

Parte 2 - Aproveitando o AWS Amazon FSx for NetApp ONTAP (FSx ONTAP) como uma fonte de dados para treinamento de modelos no SageMaker
 Sugerir alterações
Sugerir alterações
Este artigo é um tutorial sobre como usar o Amazon FSx for NetApp ONTAP (FSx ONTAP) para treinar modelos PyTorch no SageMaker, especificamente para um projeto de classificação de qualidade de pneus.
Introdução
Este tutorial oferece um exemplo prático de um projeto de classificação de visão computacional, proporcionando experiência prática na construção de modelos de ML que utilizam o FSx ONTAP como fonte de dados no ambiente SageMaker. O projeto se concentra no uso do PyTorch, uma estrutura de aprendizado profundo, para classificar a qualidade dos pneus com base em imagens de pneus. Ele enfatiza o desenvolvimento de modelos de aprendizado de máquina usando o FSx ONTAP como fonte de dados no Amazon SageMaker.
O que é FSx ONTAP
O Amazon FSx ONTAP é de fato uma solução de armazenamento totalmente gerenciada oferecida pela AWS. Ele aproveita o sistema de arquivos ONTAP da NetApp para fornecer armazenamento confiável e de alto desempenho. Com suporte para protocolos como NFS, SMB e iSCSI, ele permite acesso direto de diferentes instâncias de computação e contêineres. O serviço foi projetado para oferecer desempenho excepcional, garantindo operações de dados rápidas e eficientes. Ele também oferece alta disponibilidade e durabilidade, garantindo que seus dados permaneçam acessíveis e protegidos. Além disso, a capacidade de armazenamento do Amazon FSx ONTAP é escalável, permitindo que você a ajuste facilmente de acordo com suas necessidades.
Pré-requisito
Ambiente de rede
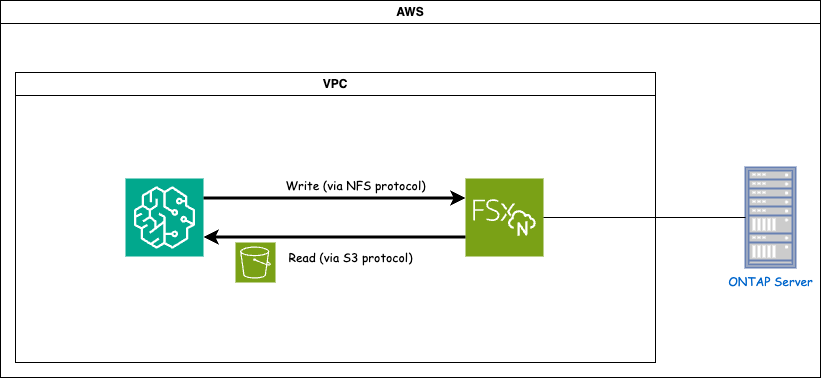
FSx ONTAP (Amazon FSx ONTAP) é um serviço de armazenamento da AWS. Ele inclui um sistema de arquivos em execução no sistema NetApp ONTAP e uma máquina virtual do sistema gerenciada pela AWS (SVM) que se conecta a ele. No diagrama fornecido, o servidor NetApp ONTAP gerenciado pela AWS está localizado fora da VPC. O SVM atua como intermediário entre o SageMaker e o sistema NetApp ONTAP , recebendo solicitações de operação do SageMaker e encaminhando-as para o armazenamento subjacente. Para acessar o FSx ONTAP, o SageMaker deve ser colocado na mesma VPC que a implantação do FSx ONTAP . Esta configuração garante a comunicação e o acesso aos dados entre o SageMaker e o FSx ONTAP.
Acesso a dados
Em cenários do mundo real, os cientistas de dados normalmente utilizam os dados existentes armazenados no FSx ONTAP para construir seus modelos de aprendizado de máquina. No entanto, para fins de demonstração, como o sistema de arquivos FSx ONTAP fica inicialmente vazio após a criação, é necessário carregar manualmente os dados de treinamento. Isso pode ser feito montando o FSx ONTAP como um volume no SageMaker. Depois que o sistema de arquivos for montado com sucesso, você poderá carregar seu conjunto de dados no local montado, tornando-o acessível para treinar seus modelos no ambiente SageMaker. Essa abordagem permite que você aproveite a capacidade de armazenamento e os recursos do FSx ONTAP enquanto trabalha com o SageMaker para desenvolvimento e treinamento de modelos.
O processo de leitura de dados envolve a configuração do FSx ONTAP como um bucket S3 privado. Para aprender as instruções detalhadas de configuração, consulte"Parte 1 - Integrando o Amazon FSx for NetApp ONTAP (FSx ONTAP) como um bucket S3 privado no AWS SageMaker"
Visão geral da integração
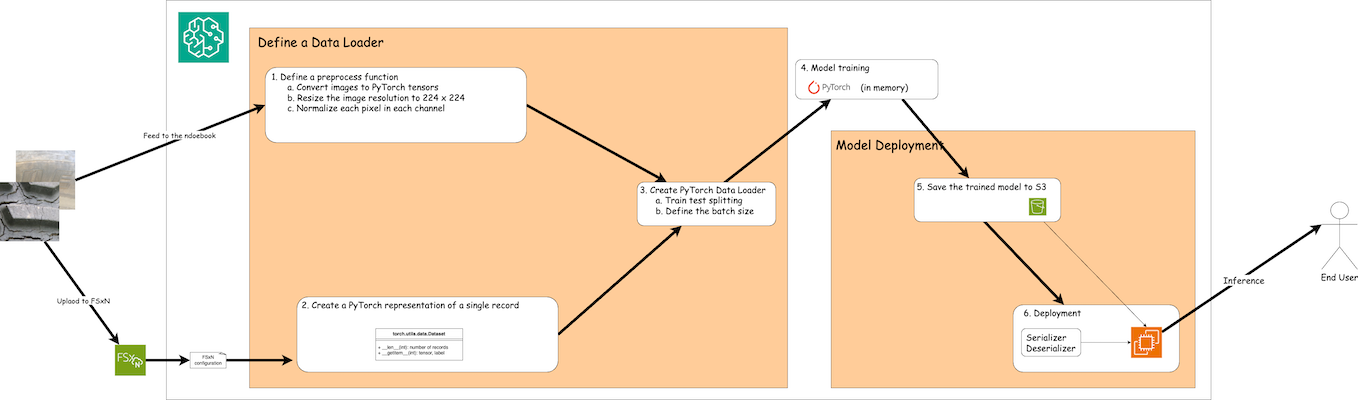
O fluxo de trabalho de uso de dados de treinamento no FSx ONTAP para criar um modelo de aprendizado profundo no SageMaker pode ser resumido em três etapas principais: definição do carregador de dados, treinamento do modelo e implantação. Em um nível alto, essas etapas formam a base de um pipeline de MLOps. No entanto, cada etapa envolve várias subetapas detalhadas para uma implementação abrangente. Essas subetapas abrangem várias tarefas, como pré-processamento de dados, divisão de conjuntos de dados, configuração de modelo, ajuste de hiperparâmetros, avaliação de modelo e implantação de modelo. Essas etapas garantem um processo completo e eficaz para criar e implantar modelos de aprendizado profundo usando dados de treinamento do FSx ONTAP no ambiente SageMaker.
Integração passo a passo
Loader de dados
Para treinar uma rede de aprendizado profundo PyTorch com dados, um carregador de dados é criado para facilitar a alimentação de dados. O carregador de dados não apenas define o tamanho do lote, mas também determina o procedimento de leitura e pré-processamento de cada registro dentro do lote. Ao configurar o carregador de dados, podemos lidar com o processamento de dados em lotes, permitindo o treinamento da rede de aprendizado profundo.
O carregador de dados consiste em 3 partes.
Função de pré-processamento
from torchvision import transforms
preprocess = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((224,224)),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])O trecho de código acima demonstra a definição de transformações de pré-processamento de imagem usando o módulo torchvision.transforms. Neste tutorial, o objeto de pré-processo é criado para aplicar uma série de transformações. Primeiro, a transformação ToTensor() converte a imagem em uma representação tensorial. Posteriormente, a transformação Resize224,224 redimensiona a imagem para um tamanho fixo de 224x224 pixels. Por fim, a transformação Normalize() normaliza os valores do tensor subtraindo a média e dividindo pelo desvio padrão ao longo de cada canal. Os valores de média e desvio padrão usados para normalização são comumente empregados em modelos de redes neurais pré-treinados. No geral, esse código prepara os dados da imagem para processamento posterior ou entrada em um modelo pré-treinado, convertendo-os em um tensor, redimensionando-os e normalizando os valores de pixels.
A classe de conjunto de dados PyTorch
import torch
from io import BytesIO
from PIL import Image
class FSxNImageDataset(torch.utils.data.Dataset):
def __init__(self, bucket, prefix='', preprocess=None):
self.image_keys = [
s3_obj.key
for s3_obj in list(bucket.objects.filter(Prefix=prefix).all())
]
self.preprocess = preprocess
def __len__(self):
return len(self.image_keys)
def __getitem__(self, index):
key = self.image_keys[index]
response = bucket.Object(key)
label = 1 if key[13:].startswith('defective') else 0
image_bytes = response.get()['Body'].read()
image = Image.open(BytesIO(image_bytes))
if image.mode == 'L':
image = image.convert('RGB')
if self.preprocess is not None:
image = self.preprocess(image)
return image, labelEsta classe fornece funcionalidade para obter o número total de registros no conjunto de dados e define o método de leitura de dados para cada registro. Dentro da função getitem, o código utiliza o objeto de bucket boto3 S3 para recuperar os dados binários do FSx ONTAP. O estilo de código para acessar dados do FSx ONTAP é semelhante à leitura de dados do Amazon S3. A explicação a seguir se aprofunda no processo de criação do objeto privado S3 bucket.
FSx ONTAP como um repositório S3 privado
seed = 77 # Random seed
bucket_name = '<Your ONTAP bucket name>' # The bucket name in ONTAP
aws_access_key_id = '<Your ONTAP bucket key id>' # Please get this credential from ONTAP
aws_secret_access_key = '<Your ONTAP bucket access key>' # Please get this credential from ONTAP
fsx_endpoint_ip = '<Your FSx ONTAP IP address>' # Please get this IP address from FSXNimport boto3
# Get session info
region_name = boto3.session.Session().region_name
# Initialize Fsxn S3 bucket object
# --- Start integrating SageMaker with FSXN ---
# This is the only code change we need to incorporate SageMaker with FSXN
s3_client: boto3.client = boto3.resource(
's3',
region_name=region_name,
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key,
use_ssl=False,
endpoint_url=f'http://{fsx_endpoint_ip}',
config=boto3.session.Config(
signature_version='s3v4',
s3={'addressing_style': 'path'}
)
)
# s3_client = boto3.resource('s3')
bucket = s3_client.Bucket(bucket_name)
# --- End integrating SageMaker with FSXN ---Para ler dados do FSx ONTAP no SageMaker, é criado um manipulador que aponta para o armazenamento do FSx ONTAP usando o protocolo S3. Isso permite que o FSx ONTAP seja tratado como um bucket S3 privado. A configuração do manipulador inclui a especificação do endereço IP do FSx ONTAP SVM, o nome do bucket e as credenciais necessárias. Para uma explicação abrangente sobre como obter esses itens de configuração, consulte o documento em"Parte 1 - Integrando o Amazon FSx for NetApp ONTAP (FSx ONTAP) como um bucket S3 privado no AWS SageMaker" .
No exemplo mencionado acima, o objeto bucket é usado para instanciar o objeto do conjunto de dados PyTorch. O objeto dataset será explicado com mais detalhes na seção subsequente.
O Loader de dados PyTorch
from torch.utils.data import DataLoader
torch.manual_seed(seed)
# 1. Hyperparameters
batch_size = 64
# 2. Preparing for the dataset
dataset = FSxNImageDataset(bucket, 'dataset/tyre', preprocess=preprocess)
train, test = torch.utils.data.random_split(dataset, [1500, 356])
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)No exemplo fornecido, um tamanho de lote de 64 é especificado, indicando que cada lote conterá 64 registros. Combinando a classe Dataset do PyTorch, a função de pré-processamento e o tamanho do lote de treinamento, obtemos o carregador de dados para treinamento. Este carregador de dados facilita o processo de iteração pelo conjunto de dados em lotes durante a fase de treinamento.
Treinamento de modelo
from torch import nn
class TyreQualityClassifier(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3,32,(3,3)),
nn.ReLU(),
nn.Conv2d(32,32,(3,3)),
nn.ReLU(),
nn.Conv2d(32,64,(3,3)),
nn.ReLU(),
nn.Flatten(),
nn.Linear(64*(224-6)*(224-6),2)
)
def forward(self, x):
return self.model(x)import datetime
num_epochs = 2
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = TyreQualityClassifier()
fn_loss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
model.to(device)
for epoch in range(num_epochs):
for idx, (X, y) in enumerate(data_loader):
X = X.to(device)
y = y.to(device)
y_hat = model(X)
loss = fn_loss(y_hat, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
current_time = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print(f"Current Time: {current_time} - Epoch [{epoch+1}/{num_epochs}]- Batch [{idx + 1}] - Loss: {loss}", end='\r')Este código implementa um processo de treinamento padrão do PyTorch. Ele define um modelo de rede neural chamado TyreQualityClassifier usando camadas convolucionais e uma camada linear para classificar a qualidade dos pneus. O loop de treinamento itera sobre lotes de dados, calcula a perda e atualiza os parâmetros do modelo usando retropropagação e otimização. Além disso, ele imprime a hora atual, época, lote e perda para fins de monitoramento.
Implantação do modelo
Implantação
import io
import os
import tarfile
import sagemaker
# 1. Save the PyTorch model to memory
buffer_model = io.BytesIO()
traced_model = torch.jit.script(model)
torch.jit.save(traced_model, buffer_model)
# 2. Upload to AWS S3
sagemaker_session = sagemaker.Session()
bucket_name_default = sagemaker_session.default_bucket()
model_name = f'tyre_quality_classifier.pth'
# 2.1. Zip PyTorch model into tar.gz file
buffer_zip = io.BytesIO()
with tarfile.open(fileobj=buffer_zip, mode="w:gz") as tar:
# Add PyTorch pt file
file_name = os.path.basename(model_name)
file_name_with_extension = os.path.split(file_name)[-1]
tarinfo = tarfile.TarInfo(file_name_with_extension)
tarinfo.size = len(buffer_model.getbuffer())
buffer_model.seek(0)
tar.addfile(tarinfo, buffer_model)
# 2.2. Upload the tar.gz file to S3 bucket
buffer_zip.seek(0)
boto3.resource('s3') \
.Bucket(bucket_name_default) \
.Object(f'pytorch/{model_name}.tar.gz') \
.put(Body=buffer_zip.getvalue())O código salva o modelo PyTorch no Amazon S3 porque o SageMaker exige que o modelo seja armazenado no S3 para implantação. Ao carregar o modelo no Amazon S3, ele se torna acessível ao SageMaker, permitindo a implantação e a inferência no modelo implantado.
import time
from sagemaker.pytorch import PyTorchModel
from sagemaker.predictor import Predictor
from sagemaker.serializers import IdentitySerializer
from sagemaker.deserializers import JSONDeserializer
class TyreQualitySerializer(IdentitySerializer):
CONTENT_TYPE = 'application/x-torch'
def serialize(self, data):
transformed_image = preprocess(data)
tensor_image = torch.Tensor(transformed_image)
serialized_data = io.BytesIO()
torch.save(tensor_image, serialized_data)
serialized_data.seek(0)
serialized_data = serialized_data.read()
return serialized_data
class TyreQualityPredictor(Predictor):
def __init__(self, endpoint_name, sagemaker_session):
super().__init__(
endpoint_name,
sagemaker_session=sagemaker_session,
serializer=TyreQualitySerializer(),
deserializer=JSONDeserializer(),
)
sagemaker_model = PyTorchModel(
model_data=f's3://{bucket_name_default}/pytorch/{model_name}.tar.gz',
role=sagemaker.get_execution_role(),
framework_version='2.0.1',
py_version='py310',
predictor_cls=TyreQualityPredictor,
entry_point='inference.py',
source_dir='code',
)
timestamp = int(time.time())
pytorch_endpoint_name = '{}-{}-{}'.format('tyre-quality-classifier', 'pt', timestamp)
sagemaker_predictor = sagemaker_model.deploy(
initial_instance_count=1,
instance_type='ml.p3.2xlarge',
endpoint_name=pytorch_endpoint_name
)Este código facilita a implantação de um modelo PyTorch no SageMaker. Ele define um serializador personalizado, TyreQualitySerializer, que pré-processa e serializa dados de entrada como um tensor PyTorch. A classe TyreQualityPredictor é um preditor personalizado que utiliza o serializador definido e um JSONDeserializer. O código também cria um objeto PyTorchModel para especificar o local S3 do modelo, a função do IAM, a versão do framework e o ponto de entrada para inferência. O código gera um registro de data e hora e constrói um nome de ponto de extremidade com base no modelo e no registro de data e hora. Por fim, o modelo é implantado usando o método deploy, especificando a contagem de instâncias, o tipo de instância e o nome do endpoint gerado. Isso permite que o modelo PyTorch seja implantado e fique acessível para inferência no SageMaker.
Inferência
image_object = list(bucket.objects.filter('dataset/tyre'))[0].get()
image_bytes = image_object['Body'].read()
with Image.open(with Image.open(BytesIO(image_bytes)) as image:
predicted_classes = sagemaker_predictor.predict(image)
print(predicted_classes)Este é o exemplo de uso do ponto de extremidade implantado para fazer a inferência.