

감사 메시지 흐름 및 보존
 변경 제안
변경 제안
모든 StorageGRID 서비스는 정상적인 시스템 작동 중에 감사 메시지를 생성합니다. 이러한 감사 메시지가 StorageGRID 시스템을 통해 어떻게 'audit.log' 파일로 이동하는지 이해해야 합니다.
감사 메시지 흐름
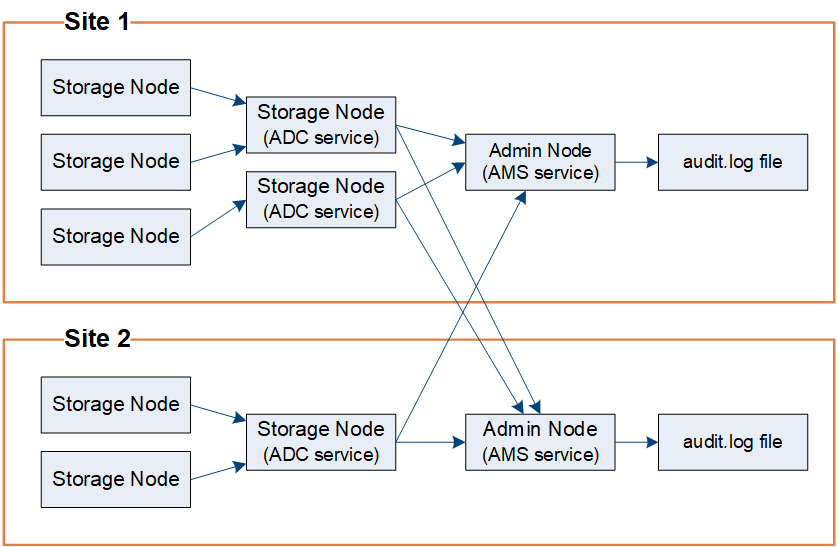
감사 메시지는 관리 노드 및 ADC(관리 도메인 컨트롤러) 서비스가 있는 스토리지 노드에 의해 처리됩니다.
감사 메시지 흐름도에 표시된 대로 각 StorageGRID 노드는 데이터 센터 사이트의 ADC 서비스 중 하나에 감사 메시지를 보냅니다. ADC 서비스는 각 사이트에 설치된 처음 세 개의 스토리지 노드에 대해 자동으로 활성화됩니다.
그러면 각 ADC 서비스가 릴레이 역할을 하고 감사 메시지 모음을 StorageGRID 시스템의 모든 관리 노드로 전송하여 각 관리 노드에 시스템 활동의 전체 기록을 제공합니다.
각 Admin Node는 텍스트 로그 파일에 감사 메시지를 저장하며, Active 로그 파일은 AUDIT.LOG로 명명된다.
감사 메시지 보존
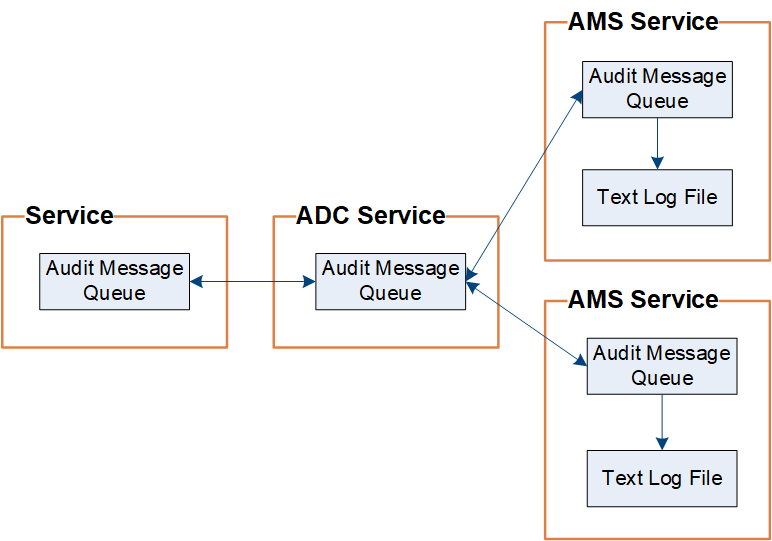
StorageGRID는 복사 및 삭제 프로세스를 사용하여 감사 로그에 쓰기 전에 감사 메시지가 손실되지 않도록 합니다.
노드가 감사 메시지를 생성하거나 릴레이할 때 이 메시지는 그리드 노드의 시스템 디스크에 있는 감사 메시지 큐에 저장됩니다. 관리 노드의 '/var/local/audit/export' 디렉토리에 감사 로그 파일에 메시지가 기록될 때까지 메시지 복사본은 항상 감사 메시지 큐에 유지됩니다. 이렇게 하면 전송 중에 감사 메시지 손실을 방지할 수 있습니다.
네트워크 연결 문제 또는 감사 용량 부족으로 인해 감사 메시지 큐가 일시적으로 증가할 수 있습니다. 대기열이 늘어갈수록 각 노드의 '/var/local/' 디렉토리에서 사용 가능한 공간이 더 많이 사용됩니다. 문제가 지속되고 노드의 감사 메시지 디렉토리가 너무 가득 차면 개별 노드가 백로그 처리를 우선 순위에 따라 새 메시지에 일시적으로 사용할 수 없게 됩니다.
특히 다음과 같은 행동을 볼 수 있습니다.
-
Admin Node에서 사용하는 '/var/local/audit/export' 디렉토리가 가득 차면 디렉토리가 더 이상 가득 차지 않을 때까지 Admin Node가 새 감사 메시지에 사용할 수 없는 것으로 플래그가 지정됩니다. S3 및 Swift 클라이언트 요청은 영향을 받지 않습니다. 감사 리포지토리에 연결할 수 없을 때 XAMS(Unreachable Audit Repositories) 경보가 트리거됩니다.
-
ADC 서비스가 있는 스토리지 노드에서 사용하는 "/var/local/" 디렉토리가 92% 차면 디렉토리가 87%만 가득 찰 때까지 노드가 메시지를 감사할 수 없는 것으로 플래그가 지정됩니다. 다른 노드에 대한 S3 및 Swift 클라이언트 요청은 영향을 받지 않습니다. 감사 릴레이에 연결할 수 없는 경우 NRLY(사용 가능한 감사 릴레이) 경보가 트리거됩니다.

ADC 서비스에 사용 가능한 스토리지 노드가 없는 경우 스토리지 노드는 감사 메시지를 '/var/local/log/localaudit.log' 파일에 로컬로 저장합니다. -
스토리지 노드에서 사용하는 "/var/local/" 디렉토리가 85%가 되면 노드에서 S3 및 Swift 클라이언트 요청을 거부하고 503 서비스 사용 불가 를 시작합니다.
다음과 같은 유형의 문제로 인해 감사 메시지 큐가 크게 증가할 수 있습니다.
-
ADC 서비스가 있는 관리 노드 또는 스토리지 노드의 정전. 시스템의 노드 중 하나가 다운되면 나머지 노드가 백로그될 수 있습니다.
-
시스템의 감사 용량을 초과하는 지속적인 활동률입니다.
-
감사 메시지와 무관한 이유로 ADC 스토리지 노드의 '/var/local/' 공간이 가득 찼습니다. 이 경우 노드에서 새 감사 메시지 수신을 중지하고 현재 백로그의 우선 순위를 지정하며, 이로 인해 다른 노드에 백로그가 발생할 수 있습니다.
AMQS(Large audit queue alert and Audit messages Queued)(대형 감사 대기열 경고 및 감사 메시지 대기 중
시간에 따라 감사 메시지 대기열의 크기를 모니터링할 수 있도록 스토리지 노드 대기열 또는 관리 노드 대기열의 메시지 수가 특정 임계값에 도달하면 * 대규모 감사 대기열 * 경고와 레거시 AMQS 경보가 트리거됩니다.
대규모 감사 대기열 * 경고 또는 레거시 AMQS 경보가 트리거되면 시스템에서 로드를 확인하여 시작합니다. — 최근 트랜잭션이 많이 발생한 경우, 경고 및 알람은 시간이 지남에 따라 해결되어야 하며 무시할 수 있습니다.
경고 또는 경보가 지속되고 심각도가 증가하면 대기열 크기의 차트를 참조하십시오. 시간이 경과하거나 며칠 동안 꾸준히 증가하는 경우 감사 로드가 시스템의 감사 용량을 초과할 가능성이 높습니다. 클라이언트 쓰기 및 클라이언트 읽기의 감사 수준을 오류 또는 끄기로 변경하여 클라이언트 작업 속도를 줄이거나 기록된 감사 메시지 수를 줄입니다. 참조"감사 메시지 및 로그 대상을 구성합니다있습니다."
중복된 메시지
StorageGRID 시스템은 네트워크 또는 노드 장애가 발생할 경우 보수적인 접근 방식을 사용합니다. 따라서 감사 로그에 중복된 메시지가 있을 수 있습니다.