Resultados dos testes
 Sugerir alterações
Sugerir alterações
Usamos os scripts TeraSort e TeraValidate na ferramenta de benchmarking TeraGen para medir a validação de desempenho do Spark com as configurações E5760, E5724 e AFF-A800. Além disso, três casos de uso principais foram testados: pipelines Spark NLP e treinamento distribuído TensorFlow, treinamento distribuído Horovod e aprendizado profundo de vários trabalhadores usando Keras para previsão de CTR com DeepFM.
Para validação do E-Series e do StorageGRID , usamos o fator de replicação 2 do Hadoop. Para validação do AFF , usamos apenas uma fonte de dados.
A tabela a seguir lista a configuração de hardware para a validação de desempenho do Spark.
| Tipo | Nós de trabalho do Hadoop | Tipo de unidade | Unidades por nó | Controlador de armazenamento |
|---|---|---|---|---|
SG6060 |
4 |
SAS |
12 |
Par único de alta disponibilidade (HA) |
E5760 |
4 |
SAS |
60 |
Par único de HA |
E5724 |
4 |
SAS |
24 |
Par único de HA |
AFF800 |
4 |
SSD |
6 |
Par único de HA |
A tabela a seguir lista os requisitos de software.
| Software | Versão |
|---|---|
RHEL |
7,9 |
Ambiente de execução OpenJDK |
1.8.0 |
VM do servidor OpenJDK de 64 bits |
25,302 |
Git |
2.24.1 |
GCC/G++ |
11.2.1 |
Fagulha |
3.2.1 |
PySpark |
3.1.2 |
SparkNLP |
3.4.2 |
TensorFlow |
2.9.0 |
Keras |
2.9.0 |
Horovod |
0.24.3 |
Análise de sentimento financeiro
Nós publicamos"TR-4910: Análise de sentimentos das comunicações com o cliente com a NetApp AI" , no qual um pipeline de IA de conversação de ponta a ponta foi construído usando o "Kit de ferramentas NetApp DataOps" , armazenamento AFF e sistema NVIDIA DGX. O pipeline executa processamento de sinal de áudio em lote, reconhecimento automático de fala (ASR), aprendizagem de transferência e análise de sentimentos, aproveitando o DataOps Toolkit, "NVIDIA Riva SDK" , e o "Estrutura do Tao" . Expandindo o caso de uso da análise de sentimentos para o setor de serviços financeiros, criamos um fluxo de trabalho SparkNLP, carregamos três modelos BERT para várias tarefas de PNL, como reconhecimento de entidade nomeada, e obtivemos sentimentos em nível de frase para as teleconferências de resultados trimestrais das 10 maiores empresas da NASDAQ.
O seguinte script sentiment_analysis_spark. py usa o modelo FinBERT para processar transcrições no HDFS e produzir contagens de sentimentos positivos, neutros e negativos, conforme mostrado na tabela a seguir:
-bash-4.2$ time ~/anaconda3/bin/spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_2.12:3.4.3 --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 --conf spark.driver.extraJavaOptions="-Xss10m -XX:MaxPermSize=1024M" --conf spark.executor.extraJavaOptions="-Xss10m -XX:MaxPermSize=512M" /sparkusecase/tr-4570-nlp/sentiment_analysis_spark.py hdfs:///data1/Transcripts/ > ./sentiment_analysis_hdfs.log 2>&1 real13m14.300s user557m11.319s sys4m47.676s
A tabela a seguir lista a análise de sentimento em nível de frase e teleconferência de resultados para as 10 maiores empresas da NASDAQ de 2016 a 2020.
| Contagens de sentimentos e porcentagem | Todas as 10 empresas | AAPL | AMD | AMZN | CSCO | GOOGL | INTC | MSFT | NVDA |
|---|---|---|---|---|---|---|---|---|---|
Contagens positivas |
7447 |
1567 |
743 |
290 |
682 |
826 |
824 |
904 |
417 |
Contagens neutras |
64067 |
6856 |
7596 |
5086 |
6650 |
5914 |
6099 |
5715 |
6189 |
Contagens negativas |
1787 |
253 |
213 |
84 |
189 |
97 |
282 |
202 |
89 |
Contagens não categorizadas |
196 |
0 |
0 |
76 |
0 |
0 |
0 |
1 |
0 |
(contagens totais) |
73497 |
8676 |
8552 |
5536 |
7521 |
6837 |
7205 |
6822 |
6695 |
Em termos de porcentagem, a maioria das frases ditas pelos CEOs e CFOs são factuais e, portanto, carregam sentimentos neutros. Durante uma teleconferência de resultados, os analistas fazem perguntas que podem transmitir sentimentos positivos ou negativos. Vale a pena investigar mais quantitativamente como o sentimento negativo ou positivo afeta os preços das ações no mesmo dia ou no dia seguinte de negociação.
A tabela a seguir lista a análise de sentimento em nível de frase para as 10 maiores empresas do NASDAQ, expressa em porcentagem.
| Porcentagem de sentimento | Todas as 10 empresas | AAPL | AMD | AMZN | CSCO | GOOGL | INTC | MSFT | NVDA |
|---|---|---|---|---|---|---|---|---|---|
Positivo |
10,13% |
18,06% |
8,69% |
5,24% |
9,07% |
12,08% |
11,44% |
13,25% |
6,23% |
Neutro |
87,17% |
79,02% |
88,82% |
91,87% |
88,42% |
86,50% |
84,65% |
83,77% |
92,44% |
Negativo |
2,43% |
2,92% |
2,49% |
1,52% |
2,51% |
1,42% |
3,91% |
2,96% |
1,33% |
Sem categoria |
0,27% |
0% |
0% |
1,37% |
0% |
0% |
0% |
0,01% |
0% |
Em termos de tempo de execução do fluxo de trabalho, vimos uma melhoria significativa de 4,78x local modo para um ambiente distribuído no HDFS e uma melhoria adicional de 0,14% ao aproveitar o NFS.
-bash-4.2$ time ~/anaconda3/bin/spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_2.12:3.4.3 --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 --conf spark.driver.extraJavaOptions="-Xss10m -XX:MaxPermSize=1024M" --conf spark.executor.extraJavaOptions="-Xss10m -XX:MaxPermSize=512M" /sparkusecase/tr-4570-nlp/sentiment_analysis_spark.py file:///sparkdemo/sparknlp/Transcripts/ > ./sentiment_analysis_nfs.log 2>&1 real13m13.149s user537m50.148s sys4m46.173s
Como mostra a figura a seguir, o paralelismo de dados e modelos melhorou o processamento de dados e a velocidade de inferência do modelo distribuído do TensorFlow. A localização dos dados no NFS produziu um tempo de execução um pouco melhor porque o gargalo do fluxo de trabalho é o download de modelos pré-treinados. Se aumentarmos o tamanho do conjunto de dados de transcrições, a vantagem do NFS fica mais óbvia.
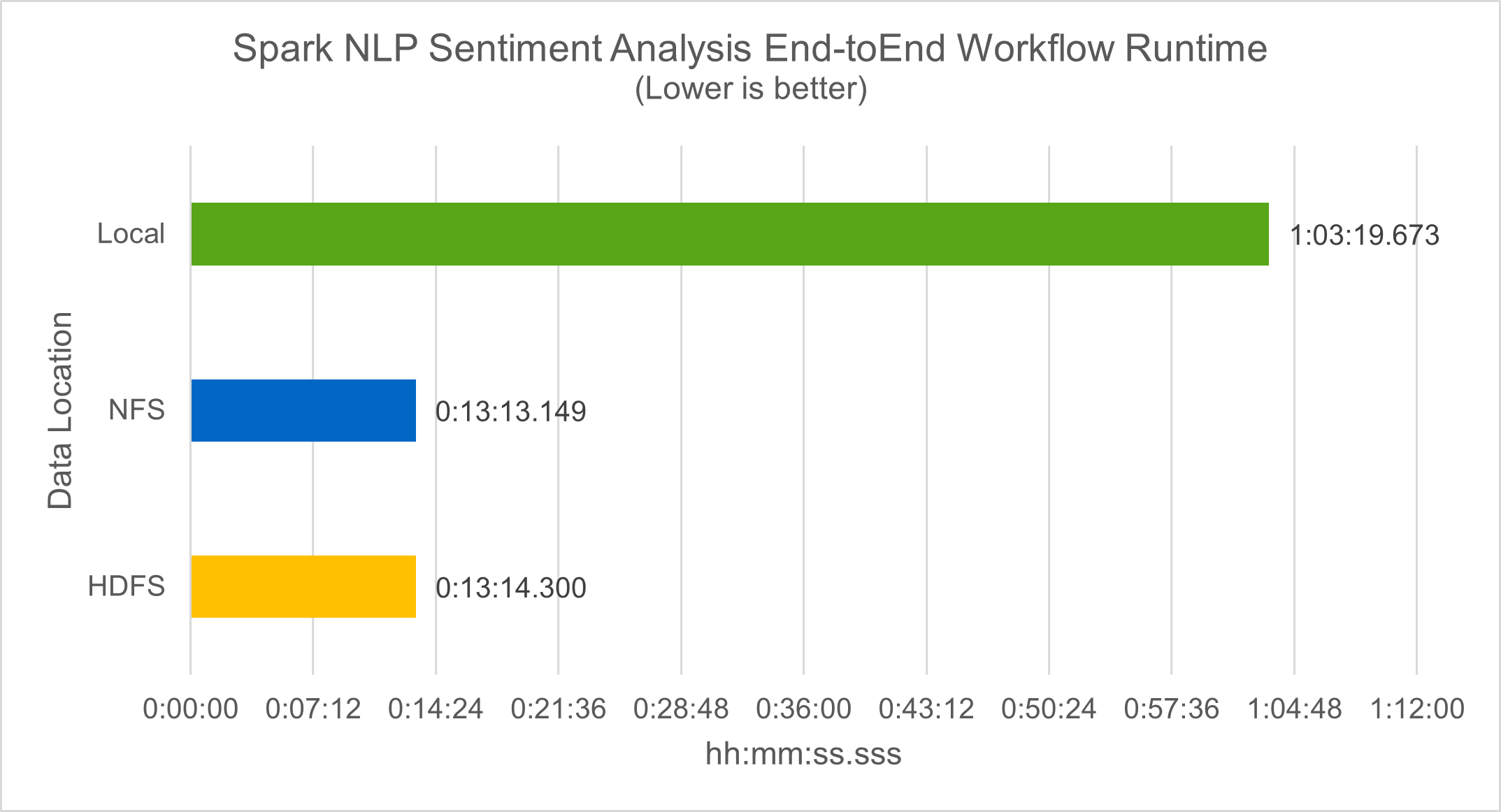
Treinamento distribuído com desempenho Horovod
O comando a seguir produziu informações de tempo de execução e um arquivo de log em nosso cluster Spark usando um único master nó com 160 executores, cada um com um núcleo. A memória do executor foi limitada a 5 GB para evitar erros de falta de memória. Veja a seção"Scripts Python para cada caso de uso principal" para mais detalhes sobre o processamento de dados, treinamento do modelo e cálculo de precisão do modelo em keras_spark_horovod_rossmann_estimator.py .
(base) [root@n138 horovod]# time spark-submit --master local --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir file:///sparkusecase/horovod --local-submission-csv /tmp/submission_0.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_local. log 2>&1
O tempo de execução resultante com dez épocas de treinamento foi o seguinte:
real43m34.608s user12m22.057s sys2m30.127s
Foram necessários mais de 43 minutos para processar dados de entrada, treinar um modelo DNN, calcular a precisão e produzir pontos de verificação do TensorFlow e um arquivo CSV para resultados de previsão. Limitamos o número de períodos de treinamento a 10, que na prática geralmente é definido como 100 para garantir precisão satisfatória do modelo. O tempo de treinamento normalmente é escalonado linearmente com o número de épocas.
Em seguida, usamos os quatro nós de trabalho disponíveis no cluster e executamos o mesmo script em yarn modo com dados em HDFS:
(base) [root@n138 horovod]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir hdfs:///user/hdfs/tr-4570/experiments/horovod --local-submission-csv /tmp/submission_1.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_yarn.log 2>&1
O tempo de execução resultante foi melhorado da seguinte forma:
real8m13.728s user7m48.421s sys1m26.063s
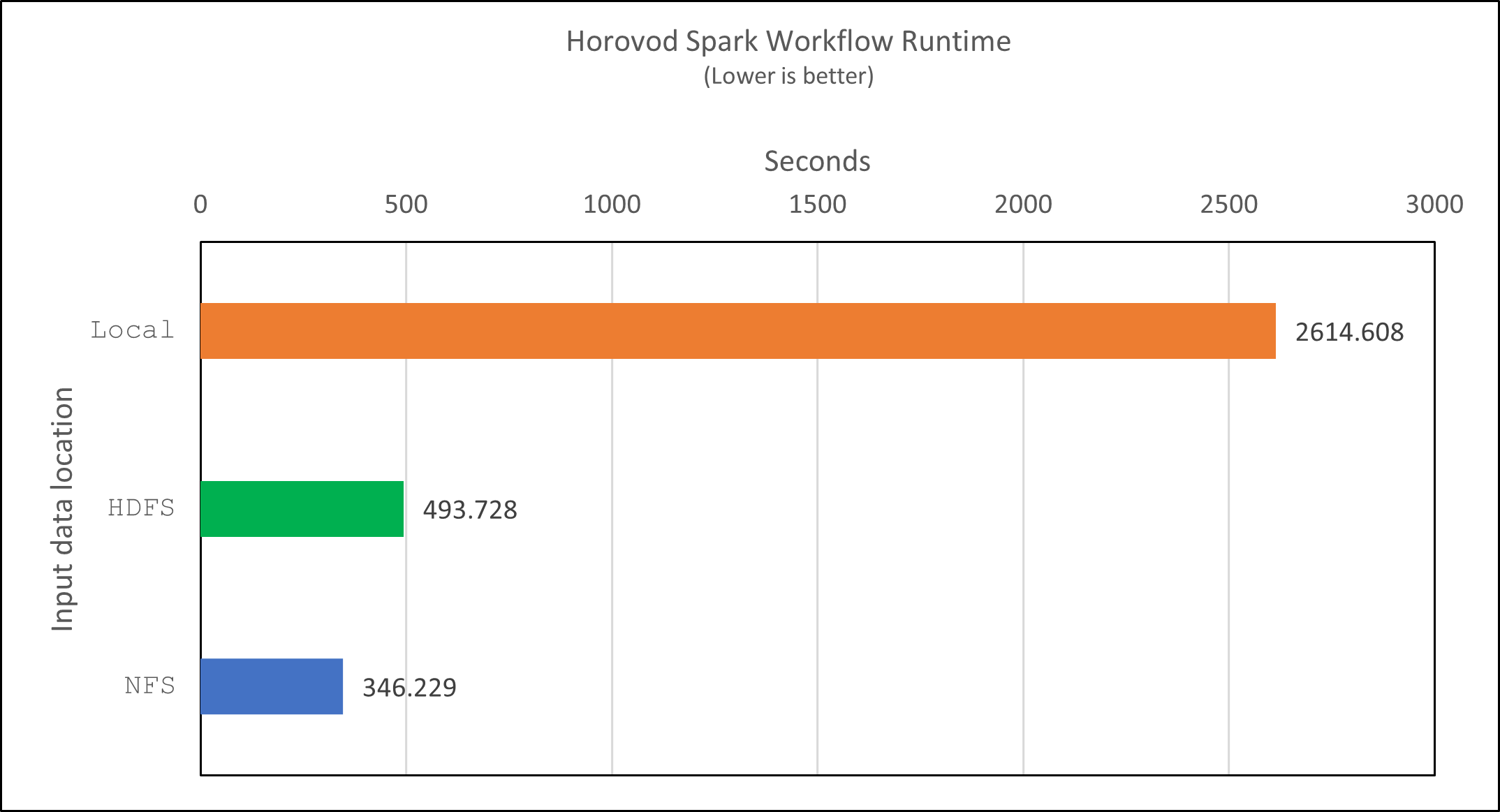
Com o modelo de Horovod e o paralelismo de dados no Spark, vimos uma aceleração de tempo de execução de 5,29x yarn contra local modo com dez épocas de treinamento. Isso é mostrado na figura a seguir com as legendas HDFS e Local . O treinamento do modelo DNN subjacente do TensorFlow pode ser ainda mais acelerado com GPUs, se disponíveis. Planejamos realizar esses testes e publicar os resultados em um futuro relatório técnico.
Nosso próximo teste comparou os tempos de execução com dados de entrada residindo em NFS versus HDFS. O volume NFS no AFF A800 foi montado em /sparkdemo/horovod nos cinco nós (um mestre, quatro trabalhadores) em nosso cluster Spark. Executamos um comando semelhante aos testes anteriores, com o --data- dir parâmetro agora apontando para a montagem NFS:
(base) [root@n138 horovod]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir file:///sparkdemo/horovod --local-submission-csv /tmp/submission_2.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_nfs.log 2>&1
O tempo de execução resultante com NFS foi o seguinte:
real 5m46.229s user 5m35.693s sys 1m5.615s
Houve uma aceleração adicional de 1,43x, conforme mostrado na figura a seguir. Portanto, com um armazenamento all-flash da NetApp conectado ao seu cluster, os clientes aproveitam os benefícios da rápida transferência e distribuição de dados para fluxos de trabalho do Horovod Spark, alcançando uma aceleração de 7,55x em comparação à execução em um único nó.
Modelos de aprendizado profundo para desempenho de previsão de CTR
Para sistemas de recomendação projetados para maximizar o CTR, você deve aprender interações de recursos sofisticados por trás dos comportamentos do usuário que podem ser calculados matematicamente da ordem mais baixa para a mais alta. Tanto as interações de recursos de baixa quanto de alta ordem devem ser igualmente importantes para um bom modelo de aprendizado profundo, sem distorção em relação a uma ou outra. Deep Factorization Machine (DeepFM), uma rede neural baseada em máquina de fatoração, combina máquinas de fatoração para recomendação e aprendizado profundo para aprendizado de recursos em uma nova arquitetura de rede neural.
Embora as máquinas de fatoração convencionais modelem interações de recursos em pares como um produto interno de vetores latentes entre recursos e possam, teoricamente, capturar informações de alta ordem, na prática, os profissionais de aprendizado de máquina geralmente usam apenas interações de recursos de segunda ordem devido à alta complexidade de computação e armazenamento. Variantes de redes neurais profundas como as do Google "Modelos largos e profundos" por outro lado, aprende interações de recursos sofisticados em uma estrutura de rede híbrida combinando um modelo linear amplo e um modelo profundo.
Há duas entradas para este Modelo Amplo e Profundo, uma para o modelo amplo subjacente e outra para o profundo, sendo que esta última parte ainda requer engenharia de recursos especializada e, portanto, torna a técnica menos generalizável para outros domínios. Diferentemente do modelo amplo e profundo, o DeepFM pode ser treinado eficientemente com recursos brutos sem qualquer engenharia de recursos, porque sua parte ampla e parte profunda compartilham a mesma entrada e o mesmo vetor de incorporação.
Primeiro processamos o Criteo train.txt (11 GB) em um arquivo CSV chamado ctr_train.csv armazenado em uma montagem NFS /sparkdemo/tr-4570-data usando run_classification_criteo_spark.py da seção"Scripts Python para cada caso de uso principal." Dentro deste script, a função process_input_file executa vários métodos de string para remover tabulações e inserir ',' como delimitador e '\n' como nova linha. Observe que você só precisa processar o original train.txt uma vez, para que o bloco de código seja mostrado como comentários.
Para os testes seguintes de diferentes modelos DL, usamos ctr_train.csv como arquivo de entrada. Em execuções de testes subsequentes, o arquivo CSV de entrada foi lido em um Spark DataFrame com esquema contendo um campo de 'label' , recursos densos inteiros ['I1', 'I2', 'I3', …, 'I13'] , e recursos esparsos ['C1', 'C2', 'C3', …, 'C26'] . A seguir spark-submit O comando recebe um CSV de entrada, treina modelos DeepFM com divisão de 20% para validação cruzada e escolhe o melhor modelo após dez períodos de treinamento para calcular a precisão da previsão no conjunto de teste:
(base) [root@n138 ~]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py --data-dir file:///sparkdemo/tr-4570-data > /tmp/run_classification_criteo_spark_local.log 2>&1
Observe que, como o arquivo de dados ctr_train.csv for maior que 11 GB, você deve definir um espaço suficiente spark.driver.maxResultSize maior que o tamanho do conjunto de dados para evitar erros.
spark = SparkSession.builder \
.master("yarn") \
.appName("deep_ctr_classification") \
.config("spark.jars.packages", "io.github.ravwojdyla:spark-schema-utils_2.12:0.1.0") \
.config("spark.executor.cores", "1") \
.config('spark.executor.memory', '5gb') \
.config('spark.executor.memoryOverhead', '1500') \
.config('spark.driver.memoryOverhead', '1500') \
.config("spark.sql.shuffle.partitions", "480") \
.config("spark.sql.execution.arrow.enabled", "true") \
.config("spark.driver.maxResultSize", "50gb") \
.getOrCreate()
No acima SparkSession.builder configuração também habilitamos "Flecha Apache" , que converte um Spark DataFrame em um Pandas DataFrame com o df.toPandas() método.
22/06/17 15:56:21 INFO scheduler.DAGScheduler: Job 2 finished: toPandas at /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py:96, took 627.126487 s Obtained Spark DF and transformed to Pandas DF using Arrow.
Após a divisão aleatória, há mais de 36 milhões de linhas no conjunto de dados de treinamento e 9 milhões de amostras no conjunto de teste:
Training dataset size = 36672493 Testing dataset size = 9168124
Como este relatório técnico se concentra em testes de CPU sem usar GPUs, é fundamental que você crie o TensorFlow com sinalizadores de compilador apropriados. Esta etapa evita invocar quaisquer bibliotecas aceleradas por GPU e aproveita ao máximo as instruções Advanced Vector Extensions (AVX) e AVX2 do TensorFlow. Esses recursos são projetados para cálculos algébricos lineares, como adição vetorizada, multiplicação de matrizes dentro de um treinamento DNN de propagação direta ou retropropagação. A instrução Fused Multiply Add (FMA) disponível com AVX2 usando registradores de ponto flutuante (FP) de 256 bits é ideal para códigos inteiros e tipos de dados, resultando em um aumento de velocidade de até 2x. Para códigos FP e tipos de dados, o AVX2 atinge 8% de aceleração em relação ao AVX.
2022-06-18 07:19:20.101478: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
Para construir o TensorFlow a partir do código-fonte, a NetApp recomenda usar "Bazel" . Para nosso ambiente, executamos os seguintes comandos no prompt do shell para instalar dnf , dnf-plugins , e Bazel.
yum install dnf dnf install 'dnf-command(copr)' dnf copr enable vbatts/bazel dnf install bazel5
Você deve habilitar o GCC 5 ou mais recente para usar os recursos do C++17 durante o processo de compilação, que é fornecido pelo RHEL com a Software Collections Library (SCL). Os seguintes comandos instalam devtoolset e GCC 11.2.1 em nosso cluster RHEL 7.9:
subscription-manager repos --enable rhel-server-rhscl-7-rpms yum install devtoolset-11-toolchain yum install devtoolset-11-gcc-c++ yum update scl enable devtoolset-11 bash . /opt/rh/devtoolset-11/enable
Observe que os dois últimos comandos habilitam devtoolset-11 , que usa /opt/rh/devtoolset-11/root/usr/bin/gcc (GCC 11.2.1). Além disso, certifique-se de que seu git a versão é maior que 1.8.3 (vem com o RHEL 7.9). Consulte isto "artigo" para atualização git para 2.24.1.
Presumimos que você já clonou o repositório mestre mais recente do TensorFlow. Em seguida, crie um workspace diretório com um WORKSPACE arquivo para compilar o TensorFlow a partir do código-fonte com AVX, AVX2 e FMA. Execute o configure arquivo e especifique o local binário correto do Python. "CUDA" está desabilitado para nossos testes porque não usamos uma GPU. UM .bazelrc o arquivo é gerado de acordo com suas configurações. Além disso, editamos o arquivo e configuramos build --define=no_hdfs_support=false para habilitar o suporte HDFS. Consulte .bazelrc na seção"Scripts Python para cada caso de uso principal," para uma lista completa de configurações e sinalizadores.
./configure bazel build -c opt --copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-mfpmath=both -k //tensorflow/tools/pip_package:build_pip_package
Depois de criar o TensorFlow com os sinalizadores corretos, execute o script a seguir para processar o conjunto de dados Criteo Display Ads, treinar um modelo DeepFM e calcular a Área sob a Curva Característica Operacional do Receptor (ROC AUC) a partir das pontuações de previsão.
(base) [root@n138 examples]# ~/anaconda3/bin/spark-submit --master yarn --executor-memory 15g --executor-cores 1 --num-executors 160 /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py --data-dir file:///sparkdemo/tr-4570-data > . /run_classification_criteo_spark_nfs.log 2>&1
Após dez períodos de treinamento, obtivemos a pontuação AUC no conjunto de dados de teste:
Epoch 1/10 125/125 - 7s - loss: 0.4976 - binary_crossentropy: 0.4974 - val_loss: 0.4629 - val_binary_crossentropy: 0.4624 Epoch 2/10 125/125 - 1s - loss: 0.3281 - binary_crossentropy: 0.3271 - val_loss: 0.5146 - val_binary_crossentropy: 0.5130 Epoch 3/10 125/125 - 1s - loss: 0.1948 - binary_crossentropy: 0.1928 - val_loss: 0.6166 - val_binary_crossentropy: 0.6144 Epoch 4/10 125/125 - 1s - loss: 0.1408 - binary_crossentropy: 0.1383 - val_loss: 0.7261 - val_binary_crossentropy: 0.7235 Epoch 5/10 125/125 - 1s - loss: 0.1129 - binary_crossentropy: 0.1102 - val_loss: 0.7961 - val_binary_crossentropy: 0.7934 Epoch 6/10 125/125 - 1s - loss: 0.0949 - binary_crossentropy: 0.0921 - val_loss: 0.9502 - val_binary_crossentropy: 0.9474 Epoch 7/10 125/125 - 1s - loss: 0.0778 - binary_crossentropy: 0.0750 - val_loss: 1.1329 - val_binary_crossentropy: 1.1301 Epoch 8/10 125/125 - 1s - loss: 0.0651 - binary_crossentropy: 0.0622 - val_loss: 1.3794 - val_binary_crossentropy: 1.3766 Epoch 9/10 125/125 - 1s - loss: 0.0555 - binary_crossentropy: 0.0527 - val_loss: 1.6115 - val_binary_crossentropy: 1.6087 Epoch 10/10 125/125 - 1s - loss: 0.0470 - binary_crossentropy: 0.0442 - val_loss: 1.6768 - val_binary_crossentropy: 1.6740 test AUC 0.6337
De maneira semelhante aos casos de uso anteriores, comparamos o tempo de execução do fluxo de trabalho do Spark com dados residentes em locais diferentes. A figura a seguir mostra uma comparação da previsão de CTR de aprendizado profundo para um tempo de execução de fluxos de trabalho do Spark.