

연결이 끊긴 그리드 노드의 서비스 해제
 변경 제안
변경 제안
현재 그리드에 연결되어 있지 않은 노드(상태가 알 수 없거나 관리상 중단된 노드)를 해제해야 할 수 있습니다.
-
귀하는 및 의 요구사항을 이해합니다 그리드 노드 폐기에 대한 고려 사항.
-
모든 필수 항목을 확보했습니다.
-
활성화된 데이터 복구 작업이 없도록 했습니다. 을 참조하십시오 데이터 복구 작업을 확인합니다.
-
스토리지 노드 복구가 그리드의 어느 곳에서든 진행되고 있지 않음을 확인했습니다. 있는 경우 복구 과정에서 Cassandra 재구축이 완료될 때까지 기다려야 합니다. 그런 다음 해체 작업을 진행할 수 있습니다.
-
노드 서비스 해제 절차가 일시 중지되지 않는 한 노드 서비스 해제 절차가 실행되는 동안 다른 유지 보수 절차가 실행되지 않도록 했습니다.
-
서비스 해제하려는 연결이 끊긴 노드 또는 노드에 대한 * 서비스 해제 가능 * 열에 녹색 확인 표시가 포함됩니다.
-
프로비저닝 암호가 있어야 합니다.
상태 * 열에서 알 수 없음(파란색) 또는 관리 다운(회색) 아이콘을 찾아 연결이 끊긴 노드를 식별할 수 있습니다. 이 예에서는 DC1-S4라는 스토리지 노드의 연결이 끊어지고 다른 모든 노드가 연결됩니다.
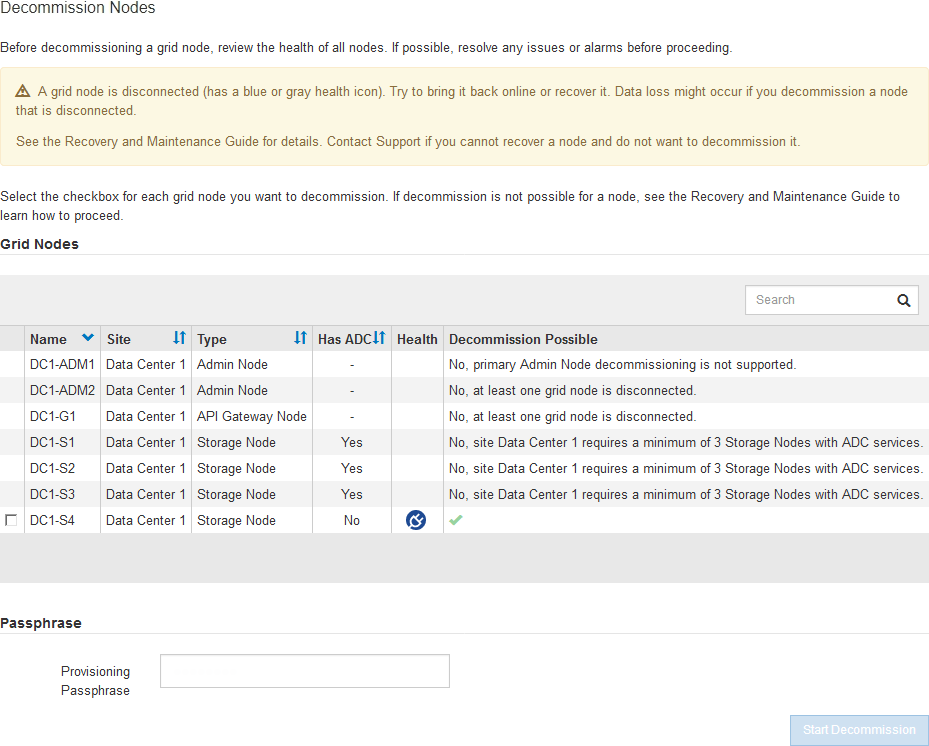
분리된 노드를 폐기하기 전에 다음 사항에 유의하십시오.
-
이 절차는 주로 연결이 끊긴 단일 노드를 제거하기 위한 것입니다. 그리드에 연결이 끊어진 노드가 여러 개 포함된 경우, 소프트웨어를 동시에 모두 해제해야 예기치 않은 결과가 발생할 가능성이 높아집니다.

연결이 끊긴 여러 개의 그리드 노드를 한 번에 해제할 때는 특히 연결이 끊긴 여러 스토리지 노드를 선택하는 경우 특히 주의해야 합니다. -
연결이 끊긴 노드를 제거할 수 없는 경우(예: ADC 쿼럼에 필요한 스토리지 노드) 연결이 끊긴 다른 노드는 제거할 수 없습니다.
연결이 끊긴 * 스토리지 노드 * 를 해제하기 전에 다음 사항에 유의하십시오
-
연결 해제된 스토리지 노드를 온라인 상태로 만들거나 복구할 수 없는 경우가 아니라면 이 스토리지 노드를 서비스 해제해서는 안 됩니다.
노드에서 개체 데이터를 복구할 수 있다고 생각되면 이 절차를 수행하지 마십시오. 대신 기술 지원 부서에 문의하여 노드 복구가 가능한지 확인하십시오. -
연결이 끊긴 스토리지 노드를 두 개 이상 폐기하는 경우 데이터가 손실될 수 있습니다. 오브젝트 복사본, 삭제 코딩 조각 또는 오브젝트 메타데이터가 충분하지 않은 경우 시스템에서 데이터를 재구성하지 못할 수 있습니다.
복구할 수 없는 스토리지 노드가 두 개 이상 연결되어 있는 경우 기술 지원 부서에 문의하여 최상의 조치 방법을 확인하십시오. -
연결이 끊긴 스토리지 노드를 폐기하는 경우 StorageGRID는 서비스 해제 프로세스가 끝날 때 데이터 복구 작업을 시작합니다. 이러한 작업은 연결이 끊긴 노드에 저장된 개체 데이터 및 메타데이터를 재구성하려고 시도합니다.
-
연결이 끊긴 스토리지 노드를 폐기하면 서비스 해제 절차가 비교적 빠르게 완료됩니다. 그러나 데이터 복구 작업을 실행하는 데 며칠 또는 몇 주가 걸릴 수 있으며 서비스 해제 절차를 통해 모니터링되지 않습니다. 이러한 작업을 수동으로 모니터링하고 필요에 따라 다시 시작해야 합니다. 을 참조하십시오 데이터 복구 작업을 확인합니다.
-
개체의 복사본만 포함된 연결이 끊긴 스토리지 노드를 폐기하면 개체가 손실됩니다. 데이터 복구 작업은 현재 연결된 스토리지 노드에 하나 이상의 복제된 복사본 또는 충분한 삭제 코딩 조각이 있는 경우에만 오브젝트를 재구성 및 복구할 수 있습니다.
연결되지 않은 * 관리 노드 * 또는 * 게이트웨이 노드 * 를 해제하기 전에 다음 사항을 확인하십시오.
-
연결이 끊긴 관리 노드를 서비스 해제할 경우 해당 노드에서 감사 로그가 손실되지만 이러한 로그는 기본 관리 노드에도 존재해야 합니다.
-
연결이 끊어진 상태에서 게이트웨이 노드를 안전하게 해제할 수 있습니다.
-
연결이 끊긴 그리드 노드를 다시 온라인 상태로 만들거나 복구해 봅니다.
지침은 복구 절차를 참조하십시오.
-
연결이 끊긴 그리드 노드를 복구할 수 없고 연결이 끊긴 동안 노드 사용을 해제하려면 해당 노드에 대한 확인란을 선택합니다.

그리드에 연결이 끊어진 노드가 여러 개 포함된 경우, 소프트웨어를 동시에 모두 해제해야 예기치 않은 결과가 발생할 가능성이 높아집니다.
연결이 끊긴 여러 스토리지 노드를 선택하는 경우, 한 번에 둘 이상의 그리드 노드 해제를 선택할 때는 특히 주의해야 합니다. 복구할 수 없는 스토리지 노드가 두 개 이상 연결되어 있는 경우 기술 지원 부서에 문의하여 최상의 조치 방법을 확인하십시오. -
프로비저닝 암호를 입력합니다.
서비스 해제 시작 * 버튼이 활성화됩니다.
-
서비스 해제 시작 * 을 클릭합니다.
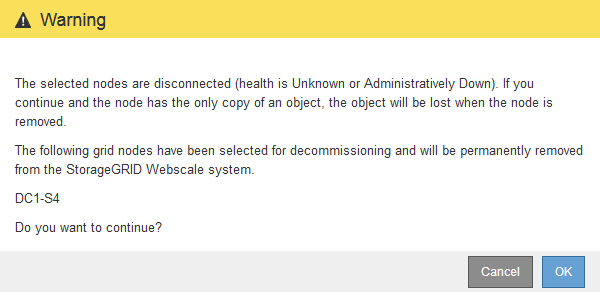
연결이 끊긴 노드를 선택했으며 노드에 개체의 복사본만 있는 경우 개체 데이터가 손실된다는 경고가 나타납니다.
-
노드 목록을 검토하고 * OK * 를 클릭합니다.
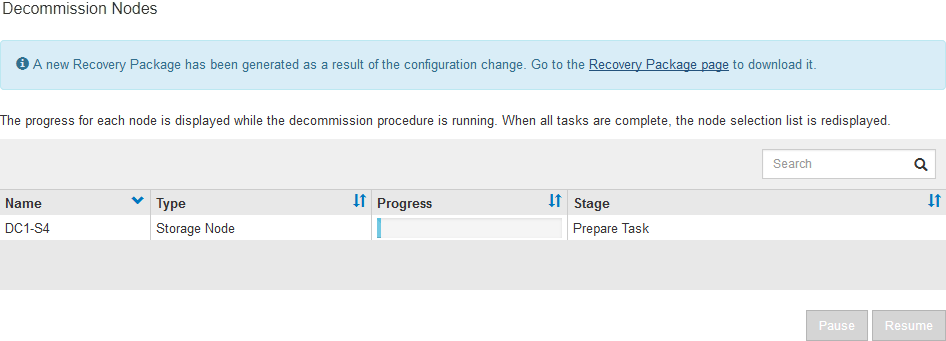
서비스 해제 절차가 시작되고 각 노드에 대한 진행률이 표시됩니다. 절차 중에 그리드 구성 변경을 포함하는 새 복구 패키지가 생성됩니다.
-
새 복구 패키지를 사용할 수 있게 되면 링크를 클릭하거나 * 유지보수 * > * 시스템 * > * 복구 패키지 * 를 선택하여 복구 패키지 페이지에 액세스합니다. 그런 다음 .zip 파일을 다운로드합니다.
의 지침을 참조하십시오 복구 패키지 다운로드 중.
서비스 해제 절차 중에 문제가 발생할 경우 그리드를 복구할 수 있도록 가능한 한 빨리 복구 패키지를 다운로드하십시오.
복구 패키지 파일은 StorageGRID 시스템에서 데이터를 가져오는 데 사용할 수 있는 암호화 키와 암호가 포함되어 있으므로 보안을 유지해야 합니다. -
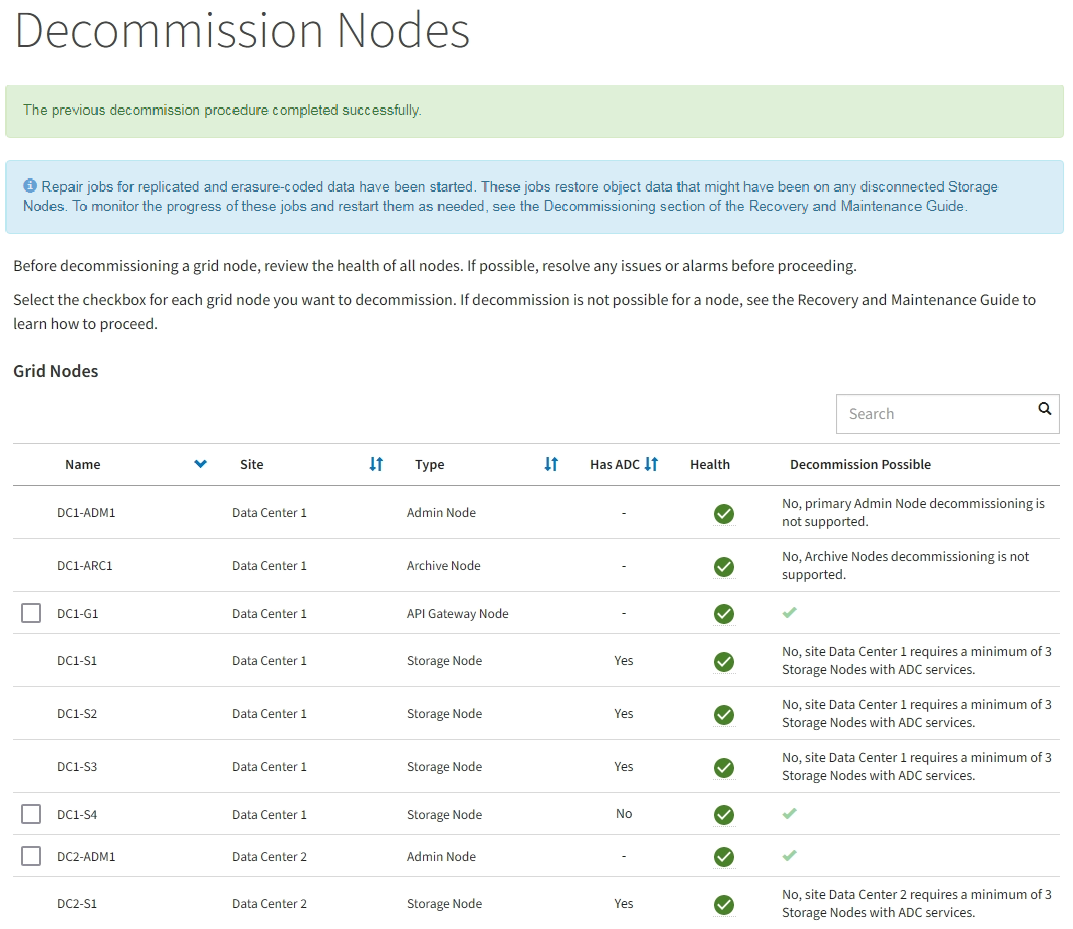
서비스 해제 페이지를 주기적으로 모니터링하여 선택한 모든 노드가 성공적으로 폐기되었는지 확인합니다.
스토리지 노드의 사용을 해제하는 데 며칠 또는 몇 주가 걸릴 수 있습니다. 모든 작업이 완료되면 노드 선택 목록이 성공 메시지와 함께 다시 표시됩니다. 분리된 스토리지 노드를 폐기한 경우 복구 작업이 시작되었다는 정보 메시지가 표시됩니다.
-
서비스 해제 절차의 일부로 노드가 자동으로 종료된 후 나머지 가상 머신 또는 사용 중지된 노드와 관련된 기타 리소스를 제거합니다.
노드가 자동으로 종료될 때까지 이 단계를 수행하지 마십시오. -
스토리지 노드를 폐기하는 경우 서비스 해제 프로세스 중에 자동으로 시작되는 * 복제된 데이터 * 및 * 삭제 코딩(EC) 데이터 * 복구 작업의 상태를 모니터링합니다.
-
수리가 완료되었는지 확인하려면:
-
노드 * > * _ 복구되는 스토리지 노드 _ * > * ILM * 을 선택합니다.
-
평가 섹션의 속성을 검토합니다. 복구가 완료되면 * Awaiting-all * 속성이 0 개체를 나타냅니다.
-
-
수리를 더 자세히 모니터링하려면:
-
지원 * > * 도구 * > * 그리드 토폴로지 * 를 선택합니다.
-
복구되는 *GRID * > *_Storage Node _ * > * LDR * > * Data Store * 를 선택합니다.
-
복제된 수리가 완료된 경우 다음 특성을 조합하여 가능한 한 결정합니다.
Cassandra의 일관성이 없을 수 있으며, 복구 실패를 추적하지 않습니다. -
* 시도된 복구(XRPA) : 이 속성을 사용하여 복제된 복구 진행률을 추적합니다. 이 속성은 스토리지 노드가 고위험 객체를 복구하려고 할 때마다 증가합니다. 이 속성이 현재 스캔 기간( Scan Period — Estimated* 속성 제공)보다 더 긴 기간 동안 증가하지 않으면 ILM 스캐닝에서 모든 노드에서 복구해야 할 고위험 개체를 찾지 못한 것입니다.
고위험 개체는 완전히 손실될 위험이 있는 개체입니다. ILM 구성을 충족하지 않는 개체는 포함되지 않습니다. -
* 스캔 기간 — 예상(XSCM) *: 이 속성을 사용하여 이전에 수집된 개체에 정책 변경이 적용되는 시점을 추정합니다. 복구 시도 * 속성이 현재 스캔 기간보다 긴 기간 동안 증가하지 않으면 복제된 수리가 수행될 수 있습니다. 스캔 기간은 변경될 수 있습니다. 스캔 기간 — 예상(XSCM) * 속성은 전체 그리드에 적용되며 모든 노드 스캔 기간의 최대값입니다. 그리드에 대한 * Scan Period — Estimated * 속성 기록을 조회하여 적절한 기간을 결정할 수 있습니다.
-
-
-
필요에 따라 복제된 복구에 대한 예상 완료율을 얻으려면 repair-data 명령에 'show-replicated-repair-status' 옵션을 추가합니다.
REpair-data show-replicated-repair-status'를 참조하십시오
StorageGRID 11.6의 기술 미리 보기에는 '복제된-수리-상태' 옵션이 제공됩니다. 이 기능은 개발 중이며 반환된 값이 잘못되었거나 지연될 수 있습니다. 수리가 완료되었는지 확인하려면 에 설명된 대로 * Awaiting – All *, * repair attemptated (XRPA) * 및 * Scan Period — Estimated (XSCM) * 를 사용합니다 수리 모니터링.
삭제 코딩 데이터의 복구를 모니터링하고 실패한 요청을 다시 시도하려면 다음을 수행하십시오.
-
삭제 코딩 데이터 복구 상태를 확인합니다.
-
현재 작업의 예상 완료 시간과 완료 비율을 보려면 * 지원 * > * 도구 * > * 메트릭 * 을 선택합니다. 그런 다음 Grafana 섹션에서 * EC 개요 * 를 선택합니다. Grid EC Job Ec Job Estimated Time to Completion * 및 * Grid EC Job Percentage Completed * 대시보드를 확인합니다.
-
특정 repair-data 작업의 상태를 확인하려면 다음 명령을 사용합니다.
REpair-data show -ec-repair-status—repair-id repair ID'를 참조하십시오
-
이 명령을 사용하여 모든 수리를 나열합니다.
Repair-data show-ec-repair-status'를 참조하십시오
이 출력에는 현재 실행 중인 모든 수리에 대한 "재쌍 ID"를 포함한 정보가 나열됩니다.
-
-
출력에 복구 작업이 실패한 것으로 표시되면 '--repair-id' 옵션을 사용하여 복구를 다시 시도합니다.
이 명령은 복구 ID 6949309319275667690을 사용하여 장애가 발생한 노드 복구를 재시도합니다.
REpair-data start-ec-node-repair—repair-id 6949309319275667690
이 명령은 복구 ID 6949309319275667690을 사용하여 실패한 볼륨 복구를 재시도합니다.
REpair-data start-ec-volume-repair—repair-id 6949309319275667690
연결이 끊긴 노드를 폐기하고 모든 데이터 복구 작업이 완료되는 즉시 연결된 모든 그리드 노드를 필요에 따라 해제할 수 있습니다.
그런 다음 서비스 해제 절차를 완료한 후 다음 단계를 완료합니다.
-
해체된 그리드 노드의 드라이브가 깨끗하게 지워졌는지 확인합니다. 상용 데이터 삭제 도구 또는 서비스를 사용하여 드라이브에서 데이터를 영구적으로 안전하게 제거합니다.
-
어플라이언스 노드를 폐기했고 어플라이언스의 데이터가 노드 암호화를 사용하여 보호된 경우 StorageGRID 어플라이언스 설치 프로그램을 사용하여 키 관리 서버 구성을 지웁니다(KMS 지우기). 다른 그리드에 어플라이언스를 추가하려면 KMS 구성을 지워야 합니다.