

장애가 발생한 스토리지 볼륨을 식별하고 마운트 해제합니다
 변경 제안
변경 제안
장애가 발생한 스토리지 볼륨으로 스토리지 노드를 복구할 때는 장애가 발생한 볼륨을 식별하고 마운트 해제해야 합니다. 복구 절차의 일부로 장애가 발생한 스토리지 볼륨만 다시 포맷되었는지 확인해야 합니다.
를 사용하여 그리드 관리자에 로그인했습니다 "지원되는 웹 브라우저".
장애가 발생한 스토리지 볼륨은 가능한 한 빨리 복구해야 합니다.
복구 프로세스의 첫 번째 단계는 분리되었거나, 마운트 해제되어야 하거나, I/O 오류가 있는 볼륨을 검색하는 것입니다. 오류가 발생한 볼륨이 여전히 연결되어 있지만 임의로 손상된 파일 시스템이 있는 경우 시스템에서 디스크의 사용되지 않거나 할당되지 않은 부분에 있는 손상을 감지하지 못할 수 있습니다.

|
디스크 추가 또는 다시 연결, 노드 중지, 노드 시작 또는 재부팅과 같은 수동 단계를 수행하여 볼륨을 복구하려면 이 절차를 완료해야 합니다. 그렇지 않으면 를 실행할 때 reformat_storage_block_devices.rb 스크립트: 파일 시스템 오류가 발생하여 스크립트가 중단되거나 실패할 수 있습니다.
|
|
|
를 실행하기 전에 하드웨어를 복구하고 디스크를 올바르게 연결합니다 reboot 명령.
|

|
장애가 발생한 스토리지 볼륨을 신중하게 식별합니다. 이 정보를 사용하여 재포맷해야 하는 볼륨을 확인할 수 있습니다. 볼륨이 다시 포맷되면 볼륨의 데이터를 복구할 수 없습니다. |
장애가 발생한 스토리지 볼륨을 올바르게 복구하려면 실패한 스토리지 볼륨의 디바이스 이름과 해당 볼륨 ID를 모두 알아야 합니다.
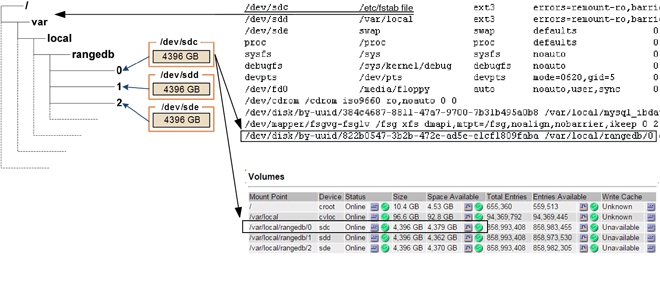
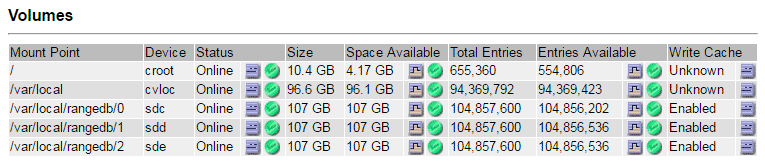
설치 시 각 스토리지 디바이스에 파일 시스템 UUID(Universal Unique Identifier)가 할당되고 할당된 파일 시스템 UUID를 사용하여 스토리지 노드의 rangedb 디렉토리에 마운트됩니다. 파일 시스템 UUID와 rangedb 디렉토리가 에 나열되어 있습니다 /etc/fstab 파일. 디바이스 이름, rangedb 디렉토리 및 마운트된 볼륨의 크기가 Grid Manager에 표시됩니다.
다음 예에서는 device입니다 /dev/sdc 볼륨 크기가 4TB이고 이 에 마운트됩니다 /var/local/rangedb/0, 장치 이름 사용 /dev/disk/by-uuid/822b0547-3b2b-472e-ad5e-e1cf1809faba 에 있습니다 /etc/fstab 파일:
-
다음 단계를 수행하여 장애가 발생한 스토리지 볼륨 및 해당 디바이스 이름을 기록합니다.
-
지원 * > * 도구 * > * 그리드 토폴로지 * 를 선택합니다.
-
site * > * failed Storage Node * > * LDR * > * Storage * > * Overview * > * Main * 을 선택하고 알람이 있는 객체 저장소를 찾습니다.

-
site * > * failed Storage Node * > * SSM * > * Resources * > * Overview * > * Main * 을 선택합니다. 이전 단계에서 확인한 실패한 각 스토리지 볼륨의 마운트 지점 및 볼륨 크기를 확인합니다.
오브젝트 저장소는 16진수로 번호가 매겨집니다. 예를 들어 0000은 첫 번째 볼륨이고 000F는 16번째 볼륨입니다. 이 예제에서 ID가 0000인 개체 저장소는 에 해당합니다
/var/local/rangedb/0장치 이름이 sdc이고 크기가 107GB인 경우
-
-
장애가 발생한 스토리지 노드에 로그인:
-
다음 명령을 입력합니다.
ssh admin@grid_node_IP -
에 나열된 암호를 입력합니다
Passwords.txt파일. -
루트로 전환하려면 다음 명령을 입력합니다.
su - -
에 나열된 암호를 입력합니다
Passwords.txt파일.
루트로 로그인하면 프롬프트가 에서 변경됩니다
$를 선택합니다#. -
-
다음 스크립트를 실행하여 장애가 발생한 스토리지 볼륨을 마운트 해제합니다.
sn-unmount-volume object_store_ID를 클릭합니다
object_store_ID실패한 스토리지 볼륨의 ID입니다. 예를 들어, 를 지정합니다0ID 0000이 있는 개체 저장소의 명령 -
메시지가 표시되면 * y * 를 눌러 스토리지 볼륨 0에 따라 Cassandra 서비스를 중지합니다.
Cassandra 서비스가 이미 중지되어 있으면 메시지가 표시되지 않습니다. Cassandra 서비스는 볼륨 0에만 중지됩니다. root@Storage-180:~/var/local/tmp/storage~ # sn-unmount-volume 0 Services depending on storage volume 0 (cassandra) aren't down. Services depending on storage volume 0 must be stopped before running this script. Stop services that require storage volume 0 [y/N]? y Shutting down services that require storage volume 0. Services requiring storage volume 0 stopped. Unmounting /var/local/rangedb/0 /var/local/rangedb/0 is unmounted.
몇 초 후 볼륨이 마운트 해제됩니다. 프로세스의 각 단계를 나타내는 메시지가 나타납니다. 마지막 메시지는 볼륨이 마운트 해제되었음을 나타냅니다.
-
볼륨이 사용 중이어서 마운트 해제에 실패하면 를 사용하여 마운트 해제를 강제 실행할 수 있습니다
--use-umountof옵션:
를 사용하여 마운트 해제 강제 실행 --use-umountof옵션을 사용하면 볼륨을 사용하는 프로세스 또는 서비스가 예기치 않게 동작하거나 충돌될 수 있습니다.root@Storage-180:~ # sn-unmount-volume --use-umountof /var/local/rangedb/2 Unmounting /var/local/rangedb/2 using umountof /var/local/rangedb/2 is unmounted. Informing LDR service of changes to storage volumes