

TR-4956: AWS FSx/EC2에서 자동화된 PostgreSQL 고가용성 배포 및 재해 복구
 변경 제안
변경 제안
Allen Cao, Niyaz Mohamed, NetApp
이 솔루션은 FSx ONTAP 스토리지 제품에 내장된 NetApp SnapMirror 기술과 AWS의 NetApp Ansible 자동화 툴킷을 기반으로 PostgreSQL 데이터베이스 배포 및 HA/DR 설정, 장애 조치, 재동기화에 대한 개요와 세부 정보를 제공합니다.
목적
PostgreSQL은 가장 인기 있는 데이터베이스 엔진 10위 중 4위를 차지한 널리 사용되는 오픈 소스 데이터베이스입니다."DB 엔진" . 한편, PostgreSQL은 정교한 기능을 갖추고 있으면서도 라이선스가 필요 없는 오픈 소스 모델에서 인기를 얻었습니다. 반면, 오픈 소스이기 때문에 고가용성 및 재해 복구(HA/DR) 측면에서 프로덕션 등급 데이터베이스를 구축하는 방법에 대한 자세한 지침이 부족하며, 특히 퍼블릭 클라우드에서 그렇습니다. 일반적으로 핫 스탠바이, 웜 스탠바이, 스트리밍 복제 등을 갖춘 일반적인 PostgreSQL HA/DR 시스템을 설정하는 것은 어려울 수 있습니다. 대기 사이트를 승격시킨 후 기본 사이트로 다시 전환하여 HA/DR 환경을 테스트하면 프로덕션에 중단이 발생할 수 있습니다. 스트리밍 핫 스탠바이에 읽기 워크로드를 배포하는 경우 기본 서버에서 성능 문제가 발생하는 것은 잘 알려진 사실입니다.
이 문서에서는 애플리케이션 수준의 PostgreSQL 스트리밍 HA/DR 솔루션을 없애고 스토리지 수준 복제를 사용하여 AWS FSx ONTAP 스토리지와 EC2 컴퓨팅 인스턴스 기반의 PostgreSQL HA/DR 솔루션을 구축하는 방법을 보여줍니다. 이 솔루션은 더 간단하고 비교 가능한 시스템을 만들어내며, HA/DR을 위한 기존 PostgreSQL 애플리케이션 수준 스트리밍 복제와 동일한 결과를 제공합니다.
이 솔루션은 PostgreSQL HA/DR을 위한 AWS 기반 FSX ONTAP 클라우드 스토리지에서 사용 가능한 검증되고 성숙한 NetApp SnapMirror 스토리지 수준 복제 기술을 기반으로 구축되었습니다. NetApp 솔루션 팀에서 제공하는 자동화 툴킷을 사용하면 간단하게 구현할 수 있습니다. 애플리케이션 수준 스트리밍 기반 HA/DR 솔루션은 기본 사이트의 복잡성과 성능 저하를 제거하는 동시에 유사한 기능을 제공합니다. 이 솔루션은 활성 기본 사이트에 영향을 주지 않고 쉽게 배포하고 테스트할 수 있습니다.
이 솔루션은 다음과 같은 사용 사례를 해결합니다.
-
퍼블릭 AWS 클라우드에서 PostgreSQL을 위한 프로덕션 등급 HA/DR 배포
-
퍼블릭 AWS 클라우드에서 PostgreSQL 워크로드 테스트 및 검증
-
NetApp SnapMirror 복제 기술을 기반으로 한 PostgreSQL HA/DR 전략 테스트 및 검증
대상
이 솔루션은 다음과 같은 사람들을 위해 만들어졌습니다.
-
퍼블릭 AWS 클라우드에서 HA/DR을 갖춘 PostgreSQL을 배포하는 데 관심이 있는 DBA입니다.
-
퍼블릭 AWS 클라우드에서 PostgreSQL 워크로드를 테스트하는 데 관심이 있는 데이터베이스 솔루션 아키텍트입니다.
-
AWS FSx 스토리지에 배포된 PostgreSQL 인스턴스를 배포하고 관리하는 데 관심이 있는 스토리지 관리자입니다.
-
AWS FSx/EC2에서 PostgreSQL 환경을 구축하는 데 관심이 있는 애플리케이션 소유자입니다.
솔루션 테스트 및 검증 환경
이 솔루션의 테스트와 검증은 최종 배포 환경과 일치하지 않을 수 있는 AWS FSx 및 EC2 환경에서 수행되었습니다. 자세한 내용은 다음 섹션을 참조하세요. 배포 고려사항의 핵심 요소 .
아키텍처
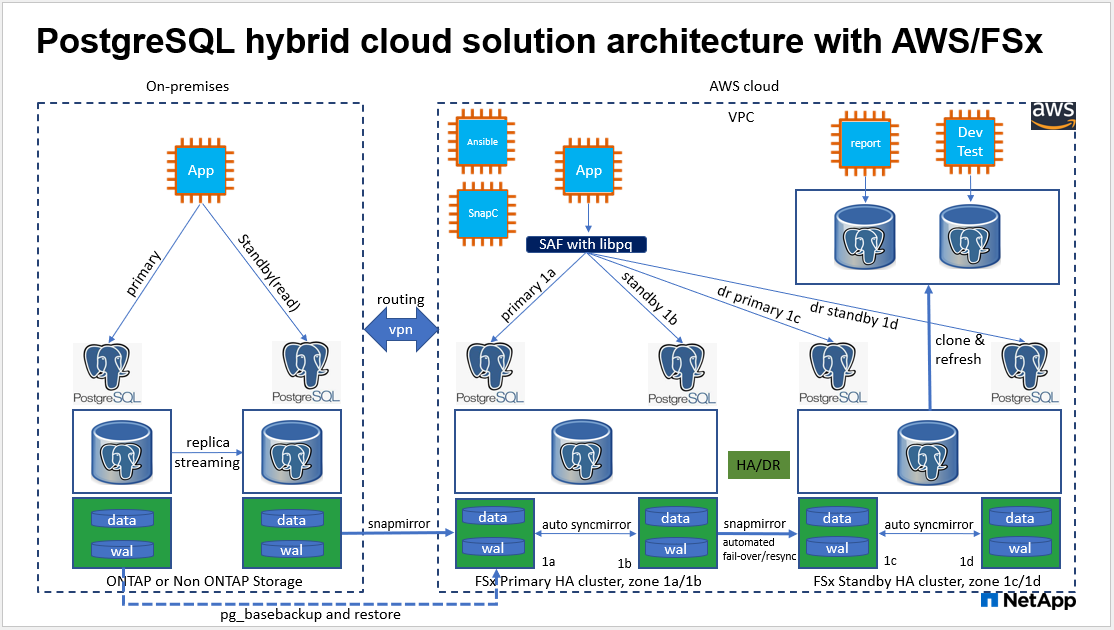
하드웨어 및 소프트웨어 구성 요소
하드웨어 |
||
FSx ONTAP 스토리지 |
현재 버전 |
기본 및 대기 HA 클러스터와 동일한 VPC 및 가용성 영역에 있는 두 개의 FSx HA 쌍 |
컴퓨팅을 위한 EC2 인스턴스 |
t2.xlarge/4vCPU/16G |
두 개의 EC2 T2 xlarge를 기본 및 대기 컴퓨팅 인스턴스로 사용 |
Ansible 컨트롤러 |
온프레미스 Centos VM/4vCPU/8G |
온프레미스 또는 클라우드에서 Ansible 자동화 컨트롤러를 호스팅하는 VM |
소프트웨어 |
||
레드햇 리눅스 |
RHEL-8.6.0_HVM-20220503-x86_64-2-시간별2-GP2 |
테스트를 위해 RedHat 구독을 배포했습니다. |
센토스 리눅스 |
CentOS Linux 릴리스 8.2.2004(코어) |
온프레미스 랩에 배포된 Ansible 컨트롤러 호스팅 |
포스트그레스큐엘 |
버전 14.5 |
자동화는 postgresql.ora yum repo에서 사용 가능한 최신 버전의 PostgreSQL을 가져옵니다. |
앤서블 |
버전 2.10.3 |
요구 사항 플레이북과 함께 설치된 필수 컬렉션 및 라이브러리에 대한 전제 조건 |
배포 고려사항의 핵심 요소
-
PostgreSQL 데이터베이스 백업, 복원 및 복구. PostgreSQL 데이터베이스는 pg_dump를 사용한 논리적 백업, pg_basebackup이나 하위 수준 OS 백업 명령을 사용한 물리적 온라인 백업, 저장소 수준 일관성 스냅샷 등 다양한 백업 방법을 지원합니다. 이 솔루션은 PostgreSQL 데이터베이스 데이터와 WAL 볼륨 백업, 복원 및 대기 사이트에서의 복구를 위해 NetApp 일관성 그룹 스냅샷을 사용합니다. NetApp 일관성 그룹 볼륨 스냅샷은 저장소에 기록되는 동안 시퀀스 I/O를 스냅샷하고 데이터베이스 데이터 파일의 무결성을 보호합니다.
-
EC2 컴퓨팅 인스턴스. 이러한 테스트와 검증에서는 PostgreSQL 데이터베이스 컴퓨팅 인스턴스에 AWS EC2 t2.xlarge 인스턴스 유형을 사용했습니다. NetApp 데이터베이스 작업 부하에 최적화되어 있으므로 PostgreSQL 배포 시 컴퓨팅 인스턴스로 M5 유형 EC2 인스턴스를 사용할 것을 권장합니다. 대기 컴퓨팅 인스턴스는 항상 FSx HA 클러스터에 배포된 수동(대기) 파일 시스템과 동일한 영역에 배포되어야 합니다.
-
FSx 스토리지 HA 클러스터 단일 또는 다중 영역 배포. 이러한 테스트와 검증을 통해 단일 AWS 가용성 영역에 FSx HA 클러스터를 배포했습니다. 프로덕션 배포의 경우 NetApp 두 개의 서로 다른 가용성 영역에 FSx HA 쌍을 배포할 것을 권장합니다. 특정 거리가 기본 및 대기 간에 필요한 경우 비즈니스 연속성을 위한 재해 복구 대기 HA 쌍을 다른 지역에 설정할 수 있습니다. FSx HA 클러스터는 항상 스토리지 수준 중복성을 제공하기 위해 액티브-패시브 파일 시스템 쌍에 동기화 미러링된 HA 쌍으로 프로비저닝됩니다.
-
PostgreSQL 데이터 및 로그 배치. 일반적인 PostgreSQL 배포에서는 데이터와 로그 파일에 대해 동일한 루트 디렉토리나 볼륨을 공유합니다. 테스트와 검증 과정에서 성능을 높이기 위해 PostgreSQL 데이터와 로그를 두 개의 별도 볼륨으로 분리했습니다. 소프트 링크는 PostgreSQL WAL 로그와 보관된 WAL 로그를 호스팅하는 로그 디렉토리나 볼륨을 가리키기 위해 데이터 디렉토리에 사용됩니다.
-
PostgreSQL 서비스 시작 지연 타이머. 이 솔루션은 NFS에 마운트된 볼륨을 사용하여 PostgreSQL 데이터베이스 파일과 WAL 로그 파일을 저장합니다. 데이터베이스 호스트를 재부팅하는 동안 PostgreSQL 서비스는 볼륨이 마운트되지 않은 상태에서 시작하려고 할 수 있습니다. 이로 인해 데이터베이스 서비스 시작이 실패합니다. PostgreSQL 데이터베이스가 올바르게 시작되려면 10~15초의 타이머 지연이 필요합니다.
-
비즈니스 연속성을 위한 RPO/RTO. DR을 위한 기본 서버에서 대기 서버로의 FSx 데이터 복제는 ASYNC를 기반으로 합니다. 즉, RPO는 스냅샷 백업 및 SnapMirror 복제 빈도에 따라 달라집니다. 스냅샷 복사와 SnapMirror 복제 빈도가 높아지면 RPO가 줄어듭니다. 따라서 재해 발생 시 잠재적인 데이터 손실과 증가하는 저장 비용 사이에 균형이 필요합니다. RPO의 경우 스냅샷 복사와 SnapMirror 복제를 단 5분 간격으로 구현할 수 있고, RTO의 경우 PostgreSQL을 일반적으로 1분 이내에 DR 대기 사이트에서 복구할 수 있다는 것을 확인했습니다.
-
데이터베이스 백업. PostgreSQL 데이터베이스가 온프레미스 데이터 센터에서 AWS FSx 스토리지로 구현되거나 마이그레이션된 후, 데이터는 보호를 위해 FSx HA 쌍에 자동으로 동기화되어 미러링됩니다. 재해 발생 시 복제된 대기 사이트를 통해 데이터가 추가로 보호됩니다. 장기 백업 보존이나 데이터 보호를 위해 NetApp 내장된 PostgreSQL pg_basebackup 유틸리티를 사용하여 S3 Blob 스토리지로 이식할 수 있는 전체 데이터베이스 백업을 실행할 것을 권장합니다.
솔루션 배포
아래에 설명된 자세한 지침에 따라 NetApp Ansible 기반 자동화 툴킷을 사용하여 이 솔루션의 배포를 자동으로 완료할 수 있습니다.
-
자동화 툴킷 READme.md의 지침을 읽어보세요."na_postgresql_aws_deploy_hadr" .
-
다음 영상을 통해 연습해보세요.
-
필수 매개변수 파일을 구성합니다.(
hosts,host_vars/host_name.yml,fsx_vars.yml) 관련 섹션의 템플릿에 사용자별 매개변수를 입력하여. 그런 다음 복사 버튼을 사용하여 파일을 Ansible 컨트롤러 호스트로 복사합니다.
자동 배포를 위한 전제 조건
배포에는 다음과 같은 전제 조건이 필요합니다.
-
AWS 계정이 설정되었고, AWS 계정 내에 필요한 VPC 및 네트워크 세그먼트가 생성되었습니다.
-
AWS EC2 콘솔에서 두 개의 EC2 Linux 인스턴스를 배포해야 합니다. 하나는 기본 사이트의 기본 PostgreSQL DB 서버로, 다른 하나는 대기 DR 사이트에 배포해야 합니다. 기본 및 대기 DR 사이트에서 컴퓨팅 중복성을 위해 두 개의 추가 EC2 Linux 인스턴스를 대기 PostgreSQL DB 서버로 배포합니다. 환경 설정에 대한 자세한 내용은 이전 섹션의 아키텍처 다이어그램을 참조하세요. 또한 검토하세요"Linux 인스턴스 사용자 가이드" 자세한 내용은.
-
AWS EC2 콘솔에서 두 개의 FSx ONTAP 스토리지 HA 클러스터를 배포하여 PostgreSQL 데이터베이스 볼륨을 호스팅합니다. FSx 스토리지 배포에 익숙하지 않은 경우 설명서를 참조하세요."FSx ONTAP 파일 시스템 생성" 단계별 지침을 확인하세요.
-
Ansible 컨트롤러를 호스팅하기 위해 Centos Linux VM을 빌드합니다. Ansible 컨트롤러는 온프레미스 또는 AWS 클라우드에 위치할 수 있습니다. 온프레미스에 있는 경우 VPC, EC2 Linux 인스턴스 및 FSx 스토리지 클러스터에 SSH 연결이 있어야 합니다.
-
리소스에서 "RHEL/CentOS에 CLI 배포를 위한 Ansible 제어 노드 설정" 섹션에 설명된 대로 Ansible 컨트롤러를 설정합니다."NetApp 솔루션 자동화 시작하기" .
-
공개 NetApp GitHub 사이트에서 자동화 툴킷 사본을 복제합니다.
git clone https://github.com/NetApp-Automation/na_postgresql_aws_deploy_hadr.git-
툴킷 루트 디렉토리에서 필수 플레이북을 실행하여 Ansible 컨트롤러에 필요한 컬렉션과 라이브러리를 설치합니다.
ansible-playbook -i hosts requirements.ymlansible-galaxy collection install -r collections/requirements.yml --force --force-with-deps-
DB 호스트 변수 파일에 필요한 EC2 FSx 인스턴스 매개변수를 검색합니다.
host_vars/*그리고 전역 변수 파일fsx_vars.yml구성.
호스트 파일 구성
기본 FSx ONTAP 클러스터 관리 IP와 EC2 인스턴스 호스트 이름을 호스트 파일에 입력합니다.
# Primary FSx cluster management IP address [fsx_ontap] 172.30.15.33
# Primary PostgreSQL DB server at primary site where database is initialized at deployment time [postgresql] psql_01p ansible_ssh_private_key_file=psql_01p.pem
# Primary PostgreSQL DB server at standby site where postgresql service is installed but disabled at deployment # Standby DB server at primary site, to setup this server comment out other servers in [dr_postgresql] # Standby DB server at standby site, to setup this server comment out other servers in [dr_postgresql] [dr_postgresql] -- psql_01s ansible_ssh_private_key_file=psql_01s.pem #psql_01ps ansible_ssh_private_key_file=psql_01ps.pem #psql_01ss ansible_ssh_private_key_file=psql_01ss.pem
host_vars 폴더에서 host_name.yml 파일을 구성하세요.
# Add your AWS EC2 instance IP address for the respective PostgreSQL server host
ansible_host: "10.61.180.15"
# "{{groups.postgresql[0]}}" represents first PostgreSQL DB server as defined in PostgreSQL hosts group [postgresql]. For concurrent multiple PostgreSQL DB servers deployment, [0] will be incremented for each additional DB server. For example, "{{groups.posgresql[1]}}" represents DB server 2, "{{groups.posgresql[2]}}" represents DB server 3 ... As a good practice and the default, two volumes are allocated to a PostgreSQL DB server with corresponding /pgdata, /pglogs mount points, which store PostgreSQL data, and PostgreSQL log files respectively. The number and naming of DB volumes allocated to a DB server must match with what is defined in global fsx_vars.yml file by src_db_vols, src_archivelog_vols parameters, which dictates how many volumes are to be created for each DB server. aggr_name is aggr1 by default. Do not change. lif address is the NFS IP address for the SVM where PostgreSQL server is expected to mount its database volumes. Primary site servers from primary SVM and standby servers from standby SVM.
host_datastores_nfs:
- {vol_name: "{{groups.postgresql[0]}}_pgdata", aggr_name: "aggr1", lif: "172.21.94.200", size: "100"}
- {vol_name: "{{groups.postgresql[0]}}_pglogs", aggr_name: "aggr1", lif: "172.21.94.200", size: "100"}
# Add swap space to EC2 instance, that is equal to size of RAM up to 16G max. Determine the number of blocks by dividing swap size in MB by 128.
swap_blocks: "128"
# Postgresql user configurable parameters
psql_port: "5432"
buffer_cache: "8192MB"
archive_mode: "on"
max_wal_size: "5GB"
client_address: "172.30.15.0/24"vars 폴더에서 글로벌 fsx_vars.yml 파일을 구성합니다.
########################################################################
###### PostgreSQL HADR global user configuration variables ######
###### Consolidate all variables from FSx, Linux, and postgresql ######
########################################################################
###########################################
### Ontap env specific config variables ###
###########################################
####################################################################################################
# Variables for SnapMirror Peering
####################################################################################################
#Passphrase for cluster peering authentication
passphrase: "xxxxxxx"
#Please enter destination or standby FSx cluster name
dst_cluster_name: "FsxId0cf8e0bccb14805e8"
#Please enter destination or standby FSx cluster management IP
dst_cluster_ip: "172.30.15.90"
#Please enter destination or standby FSx cluster inter-cluster IP
dst_inter_ip: "172.30.15.13"
#Please enter destination or standby SVM name to create mirror relationship
dst_vserver: "dr"
#Please enter destination or standby SVM management IP
dst_vserver_mgmt_lif: "172.30.15.88"
#Please enter destination or standby SVM NFS lif
dst_nfs_lif: "172.30.15.88"
#Please enter source or primary FSx cluster name
src_cluster_name: "FsxId0cf8e0bccb14805e8"
#Please enter source or primary FSx cluster management IP
src_cluster_ip: "172.30.15.20"
#Please enter source or primary FSx cluster inter-cluster IP
src_inter_ip: "172.30.15.5"
#Please enter source or primary SVM name to create mirror relationship
src_vserver: "prod"
#Please enter source or primary SVM management IP
src_vserver_mgmt_lif: "172.30.15.115"
#####################################################################################################
# Variable for PostgreSQL Volumes, lif - source or primary FSx NFS lif address
#####################################################################################################
src_db_vols:
- {vol_name: "{{groups.postgresql[0]}}_pgdata", aggr_name: "aggr1", lif: "172.21.94.200", size: "100"}
src_archivelog_vols:
- {vol_name: "{{groups.postgresql[0]}}_pglogs", aggr_name: "aggr1", lif: "172.21.94.200", size: "100"}
#Names of the Nodes in the ONTAP Cluster
nfs_export_policy: "default"
#####################################################################################################
### Linux env specific config variables ###
#####################################################################################################
#NFS Mount points for PostgreSQL DB volumes
mount_points:
- "/pgdata"
- "/pglogs"
#RedHat subscription username and password
redhat_sub_username: "xxxxx"
redhat_sub_password: "xxxxx"
####################################################
### DB env specific install and config variables ###
####################################################
#The latest version of PostgreSQL RPM is pulled/installed and config file is deployed from a preconfigured template
#Recovery type and point: default as all logs and promote and leave all PITR parameters blankPostgreSQL 배포 및 HA/DR 설정
다음 작업에서는 PostgreSQL DB 서버 서비스를 배포하고 기본 EC2 DB 서버 호스트의 기본 사이트에서 데이터베이스를 초기화합니다. 그런 다음 대기 사이트에 대기 기본 EC2 DB 서버 호스트가 설정됩니다. 마지막으로, 재해 복구를 위해 기본 사이트 FSx 클러스터에서 대기 사이트 FSx 클러스터로 DB 볼륨 복제가 설정됩니다.
-
기본 FSx 클러스터에 DB 볼륨을 생성하고, 기본 EC2 인스턴스 호스트에 postgresql을 설정합니다.
ansible-playbook -i hosts postgresql_deploy.yml -u ec2-user --private-key psql_01p.pem -e @vars/fsx_vars.yml -
대기 DR EC2 인스턴스 호스트를 설정합니다.
ansible-playbook -i hosts postgresql_standby_setup.yml -u ec2-user --private-key psql_01s.pem -e @vars/fsx_vars.yml -
FSx ONTAP 클러스터 피어링 및 데이터베이스 볼륨 복제를 설정합니다.
ansible-playbook -i hosts fsx_replication_setup.yml -e @vars/fsx_vars.yml -
이전 단계를 단일 단계 PostgreSQL 배포 및 HA/DR 설정으로 통합합니다.
ansible-playbook -i hosts postgresql_hadr_setup.yml -u ec2-user -e @vars/fsx_vars.yml -
기본 사이트나 대기 사이트에 대기 PostgreSQL DB 호스트를 설정하려면 호스트 파일 [dr_postgresql] 섹션에서 다른 모든 서버를 주석 처리한 다음 해당 대상 호스트(예: psql_01ps 또는 기본 사이트의 대기 EC2 컴퓨팅 인스턴스)를 사용하여 postgresql_standby_setup.yml 플레이북을 실행합니다. 다음과 같은 호스트 매개변수 파일을 확인하세요.
psql_01ps.yml아래에 구성됩니다host_vars예배 규칙서.[dr_postgresql] -- #psql_01s ansible_ssh_private_key_file=psql_01s.pem psql_01ps ansible_ssh_private_key_file=psql_01ps.pem #psql_01ss ansible_ssh_private_key_file=psql_01ss.pem
ansible-playbook -i hosts postgresql_standby_setup.yml -u ec2-user --private-key psql_01ps.pem -e @vars/fsx_vars.ymlPostgreSQL 데이터베이스 스냅샷 백업 및 대기 사이트로의 복제
PostgreSQL 데이터베이스 스냅샷 백업 및 스탠바이 사이트로의 복제는 사용자가 정의한 간격으로 Ansible 컨트롤러에서 제어하고 실행할 수 있습니다. 우리는 간격이 5분 정도로 짧을 수 있다는 것을 검증했습니다. 따라서 기본 사이트에 장애가 발생하는 경우, 다음 예약된 스냅샷 백업 바로 전에 장애가 발생하면 5분간의 데이터 손실 가능성이 있습니다.
*/15 * * * * /home/admin/na_postgresql_aws_deploy_hadr/data_log_snap.shDR을 위한 대기 사이트로의 장애 조치
DR 연습으로 PostgreSQL HA/DR 시스템을 테스트하려면 다음 플레이북을 실행하여 대기 사이트의 기본 대기 EC2 DB 인스턴스에서 장애 조치 및 PostgreSQL 데이터베이스 복구를 실행합니다. 실제 DR 시나리오에서는 DR 사이트로의 실제 장애 조치에 대해 동일한 작업을 실행합니다.
ansible-playbook -i hosts postgresql_failover.yml -u ec2-user --private-key psql_01s.pem -e @vars/fsx_vars.yml장애 조치 테스트 후 복제된 DB 볼륨 재동기화
장애 조치 테스트 후 재동기화를 실행하여 데이터베이스 볼륨 SnapMirror 복제를 재설정합니다.
ansible-playbook -i hosts postgresql_standby_resync.yml -u ec2-user --private-key psql_01s.pem -e @vars/fsx_vars.ymlEC2 컴퓨팅 인스턴스 장애로 인해 기본 EC2 DB 서버에서 대기 EC2 DB 서버로 장애 조치(failover)
NetApp 수동 장애 조치를 실행하거나 라이선스가 필요할 수 있는 잘 확립된 OS 클러스터웨어를 사용할 것을 권장합니다.
추가 정보를 찾을 수 있는 곳
이 문서에 설명된 정보에 대해 자세히 알아보려면 다음 문서 및/또는 웹사이트를 검토하세요.
-
Amazon FSx ONTAP
-
아마존 EC2
-
NetApp 솔루션 자동화