을 실행하는 자동화 키트를 제공합니다. 자동화 키트의 현재 버전은 기본 RU 패치 19.8을 사용하여 NFS에서 Oracle 19c를 지원합니다. 필요한 경우 자동화 키트를 다른 RU 패치에 쉽게 적용할 수 있습니다.
자동화를 실행하기 위한 Ansible 컨트롤러 준비
"섹션의 지침을 따르세요.Oracle 데이터베이스 호스팅을 위한 EC2 인스턴스 생성 및 연결 "Ansible 컨트롤러를 실행하기 위해 작은 EC2 Linux 인스턴스를 프로비저닝합니다. RedHat을 사용하는 대신 2vCPU와 8G RAM을 탑재한 Amazon Linux t2.large로 충분할 것입니다.
NetApp Oracle 배포 자동화 툴킷 검색
1단계에서 프로비저닝된 EC2 Ansible 컨트롤러 인스턴스에 ec2-user로 로그인하고 ec2-user 홈 디렉토리에서 다음을 실행합니다. git clone 자동화 코드 사본을 복제하는 명령입니다.
git clone https://github.com/NetApp-Automation/na_oracle19c_deploy.gitgit clone https://github.com/NetApp-Automation/na_rds_fsx_oranfs_config.git자동화 툴킷을 사용하여 자동화된 Oracle 19c 배포 실행
자세한 지침을 참조하세요"CLI 배포 Oracle 19c 데이터베이스" CLI 자동화를 통해 Oracle 19c를 배포합니다. 호스트 액세스 인증을 위해 비밀번호 대신 SSH 키 쌍을 사용하기 때문에 플레이북 실행을 위한 명령 구문에 약간의 변경 사항이 있습니다. 다음 목록은 간략한 요약입니다.
-
기본적으로 EC2 인스턴스는 액세스 인증을 위해 SSH 키 쌍을 사용합니다. Ansible 컨트롤러 자동화 루트 디렉토리에서
/home/ec2-user/na_oracle19c_deploy, 그리고/home/ec2-user/na_rds_fsx_oranfs_configSSH 키의 사본을 만드세요accesststkey.pem"단계에서 배포된 Oracle 호스트의 경우Oracle 데이터베이스 호스팅을 위한 EC2 인스턴스 생성 및 연결 ." -
EC2 인스턴스 DB 호스트에 ec2-user로 로그인하고 python3 라이브러리를 설치합니다.
sudo yum install python3 -
루트 디스크 드라이브에서 16G 스왑 공간을 만듭니다. 기본적으로 EC2 인스턴스는 스왑 공간을 생성하지 않습니다. 다음 AWS 문서를 따르세요."스왑 파일을 사용하여 Amazon EC2 인스턴스에서 스왑 공간으로 작동하는 메모리를 할당하려면 어떻게 해야 합니까?" .
-
Ansible 컨트롤러로 돌아가기(
cd /home/ec2-user/na_rds_fsx_oranfs_config), 그리고 적절한 요구 사항을 사용하여 사전 복제 플레이북을 실행합니다.linux_config태그.ansible-playbook -i hosts rds_preclone_config.yml -u ec2-user --private-key accesststkey.pem -e @vars/fsx_vars.yml -t requirements_configansible-playbook -i hosts rds_preclone_config.yml -u ec2-user --private-key accesststkey.pem -e @vars/fsx_vars.yml -t linux_config -
로 전환
/home/ec2-user/na_oracle19c_deploy-master디렉토리에서 README 파일을 읽고 글로벌을 채웁니다.vars.yml관련 글로벌 매개변수가 포함된 파일입니다. -
채우다
host_name.yml관련 매개변수가 있는 파일host_vars예배 규칙서. -
Linux용 플레이북을 실행하고 vsadmin 비밀번호를 입력하라는 메시지가 표시되면 Enter를 누릅니다.
ansible-playbook -i hosts all_playbook.yml -u ec2-user --private-key accesststkey.pem -t linux_config -e @vars/vars.yml -
Oracle용 플레이북을 실행하고 vsadmin 비밀번호를 입력하라는 메시지가 표시되면 Enter를 누릅니다.
ansible-playbook -i hosts all_playbook.yml -u ec2-user --private-key accesststkey.pem -t oracle_config -e @vars/vars.yml
필요한 경우 SSH 키 파일의 권한 비트를 400으로 변경합니다. Oracle 호스트 변경(ansible_host 에서 host_vars 파일) IP 주소를 EC2 인스턴스 공용 주소로 변경합니다.
기본 및 대기 FSx HA 클러스터 간 SnapMirror 설정
고가용성 및 재해 복구를 위해 기본 및 대기 FSx 스토리지 클러스터 간에 SnapMirror 복제를 설정할 수 있습니다. 다른 클라우드 스토리지 서비스와 달리 FSx를 사용하면 사용자가 원하는 빈도와 복제 처리량으로 스토리지 복제를 제어하고 관리할 수 있습니다. 또한 이를 통해 사용자는 가용성에 영향을 주지 않고 HA/DR을 테스트할 수 있습니다.
다음 단계에서는 기본 및 대기 FSx 스토리지 클러스터 간에 복제를 설정하는 방법을 보여줍니다.
-
기본 및 대기 클러스터 피어링을 설정합니다. fsxadmin 사용자로 기본 클러스터에 로그인하고 다음 명령을 실행합니다. 이 상호 생성 프로세스는 기본 클러스터와 대기 클러스터 모두에서 생성 명령을 실행합니다. 바꾸다
standby_cluster_name사용자 환경에 적합한 이름을 사용하세요.cluster peer create -peer-addrs standby_cluster_name,inter_cluster_ip_address -username fsxadmin -initial-allowed-vserver-peers * -
기본 클러스터와 대기 클러스터 간에 vServer 피어링을 설정합니다. vsadmin 사용자로 기본 클러스터에 로그인하고 다음 명령을 실행합니다. 바꾸다
primary_vserver_name,standby_vserver_name,standby_cluster_name사용자 환경에 적합한 이름을 사용하세요.vserver peer create -vserver primary_vserver_name -peer-vserver standby_vserver_name -peer-cluster standby_cluster_name -applications snapmirror -
클러스터와 vserver 피어링이 올바르게 설정되었는지 확인하세요.
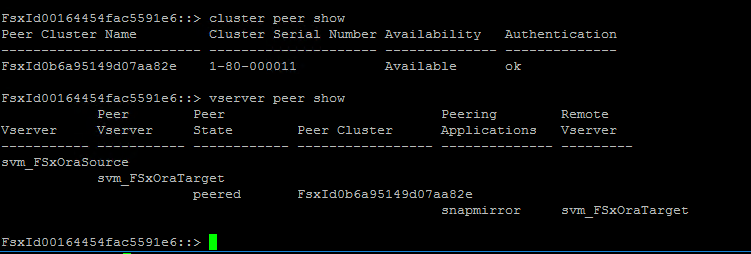
-
기본 FSx 클러스터의 각 소스 볼륨에 대해 대기 FSx 클러스터에 대상 NFS 볼륨을 생성합니다. 사용자 환경에 맞게 볼륨 이름을 바꾸세요.
vol create -volume dr_db1_bin -aggregate aggr1 -size 50G -state online -policy default -type DPvol create -volume dr_db1_data -aggregate aggr1 -size 500G -state online -policy default -type DPvol create -volume dr_db1_log -aggregate aggr1 -size 250G -state online -policy default -type DP -
iSCSI 프로토콜을 사용하여 데이터 액세스하는 경우 Oracle 바이너리, Oracle 데이터 및 Oracle 로그에 대한 iSCSI 볼륨과 LUN을 생성할 수도 있습니다. 스냅샷을 위해 볼륨에 약 10%의 여유 공간을 남겨 두세요.
vol create -volume dr_db1_bin -aggregate aggr1 -size 50G -state online -policy default -unix-permissions ---rwxr-xr-x -type RWlun create -path /vol/dr_db1_bin/dr_db1_bin_01 -size 45G -ostype linuxvol create -volume dr_db1_data -aggregate aggr1 -size 500G -state online -policy default -unix-permissions ---rwxr-xr-x -type RWlun create -path /vol/dr_db1_data/dr_db1_data_01 -size 100G -ostype linuxlun create -path /vol/dr_db1_data/dr_db1_data_02 -size 100G -ostype linuxlun create -path /vol/dr_db1_data/dr_db1_data_03 -size 100G -ostype linuxlun create -path /vol/dr_db1_data/dr_db1_data_04 -size 100G -ostype linuxvol create -volume dr_db1_log -aggregate aggr1 -size 250G -state online -policy default -unix-permissions ---rwxr-xr-x -type RW
lun create -path /vol/dr_db1_log/dr_db1_log_01 -size 45G -ostype linuxlun create -path /vol/dr_db1_log/dr_db1_log_02 -size 45G -ostype linuxlun create -path /vol/dr_db1_log/dr_db1_log_03 -size 45G -ostype linuxlun create -path /vol/dr_db1_log/dr_db1_log_04 -size 45G -ostype linux -
iSCSI LUN의 경우 바이너리 LUN을 예로 들어 각 LUN에 대한 Oracle 호스트 이니시에이터에 대한 매핑을 만듭니다. igroup을 사용자 환경에 적합한 이름으로 바꾸고, 추가되는 각 LUN에 대해 lun-id를 증가시킵니다.
lun mapping create -path /vol/dr_db1_bin/dr_db1_bin_01 -igroup ip-10-0-1-136 -lun-id 0lun mapping create -path /vol/dr_db1_data/dr_db1_data_01 -igroup ip-10-0-1-136 -lun-id 1 -
기본 데이터베이스 볼륨과 대기 데이터베이스 볼륨 사이에 SnapMirror 관계를 만듭니다. 사용자 환경에 맞는 SVM 이름을 바꾸세요.
snapmirror create -source-path svm_FSxOraSource:db1_bin -destination-path svm_FSxOraTarget:dr_db1_bin -vserver svm_FSxOraTarget -throttle unlimited -identity-preserve false -policy MirrorAllSnapshots -type DPsnapmirror create -source-path svm_FSxOraSource:db1_data -destination-path svm_FSxOraTarget:dr_db1_data -vserver svm_FSxOraTarget -throttle unlimited -identity-preserve false -policy MirrorAllSnapshots -type DPsnapmirror create -source-path svm_FSxOraSource:db1_log -destination-path svm_FSxOraTarget:dr_db1_log -vserver svm_FSxOraTarget -throttle unlimited -identity-preserve false -policy MirrorAllSnapshots -type DP
이 SnapMirror 설정은 NFS 데이터베이스 볼륨을 위한 NetApp Automation Toolkit을 사용하여 자동화할 수 있습니다. 이 툴킷은 NetApp 공개 GitHub 사이트에서 다운로드할 수 있습니다.
git clone https://github.com/NetApp-Automation/na_ora_hadr_failover_resync.git설정 및 장애 조치 테스트를 시도하기 전에 README 지침을 주의 깊게 읽으세요.
|
|
기본 클러스터에서 스탠바이 클러스터로 Oracle 바이너리를 복제하면 Oracle 라이선스에 문제가 생길 수 있습니다. 자세한 내용은 Oracle 라이선스 담당자에게 문의하세요. 또 다른 방법은 복구 및 장애 조치 시 Oracle을 설치하고 구성하는 것입니다. |
SnapCenter 배포
SnapCenter 설치
따르다"SnapCenter 서버 설치" SnapCenter 서버를 설치하세요. 이 문서에서는 독립형 SnapCenter 서버를 설치하는 방법을 설명합니다. SnapCenter 의 SaaS 버전은 현재 베타 리뷰 중이며 곧 출시될 수 있습니다. 필요한 경우 NetApp 담당자에게 이용 가능 여부를 문의하세요.
EC2 Oracle 호스트에 대한 SnapCenter 플러그인 구성
-
SnapCenter 자동으로 설치된 후 SnapCenter 서버가 설치된 Windows 호스트의 관리자 권한으로 SnapCenter 에 로그인합니다.

-
왼쪽 메뉴에서 설정을 클릭한 다음 자격 증명과 새로 만들기를 클릭하여 SnapCenter 플러그인 설치를 위한 ec2-user 자격 증명을 추가합니다.
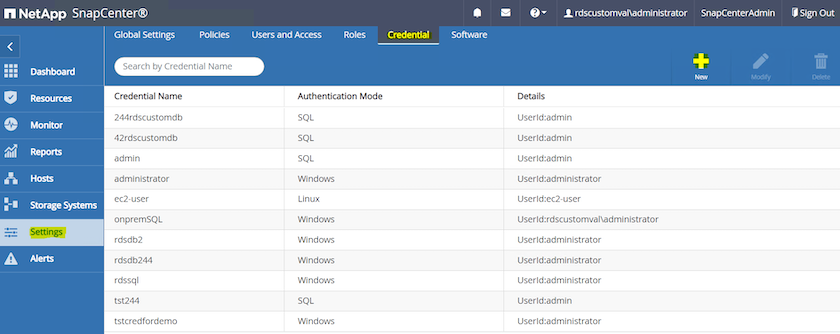
-
ec2-user 비밀번호를 재설정하고 SSH 인증을 활성화하려면 다음을 편집하세요.
/etc/ssh/sshd_configEC2 인스턴스 호스트의 파일입니다. -
"sudo 권한 사용" 체크박스가 선택되어 있는지 확인하세요. 이전 단계에서 ec2-user 비밀번호를 재설정했습니다.
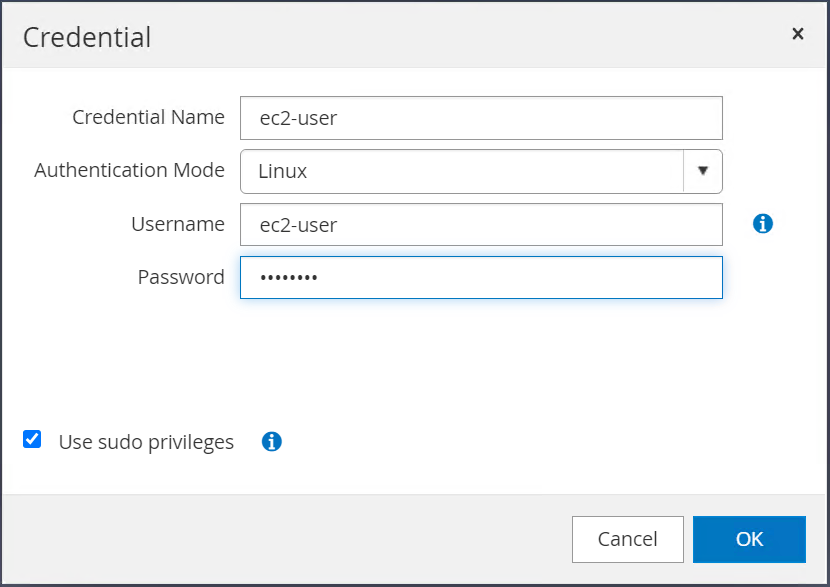
-
이름 확인을 위해 SnapCenter 서버 이름과 IP 주소를 EC2 인스턴스 호스트 파일에 추가합니다.
[ec2-user@ip-10-0-0-151 ~]$ sudo vi /etc/hosts [ec2-user@ip-10-0-0-151 ~]$ cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 10.0.1.233 rdscustomvalsc.rdscustomval.com rdscustomvalsc
-
SnapCenter 서버 Windows 호스트에서 EC2 인스턴스 호스트 IP 주소를 Windows 호스트 파일에 추가합니다.
C:\Windows\System32\drivers\etc\hosts.10.0.0.151 ip-10-0-0-151.ec2.internal
-
왼쪽 메뉴에서 호스트 > 관리 호스트를 선택한 다음 추가를 클릭하여 EC2 인스턴스 호스트를 SnapCenter 에 추가합니다.
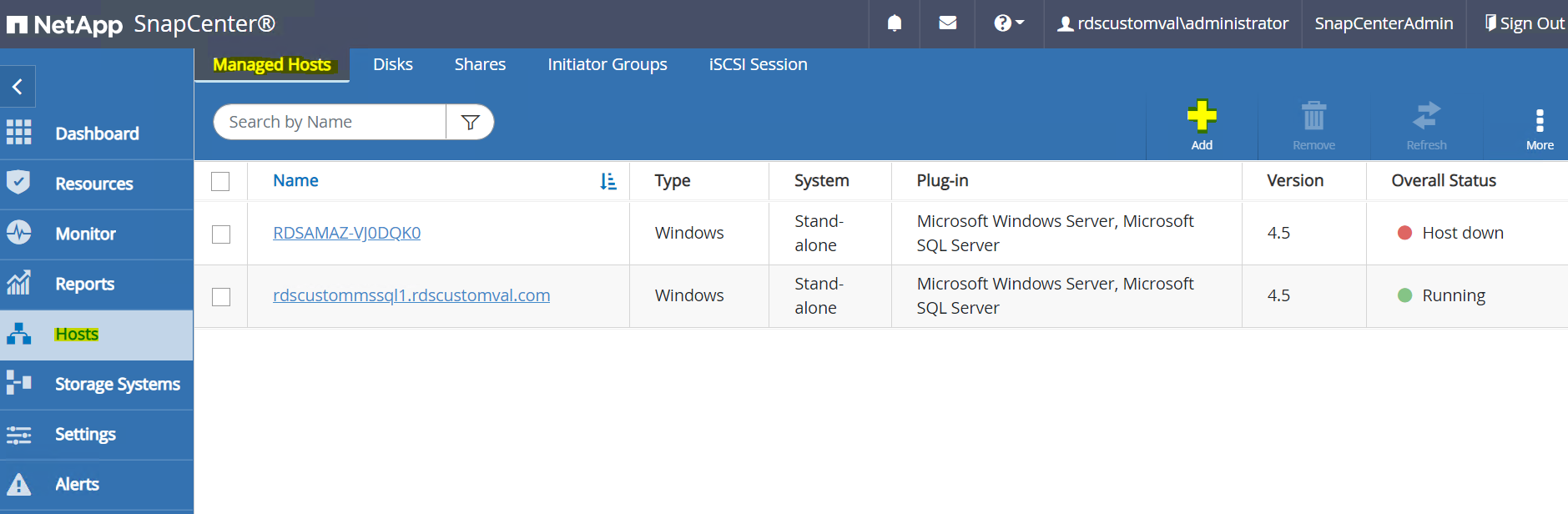
Oracle Database를 확인하고 제출하기 전에 추가 옵션을 클릭하세요.
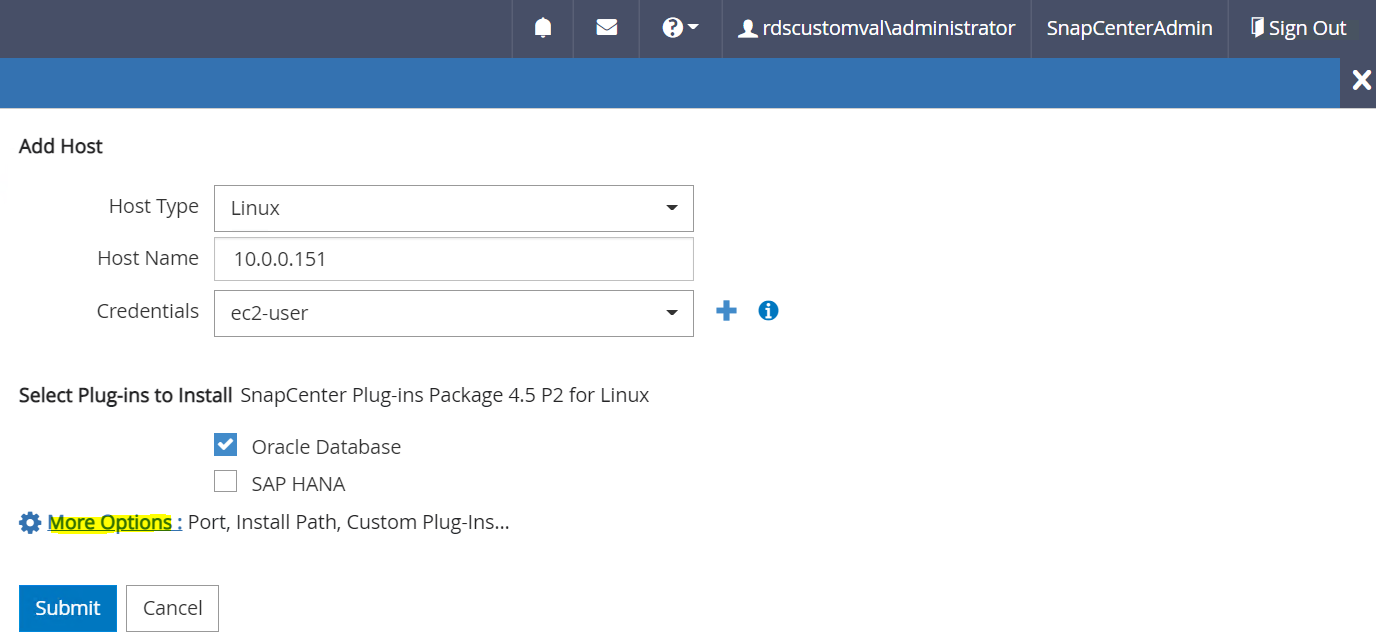
사전 설치 검사를 건너뜁니다. 사전 설치 검사 건너뛰기를 선택한 후 저장 후 제출을 클릭합니다.
지문 확인 메시지가 표시되면 확인 및 제출을 클릭합니다.
플러그인 구성이 성공적으로 완료되면 관리 호스트의 전반적인 상태가 '실행 중'으로 표시됩니다.

Oracle 데이터베이스에 대한 백업 정책 구성
이 섹션을 참조하세요"SnapCenter 에서 데이터베이스 백업 정책 설정" Oracle 데이터베이스 백업 정책 구성에 대한 자세한 내용은 다음을 참조하세요.
일반적으로 전체 스냅샷 Oracle 데이터베이스 백업에 대한 정책과 Oracle 아카이브 로그 전용 스냅샷 백업에 대한 정책을 만들어야 합니다.
|
|
백업 정책에서 Oracle 아카이브 로그 정리를 활성화하여 로그 아카이브 공간을 제어할 수 있습니다. HA 또는 DR을 위해 대기 위치로 복제해야 하므로 "보조 복제 옵션 선택"에서 "로컬 스냅샷 복사본을 만든 후 SnapMirror 업데이트"를 선택하세요. |
Oracle 데이터베이스 백업 및 일정 구성
SnapCenter 의 데이터베이스 백업은 사용자가 구성할 수 있으며, 리소스 그룹 내에서 개별적으로 또는 그룹으로 설정할 수 있습니다. 백업 간격은 RTO 및 RPO 목표에 따라 달라집니다. NetApp 몇 시간마다 전체 데이터베이스 백업을 실행하고 빠른 복구를 위해 10~15분 간격으로 로그 백업을 보관할 것을 권장합니다.
Oracle 섹션을 참조하세요."데이터베이스를 보호하기 위한 백업 정책 구현" 섹션에서 생성된 백업 정책을 구현하기 위한 자세한 단계별 프로세스는 다음과 같습니다.Oracle 데이터베이스에 대한 백업 정책 구성 백업 작업 일정을 위해서입니다.
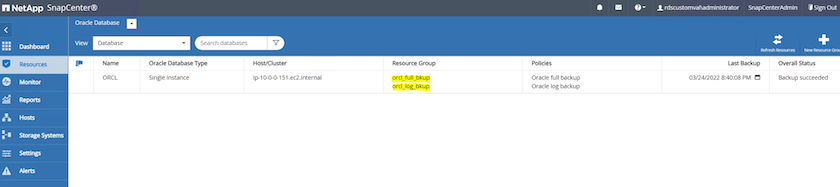
다음 이미지는 Oracle 데이터베이스를 백업하기 위해 설정된 리소스 그룹의 예를 보여줍니다.