

Tecnologia de soluções
 Sugerir alterações
Sugerir alterações
Apache Spark é uma estrutura de programação popular para escrever aplicativos Hadoop que funciona diretamente com o Hadoop Distributed File System (HDFS). O Spark está pronto para produção, suporta processamento de dados de streaming e é mais rápido que o MapReduce. O Spark tem cache de dados na memória configurável para iteração eficiente, e o shell do Spark é interativo para aprendizado e exploração de dados. Com o Spark, você pode criar aplicativos em Python, Scala ou Java. Os aplicativos Spark consistem em um ou mais trabalhos que têm uma ou mais tarefas.
Cada aplicativo Spark tem um driver Spark. No modo YARN-Client, o driver é executado no cliente localmente. No modo YARN-Cluster, o driver é executado no cluster no mestre do aplicativo. No modo de cluster, o aplicativo continua em execução mesmo se o cliente se desconectar.
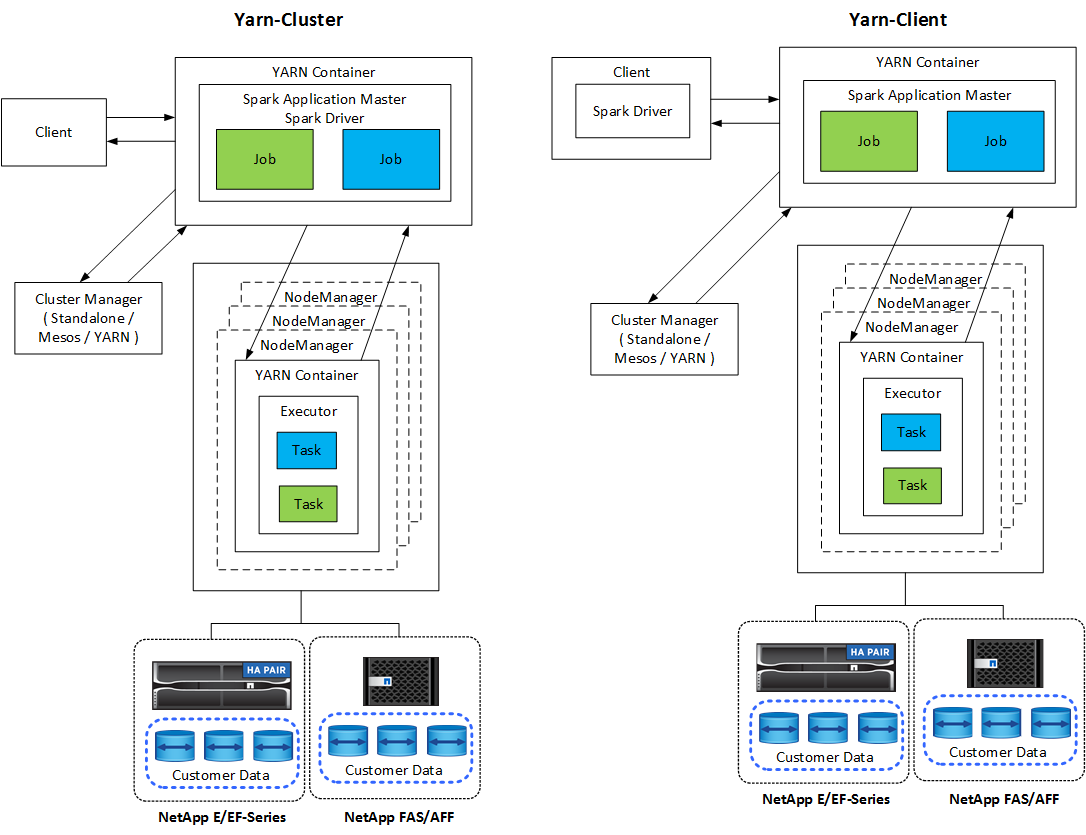
Existem três gerenciadores de cluster:
-
Autônomo. Este gerenciador faz parte do Spark, o que facilita a configuração de um cluster.
-
Apache Mesos. Este é um gerenciador de cluster geral que também executa o MapReduce e outros aplicativos.
-
Hadoop YARN. Este é um gerenciador de recursos no Hadoop 3.
O conjunto de dados distribuídos resilientes (RDD) é o principal componente do Spark. O RDD recria os dados perdidos e ausentes a partir dos dados armazenados na memória do cluster e armazena os dados iniciais que vêm de um arquivo ou são criados programaticamente. RDDs são criados a partir de arquivos, dados na memória ou outro RDD. A programação Spark realiza duas operações: transformação e ações. A transformação cria um novo RDD com base em um existente. Ações retornam um valor de um RDD.
Transformações e ações também se aplicam a conjuntos de dados e quadros de dados do Spark. Um conjunto de dados é uma coleção distribuída de dados que fornece os benefícios de RDDs (tipagem forte, uso de funções lambda) com os benefícios do mecanismo de execução otimizado do Spark SQL. Um conjunto de dados pode ser construído a partir de objetos JVM e então manipulado usando transformações funcionais (mapa, flatMap, filtro e assim por diante). Um DataFrame é um conjunto de dados organizado em colunas nomeadas. É conceitualmente equivalente a uma tabela em um banco de dados relacional ou a um quadro de dados em R/Python. Os DataFrames podem ser construídos a partir de uma ampla gama de fontes, como arquivos de dados estruturados, tabelas no Hive/HBase, bancos de dados externos no local ou na nuvem, ou RDDs existentes.
Os aplicativos Spark incluem um ou mais trabalhos Spark. Os trabalhos executam tarefas em executores, e os executores são executados em contêineres YARN. Cada executor é executado em um único contêiner, e os executores existem durante toda a vida de um aplicativo. Um executor é corrigido depois que o aplicativo é iniciado, e o YARN não redimensiona o contêiner já alocado. Um executor pode executar tarefas simultaneamente em dados na memória.