

Verificação do design
 Sugerir alterações
Sugerir alterações
O design de segunda geração da solução BeeGFS on NetApp foi verificado usando três perfis de configuração de componentes básicos.
Os perfis de configuração incluem o seguinte:
-
Um componente básico único, incluindo gerenciamento, metadados e serviços de storage do BeeGFS.
-
Metadados do BeeGFS, além de um componente básico de storage.
-
Componente básico somente de storage do BeeGFS.
Os componentes básicos foram anexados a dois switches NVIDIA Quantum InfiniBand (MQM8700). Dez clientes BeeGFS também foram anexados aos switches InfiniBand e usados para executar utilitários de benchmark sintéticos.
A figura a seguir mostra a configuração BeeGFS usada para validar a solução BeeGFS no NetApp.

Distribuição de arquivos BeeGFS
Um benefício dos sistemas de arquivos paralelos é a capacidade de distribuir arquivos individuais entre vários destinos de storage, o que pode representar volumes no mesmo ou em diferentes sistemas de storage subjacentes.
No BeeGFS, você pode configurar a distribuição por diretório e por arquivo para controlar o número de destinos usados para cada arquivo e controlar o tamanho do bloco (ou tamanho do bloco) usado para cada faixa de arquivo. Essa configuração permite que o sistema de arquivos ofereça suporte a diferentes tipos de cargas de trabalho e perfis de e/S sem a necessidade de reconfigurar ou reiniciar serviços. Você pode aplicar configurações de stripe usando a beegfs-ctl ferramenta de linha de comando ou com aplicativos que usam a API de striping. Para obter mais informações, consulte a documentação do BeeGFS para "Riscar" e "Striping API".
Para alcançar o melhor desempenho, padrões de faixa foram ajustados ao longo dos testes, e os parâmetros usados para cada teste são observados.
Testes de largura de banda IOR: Vários clientes
Os testes de largura de banda IOR usaram o OpenMPI para executar trabalhos paralelos da ferramenta de gerador de e/S sintética IOR (disponível a partir de "HPC GitHub") em todos os nós de cliente 10 para um ou mais blocos de construção BeeGFS. Salvo indicação em contrário:
-
Todos os testes usaram I/o direto com um tamanho de transferência de 1MiB.
-
A distribuição de arquivos BeeGFS foi definida como um tamanho de 1MB chunksize e um destino por arquivo.
Os seguintes parâmetros foram utilizados para IOR com a contagem de segmentos ajustada para manter o tamanho do arquivo agregado para 5TiB para um bloco de construção e 40TiB para três blocos de construção.
mpirun --allow-run-as-root --mca btl tcp -np 48 -map-by node -hostfile 10xnodes ior -b 1024k --posix.odirect -e -t 1024k -s 54613 -z -C -F -E -k
A figura a seguir mostra os resultados do teste de IOR com um único componente básico do BeeGFS (gerenciamento, metadados e storage).
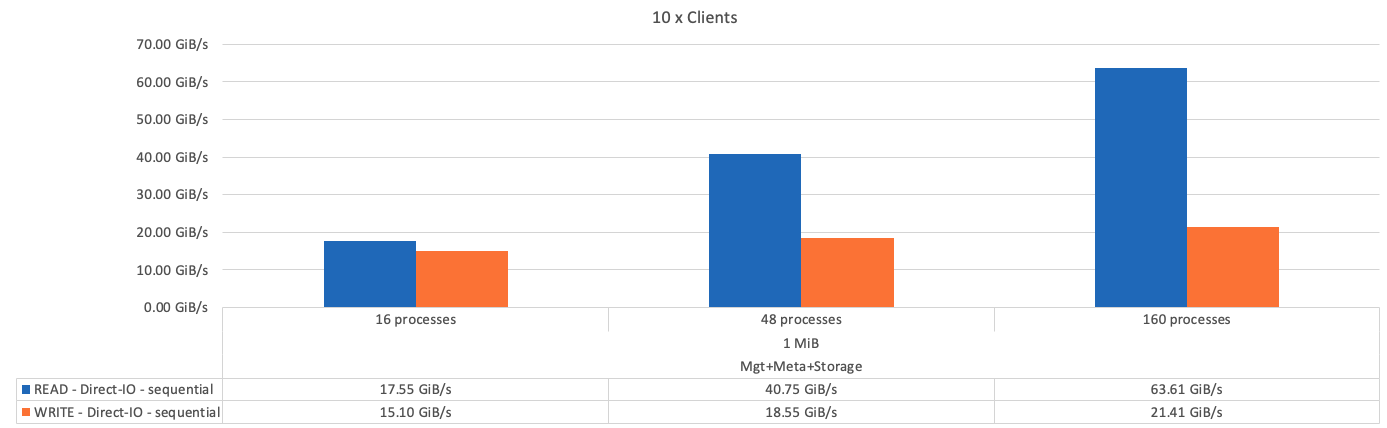
A figura a seguir mostra os resultados do teste de IOR com um único componente básico de storage e metadados do BeeGFS.
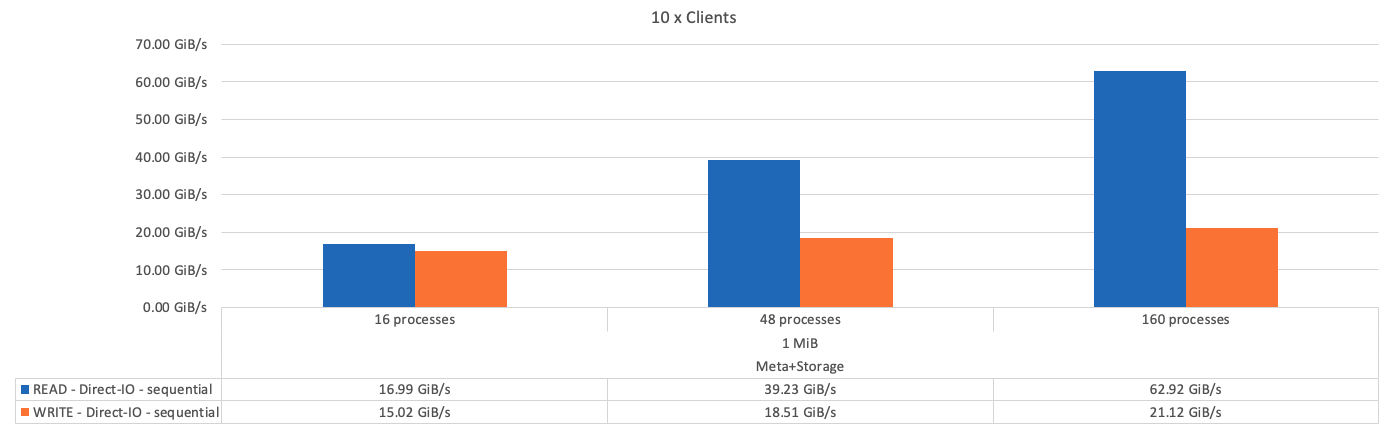
A figura a seguir mostra os resultados do teste de IOR com um único componente básico somente de storage do BeeGFS.
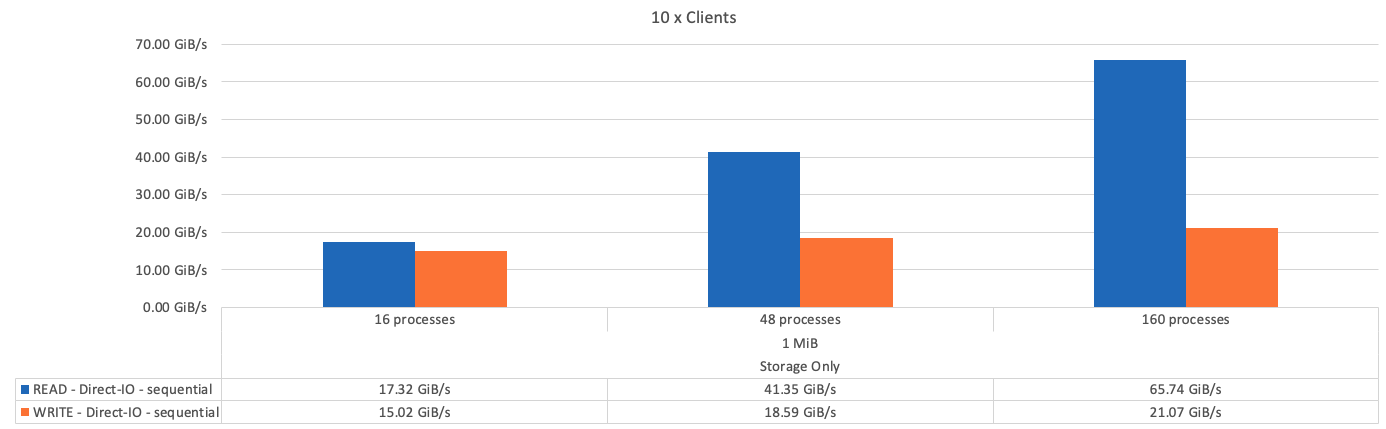
A figura a seguir mostra os resultados do teste de IOR com três componentes básicos do BeeGFS.
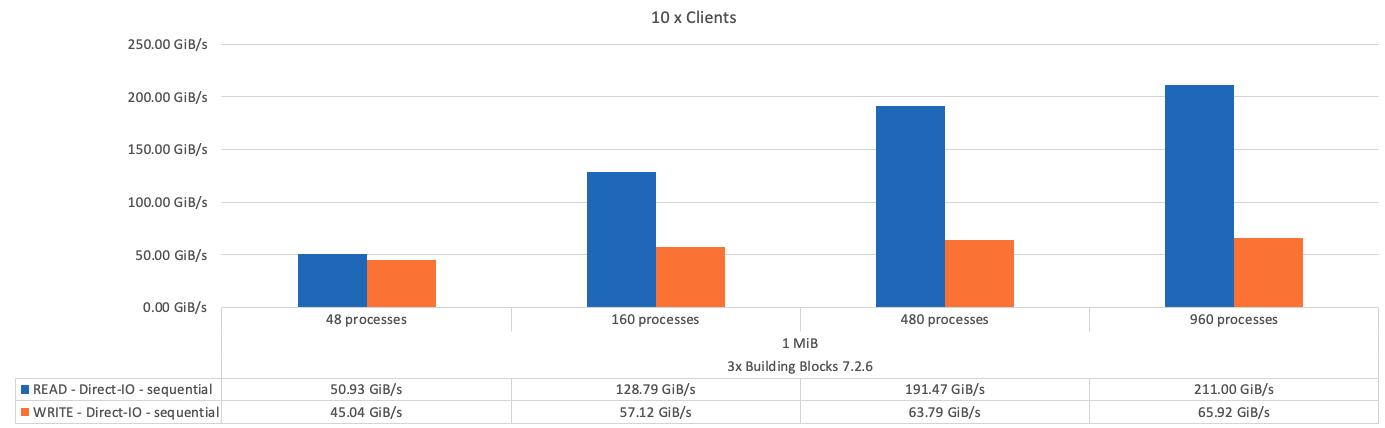
Como esperado, a diferença de desempenho entre o componente básico e o componente básico de armazenamento de metadados subsequentes é insignificante. Comparar os metadados e o componente básico de armazenamento e um componente básico somente de armazenamento mostra um ligeiro aumento no desempenho de leitura devido às unidades adicionais usadas como destinos de armazenamento. No entanto, não há diferença significativa no desempenho de gravação. Para obter um desempenho mais alto, você pode adicionar vários blocos de construção juntos para dimensionar o desempenho de forma linear.
Testes de largura de banda IOR: Cliente único
O teste de largura de banda IOR usou o OpenMPI para executar vários processos IOR usando um único servidor GPU de alto desempenho para explorar o desempenho possível para um único cliente.
Este teste também compara o comportamento de releitura e o desempenho do BeeGFS quando o cliente está configurado para usar o cache de página do kernel Linux (tuneFileCacheType = native) versus a configuração padrão buffered.
O modo de cache nativo usa o cache de página do kernel Linux no cliente, permitindo que as operações de releitura venham da memória local em vez de serem retransmitidas pela rede.
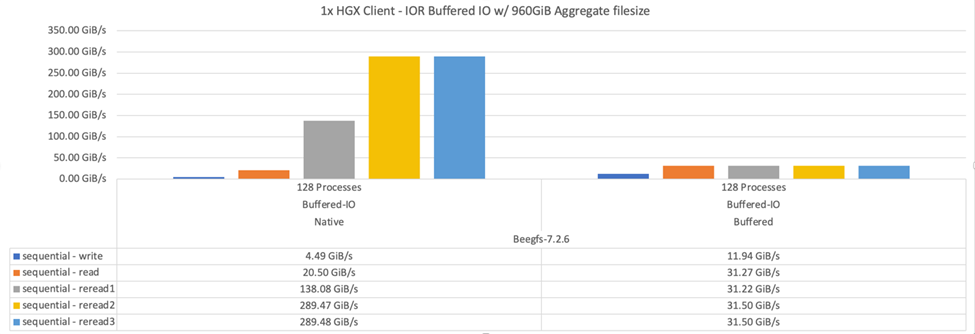
O diagrama a seguir mostra os resultados do teste de IOR com três componentes básicos do BeeGFS e um único cliente.

|
BeeGFS striping para esses testes foi definido para um tamanho de 1MB chunksize com oito alvos por arquivo. |
Embora o desempenho de gravação e leitura inicial seja maior usando o modo de buffer padrão, para cargas de trabalho que releram os mesmos dados várias vezes, um aumento de desempenho significativo é observado no modo de armazenamento em cache nativo. Essa performance de releitura aprimorada é importante para workloads como o deep learning que releiam o mesmo conjunto de dados várias vezes em várias épocas.
Teste de desempenho de metadados
Os testes de performance de metadados usaram a ferramenta MDTest (incluída como parte da IOR) para medir a performance de metadados do BeeGFS. Os testes utilizaram OpenMPI para executar trabalhos paralelos em todos os dez nós de cliente.
Os seguintes parâmetros foram utilizados para executar o teste de benchmark com o número total de processos dimensionados de 10 a 320 na etapa de 2x e com um tamanho de arquivo de 4K.
mpirun -h 10xnodes –map-by node np $processes mdtest -e 4k -w 4k -i 3 -I 16 -z 3 -b 8 -u
A performance dos metadados foi medida primeiro com um e dois componentes básicos de storage e metadados para mostrar como a performance é dimensionada com a adição de componentes básicos adicionais.
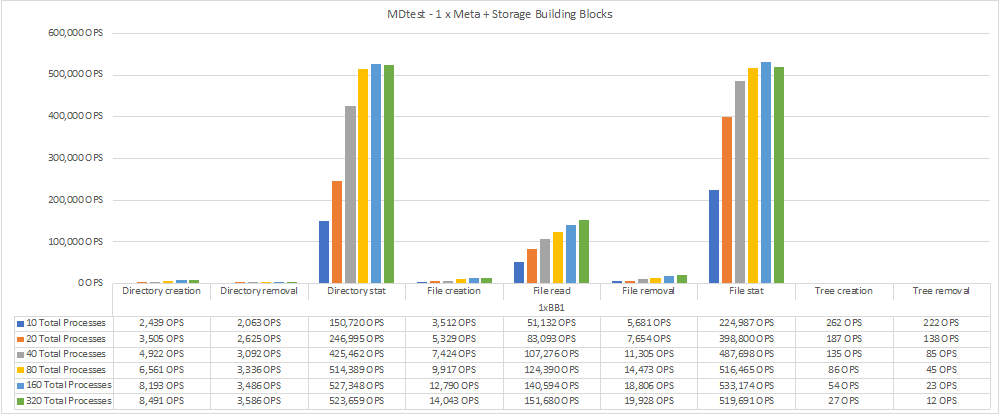
O diagrama a seguir mostra os resultados do MDTest com os componentes básicos de storage e metadados do BeeGFS.
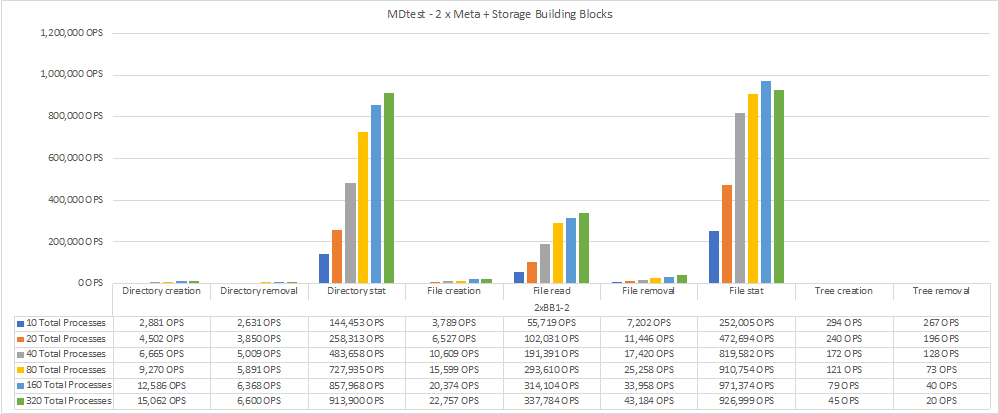
O diagrama a seguir mostra os resultados do MDTest com dois componentes básicos de storage e metadados do BeeGFS.
Validação funcional
Como parte da validação desta arquitetura, o NetApp executou vários testes funcionais, incluindo os seguintes:
-
Falha em uma única porta InfiniBand de cliente desativando a porta do switch.
-
Falha em uma única porta InfiniBand de servidor desativando a porta do switch.
-
Acionando uma desativação imediata do servidor usando o BMC.
-
Colocação graciosa de um nó em standby e falha no serviço para outro nó.
-
Colocando um nó de volta on-line e falhando serviços de volta para o nó original.
-
Desligar um dos switches InfiniBand usando a PDU. Todos os testes foram realizados enquanto o teste de estresse estava em andamento com o
sysSessionChecksEnabled: falseparâmetro definido nos clientes BeeGFS. Não foram observados erros ou interrupções na e/S.
|
|
Há um problema conhecido (consulte a "Changelog") quando as conexões RDMA cliente/servidor BeeGFS são interrompidas inesperadamente, seja pela perda da interface principal (conforme definido na connInterfacesFile) ou por falha de um servidor BeeGFS; e/S cliente ativo pode travar por até dez minutos antes de retomar. Esse problema não ocorre quando os nós BeeGFS são colocados graciosamente dentro e fora de espera para manutenção planejada ou se o TCP estiver em uso.
|
Validação do NVIDIA DGX SuperPOD e BasePOD
A NetApp validou uma solução de storage para NVIDIAs DGX A100 SuperPOD usando um sistema de arquivos BeeGFS semelhante, que consiste em três componentes básicos com os metadados e o perfil de configuração de storage aplicado. O esforço de qualificação envolveu o teste da solução descrita por esse NVA com vinte servidores de GPU DGX A100 que executam diversos benchmarks de storage, aprendizado de máquina e deep learning. Com base na validação estabelecida pelo SuperPOD DGX A100 da NVIDIA, a solução BeeGFS on NetApp foi aprovada para os sistemas DGX SuperPOD H100, H200 e B200. Essa extensão se baseia no cumprimento dos requisitos de sistema e de benchmark estabelecidos anteriormente, conforme validado com o NVIDIA DGX A100.
Para obter mais informações, "NVIDIA DGX SuperPOD com NetApp" consulte e "NVIDIA DGX BasePOD".