복구 시작 을 선택하여 스토리지 노드를 구성합니다
 변경 제안
변경 제안
스토리지 노드를 교체한 후 그리드 관리자에서 복구 시작 을 선택하여 장애가 발생한 노드의 대체 노드로 새 노드를 구성해야 합니다.
-
를 사용하여 그리드 관리자에 로그인해야 합니다 지원되는 웹 브라우저.
-
유지 관리 또는 루트 액세스 권한이 있어야 합니다.
-
프로비저닝 암호가 있어야 합니다.
-
교체 노드를 구축하고 구성해야 합니다.
-
삭제 코딩 데이터에 대한 복구 작업의 시작 날짜를 알아야 합니다.
-
스토리지 노드가 지난 15일 이내에 재구축되지 않은 것을 확인해야 합니다.
스토리지 노드가 Linux 호스트에 컨테이너로 설치되어 있는 경우 다음 중 하나가 참인 경우에만 이 단계를 수행해야 합니다.
-
노드를 가져오려면 '--force' 플래그를 사용하거나 StorageGRID node force-recovery_node-name_'을(를) 실행했습니다
-
전체 노드를 다시 설치하거나 /var/local을 복원해야 했습니다.
-
Grid Manager에서 * 유지보수 * > * 작업 * > * 복구 * 를 선택합니다.
-
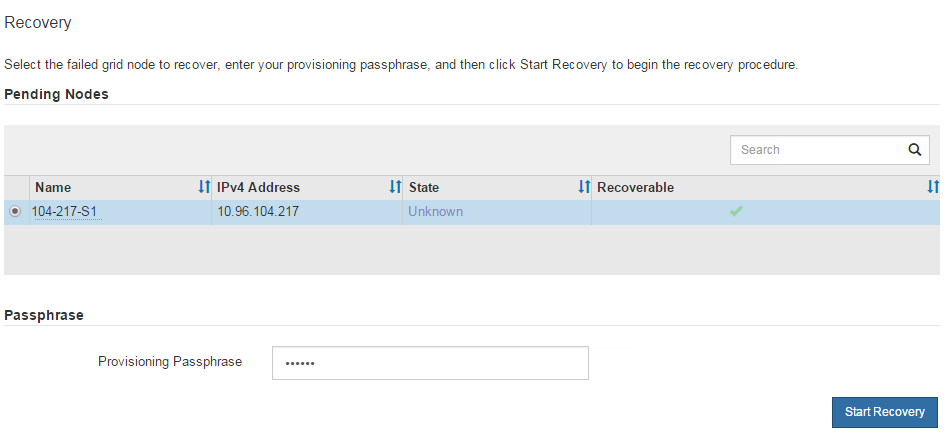
Pending Nodes 목록에서 복구할 그리드 노드를 선택합니다.
노드가 실패한 후 목록에 나타나지만 다시 설치되고 복구 준비가 될 때까지 노드를 선택할 수 없습니다.
-
Provisioning Passphrase * 를 입력합니다.
-
복구 시작 * 을 클릭합니다.
-
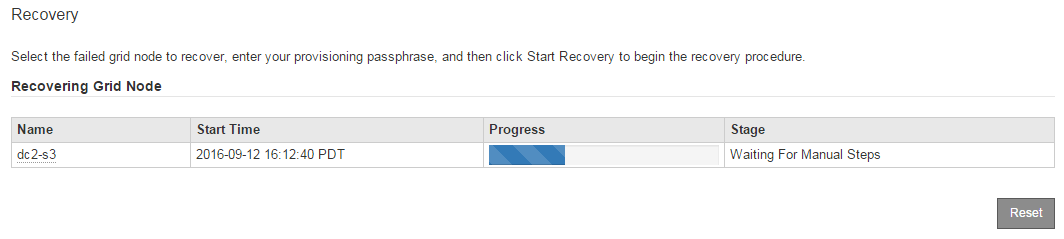
복구 그리드 노드 테이블에서 복구 진행률을 모니터링합니다.

복구 절차가 실행되는 동안 * Reset * 을 클릭하여 새 복구를 시작할 수 있습니다. 프로시저를 재설정하면 노드가 결정되지 않은 상태로 남아 있음을 나타내는 정보 대화 상자가 나타납니다. 
절차를 재설정한 후 복구를 재시도하려면 다음과 같이 노드를 사전 설치된 상태로 복원해야 합니다.
-
* VMware *: 배포된 가상 그리드 노드를 삭제합니다. 그런 다음 복구를 다시 시작할 준비가 되면 노드를 다시 배포합니다.
-
Linux*: Linux 호스트에서 'StorageGRID node force-recovery_node-name_' 명령을 실행하여 노드를 다시 시작합니다
-
-
스토리지 노드가 ""수동 단계 대기 중" 단계에 도달하면 복구 절차의 다음 작업으로 이동하여 스토리지 볼륨을 다시 마운트하고 다시 포맷합니다.