

메타데이터 문제를 해결합니다
 변경 제안
변경 제안
여러 작업을 수행하여 메타데이터 문제의 원인을 확인할 수 있습니다.
메타데이터 부족 스토리지 경고 문제를 해결합니다
메타데이터 스토리지 부족 * 경고가 트리거되면 새 스토리지 노드를 추가해야 합니다.
-
를 사용하여 그리드 관리자에 로그인해야 합니다 지원되는 웹 브라우저.
StorageGRID는 각 스토리지 노드의 볼륨 0에 개체 메타데이터를 위한 일정한 양의 공간을 예약합니다. 이 공간을 실제 예약 공간이라고 하며, 여기에는 오브젝트 메타데이터(허용되는 메타데이터 공간)에 허용되는 공간과 컴팩션 및 복구처럼 필수 데이터베이스 작업에 필요한 공간으로 세분화됩니다. 허용되는 메타데이터 공간은 전체 오브젝트 용량을 관리합니다.
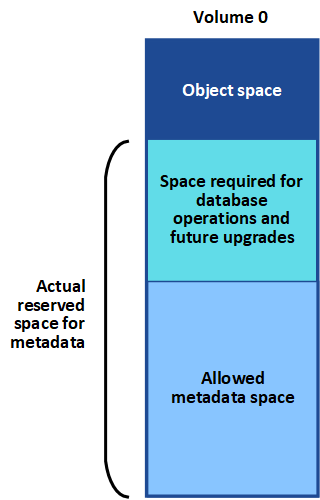
오브젝트 메타데이터가 메타데이터에 허용된 공간의 100% 이상을 소비하면 데이터베이스 작업이 효율적으로 실행되지 않고 오류가 발생합니다.
가능합니다 각 스토리지 노드의 객체 메타데이터 용량을 모니터링합니다 오류가 발생하기 전에 미리 예측하고 수정할 수 있도록 도와줍니다.
StorageGRID는 다음 Prometheus 메트릭을 사용하여 허용되는 메타데이터 공간의 전체 용량을 측정합니다.
storagegrid_storage_utilization_metadata_bytes/storagegrid_storage_utilization_metadata_allowed_bytes
이 Prometheus 표현식이 특정 임계값에 도달하면 * Low metadata storage * 경고가 트리거됩니다.
-
* Minor * : 객체 메타데이터가 허용된 메타데이터 공간의 70% 이상을 사용하고 있습니다. 가능한 빨리 새 스토리지 노드를 추가해야 합니다.
-
* Major *: 오브젝트 메타데이터는 허용된 메타데이터 공간을 90% 이상 사용합니다. 새 스토리지 노드를 즉시 추가해야 합니다.

오브젝트 메타데이터가 허용된 메타데이터 공간의 90% 이상을 사용하는 경우 대시보드에 경고가 표시됩니다. 이 경고가 나타나면 새 스토리지 노드를 즉시 추가해야 합니다. 오브젝트 메타데이터에서 허용되는 공간의 100% 이상을 사용하도록 허용해서는 안 됩니다. -
* Critical *: 오브젝트 메타데이터는 허용된 메타데이터 공간을 100% 이상 사용하며 필수 데이터베이스 작업에 필요한 공간을 사용하기 시작합니다. 새 오브젝트 수집을 중지해야 하며 새 스토리지 노드를 즉시 추가해야 합니다.
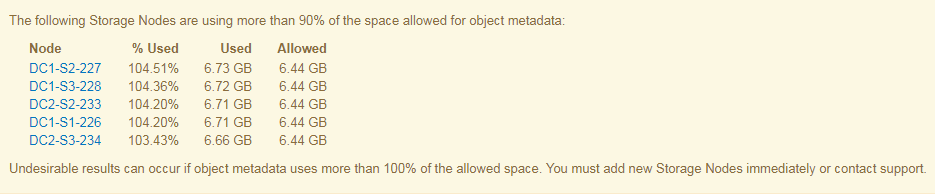
다음 예제에서 오브젝트 메타데이터는 허용되는 메타데이터 공간의 100% 이상을 사용합니다. 이는 비효율적인 데이터베이스 작업 및 오류를 초래할 수 있는 심각한 상황입니다.
|
|
볼륨 0의 크기가 Metadata Reserved Space Storage Option(예: 비운영 환경)보다 작은 경우 * Low Metadata Storage * 알림에 대한 계산이 부정확할 수 있습니다. |
-
alerts * > * current * 를 선택합니다.
-
경고 표에서 * Low metadata storage * 알림 그룹을 확장하고 필요한 경우 보려는 특정 경고를 선택합니다.
-
경고 대화 상자에서 세부 정보를 검토합니다.
-
Major 또는 Critical * Low Metadata Storage * 알림이 트리거된 경우 확장을 수행하여 스토리지 노드를 즉시 추가합니다.

StorageGRID는 모든 오브젝트 메타데이터의 전체 복사본을 각 사이트에 유지하므로 전체 그리드의 메타데이터 용량은 가장 작은 사이트의 메타데이터 용량에 의해 제한됩니다. 한 사이트에 메타데이터 용량을 추가해야 하는 경우에도 필요합니다 다른 사이트를 확장합니다 동일한 수의 스토리지 노드 기준 확장을 수행한 후 StorageGRID는 기존 오브젝트 메타데이터를 새 노드로 재분산하여 그리드의 전체 메타데이터 용량을 늘립니다. 사용자 작업이 필요하지 않습니다. Low metadata storage * 알림이 지워집니다.
서비스: 상태 - Cassandra(SVST) 알람 문제를 해결합니다
서비스: 상태 - Cassandra(SVST) 알람은 스토리지 노드에 대한 Cassandra 데이터베이스를 재구성해야 할 수 있음을 나타냅니다. Cassandra는 StorageGRID의 메타데이터 저장소로 사용됩니다.
-
를 사용하여 그리드 관리자에 로그인해야 합니다 지원되는 웹 브라우저.
-
특정 액세스 권한이 있어야 합니다.
-
"passwords.txt" 파일이 있어야 합니다.
Cassandra가 15일 이상 중지(예: 스토리지 노드 전원이 꺼져 있는 경우)인 경우, 노드가 다시 온라인 상태가 될 때 Cassandra가 시작되지 않습니다. 영향을 받는 DDS 서비스를 위해 Cassandra 데이터베이스를 재구축해야 합니다.
가능합니다 진단 유틸리티를 실행합니다 그리드의 현재 상태에 대한 추가 정보를 얻습니다.
|
|
Cassandra 데이터베이스 서비스가 15일 이상 중단된 경우, 기술 지원 팀에 문의 하여 다음 단계를 진행하지 마십시오. |
-
지원 * > * 도구 * > * 그리드 토폴로지 * 를 선택합니다.
-
경보를 표시하려면 *Site * > *Storage Node * > * SSM * > * Services * > * Alarms * > * Main * 을 선택합니다.
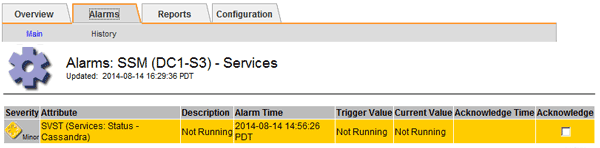
이 예에서는 SVST 알람이 트리거되었음을 보여 줍니다.
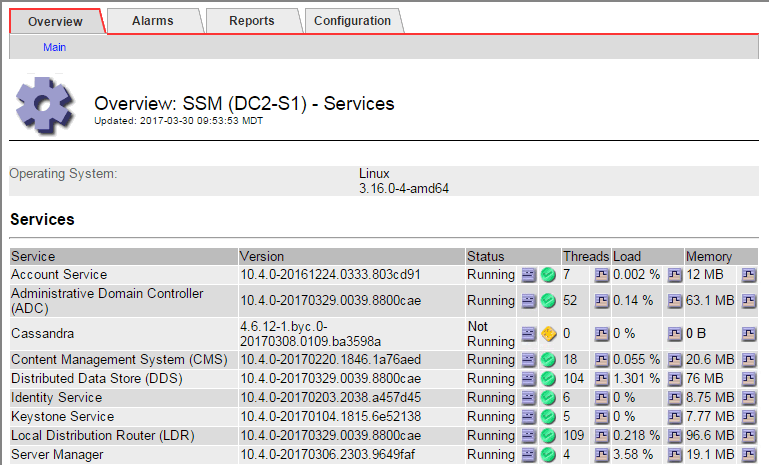
SSM 서비스 기본 페이지에는 Cassandra가 실행되고 있지 않습니다.
-
스토리지 노드에서 Cassandra를 다시 시작합니다.
-
그리드 노드에 로그인합니다.
-
ssh admin@grid_node_ip' 명령을 입력한다
-
"passwords.txt" 파일에 나열된 암호를 입력합니다.
-
루트로 전환하려면 다음 명령을 입력합니다
-
"passwords.txt" 파일에 나열된 암호를 입력합니다. 루트로 로그인하면 프롬프트가 '$'에서 '#'로 바뀝니다.
-
-
'/etc/init.d/cassandra status'를 입력합니다
-
Cassandra가 실행되고 있지 않으면 '/etc/init.d/cassandra restart'를 다시 시작합니다
-
-
Cassandra가 다시 시작되지 않으면 Cassandra가 얼마 동안 중단되었는지 확인합니다. Cassandra가 15일 이상 중단된 경우 Cassandra 데이터베이스를 재구성해야 합니다.
Cassandra 데이터베이스 서비스가 두 개 이상 중단된 경우 기술 지원 팀에 문의 하여 다음 단계를 진행하지 마십시오. Cassandra의 가동 중지 시간은 차트를 작성하거나 servermanager.log 파일을 검토하여 확인할 수 있습니다.
-
Cassandra 차트 만들기:
-
지원 * > * 도구 * > * 그리드 토폴로지 * 를 선택합니다. 그런 다음 *Site * > *Storage Node * > * SSM * > * Services * > * Reports * > * Charts * 를 선택합니다.
-
Attribute * > * Service:Status-Cassandra * 를 선택합니다.
-
시작 날짜 * 에 대해 현재 날짜 16일 이전의 날짜를 입력합니다. 종료 날짜 * 에 현재 날짜를 입력합니다.
-
Update * 를 클릭합니다.
-
차트에 Cassandra가 15일 이상 다운된 것으로 표시되면 Cassandra 데이터베이스를 재구축합니다.
-
다음 차트 예제에서는 Cassandra가 최소 17일 동안 중단되었음을 보여 줍니다.
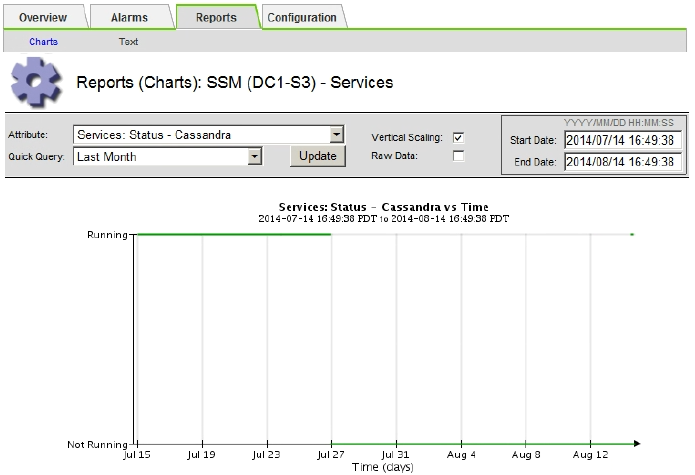
-
스토리지 노드에서 servermanager.log 파일을 검토하려면 다음을 수행합니다.
-
그리드 노드에 로그인합니다.
-
ssh admin@grid_node_ip' 명령을 입력한다
-
"passwords.txt" 파일에 나열된 암호를 입력합니다.
-
루트로 전환하려면 다음 명령을 입력합니다
-
"passwords.txt" 파일에 나열된 암호를 입력합니다. 루트로 로그인하면 프롬프트가 '$'에서 '#'로 바뀝니다.
-
-
'cat/var/local/log/ServerManager.log'를 입력합니다
servermanager.log 파일의 내용이 표시됩니다.
Cassandra가 15일 이상 중단된 경우 servermanager.log 파일에 다음 메시지가 표시됩니다.
"2014-08-14 21:01:35 +0000 | cassandra | cassandra not started because it has been offline for longer than its 15 day grace period - rebuild cassandra
-
이 메시지의 타임스탬프가 단계의 지침에 따라 Cassandra를 다시 시작하려고 시도한 시간인지 확인합니다 스토리지 노드에서 Cassandra를 다시 시작합니다.
Cassandra에는 여러 항목이 있을 수 있으며, 가장 최근 항목을 찾아야 합니다.
-
Cassandra가 15일 이상 중단된 경우 Cassandra 데이터베이스를 재구성해야 합니다.
자세한 내용은 을 참조하십시오 스토리지 노드를 15일 이상 복구합니다.
-
Cassandra를 재구축한 후 경보가 지워지지 않으면 기술 지원 부서에 문의하십시오.
-
Cassandra 메모리 부족 오류(SMTT 알람) 문제 해결
Cassandra 데이터베이스에 메모리 부족 오류가 발생하면 SMTT(Total Events) 경보가 발생합니다. 이 오류가 발생하면 기술 지원 부서에 문의하여 문제를 해결하십시오.
Cassandra 데이터베이스에 대해 메모리 부족 오류가 발생하면 힙 덤프가 생성되고, SMTT(Total Events) 경보가 트리거되고, Cassandra 힙 Out of Memory Errors 카운트가 1씩 증가합니다.
-
이벤트를 보려면 * 지원 * > * 도구 * > * 그리드 토폴로지 * > * 구성 * 을 선택합니다.
-
Cassandra 힙 Out of Memory Errors 카운트가 1 이상인지 확인합니다.
가능합니다 진단 유틸리티를 실행합니다 그리드의 현재 상태에 대한 추가 정보를 얻습니다.
-
'/var/local/core/'로 이동하여 ''Cassandra.hprof' 파일을 압축하고 기술 지원 부서에 보냅니다.
-
Cassandra.hprof 파일을 백업하고 "/var/local/core/directory"에서 삭제합니다.
이 파일은 24GB까지 커질 수 있으므로 이 파일을 제거하여 공간을 확보해야 합니다.
-
문제가 해결된 후 Cassandra 힙 Out of Memory Errors 카운트에 대한 * Reset * 확인란을 선택합니다. 그런 다음 * 변경 사항 적용 * 을 선택합니다.
이벤트 수를 재설정하려면 그리드 토폴로지 페이지 구성 권한이 있어야 합니다.