MetroCluster가 있는 vMSC의 실패 시나리오
 변경 제안
변경 제안
다음 섹션에서는 vMSC 및 NetApp MetroCluster 시스템의 다양한 장애 시나리오에서 예상되는 결과를 간략하게 설명합니다.
단일 스토리지 경로 오류
이 시나리오에서 HBA 포트, 네트워크 포트, 프런트엔드 데이터 스위치 포트 또는 FC 또는 이더넷 케이블과 같은 구성 요소에 장애가 발생하면 ESXi 호스트에서 스토리지 디바이스에 대한 특정 경로가 비활성 상태로 표시됩니다. HBA/네트워크/스위치 포트에서 복원력을 제공하여 스토리지 디바이스에 여러 경로를 구성한 경우 ESXi는 경로 전환을 수행하는 것이 가장 좋습니다. 이 기간 동안 스토리지 디바이스에 다중 경로를 제공하여 스토리지 가용성이 관리되기 때문에 가상 머신은 영향을 받지 않고 계속 실행됩니다.

|
이 시나리오에서는 MetroCluster 동작에 변화가 없으며 모든 데이터 저장소가 해당 사이트에서 그대로 유지됩니다. |
모범 사례
NFS/iSCSI 볼륨이 사용되는 환경에서는 NetApp 표준 vSwitch의 NFS vmkernel 포트에 대해 두 개 이상의 네트워크 업링크를 구성하고 분산형 vSwitch에 대해 NFS vmkernel 인터페이스가 매핑된 포트 그룹에서 동일한 네트워크 업링크를 구성하는 것이 좋습니다. NIC 티밍은 Active-Active 또는 Active-Standby 중 하나로 구성할 수 있습니다.
또한 iSCSI LUN의 경우 vmkernel 인터페이스를 iSCSI 네트워크 어댑터에 바인딩하여 다중 경로를 구성해야 합니다. 자세한 내용은 vSphere 스토리지 설명서를 참조하십시오.
모범 사례
Fibre Channel LUN이 사용되는 환경에서는 NetApp HBA/포트 레벨에서 복원력을 보장하는 HBA를 2개 이상 사용하는 것이 좋습니다. 또한 NetApp은 조닝을 구성하는 모범 사례로서 단일 이니시에이터에 단일 타겟 조닝으로 권장합니다.
모든 신규 및 기존 NetApp 스토리지 장치에 대한 정책을 설정하므로 VSC(가상 스토리지 콘솔)를 사용하여 다중 경로 정책을 설정해야 합니다.
단일 ESXi 호스트 장애
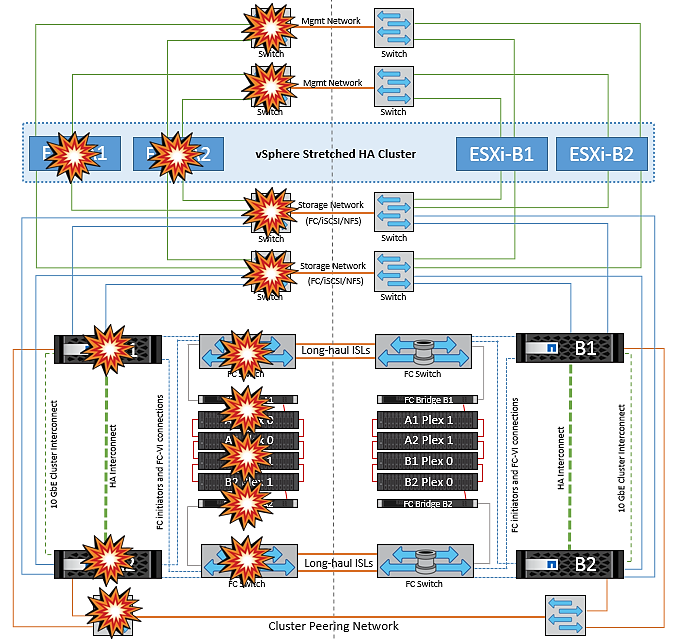
이 시나리오에서는 ESXi 호스트 장애가 있는 경우 VMware HA 클러스터의 마스터 노드가 더 이상 네트워크 하트비트를 수신하지 않기 때문에 호스트 장애를 감지합니다. 호스트가 실제로 다운되었는지 아니면 네트워크 파티션만 발생하는지 확인하기 위해 마스터 노드는 데이터 저장소 하트비트를 모니터링하고, 이 하트비트가 없는 경우 장애가 발생한 호스트의 관리 IP 주소를 ping하여 최종 점검을 수행합니다. 이러한 검사가 모두 음수이면 마스터 노드가 이 호스트에 장애가 발생한 호스트를 선언하고 장애가 발생한 이 호스트에서 실행 중이던 모든 가상 머신이 클러스터의 나머지 호스트에서 재부팅됩니다.
DRS VM 및 호스트 선호도 규칙이 구성된 경우(VM 그룹 SiteA_VM의 VM은 호스트 그룹 SiteA_hosts에서 호스트를 실행해야 함), HA 마스터는 먼저 사이트 A에서 사용 가능한 리소스를 확인합니다 사이트 A에 사용 가능한 호스트가 없는 경우 마스터가 사이트 B의 호스트에서 VM을 다시 시작하려고 시도합니다
로컬 사이트에 리소스 제한이 있는 경우 다른 사이트의 ESXi 호스트에서 가상 머신을 시작할 수 있습니다. 그러나 가상 머신을 로컬 사이트의 정상적인 ESXi 호스트로 다시 마이그레이션하여 규칙을 위반하는 경우 정의된 DRS VM 및 호스트 선호도 규칙이 수정됩니다. DRS가 수동으로 설정된 경우 NetApp는 DRS를 호출하고 권장 사항을 적용하여 가상 머신 배치를 수정하는 것이 좋습니다.
이 시나리오에서는 MetroCluster 동작에 변화가 없으며 모든 데이터 저장소가 해당 사이트에서 그대로 유지됩니다.
ESXi 호스트 격리
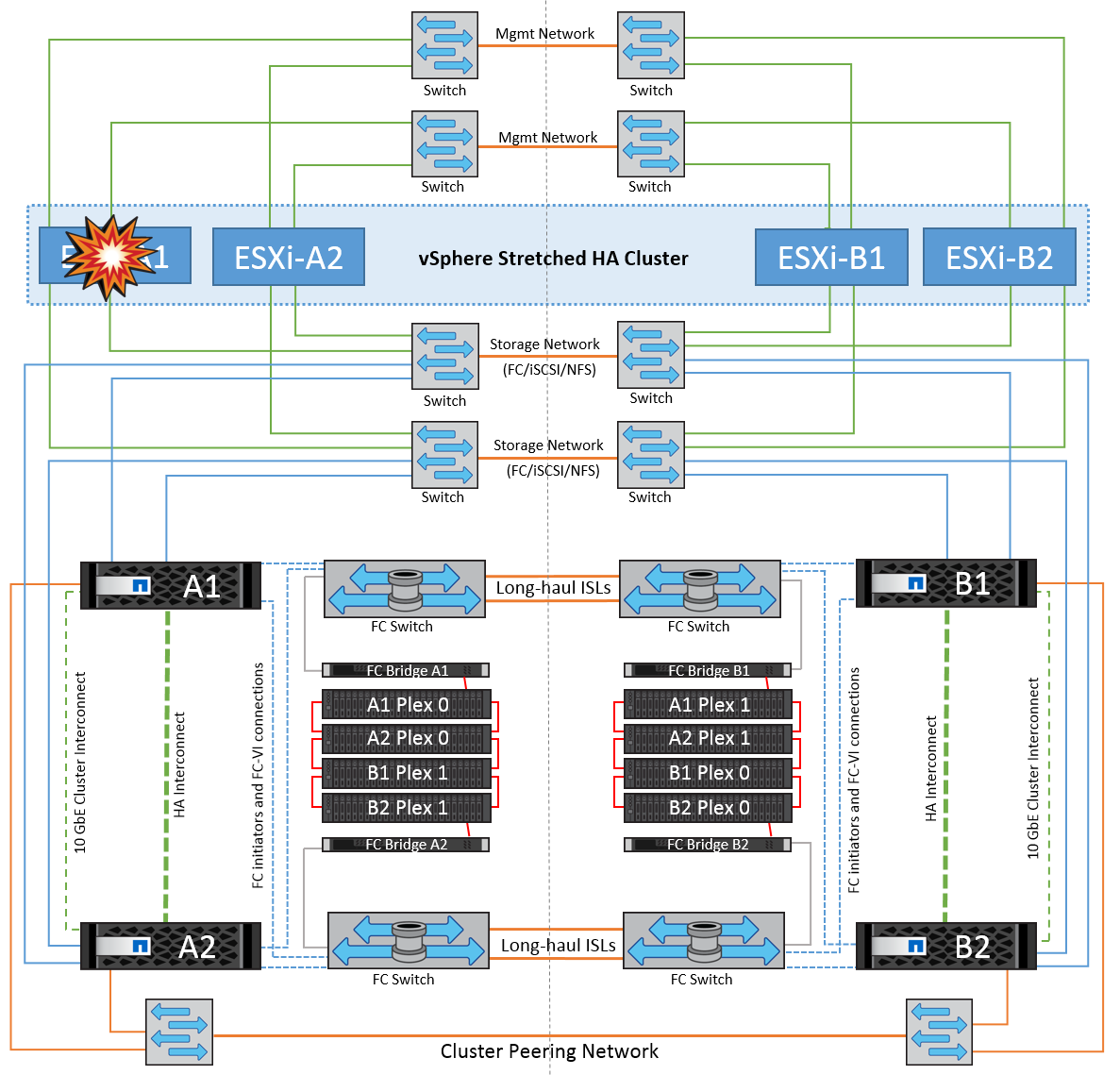
이 시나리오에서는 ESXi 호스트의 관리 네트워크가 다운된 경우 HA 클러스터의 마스터 노드가 하트비트를 수신하지 않으므로 이 호스트가 네트워크에서 격리됩니다. 마스터 노드가 데이터 저장소 하트비트를 모니터링하기 시작합니다. 호스트가 있는 경우 마스터 노드에 의해 격리된 것으로 선언됩니다. 구성된 격리 응답에 따라 호스트는 전원을 끄거나, 가상 시스템을 종료하거나, 가상 시스템의 전원을 계속 켜도록 선택할 수 있습니다. 격리 응답의 기본 간격은 30초입니다.
이 시나리오에서는 MetroCluster 동작에 변화가 없으며 모든 데이터 저장소가 해당 사이트에서 그대로 유지됩니다.
디스크 쉘프 오류입니다
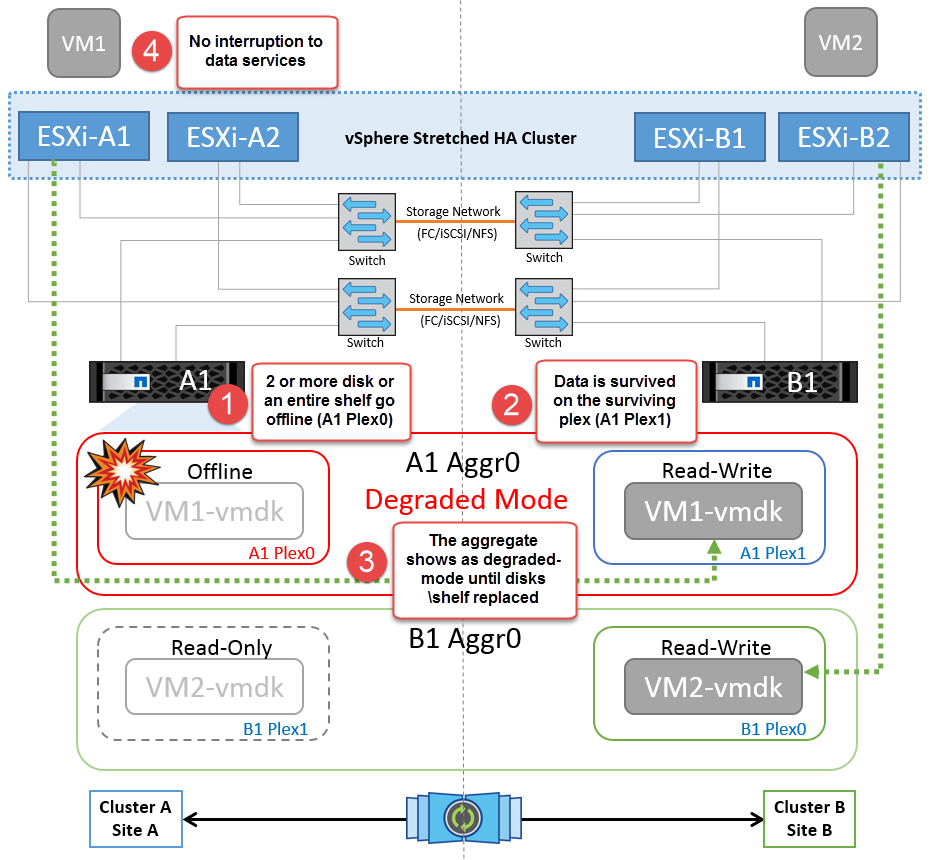
이 시나리오에서는 두 개 이상의 디스크에서 장애가 발생하거나 전체 쉘프에 장애가 발생합니다. 작동하는 플렉스에서 데이터 서비스를 중단하지 않고 데이터를 제공합니다. 디스크 장애가 로컬 또는 원격 플렉스에 영향을 줄 수 있습니다. 하나의 플렉스만 활성 상태이므로 애그리게이트가 성능 저하 모드로 표시됩니다. 장애가 발생한 디스크를 교체하면 영향을 받는 애그리게이트가 자동으로 다시 동기화되어 데이터를 재구축합니다. 다시 동기화하면 애그리게이트가 정상 미러링된 모드로 자동으로 돌아갑니다. 단일 RAID 그룹 내에서 두 개 이상의 디스크에 장애가 발생한 경우 플렉스를 재구축해야 합니다.
-
[참고]
-
이 기간 동안에는 가상 머신 입출력 작업에 영향을 주지 않지만 ISL 링크를 통해 원격 디스크 셸프에서 데이터에 액세스하므로 성능이 저하됩니다.
단일 스토리지 컨트롤러 장애
이 시나리오에서는 두 스토리지 컨트롤러 중 하나가 한 사이트에서 장애가 발생합니다. 각 사이트에 HA 쌍이 있으므로 한 노드에 장애가 발생하면 운영에 영향을 미치지 않고 다른 노드에 대한 페일오버가 자동으로 트리거됩니다. 예를 들어 노드 A1에 장애가 발생하면 해당 스토리지 및 워크로드가 자동으로 노드 A2로 전송됩니다. 모든 플렉스를 사용할 수 있으므로 가상 머신은 영향을 받지 않습니다. 두 번째 사이트 노드(B1 및 B2)는 영향을 받지 않습니다. 또한 클러스터의 마스터 노드가 네트워크 하트비트를 계속 수신하므로 vSphere HA는 아무 작업도 수행하지 않습니다.
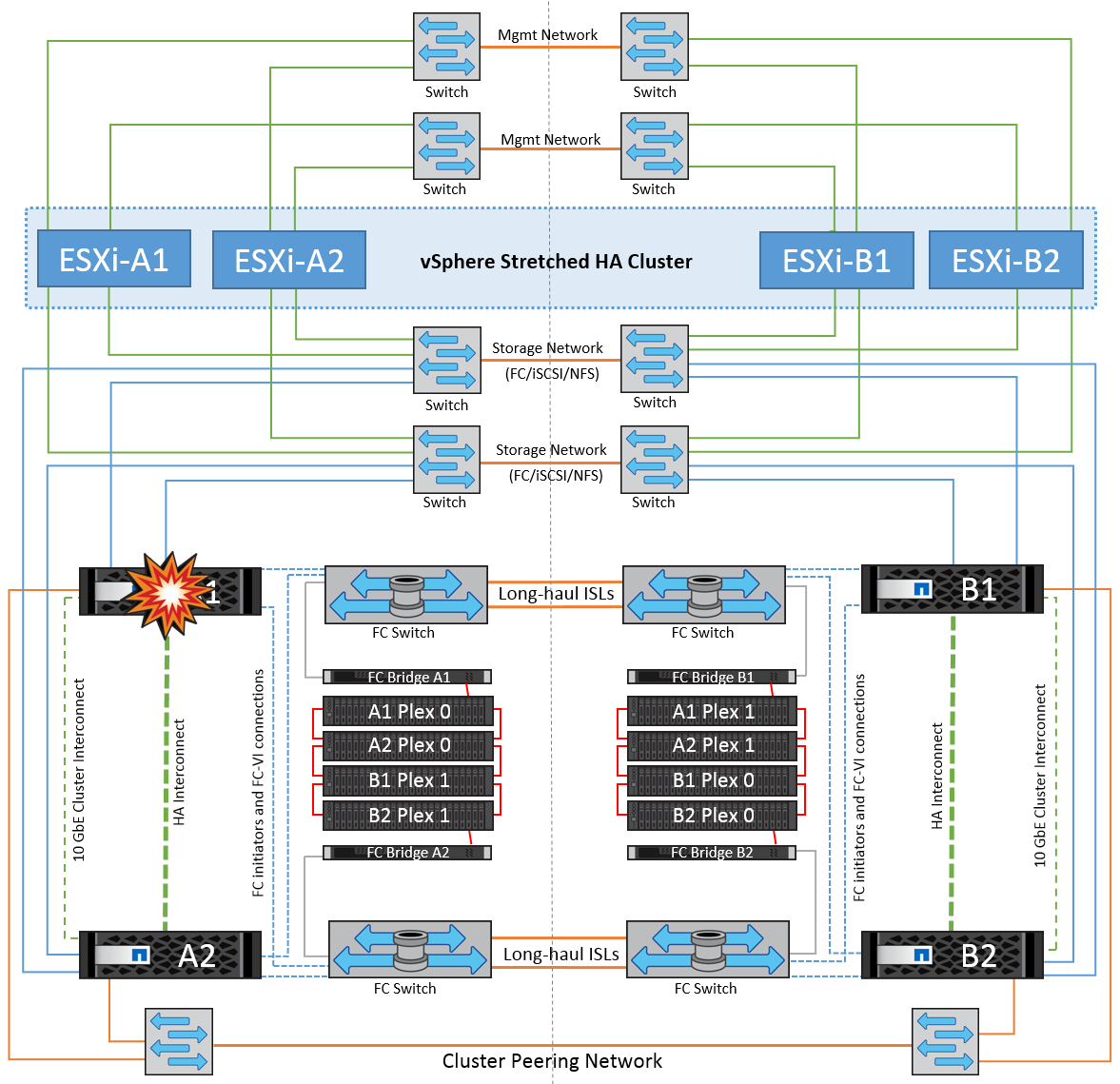
장애 조치가 롤링 재해의 일부인 경우(노드 A1이 A2로 장애 조치), A2의 후속 장애 또는 사이트 A의 전체 장애가 발생한 경우 사이트 B에서 재해가 발생한 후 전환이 발생할 수 있습니다
인터스위치 링크 오류
관리 네트워크에서 스위치 간 링크 오류
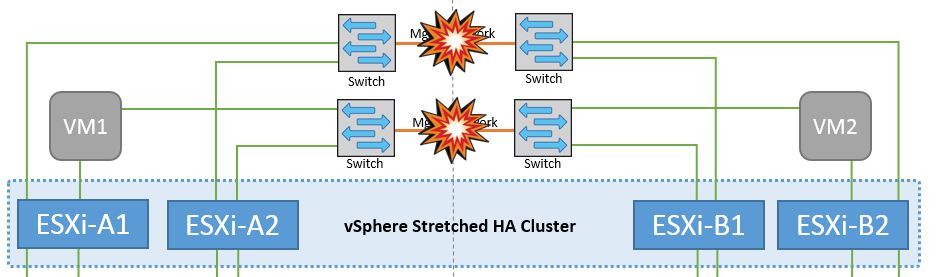
이 시나리오에서 프런트엔드 호스트 관리 네트워크의 ISL 링크에 장애가 발생하면 사이트 A의 ESXi 호스트가 사이트 B의 ESXi 호스트와 통신할 수 없습니다 특정 사이트의 ESXi 호스트는 네트워크 하트비트를 HA 클러스터의 마스터 노드로 보낼 수 없기 때문에 이로 인해 네트워크 파티션이 발생합니다. 따라서 파티션으로 인해 두 개의 네트워크 세그먼트가 있으며 각 세그먼트에는 특정 사이트 내의 호스트 장애로부터 VM을 보호하는 마스터 노드가 있습니다.
|
|
이 기간 동안 가상 머신은 실행 중인 상태로 유지되며 이 시나리오에서는 MetroCluster 동작이 변경되지 않습니다. 모든 데이터 저장소는 해당 사이트에서 그대로 유지됩니다. |
스토리지 네트워크에서 스위치 간 링크 오류
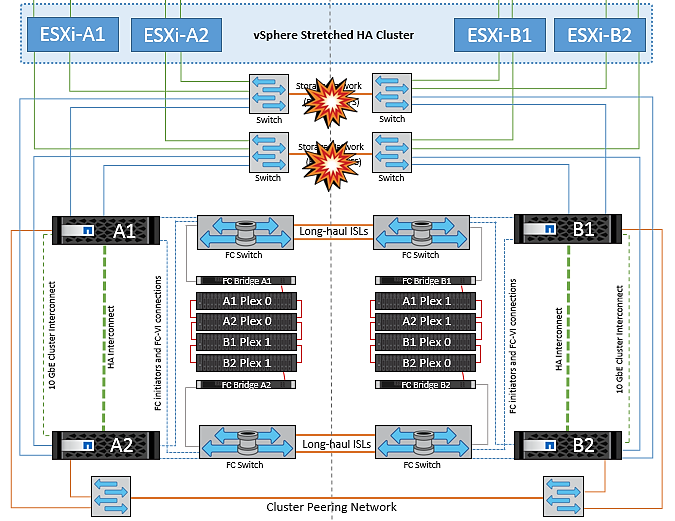
이 시나리오에서는 백엔드 스토리지 네트워크의 ISL 링크에 장애가 발생하면 사이트 A의 호스트가 사이트 B의 클러스터 B의 스토리지 볼륨 또는 LUN에 액세스할 수 없게 되며, 그 반대의 경우도 마찬가지입니다. VMware DRS 규칙은 호스트-스토리지 사이트 선호도를 통해 사이트 내에서 아무런 영향을 받지 않고 가상 시스템을 실행할 수 있도록 정의됩니다.
이 기간 동안 가상 머신은 해당 사이트에서 계속 실행되고 있으며 이 시나리오에서는 MetroCluster 동작이 변경되지 않습니다. 모든 데이터 저장소는 해당 사이트에서 그대로 유지됩니다.
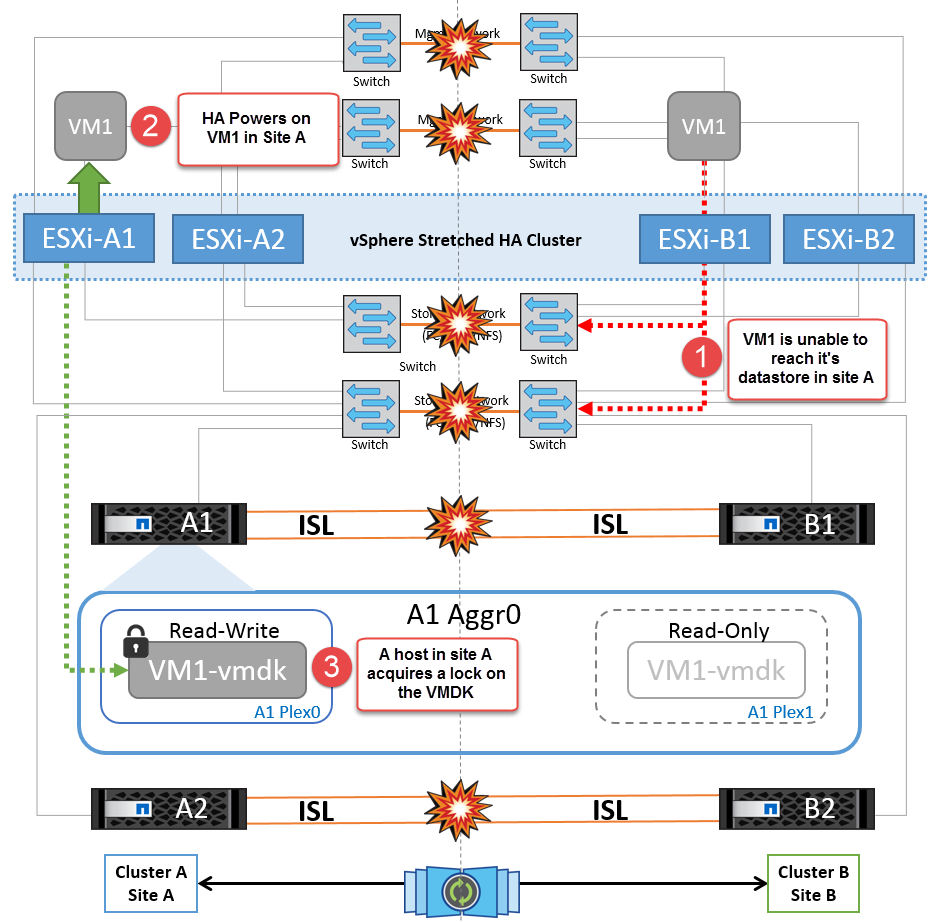
어떤 이유로 선호도 규칙을 위반하는 경우(예: 디스크가 로컬 클러스터 A 노드에 있는 사이트 A에서 실행되어야 하는 VM1이 사이트 B의 호스트에서 실행), 가상 머신의 디스크는 ISL 링크를 통해 원격으로 액세스됩니다. ISL 링크 장애로 인해 사이트 B에서 실행되는 VM1은 스토리지 볼륨에 대한 경로가 다운되고 특정 가상 시스템이 다운되기 때문에 해당 디스크에 쓸 수 없습니다. 이러한 경우 VMware HA는 호스트가 심박동을 능동적으로 전송하기 때문에 아무 작업도 수행하지 않습니다. 이러한 가상 머신의 전원을 수동으로 끄고 해당 사이트에서 전원을 켜야 합니다. 다음 그림에서는 DRS 선호도 규칙을 위반하는 VM을 보여 줍니다.
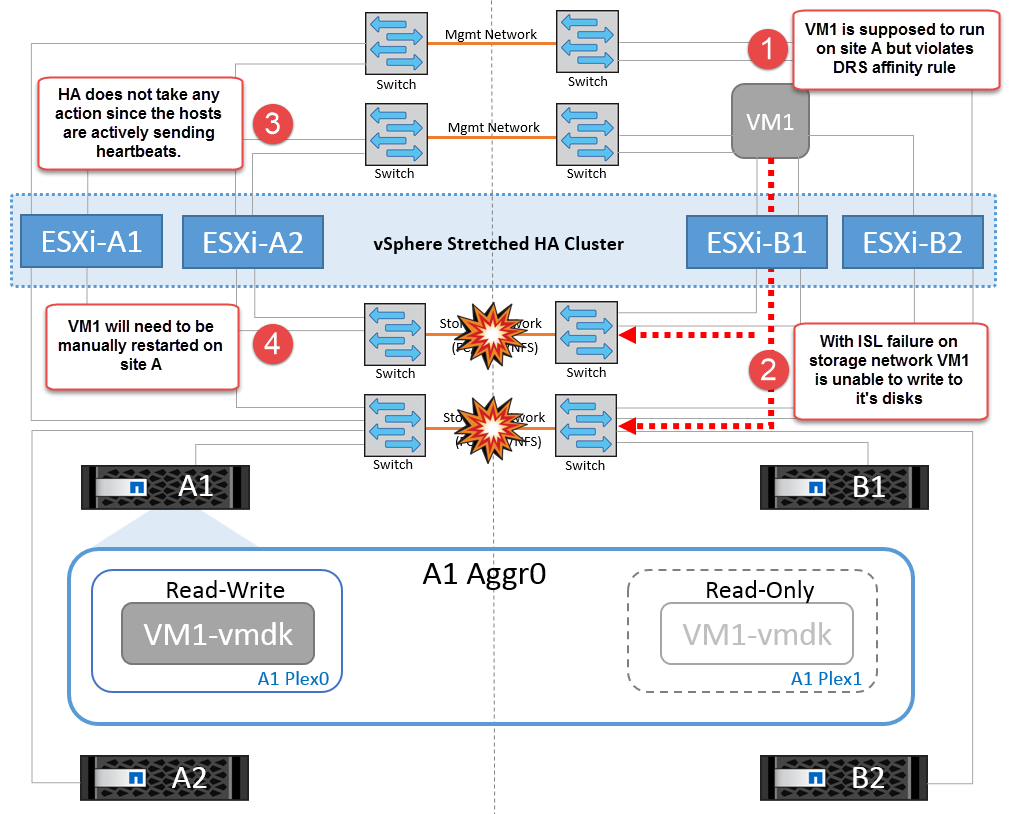
모든 인터스위치 오류 또는 전체 데이터 센터 파티션
이 시나리오에서는 사이트 간의 모든 ISL 링크가 다운되고 두 사이트가 서로 격리됩니다. 관리 네트워크 및 스토리지 네트워크에서 ISL 장애와 같은 이전 시나리오에서 설명한 것처럼 가상 머신은 완전한 ISL 장애에도 영향을 받지 않습니다.
ESXi 호스트가 사이트 간에 분할된 후 vSphere HA 에이전트는 데이터 저장소 하트비트를 확인하고 각 사이트에서 로컬 ESXi 호스트는 데이터 저장소 하트비트를 해당 읽기/쓰기 볼륨/LUN으로 업데이트할 수 있습니다. 사이트 A의 호스트는 네트워크/데이터 저장소 하트비트가 없기 때문에 사이트 B의 다른 ESXi 호스트에 장애가 발생한 것으로 가정합니다. 사이트 A의 vSphere HA는 사이트 B의 가상 머신을 재시작합니다. 그러면 스토리지 ISL 장애로 인해 사이트 B의 데이터 저장소에 액세스할 수 없기 때문에 결국 실패합니다. 비슷한 상황이 사이트 B에서 반복됩니다
NetApp에서는 가상 시스템이 DRS 규칙을 위반했는지 여부를 확인하는 것이 좋습니다. 원격 사이트에서 실행되는 모든 가상 머신은 데이터 저장소에 액세스할 수 없으므로 작동이 중지되고 vSphere HA는 로컬 사이트에서 해당 가상 머신을 다시 시작합니다. ISL 링크가 다시 온라인 상태가 되면 동일한 MAC 주소로 실행되는 가상 시스템의 인스턴스가 두 개 있을 수 없으므로 원격 사이트에서 실행 중이던 가상 시스템이 종료됩니다.
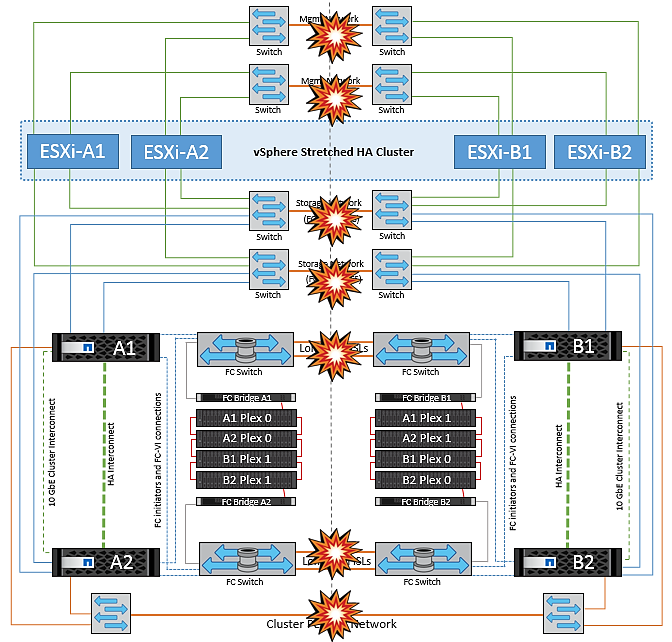
NetApp MetroCluster의 두 Fabric에서 스위치 간 링크 장애가 발생했습니다
하나 이상의 ISL이 실패하는 경우 트래픽은 나머지 링크를 통해 계속됩니다. 두 Fabric의 모든 ISL에 장애가 발생하여 스토리지와 NVRAM 복제를 위해 사이트 간에 링크가 없는 경우, 각 컨트롤러는 계속해서 로컬 데이터를 제공합니다. 최소 하나의 ISL이 복구되면 모든 플렉스의 재동기화가 자동으로 수행됩니다.
모든 ISL이 다운된 후에 발생하는 모든 쓰기는 다른 사이트로 미러링되지 않습니다. 따라서 구성이 이 상태일 때 재해 발생 시 전환이 이루어지면 동기화되지 않은 데이터가 손실됩니다. 이 경우 전환 후 복구를 위해 수동 개입이 필요합니다. 장기간 사용할 수 있는 ISL이 없을 경우 관리자는 모든 데이터 서비스를 종료하여 재해 발생 시 전환이 필요할 경우 데이터 손실 위험을 피할 수 있습니다. 이 작업을 수행하는 것은 하나 이상의 ISL을 사용할 수 있게 되기 전에 전환이 필요한 재해의 가능성과 비교해야 합니다. 또는 다중 구간 시나리오에서 ISL이 실패하는 경우 관리자가 모든 링크에 장애가 발생하기 전에 사이트 중 하나로 계획된 전환을 트리거할 수 있습니다.
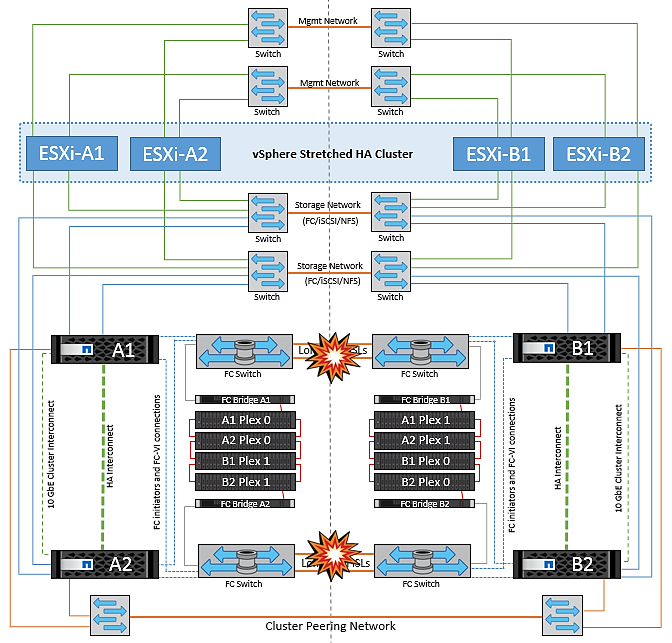
피어링된 클러스터 링크 장애
피어링된 클러스터 링크 장애 시나리오에서 패브릭 ISL은 여전히 활성 상태이므로 두 사이트에서 데이터 서비스(읽기 및 쓰기)가 두 플렉스에 계속 적용됩니다. 클러스터 구성 변경(예: 새 SVM 추가, 기존 SVM에서 볼륨 또는 LUN 프로비저닝)은 다른 사이트에 전파될 수 없습니다. 이러한 데이터는 로컬 CRS 메타데이터 볼륨에 보관되며 피어링된 클러스터 링크가 복구되면 자동으로 다른 클러스터로 전파됩니다. 피어링된 클러스터 링크를 복원하기 전에 강제 전환이 필요한 경우 전환 프로세스의 일부로 남아 있는 사이트에 있는 메타데이터 볼륨의 원격 복제 복사본에서 미결 클러스터 구성 변경 사항이 자동으로 재생됩니다.
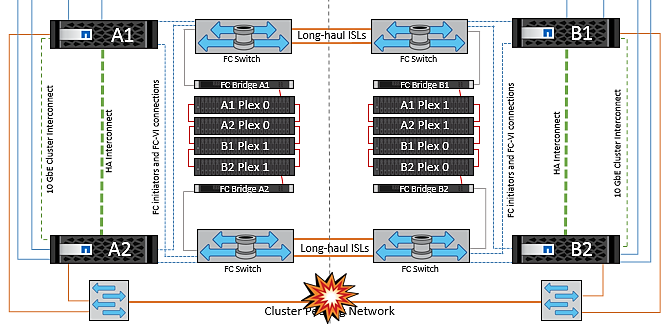
전체 사이트 오류입니다
전체 사이트 A 장애 시나리오에서 사이트 B에 있는 ESXi 호스트는 사이트 A의 ESXi 호스트에서 다운되었기 때문에 네트워크 하트비트를 가져오지 않습니다. 사이트 B의 HA 마스터는 데이터 저장소 하트비트가 없는지 확인하고, 사이트 A의 호스트가 실패하도록 선언한 다음 사이트 B의 가상 머신을 재시작합니다 이 기간 동안 스토리지 관리자는 스위치오버를 수행하여 장애가 발생한 사이트의 노드 서비스를 재개하고 사이트 B에 있는 사이트 A의 모든 스토리지 서비스를 복구합니다 사이트 B에서 사이트 A 볼륨 또는 LUN을 사용할 수 있게 되면 HA 마스터 에이전트가 사이트 B에서 사이트 A 가상 머신을 재시작합니다
vSphere HA 마스터 에이전트의 VM 재시작 시도(등록 및 전원 켜기 포함)가 실패하면 지연 후 재시작됩니다. 다시 시작 사이의 지연은 최대 30분까지 구성할 수 있습니다. vSphere HA는 최대 시도 횟수(기본적으로 6회 시도)에 대해 이러한 재시작을 시도합니다.
|
|
HA 마스터는 배치 관리자가 적합한 스토리지를 찾을 때까지 재시작 시도를 시작하지 않으므로, 전체 사이트 장애가 발생한 경우 전환이 수행된 후에 다시 시작합니다. |
사이트 A가 페일오버된 경우 정상 사이트 B 노드 중 하나의 후속 장애 조치를 통해 정상적인 노드로 원활하게 처리할 수 있습니다. 이 경우 4개 노드의 작업은 현재 하나의 노드에서만 수행됩니다. 이 경우 복구는 로컬 노드로의 반환 수행으로 구성됩니다. 그런 다음 사이트 A가 복구되면 구성의 안정적 상태 작업을 복원하기 위한 스위치백 작업이 수행됩니다.