

TR-4570: Soluções de armazenamento NetApp para Apache Spark: Arquitetura, casos de uso e resultados de desempenho
 Sugerir alterações
Sugerir alterações
Rick Huang, Karthikeyan Nagalingam, NetApp
Este documento se concentra na arquitetura do Apache Spark, nos casos de uso do cliente e no portfólio de armazenamento da NetApp relacionado à análise de big data e inteligência artificial (IA). Ele também apresenta vários resultados de testes usando ferramentas de IA, aprendizado de máquina (ML) e aprendizado profundo (DL) padrão do setor em relação a um sistema Hadoop típico para que você possa escolher a solução Spark apropriada. Para começar, você precisa de uma arquitetura Spark, componentes apropriados e dois modos de implantação (cluster e cliente).
Este documento também fornece casos de uso do cliente para resolver problemas de configuração e discute uma visão geral do portfólio de armazenamento da NetApp relevante para análise de big data e IA, ML e DL com Spark. Em seguida, finalizamos com os resultados dos testes derivados de casos de uso específicos do Spark e do portfólio de soluções NetApp Spark.
Desafios do cliente
Esta seção se concentra nos desafios dos clientes com análise de big data e IA/ML/DL em setores de crescimento de dados, como varejo, marketing digital, bancos, manufatura discreta, manufatura por processos, governo e serviços profissionais.
Desempenho imprevisível
Implantações tradicionais do Hadoop normalmente usam hardware comum. Para melhorar o desempenho, você deve ajustar a rede, o sistema operacional, o cluster Hadoop, os componentes do ecossistema, como o Spark, e o hardware. Mesmo se você ajustar cada camada, pode ser difícil atingir os níveis de desempenho desejados porque o Hadoop é executado em hardware comum que não foi projetado para alto desempenho em seu ambiente.
Falhas de mídia e nó
Mesmo em condições normais, o hardware comum está sujeito a falhas. Se um disco em um nó de dados falhar, o mestre do Hadoop, por padrão, considera esse nó como não íntegro. Em seguida, ele copia dados específicos desse nó pela rede, de réplicas para um nó íntegro. Esse processo torna os pacotes de rede mais lentos para qualquer tarefa do Hadoop. O cluster deve então copiar os dados novamente e remover os dados replicados em excesso quando o nó com problemas retornar a um estado saudável.
Bloqueio de fornecedor do Hadoop
Os distribuidores do Hadoop têm sua própria distribuição do Hadoop com seu próprio controle de versão, o que prende o cliente a essas distribuições. No entanto, muitos clientes exigem suporte para análises na memória que não vinculem o cliente a distribuições específicas do Hadoop. Eles precisam da liberdade de mudar as distribuições e ainda levar suas análises com eles.
Falta de suporte para mais de um idioma
Os clientes geralmente precisam de suporte para vários idiomas, além dos programas MapReduce Java, para executar seus trabalhos. Opções como SQL e scripts oferecem mais flexibilidade para obter respostas, mais opções para organizar e recuperar dados e maneiras mais rápidas de mover dados para uma estrutura de análise.
Dificuldade de uso
Já faz algum tempo que as pessoas reclamam que o Hadoop é difícil de usar. Embora o Hadoop tenha se tornado mais simples e poderoso a cada nova versão, essa crítica persiste. O Hadoop exige que você entenda os padrões de programação Java e MapReduce, um desafio para administradores de banco de dados e pessoas com conjuntos de habilidades tradicionais de script.
Estruturas e ferramentas complicadas
As equipes de IA corporativas enfrentam vários desafios. Mesmo com conhecimento especializado em ciência de dados, ferramentas e estruturas para diferentes ecossistemas e aplicativos de implantação podem não ser facilmente transferidas de um para outro. Uma plataforma de ciência de dados deve integrar-se perfeitamente com plataformas de big data correspondentes criadas no Spark, com facilidade de movimentação de dados, modelos reutilizáveis, código pronto para uso e ferramentas que oferecem suporte às melhores práticas para prototipagem, validação, controle de versão, compartilhamento, reutilização e implantação rápida de modelos na produção.
Por que escolher a NetApp?
A NetApp pode melhorar sua experiência com o Spark das seguintes maneiras:
-
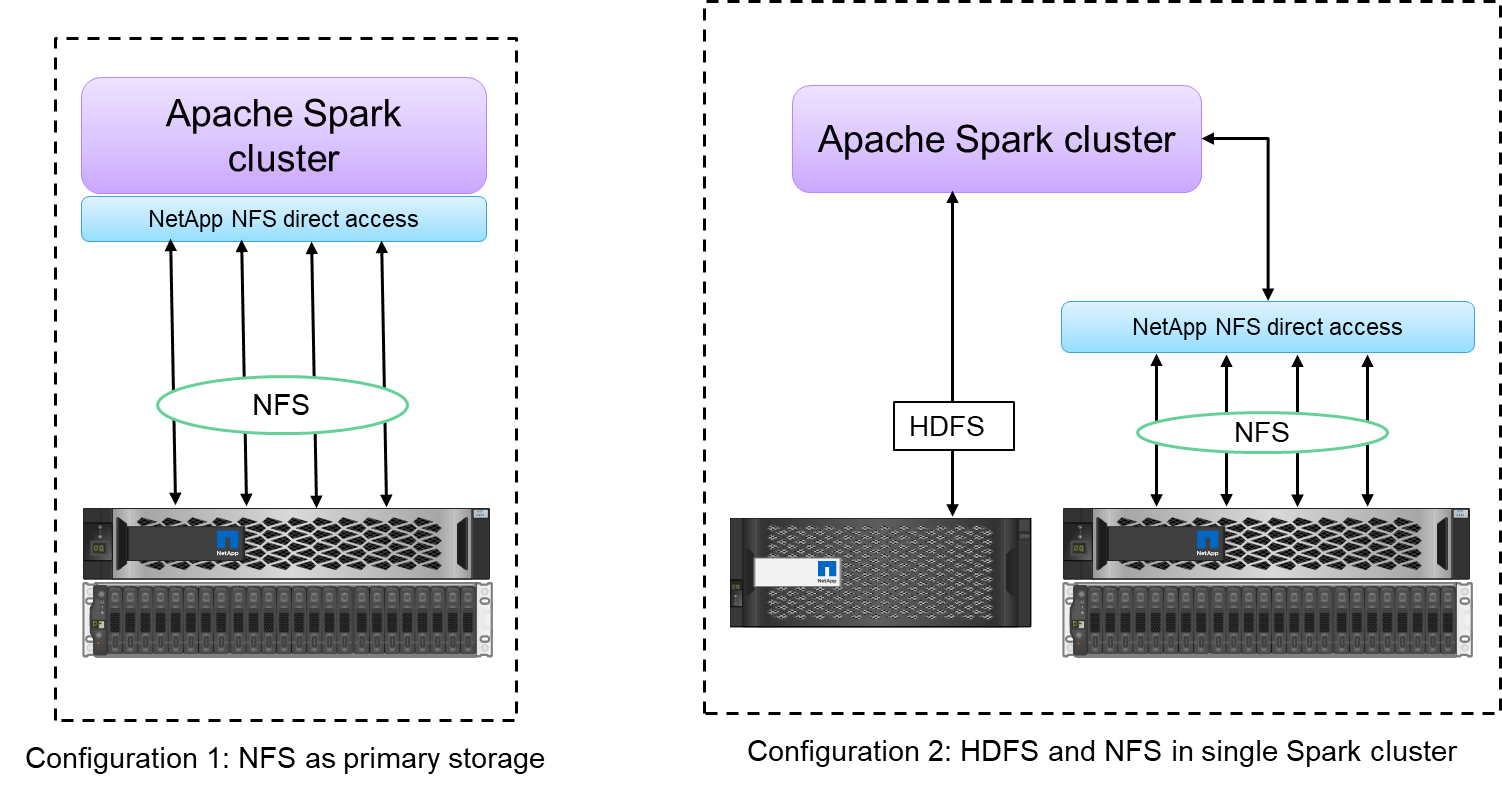
O acesso direto do NetApp NFS (mostrado na figura abaixo) permite que os clientes executem trabalhos de análise de big data em seus dados NFSv3 ou NFSv4 existentes ou novos sem mover ou copiar os dados. Ele evita múltiplas cópias de dados e elimina a necessidade de sincronizar os dados com uma fonte.
-
Armazenamento mais eficiente e menos replicação de servidor. Por exemplo, a solução NetApp E-Series Hadoop requer duas, em vez de três réplicas dos dados, e a solução FAS Hadoop requer uma fonte de dados, mas nenhuma replicação ou cópias de dados. As soluções de armazenamento da NetApp também produzem menos tráfego de servidor para servidor.
-
Melhor comportamento do cluster e do trabalho do Hadoop durante falhas de unidade e nó.
-
Melhor desempenho de ingestão de dados.
Por exemplo, no setor financeiro e de saúde, a movimentação de dados de um lugar para outro deve atender a obrigações legais, o que não é uma tarefa fácil. Nesse cenário, o acesso direto do NetApp NFS analisa os dados financeiros e de saúde de seu local original. Outro benefício importante é que o uso do acesso direto do NetApp NFS simplifica a proteção de dados do Hadoop usando comandos nativos do Hadoop e permitindo fluxos de trabalho de proteção de dados com o rico portfólio de gerenciamento de dados da NetApp.
O acesso direto do NetApp NFS oferece dois tipos de opções de implantação para clusters Hadoop/Spark:
-
Por padrão, os clusters Hadoop ou Spark usam o Hadoop Distributed File System (HDFS) para armazenamento de dados e o sistema de arquivos padrão. O acesso direto do NetApp NFS pode substituir o HDFS padrão pelo armazenamento NFS como o sistema de arquivos padrão, permitindo análises diretas em dados NFS.
-
Em outra opção de implantação, o acesso direto do NetApp NFS oferece suporte à configuração do NFS como armazenamento adicional junto com o HDFS em um único cluster Hadoop ou Spark. Nesse caso, o cliente pode compartilhar dados por meio de exportações NFS e acessá-los do mesmo cluster junto com os dados HDFS.
Os principais benefícios de usar o acesso direto do NetApp NFS incluem o seguinte:
-
Analisar os dados de seu local atual, o que evita a tarefa demorada e de alto desempenho de mover dados analíticos para uma infraestrutura Hadoop, como o HDFS.
-
Reduzindo o número de réplicas de três para uma.
-
Permitindo que os usuários dissociem a computação e o armazenamento para dimensioná-los de forma independente.
-
Fornecendo proteção de dados empresariais aproveitando os recursos avançados de gerenciamento de dados do ONTAP.
-
Certificação com a plataforma de dados Hortonworks.
-
Habilitando implantações de análise de dados híbrida.
-
Reduzindo o tempo de backup aproveitando a capacidade multithread dinâmica.
Ver"TR-4657: Soluções de dados em nuvem híbrida da NetApp - Spark e Hadoop com base em casos de uso do cliente" para fazer backup de dados do Hadoop, backup e recuperação de desastres da nuvem para o local, habilitar DevTest em dados do Hadoop existentes, proteção de dados e conectividade multicloud e acelerar cargas de trabalho de análise.
As seções a seguir descrevem recursos de armazenamento que são importantes para clientes do Spark.
Camadas de armazenamento
Com o armazenamento em camadas do Hadoop, você pode armazenar arquivos com diferentes tipos de armazenamento de acordo com uma política de armazenamento. Os tipos de armazenamento incluem hot , cold , warm , all_ssd , one_ssd , e lazy_persist .
Realizamos a validação da divisão em camadas de armazenamento do Hadoop em um controlador de armazenamento NetApp AFF e um controlador de armazenamento da série E com unidades SSD e SAS com diferentes políticas de armazenamento. O cluster Spark com AFF-A800 tem quatro nós de trabalho de computação, enquanto o cluster com E-Series tem oito. O objetivo principal é comparar o desempenho de unidades de estado sólido (SSDs) com o de discos rígidos (HDDs).
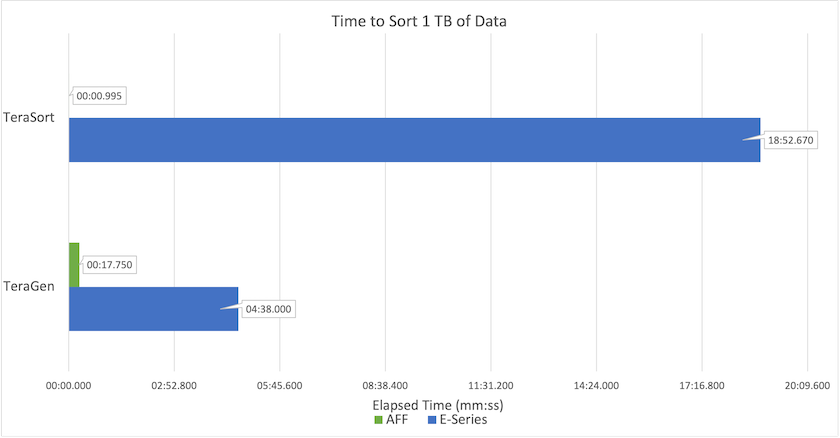
A figura a seguir mostra o desempenho das soluções NetApp para um SSD Hadoop.
-
A configuração básica do NL-SAS usava oito nós de computação e 96 unidades NL-SAS. Esta configuração gerou 1 TB de dados em 4 minutos e 38 segundos. Ver "Solução NetApp E-Series TR-3969 para Hadoop" para obter detalhes sobre a configuração do cluster e do armazenamento.
-
Usando o TeraGen, a configuração SSD gerou 1 TB de dados 15,66x mais rápido que a configuração NL-SAS. Além disso, a configuração SSD usou metade do número de nós de computação e metade do número de unidades de disco (24 unidades SSD no total). Com base no tempo de conclusão do trabalho, ele foi quase duas vezes mais rápido que a configuração NL-SAS.
-
Usando o TeraSort, a configuração SSD classificou 1 TB de dados 1138,36 vezes mais rápido que a configuração NL-SAS. Além disso, a configuração SSD usou metade do número de nós de computação e metade do número de unidades de disco (24 unidades SSD no total). Portanto, por unidade, era aproximadamente três vezes mais rápido que a configuração NL-SAS.
-
A conclusão é que a transição de discos giratórios para all-flash melhora o desempenho. O número de nós de computação não era o gargalo. Com o armazenamento all-flash da NetApp, o desempenho do tempo de execução é bem dimensionado.
-
Com o NFS, os dados eram funcionalmente equivalentes a serem agrupados, o que pode reduzir o número de nós de computação dependendo da sua carga de trabalho. Os usuários do cluster Apache Spark não precisam rebalancear manualmente os dados ao alterar o número de nós de computação.
Escalonamento de desempenho - Escala horizontal
Quando você precisa de mais poder de computação de um cluster Hadoop em uma solução AFF , você pode adicionar nós de dados com um número apropriado de controladores de armazenamento. A NetApp recomenda começar com quatro nós de dados por matriz de controlador de armazenamento e aumentar o número para oito nós de dados por controlador de armazenamento, dependendo das características da carga de trabalho.
AFF e FAS são perfeitos para análises no local. Com base nos requisitos de computação, você pode adicionar gerenciadores de nós, e operações não disruptivas permitem adicionar um controlador de armazenamento sob demanda, sem tempo de inatividade. Oferecemos recursos avançados com AFF e FAS, como suporte de mídia NVME, eficiência garantida, redução de dados, QOS, análise preditiva, camadas de nuvem, replicação, implantação de nuvem e segurança. Para ajudar os clientes a atender às suas necessidades, a NetApp oferece recursos como análise de sistema de arquivos, cotas e balanceamento de carga on-box, sem custos adicionais de licença. A NetApp tem melhor desempenho no número de trabalhos simultâneos, menor latência, operações mais simples e maior taxa de transferência de gigabytes por segundo do que nossos concorrentes. Além disso, o NetApp Cloud Volumes ONTAP é executado em todos os três principais provedores de nuvem.
Escalonamento de desempenho - Escalonamento vertical
Os recursos de expansão permitem que você adicione unidades de disco aos sistemas AFF, FAS e E-Series quando precisar de capacidade de armazenamento adicional. Com o Cloud Volumes ONTAP, dimensionar o armazenamento para o nível PB é uma combinação de dois fatores: hierarquizar dados usados com pouca frequência para armazenamento de objetos a partir do armazenamento em bloco e empilhar licenças do Cloud Volumes ONTAP sem computação adicional.
Vários protocolos
Os sistemas NetApp oferecem suporte à maioria dos protocolos para implantações do Hadoop, incluindo SAS, iSCSI, FCP, InfiniBand e NFS.
Soluções operacionais e suportadas
As soluções Hadoop descritas neste documento são suportadas pela NetApp. Essas soluções também são certificadas pelos principais distribuidores do Hadoop. Para obter informações, consulte o "Hortonworks" site e o Cloudera "certificação" e "parceiro" sites.