

캐싱 모듈 FAS8200을 교체하십시오
 변경 제안
변경 제안
시스템에서 모듈이 오프라인으로 전환되었다는 단일 AutoSupport(ASUP) 메시지를 등록하는 경우 컨트롤러 모듈에서 캐싱 모듈을 교체해야 하며, 그렇게 하지 않으면 성능이 저하됩니다.
캐시 모듈을 교체하기 전에 캐시 모듈의 내용을 지울 수 있습니다.
-
캐싱 모듈의 데이터가 암호화되지만 손상된 캐싱 모듈에서 데이터를 모두 지우고 캐싱 모듈에 데이터가 없는지 확인해야 할 수 있습니다.
-
캐싱 모듈의 데이터를 지웁니다.
system controller flash-cache secure-erase run -node node name localhost -device-id device_number
`system controller flash-cache show`Flash Cache 디바이스 ID를 모르는 경우 명령을 실행합니다. -
캐싱 모듈에서 데이터가 삭제되었는지 확인합니다.
system controller flash-cache secure-erase show
-
-
오류가 발생한 구성 요소를 공급업체로부터 받은 교체 FRU 구성 요소로 교체해야 합니다.
1단계: 손상된 컨트롤러를 종료합니다
스토리지 시스템 하드웨어 구성에 따라 다른 절차를 사용하여 손상된 컨트롤러를 종료하거나 인수할 수 있습니다.
손상된 컨트롤러의 기능을 인계받아 중지시키면 정상적인 컨트롤러가 손상된 컨트롤러의 스토리지에서 데이터를 계속 제공할 수 있습니다. 이를 위해 AutoSupport에서 자동 케이스 생성을 억제하고 자동 반환 기능을 비활성화한 다음 손상된 컨트롤러를 LOADER 프롬프트로 전환합니다. LOADER 프롬프트는 FRU를 교체할 수 있는 안전한 중지 상태입니다.
-
SAN 시스템을 사용하는 경우 손상된 컨트롤러 SCSI 블레이드에 대한 이벤트 메시지를 확인해야
cluster kernel-service show`합니다. priv advanced 모드에서 명령을 실행하면 `cluster kernel-service show해당 노드의 노드 이름"쿼럼 상태입니다", 해당 노드의 가용성 상태 및 해당 노드의 작동 상태가 표시됩니다.각 SCSI 블레이드 프로세스는 클러스터의 다른 노드와 함께 쿼럼에 있어야 합니다. 교체를 진행하기 전에 모든 문제를 해결해야 합니다.
-
노드가 2개 이상인 클러스터가 있는 경우 쿼럼에 있어야 합니다. 클러스터가 쿼럼에 없거나 정상 컨트롤러에 자격 및 상태에 대해 FALSE가 표시되는 경우 손상된 컨트롤러를 종료하기 전에 문제를 해결해야 합니다(참조) "노드를 클러스터와 동기화합니다".
-
AutoSupport가 활성화된 경우 AutoSupport 메시지를 호출하여 자동 케이스 생성을 억제합니다.
system node autosupport invoke -node * -type all -message MAINT=<number of hours down>h이렇게 하면 예정된 유지보수 윈도우 동안 자동 지원 케이스가 열리지 않습니다. 최대 차단 기간은 72시간입니다. 유지 관리가 조기에 완료된 경우 `MAINT=END`와 함께 AutoSupport 메시지를 호출하여 케이스 생성을 다시 활성화할 수 있습니다. 자세한 내용은 "예정된 유지보수 윈도우 동안 자동 케이스 생성을 억제하는 방법"을 참조하십시오.
다음 AutoSupport 메시지는 2시간 동안 자동 케이스 생성을 억제합니다.
cluster1:> system node autosupport invoke -node * -type all -message MAINT=2h -
자동 환불 비활성화:
-
정상 컨트롤러의 콘솔에서 다음 명령을 입력하세요.
storage failover modify -node impaired_node_name -auto-giveback false -
입력하다
y_자동 환불을 비활성화하시겠습니까?_라는 메시지가 표시되면
-
-
손상된 컨트롤러를 로더 프롬프트로 가져가십시오.
손상된 컨트롤러가 표시되는 경우… 그러면… LOADER 메시지가 표시됩니다
다음 단계로 이동합니다.
반환 대기 중…
Ctrl-C를 누른 다음 메시지가 나타나면 y를 누릅니다.
시스템 프롬프트 또는 암호 프롬프트
정상적인 컨트롤러에서 손상된 컨트롤러를 인계하거나 중지합니다.
storage failover takeover -ofnode impaired_node_name -halt true_-halt true_parameter는 Loader 프롬프트를 표시합니다.
손상된 컨트롤러를 종료하려면 컨트롤러 상태를 확인하고, 필요한 경우 컨트롤러 전원을 전환하여 정상적인 컨트롤러가 손상된 컨트롤러 스토리지에서 데이터를 계속 제공하도록 해야 합니다.
-
정상 컨트롤러에 전원을 공급하려면 이 절차의 마지막에 전원 공급 장치를 켜 두어야 합니다.
-
MetroCluster 상태를 확인하여 장애가 있는 컨트롤러가 자동으로 정상 컨트롤러(MetroCluster show)로 전환되었는지 확인합니다
-
자동 절체가 발생했는지 여부에 따라 다음 표에 따라 진행합니다.
컨트롤러 손상 여부 그러면… 가 자동으로 전환되었습니다
다음 단계를 진행합니다.
가 자동으로 전환되지 않았습니다
정상 컨트롤러 MetroCluster 절체 기능을 통해 계획된 절체 동작을 수행한다
가 자동으로 전환되지 않고, 'MetroCluster switchover' 명령으로 전환을 시도했으며, 스위치오버가 거부되었습니다
거부권 메시지를 검토하고 가능한 경우 문제를 해결한 후 다시 시도하십시오. 문제를 해결할 수 없는 경우 기술 지원 부서에 문의하십시오.
-
정상적인 클러스터에서 'MetroCluster 환원 단계 집계' 명령을 실행하여 데이터 애그리게이트를 재동기화합니다.
controller_A_1::> metrocluster heal -phase aggregates [Job 130] Job succeeded: Heal Aggregates is successful.
치유가 거부되면 '-override-vetoes' 매개 변수를 사용하여 'MetroCluster 환원' 명령을 재실행할 수 있습니다. 이 선택적 매개 변수를 사용하는 경우 시스템은 복구 작업을 방지하는 모든 소프트 베인을 재정의합니다.
-
MetroCluster operation show 명령을 사용하여 작업이 완료되었는지 확인합니다.
controller_A_1::> metrocluster operation show Operation: heal-aggregates State: successful Start Time: 7/25/2016 18:45:55 End Time: 7/25/2016 18:45:56 Errors: - -
'storage aggregate show' 명령을 사용하여 애그리게이트의 상태를 확인하십시오.
controller_A_1::> storage aggregate show Aggregate Size Available Used% State #Vols Nodes RAID Status --------- -------- --------- ----- ------- ------ ---------------- ------------ ... aggr_b2 227.1GB 227.1GB 0% online 0 mcc1-a2 raid_dp, mirrored, normal...
-
MetroCluster 환원 단계 루트 애그리게이트( heal-phase root-aggregate) 명령을 사용하여 루트 애그리게이트를 수정합니다.
mcc1A::> metrocluster heal -phase root-aggregates [Job 137] Job succeeded: Heal Root Aggregates is successful
치유가 거부되면 -override-vetoes 매개변수를 사용하여 'MetroCluster 환원' 명령을 재실행할 수 있습니다. 이 선택적 매개 변수를 사용하는 경우 시스템은 복구 작업을 방지하는 모든 소프트 베인을 재정의합니다.
-
대상 클러스터에서 'MetroCluster operation show' 명령을 사용하여 환원 작업이 완료되었는지 확인합니다.
mcc1A::> metrocluster operation show Operation: heal-root-aggregates State: successful Start Time: 7/29/2016 20:54:41 End Time: 7/29/2016 20:54:42 Errors: - -
손상된 컨트롤러 모듈에서 전원 공급 장치를 분리합니다.
2단계: 컨트롤러 모듈을 엽니다
컨트롤러 내의 구성 요소에 액세스하려면 먼저 시스템에서 컨트롤러 모듈을 분리한 다음 컨트롤러 모듈의 덮개를 분리해야 합니다.
-
아직 접지되지 않은 경우 올바르게 접지하십시오.
-
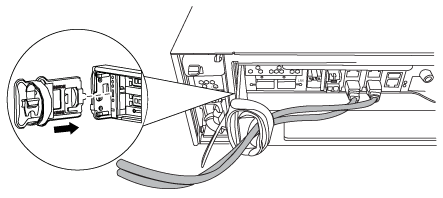
케이블을 케이블 관리 장치에 연결하는 후크 및 루프 스트랩을 푼 다음, 케이블이 연결된 위치를 추적하면서 컨트롤러 모듈에서 시스템 케이블과 SFP(필요한 경우)를 분리합니다.
케이블 관리 장치에 케이블을 남겨 두면 케이블 관리 장치를 다시 설치할 때 케이블이 정리됩니다.
-
컨트롤러 모듈의 왼쪽과 오른쪽에서 케이블 관리 장치를 분리하여 한쪽에 둡니다.
-
컨트롤러 모듈의 캠 핸들에 있는 손잡이 나사를 풉니다.
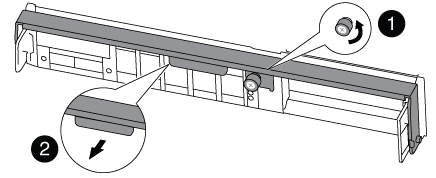

나비 나사

캠 핸들
-
캠 핸들을 아래로 당기고 컨트롤러 모듈을 섀시 밖으로 밀어냅니다.
컨트롤러 모듈 하단을 섀시 밖으로 밀어낼 때 지지하는지 확인합니다.
3단계: 캐싱 모듈을 교체하거나 추가하십시오
컨트롤러의 레이블에 M.2 PCIe 카드라고 하는 캐싱 모듈을 교체하거나 추가하려면 컨트롤러 내부의 슬롯을 찾아 특정 단계를 따릅니다.
스토리지 시스템은 상황에 따라 특정 기준을 충족해야 합니다.
-
설치하는 캐싱 모듈에 적합한 운영 체제가 있어야 합니다.
-
캐싱 용량을 지원해야 합니다.
-
스토리지 시스템의 다른 모든 구성 요소가 제대로 작동해야 합니다. 그렇지 않은 경우 기술 지원 부서에 문의해야 합니다.
-
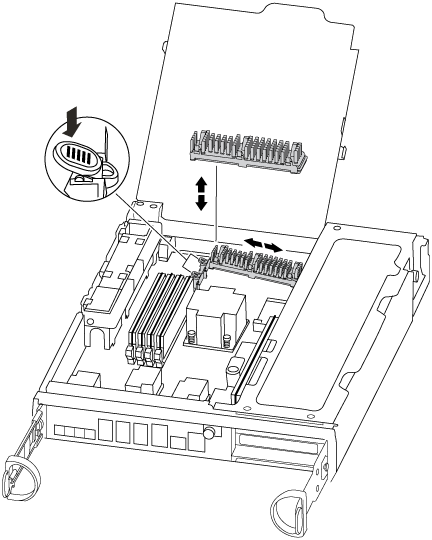
컨트롤러 모듈 후면에서 캐싱 모듈을 찾아 분리합니다.
-
분리 탭을 누릅니다.
-
히트싱크를 분리합니다.
스토리지 시스템에는 캐싱 모듈에 사용할 수 있는 슬롯이 2개 있으며 기본적으로 슬롯이 1개만 사용되고 있습니다.
-
-
캐싱 모듈을 추가하는 경우 다음 단계로 이동합니다. 캐싱 모듈을 교체하는 경우 하우징에서 똑바로 조심스럽게 당기십시오.
-
캐싱 모듈의 가장자리를 하우징의 소켓에 맞춘 다음 소켓에 부드럽게 밀어 넣습니다.
-
캐싱 모듈이 소켓에 직각으로 완전히 장착되었는지 확인합니다.
필요한 경우 캐시 모듈을 분리하고 소켓에 재장착합니다.
-
히트싱크를 다시 장착하고 아래로 눌러 캐싱 모듈 하우징의 잠금 버튼을 누릅니다.
-
두 번째 캐싱 모듈이 있는 경우 이 단계를 반복합니다. 필요에 따라 컨트롤러 모듈 덮개를 닫습니다.
-
4단계: 컨트롤러를 다시 설치합니다
컨트롤러 모듈 내에서 구성 요소를 교체한 후 시스템 섀시에 컨트롤러 모듈을 재설치해야 합니다.
-
컨트롤러 모듈의 끝을 섀시의 입구에 맞춘 다음 컨트롤러 모듈을 반쯤 조심스럽게 시스템에 밀어 넣습니다.
지시가 있을 때까지 컨트롤러 모듈을 섀시에 완전히 삽입하지 마십시오. -
필요에 따라 시스템을 다시 연결합니다.
미디어 컨버터(QSFP 또는 SFP)를 분리한 경우 광섬유 케이블을 사용하는 경우 다시 설치해야 합니다.
-
컨트롤러 모듈 재설치를 완료합니다.
컨트롤러 모듈이 섀시에 완전히 장착되면 바로 부팅이 시작됩니다
-
캠 핸들을 열린 위치에 둔 상태에서 컨트롤러 모듈이 중앙판과 완전히 맞닿고 완전히 장착될 때까지 단단히 누른 다음 캠 핸들을 잠금 위치로 닫습니다.
커넥터가 손상되지 않도록 컨트롤러 모듈을 섀시에 밀어 넣을 때 과도한 힘을 가하지 마십시오. -
컨트롤러 모듈 후면의 캠 핸들에 있는 나비 나사를 조입니다.
-
아직 설치하지 않은 경우 케이블 관리 장치를 다시 설치하십시오.
-
케이블을 후크와 루프 스트랩으로 케이블 관리 장치에 연결합니다.
-
5단계: 2노드 MetroCluster 구성에서 애그리게이트를 다시 전환합니다
이 작업은 2노드 MetroCluster 구성에만 적용됩니다.
-
모든 노드가 "enabled" 상태(MetroCluster node show)에 있는지 확인합니다
cluster_B::> metrocluster node show DR Configuration DR Group Cluster Node State Mirroring Mode ----- ------- -------------- -------------- --------- -------------------- 1 cluster_A controller_A_1 configured enabled heal roots completed cluster_B controller_B_1 configured enabled waiting for switchback recovery 2 entries were displayed. -
모든 SVM에서 재동기화가 완료되었는지 확인합니다. 'MetroCluster vserver show'
-
복구 작업에 의해 수행되는 자동 LIF 마이그레이션이 'MetroCluster check lif show'에 성공적으로 완료되었는지 확인합니다
-
정상적인 클러스터에 있는 모든 노드에서 'MetroCluster 스위치백' 명령을 사용하여 스위치백을 수행합니다.
-
스위치백 작업이 완료되었는지 확인합니다. 'MetroCluster show'
클러스터가 "대기 중 - 스위치백" 상태에 있으면 스위치백 작업이 여전히 실행 중입니다.
cluster_B::> metrocluster show Cluster Configuration State Mode -------------------- ------------------- --------- Local: cluster_B configured switchover Remote: cluster_A configured waiting-for-switchback
클러스터가 '정상' 상태에 있으면 스위치백 작업이 완료됩니다.
cluster_B::> metrocluster show Cluster Configuration State Mode -------------------- ------------------- --------- Local: cluster_B configured normal Remote: cluster_A configured normal
스위치백을 완료하는 데 시간이 오래 걸리는 경우 MetroCluster config-replication resync resync-status show 명령을 사용하여 진행 중인 기준선의 상태를 확인할 수 있습니다.
-
SnapMirror 또는 SnapVault 구성을 다시 설정합니다.
6단계: 교체 프로세스를 완료합니다
키트와 함께 제공된 RMA 지침에 설명된 대로 오류가 발생한 부품을 NetApp에 반환합니다. "부품 반환 및 교체"자세한 내용은 페이지를 참조하십시오.