

Analisando um evento de desempenho dinâmico em um cluster em uma configuração do MetroCluster
 Sugerir alterações
Sugerir alterações
Você pode usar o Unified Manager para analisar o cluster em uma configuração do MetroCluster na qual um evento de desempenho foi detetado. Você pode identificar o nome do cluster, o tempo de deteção de eventos e as cargas de trabalho bully e vitima envolvidas.
Antes de começar
-
Tem de ter a função Operador, Administrador de aplicações ou Administrador de armazenamento.
-
Deve haver eventos de desempenho novos, reconhecidos ou obsoletos para uma configuração do MetroCluster.
-
Ambos os clusters na configuração do MetroCluster precisam ser monitorados pela mesma instância do Unified Manager.
Passos
-
Exiba a página Detalhes do evento para exibir informações sobre o evento.
-
Revise a descrição do evento para ver os nomes das cargas de trabalho envolvidas e o número de cargas de trabalho envolvidas.
Neste exemplo, o ícone recursos do MetroCluster é vermelho, indicando que os recursos do MetroCluster estão em disputa. Posicione o cursor sobre o ícone para exibir uma descrição do ícone.

-
Anote o nome do cluster e o tempo de deteção de eventos, que pode ser usado para analisar eventos de desempenho no cluster de parceiros.
-
Nos gráficos, revise as cargas de trabalho vítima para confirmar que seus tempos de resposta são maiores do que o limite de desempenho.
Neste exemplo, a carga de trabalho da vítima é exibida no texto do cursor. Os gráficos de latência exibem, em alto nível, um padrão de latência consistente para as cargas de trabalho da vítima envolvidas. Mesmo que a latência anormal das cargas de trabalho da vítima tenha acionado o evento, um padrão de latência consistente pode indicar que as cargas de trabalho estão com desempenho dentro do intervalo esperado, mas que um pico de e/S aumentou a latência e acionou o evento.
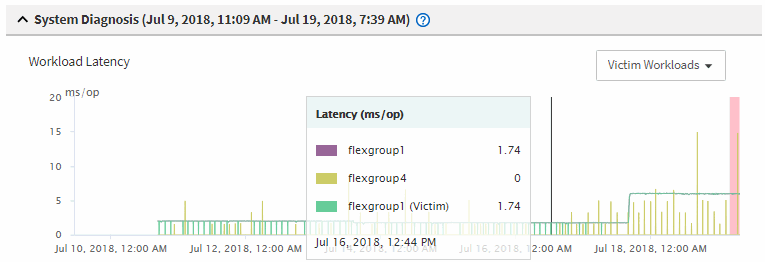
Se você instalou recentemente um aplicativo em um cliente que acessa esses workloads de volume e esse aplicativo enviar uma grande quantidade de e/S para eles, talvez você esteja antecipando o aumento das latências. Se a latência das cargas de trabalho retornar dentro do intervalo esperado, o estado do evento muda para obsoleto e permanece nesse estado por mais de 30 minutos, você provavelmente pode ignorar o evento. Se o evento estiver em andamento e permanecer no novo estado, você poderá investigá-lo ainda mais para determinar se outros problemas causaram o evento.
-
No gráfico de taxa de transferência de carga de trabalho, selecione Bully cargas de trabalho para exibir as cargas de trabalho bully.
A presença de cargas de trabalho bully indica que o evento pode ter sido causado por uma ou mais cargas de trabalho no cluster local que sobreutiliza os recursos do MetroCluster. As cargas de trabalho bully têm um alto desvio na taxa de transferência de gravação (MB/s).
Esse gráfico exibe, em alto nível, o padrão de taxa de transferência de gravação (MB/s) para as cargas de trabalho. Você pode revisar o padrão de MB/s de gravação para identificar taxa de transferência anormal, o que pode indicar que uma carga de trabalho está sobreutilizando os recursos do MetroCluster.
Se não houver workloads com bully envolvidos no evento, o evento pode ter sido causado por um problema de integridade com o link entre os clusters ou um problema de desempenho no cluster de parceiros. Você pode usar o Unified Manager para verificar a integridade dos dois clusters em uma configuração do MetroCluster. Você também pode usar o Unified Manager para verificar e analisar eventos de desempenho no cluster de parceiros.