TR-4920: Centro de dados FlexPod com continuidade de Negócios NetApp SnapMirror e ONTAP 9.10
 Sugerir alterações
Sugerir alterações
Jyh-shing Chen, NetApp
Introdução
Solução FlexPod
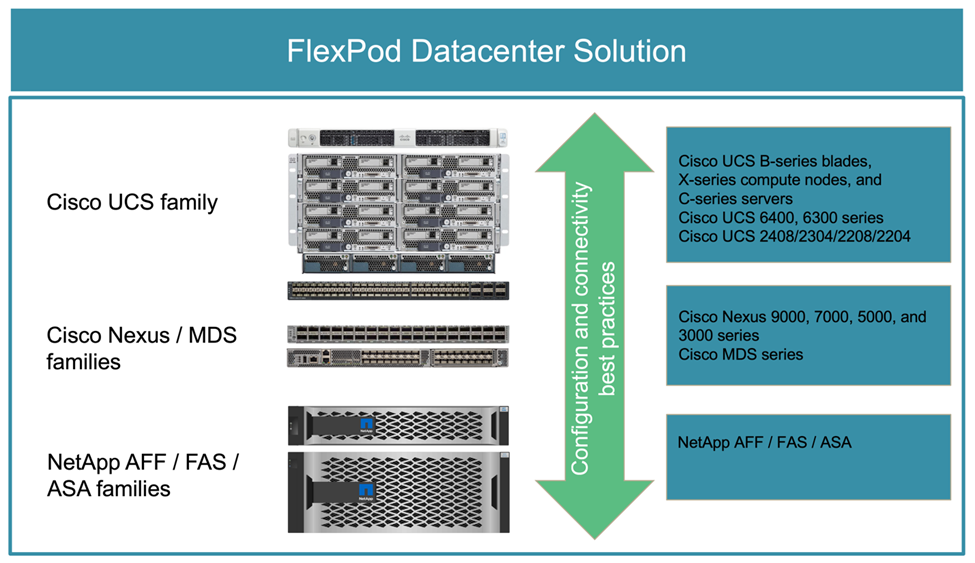
O FlexPod é uma arquitetura de data center de infraestrutura convergente prática recomendada que inclui os seguintes componentes do Cisco e do NetApp:
-
Sistema de computação unificada da Cisco (Cisco UCS)
-
Famílias de switches Cisco Nexus e MDS
-
Sistemas NetApp FAS, NetApp AFF e NetApp All SAN Array (ASA)
A figura a seguir mostra alguns dos componentes usados para criar soluções FlexPod. Esses componentes são conectados e configurados de acordo com as práticas recomendadas do Cisco e do NetApp para fornecer uma plataforma ideal para executar uma variedade de workloads empresariais com confiança.
Um grande portfólio de Cisco Validated designs (CVDs) e NetApp Verified Architectures (NVAs) estão disponíveis. Esses CVDs e NVAs cobrem todas as principais cargas de trabalho de data center e são o resultado de colaborações e inovações contínuas entre a NetApp e a Cisco em soluções FlexPod.
Incorporando testes e validações extensivos em seu processo de criação, os CVDs e NVAs da FlexPod fornecem designs de arquitetura de solução de referência e guias de implantação passo a passo para ajudar parceiros e clientes a implantar e adotar soluções da FlexPod. Ao usar esses CVDs e NVAs como guias de projeto e implementação, as empresas podem reduzir riscos, reduzir o tempo de inatividade da solução e aumentar a disponibilidade, escalabilidade, flexibilidade e segurança das soluções FlexPod que implantam.
Cada uma das famílias de componentes do FlexPod mostradas (Cisco UCS, switches Cisco Nexus/MDS e storage NetApp) oferece opções de plataforma e recursos para escalar a infraestrutura para cima ou para baixo, oferecendo suporte aos recursos e funcionalidades necessários nas práticas recomendadas de configuração e conectividade do FlexPod. O FlexPod também pode fazer escalabilidade horizontal para ambientes que exigem várias implantações consistentes com a implementação de stacks FlexPod adicionais.
Recuperação de desastres e continuidade dos negócios
Existem vários métodos que as empresas podem adotar para garantir que possam recuperar rapidamente seus aplicativos e serviços de dados de desastres. Ter um plano de recuperação de desastres (DR) e continuidade dos negócios (BC), implementar uma solução que atenda aos objetivos de negócios e realizar testes regulares dos cenários de desastre permite que as empresas se recuperem de um desastre e continuem serviços comerciais críticos após uma situação de desastre.
As empresas podem ter diferentes requisitos de DR e BC para diferentes tipos de aplicativos e serviços de dados. Alguns aplicativos e dados podem não ser necessários durante uma situação de emergência ou desastre, enquanto outros podem precisar estar continuamente disponíveis para atender aos requisitos empresariais.
Para aplicativos de missão crítica e serviços de dados que possam interromper seus negócios quando não estiverem disponíveis, uma avaliação cuidadosa é necessária para responder a perguntas como o tipo de cenários de manutenção e desastre que a empresa precisa considerar, a quantidade de dados que a empresa pode perder em caso de desastre e a rapidez com que a recuperação pode e deve ocorrer.
Para empresas que dependem de serviços de dados para geração de receita, os serviços de dados podem precisar ser protegidos por uma solução que pode suportar não apenas vários cenários de ponto único de falha, mas também um cenário de desastre de interrupção no local para fornecer operações de negócios contínuas.
Objetivo do ponto de restauração e objetivo de tempo de recuperação
O objetivo do ponto de restauração (RPO) mede a quantidade de dados que você pode perder em termos de tempo ou o ponto em que pode recuperar os dados. Com um plano de backup diário, uma empresa pode perder um dia de dados, porque as alterações feitas nos dados desde o último backup podem ser perdidas em um desastre. Para serviços de dados essenciais aos negócios e essenciais, é possível que você precise de um RPO zero e de um plano e infraestruturas associados para proteger os dados sem perda de dados.
O objetivo de tempo de recuperação (rto) mede quanto tempo você pode se dar ao luxo de não ter os dados disponíveis ou a rapidez com que os serviços de dados precisam ser restaurados. Por exemplo, uma empresa pode ter uma implementação de backup e recuperação que usa fitas tradicionais para certos conjuntos de dados devido ao seu tamanho. Como resultado, para restaurar os dados das fitas de backup, pode levar várias horas ou até dias se houver uma falha de infraestrutura. As considerações de tempo também devem incluir tempo para fazer backup da infraestrutura, além de restaurar dados. Para serviços de dados essenciais, você pode exigir um rto muito baixo e, assim, só pode tolerar um tempo de failover de segundos ou minutos para colocar os serviços de dados on-line de volta para continuidade dos negócios com rapidez.
SM-BC
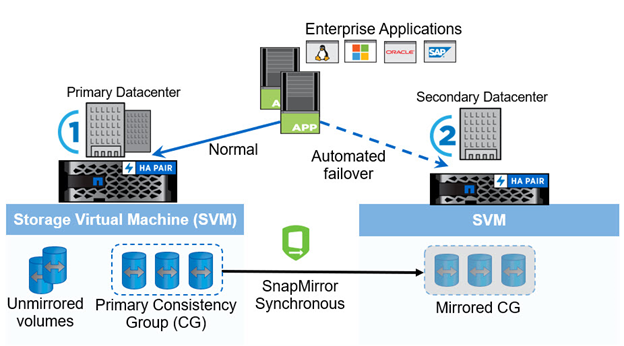
A partir do ONTAP 9.8, você pode proteger workloads SAN para failover transparente de aplicações com o NetApp SM-BC. Você pode criar relacionamentos de grupo de consistência entre dois clusters AFF ou dois clusters ASA para replicação de dados a fim de alcançar RPO zero e rto quase zero.
A solução SM-BC replica dados usando a tecnologia SnapMirror Synchronous em uma rede IP. Ele fornece granularidade no nível da aplicação e failover automático para proteger seus serviços de dados essenciais aos negócios, como Microsoft SQL Server, Oracle, etc., com LUNs SAN baseados em protocolo iSCSI ou FC. Um Mediador ONTAP implantado em um terceiro local monitora a solução SM-BC e permite o failover automático em caso de desastre no local.
Um grupo de consistência (CG) é uma coleção de volumes FlexVol que oferece uma garantia de consistência de ordem de gravação para o workload do aplicativo que precisa ser protegido para manter a continuidade dos negócios. Ele permite cópias Snapshot simultâneas de uma coleção de volumes consistentes com falhas. Uma relação SnapMirror, também conhecida como relação CG, é estabelecida entre um CG de origem e um CG de destino. O grupo de volumes escolhidos para fazer parte de um CG pode ser mapeado para uma instância de aplicativo, um grupo de instâncias de aplicativos ou para uma solução completa. Além disso, os relacionamentos de grupo de consistência SM-BC podem ser criados ou excluídos sob demanda com base em requisitos e mudanças de negócios.
Conforme ilustrado na figura a seguir, os dados no grupo de consistência são replicados para um segundo cluster do ONTAP para recuperação de desastres e continuidade dos negócios. As aplicações têm conectividade com os LUNs nos dois clusters do ONTAP. A e/S normalmente é servida pelo cluster primário e é retomada automaticamente do cluster secundário se um desastre ocorrer no primário. Ao projetar uma solução SM-BC, as contagens de objetos suportados para as relações CG (por exemplo, um máximo de 20 CGS e máximo de 200 endpoints) devem ser observadas para evitar exceder os limites suportados.