
지능형 계층화 및 비용 절감
 변경 제안
변경 제안
고객은 Splunk 데이터 분석을 더욱 쉽고 원활하게 사용할 수 있다는 것을 알게 되므로 당연히 계속해서 증가하는 데이터를 인덱싱하기를 원합니다. 데이터의 양이 증가할수록 서비스를 제공하는 데 필요한 컴퓨팅 및 스토리지 인프라도 증가합니다. 오래된 데이터를 자주 참조하지 않기 때문에 동일한 양의 컴퓨팅 리소스를 커밋하고 값비싼 기본 스토리지를 사용하는 것은 점점 비효율적입니다. 고객은 규모에 맞게 운영하는 데 필요한 데이터를 보다 비용 효율적인 계층으로 이동하여 사용 빈도가 높은 데이터를 위한 컴퓨팅과 운영 스토리지를 확보함으로써 이점을 누릴 수 있습니다.
StorageGRID를 포함한 Splunk SmartStore는 확장 가능하고 성능 기준에 부합하는 비용 효율적인 솔루션을 제공합니다. SmartStore는 데이터를 인식하기 때문에 데이터 액세스 패턴을 자동으로 평가하여 실시간 분석(핫 데이터)을 위해 액세스해야 하는 데이터와 저렴한 장기 스토리지(웜 데이터)에 상주해야 하는 데이터를 결정합니다. SmartStore는 업계 표준인 AWS S3 API를 동적으로 지능적으로 사용하여 StorageGRID에서 제공하는 S3 스토리지에 데이터를 배치합니다. StorageGRID의 유연한 스케일아웃 아키텍처를 사용하면 웜 데이터 계층을 필요에 따라 비용 효율적으로 확장할 수 있습니다. StorageGRID의 노드 기반 아키텍처는 성능 및 비용 요구사항을 최적의 상태로 충족합니다.
다음 그림은 Splunk 및 StorageGRID 계층화를 보여줍니다.
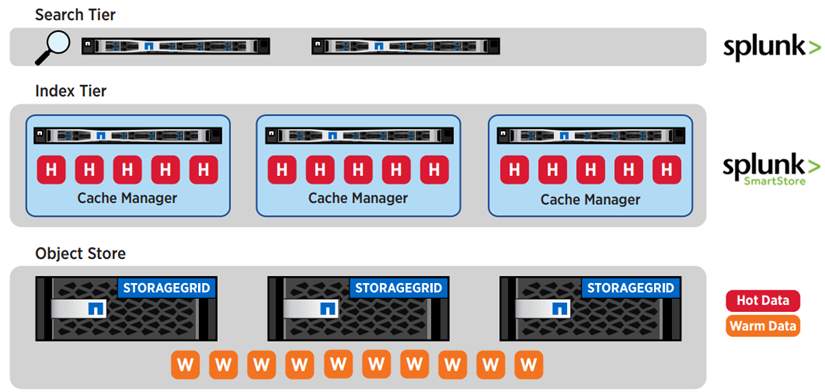
업계 최고 수준의 Splunk SmartStore와 NetApp StorageGRID를 결합하여 전체 스택 솔루션을 통해 분리 아키텍처의 이점을 제공합니다.