

NetApp 및 MLflow를 통한 데이터 세트 대 모델 추적성
 변경 제안
변경 제안
를 "Kubernetes용 NetApp DataOps 툴킷" MLflow의 실험 추적 기능과 함께 사용하여 코드-데이터세트, 데이터 세트-모델 또는 작업 공간-모델 추적 기능을 구현할 수 있습니다.
예제 전자 필기장에는 다음 라이브러리가 사용되었습니다.
필수 구성 요소
코드 데이터 세트 모델 또는 작업 공간 대 모델 추적 기능을 구현하려면 다음 코드 조각에 표시된 것처럼 교육 실행의 일부로 DataOps Toolkit을 사용하여 데이터 세트 또는 작업 공간 볼륨의 스냅샷을 생성하기만 하면 됩니다. 이 코드는 데이터 볼륨 이름 및 스냅샷 이름을 MLflow Experiment Tracking Server에 로깅하는 특정 교육 실행과 관련된 태그로 저장합니다.
...
from netapp_dataops.k8s import cloneJupyterLab, createJupyterLab, deleteJupyterLab, \
listJupyterLabs, createJupyterLabSnapshot, listJupyterLabSnapshots, restoreJupyterLabSnapshot, \
cloneVolume, createVolume, deleteVolume, listVolumes, createVolumeSnapshot, \
deleteVolumeSnapshot, listVolumeSnapshots, restoreVolumeSnapshot
mlflow.set_tracking_uri("<your_tracking_server_uri>>:<port>>")
os.environ['MLFLOW_HTTP_REQUEST_TIMEOUT'] = '500' # Increase to 500 seconds
mlflow.set_experiment(experiment_id)
with mlflow.start_run() as run:
latest_run_id = run.info.run_id
start_time = datetime.now()
# Preprocess the data
preprocess(input_pdf_file_path, to_be_cleaned_input_file_path)
# Print out sensitive data (passwords, SECRET_TOKEN, API_KEY found)
check_pretrain(to_be_cleaned_input_file_path)
# Tokenize the input file
pretrain_tokenization(to_be_cleaned_input_file_path, model_name, tokenized_output_file_path)
# Load the tokenizer and model
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
# Set the pad token
tokenizer.pad_token = tokenizer.eos_token
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
# Encode, generate, and decode the text
with open(tokenized_output_file_path, 'r', encoding='utf-8') as file:
content = file.read()
encode_generate_decode(content, decoded_output_file_path, tokenizer=tokenizer, model=model)
# Save the model
model.save_pretrained(model_save_path)
tokenizer.save_pretrained(model_save_path)
# Finetuning here
with open(decoded_output_file_path, 'r', encoding='utf-8') as file:
content = file.read()
model.finetune(content, tokenizer=tokenizer, model=model)
# Evaluate the model using NLTK
output_set = Dataset.from_dict({"text": [content]})
test_set = Dataset.from_dict({"text": [content]})
scores = nltk_evaluation_gpt(output_set, test_set, model=model, tokenizer=tokenizer)
print(f"Scores: {scores}")
# End time and elapsed time
end_time = datetime.now()
elapsed_time = end_time - start_time
elapsed_minutes = elapsed_time.total_seconds() // 60
elapsed_seconds = elapsed_time.total_seconds() % 60
# Create DOTK snapshots for code, dataset, and model
snapshot = createVolumeSnapshot(pvcName="model-pvc", namespace="default", printOutput=True)
#Log snapshot IDs to MLflow
mlflow.log_param("code_snapshot_id", snapshot)
mlflow.log_param("dataset_snapshot_id", snapshot)
mlflow.log_param("model_snapshot_id", snapshot)
# Log parameters and metrics to MLflow
mlflow.log_param("wf_start_time", start_time)
mlflow.log_param("wf_end_time", end_time)
mlflow.log_param("wf_elapsed_time_minutes", elapsed_minutes)
mlflow.log_param("wf_elapsed_time_seconds", elapsed_seconds)
mlflow.log_artifact(decoded_output_file_path.rsplit('/', 1)[0]) # Remove the filename to log the directory
mlflow.log_artifact(model_save_path) # log the model save path
print(f"Experiment ID: {experiment_id}")
print(f"Run ID: {latest_run_id}")
print(f"Elapsed time: {elapsed_minutes} minutes and {elapsed_seconds} seconds")위의 코드 조각은 MLflow Experiment Tracking Server에 스냅샷 ID를 기록하며, 이 정보를 사용하여 모델을 훈련하는 데 사용된 특정 데이터세트 및 모델을 추적할 수 있습니다. 이렇게 하면 모델을 훈련하는 데 사용된 특정 데이터세트 및 모델뿐만 아니라 데이터를 사전 처리하고, 입력 파일을 토큰화하고, 토큰화 및 모델을 로드하고, 텍스트를 인코딩, 생성 및 디코딩하고, 모델을 저장하고"NLTK입니다", 모델을 세부 조정하고, 하이퍼플렉시 점수를 사용하여 모델을 평가하고, 하이퍼플로우 메트릭을 기록하는 데 사용된 특정 코드를 다시 추적할 수 있습니다. 예를 들어, 다음 그림은 다양한 실험 실행에 대한 Scikit-Learn 모델의 MSE(Mean-Squared Error)를 보여줍니다.

데이터 분석, 사업부 소유자 및 경영진은 특정 제약 조건, 설정, 기간 및 기타 상황에서 가장 적합한 모델을 이해하고 유추할 수 있습니다. 모델을 전처리, 토큰화, 로드, 인코딩, 생성, 디코딩, 저장, 세부 조정 및 평가하는 방법에 대한 자세한 내용은 dotk-mlflow netapp_dataops.k8s 리포지토리의 패키지 Python 예제를 참조하십시오.
데이터 세트 또는 JupyterLab 작업 공간의 스냅샷을 생성하는 방법에 대한 자세한 내용은 를 "NetApp DataOps 툴킷 페이지 를 참조하십시오"참조하십시오.
훈련된 모델과 관련하여 dotk-mlflow 노트북에는 다음 모델이 사용되었습니다.
모델
-
"GPT2LMHeadModel를 참조하십시오": 언어 모델링 헤드 상단에 GPT2 모델 변압기 (입력 임베딩에 가중치가 묶인 선형 레이어). 이 트랜스포머 모델은 대량의 텍스트 데이터에 대해 사전 교육을 받고 특정 데이터 세트에서 Finetuned를 거친 트랜스포머 모델입니다. 기본 GPT2 모델을 사용하여 "주의 마스크"선택한 모델에 해당하는 토큰화를 사용하여 입력 시퀀스를 일괄 처리했습니다.
-
"파이-2": Phi-2는 27억 개의 매개 변수를 가진 변압기입니다. Phi-1.5와 동일한 데이터 소스를 사용하여 훈련되었으며, 다양한 NLP 합성 텍스트와 필터링된 웹 사이트로 구성된 새로운 데이터 소스가 보강되었습니다(안전 및 교육 가치).
-
"XLNet(기반 크기 모델)": XLNet 모델은 영어로 사전 교육을 받았습니다. 그것은 "XLNet: 언어 이해를 위한 일반화된 자동 회귀 사전 교육"양에 의해 신문에 소개되었다. 그리고 처음으로 릴리스이"리포지토리".
결과에는 "MLflow의 모델 레지스트리"다음과 같은 임의 포리스트 모델, 버전 및 태그가 포함됩니다.
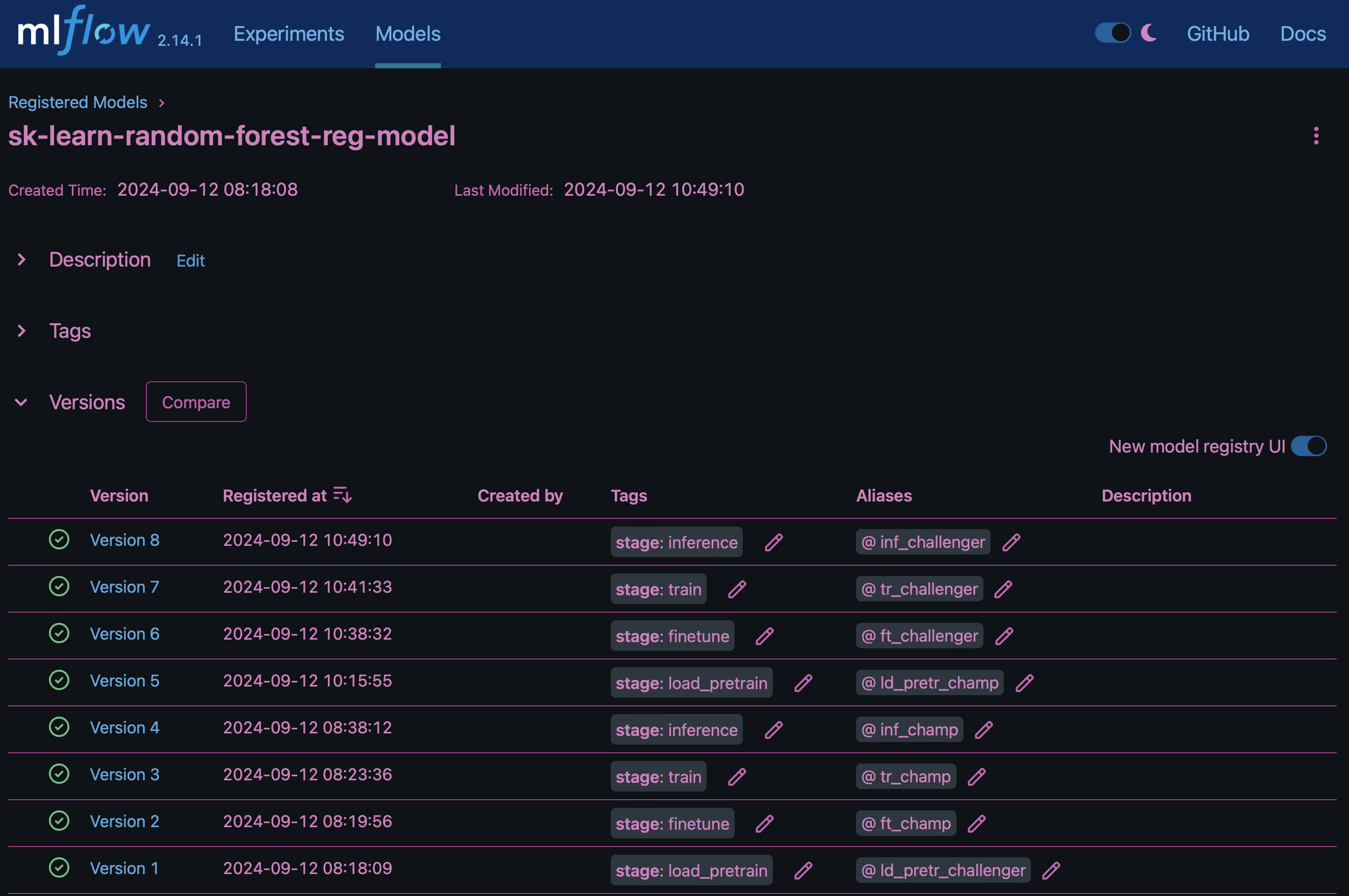
Kubernetes를 통해 모델을 추론 서버에 배포하려면 다음 Jupyter Notebook을 실행합니다. 이 예제에서는 dotk-mlflow 패키지를 사용하는 대신 임의의 포리스트 회귀 모델 아키텍처를 수정하여 초기 모델에서 MSE(Mean-Squared Error)를 최소화함으로써 모델 레지스트리에서 이러한 모델의 여러 버전을 만듭니다.
from mlflow.models import Model
mlflow.set_tracking_uri("http://<tracking_server_URI_with_port>")
experiment_id='<your_specified_exp_id>'
# Alternatively, you can load the Model object from a local MLmodel file
# model1 = Model.load("~/path/to/my/MLmodel")
from sklearn.datasets import make_regression
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
import mlflow
import mlflow.sklearn
from mlflow.models import infer_signature
# Create a new experiment and get its ID
experiment_id = mlflow.create_experiment(experiment_id)
# Or fetch the ID of the existing experiment
# experiment_id = mlflow.get_experiment_by_name("<your_specified_exp_id>").experiment_id
with mlflow.start_run(experiment_id=experiment_id) as run:
X, y = make_regression(n_features=4, n_informative=2, random_state=0, shuffle=False)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
params = {"max_depth": 2, "random_state": 42}
model = RandomForestRegressor(**params)
model.fit(X_train, y_train)
# Infer the model signature
y_pred = model.predict(X_test)
signature = infer_signature(X_test, y_pred)
# Log parameters and metrics using the MLflow APIs
mlflow.log_params(params)
mlflow.log_metrics({"mse": mean_squared_error(y_test, y_pred)})
# Log the sklearn model and register as version 1
mlflow.sklearn.log_model(
sk_model=model,
artifact_path="sklearn-model",
signature=signature,
registered_model_name="sk-learn-random-forest-reg-model",
)Jupyter Notebook 셀의 실행 결과는 다음과 비슷해야 하며, 3 모델 레지스트리에 모델이 버전으로 등록됩니다.
Registered model 'sk-learn-random-forest-reg-model' already exists. Creating a new version of this model... 2024/09/12 15:23:36 INFO mlflow.store.model_registry.abstract_store: Waiting up to 300 seconds for model version to finish creation. Model name: sk-learn-random-forest-reg-model, version 3 Created version '3' of model 'sk-learn-random-forest-reg-model'.
모델 레지스트리에서 원하는 모델, 버전 및 태그를 저장한 후, 모델을 훈련하는 데 사용된 특정 데이터 세트, 모델 및 코드뿐만 아니라 데이터 처리에 사용된 특정 코드를 다시 추적할 수 있습니다 snapshot_id's and your chosen metrics to MLflow by choosing the corerct experiment under `mlrun.
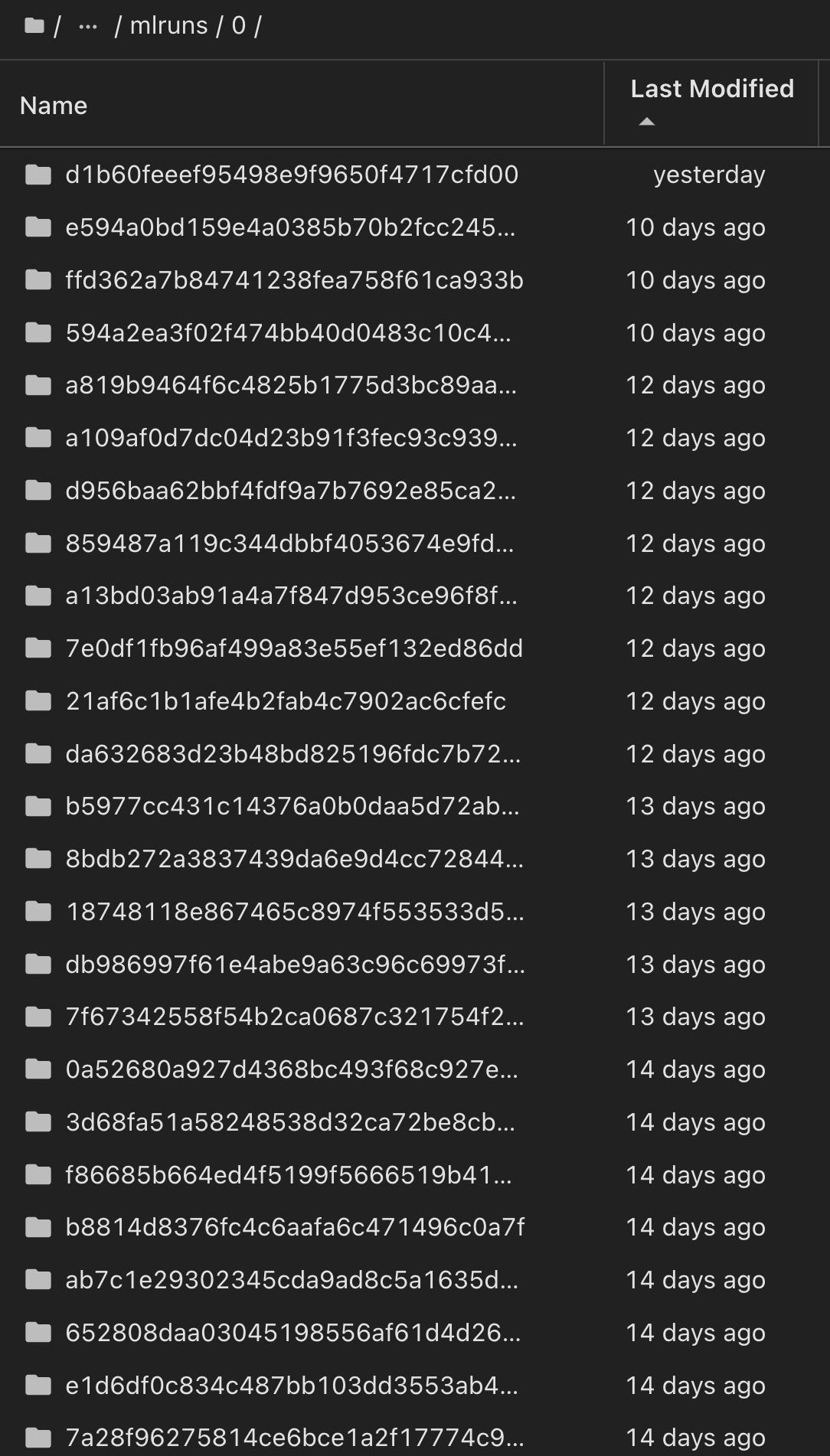
마찬가지로, phi-2_finetuned_model torch 라이브러리를 사용하여 GPU 또는 vGPU를 통해 정량화된 가중치를 계산한 당사의 경우, 다음과 같은 중간 아티팩트를 검사하여 성능 최적화, 확장성(처리량/SLA 가어런티) 및 전체 워크플로의 비용 절감을 실현할 수 있습니다.
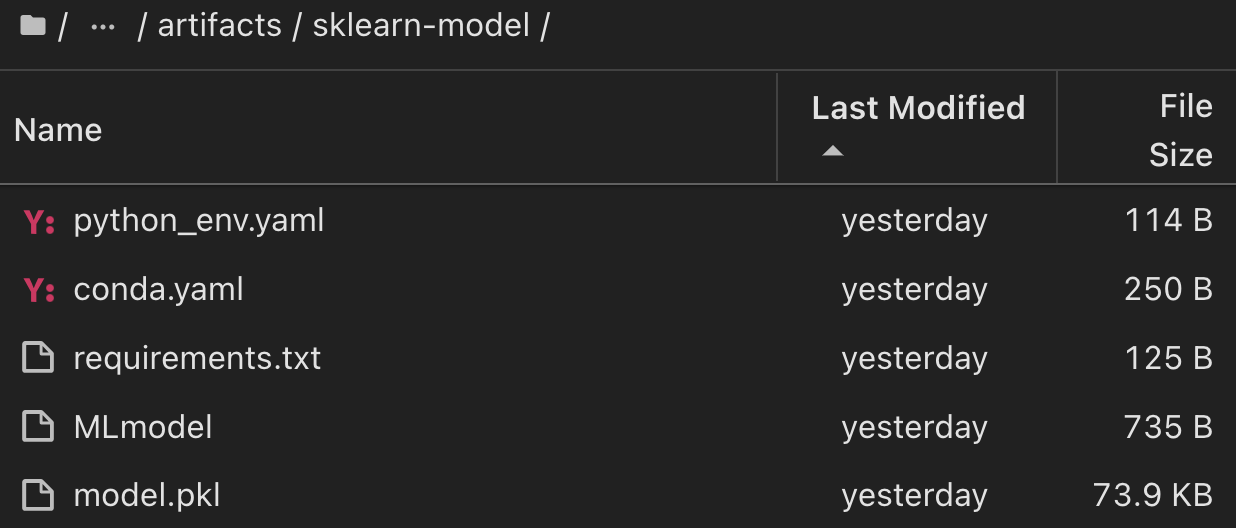
Scikit-Learn 및 MLflow를 사용한 단일 실험 실행의 경우 다음 그림은 생성된 인공물, conda 환경, MLmodel 파일 및 MLmodel 디렉토리를 보여줍니다.
고객은 태그(예: "기본", "단계", "프로세스", "병목 현상" contributors)를 지정하여 AI 워크플로 실행의 다양한 특성을 구성하거나, 최신 결과를 기록하거나, 데이터 과학팀 개발자의 진행 상황을 추적하도록 설정할 수 있습니다. 기본 태그 ""의 경우, 저장 mlflow.log-model.history, mlflow.runName, mlflow.source.type mlflow.source.name 및 mlflow.user JupyterHub 현재 활성 파일 탐색기 탭 아래에서:
마지막으로 사용자는 고유의 지정된 Jupyter Workspace를 갖게 되며, 이 Workspace는 Kubernetes 클러스터의 PVC(영구 볼륨 클레임)에 버전 관리되고 저장됩니다. 다음 그림에서는 netapp_dataops.k8s Python 패키지가 포함된 Jupyter Workspace와 성공적으로 생성된 의 결과를 보여 VolumeSnapshot 줍니다.
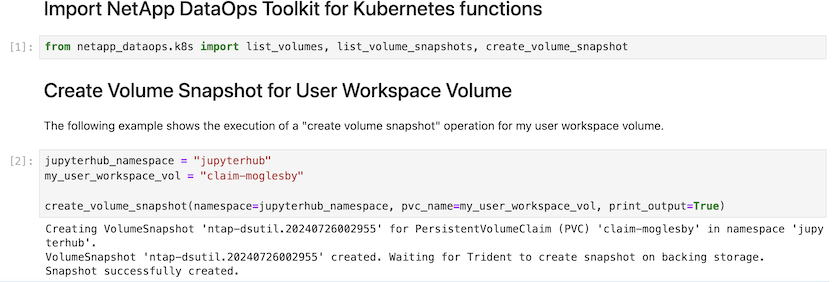
업계에서 검증된 NetApp의 Snapshot ® 및 기타 기술을 사용하여 엔터프라이즈급 데이터 보호, 이동, 효율적인 압축을 보장했습니다. 다른 AI 사용 사례는 "NetApp AIPod"문서 를 참조하십시오.