

Diretrizes de melhores práticas
 Sugerir alterações
Sugerir alterações
Esta seção apresenta lições aprendidas com esta certificação.
-
Com base em nossa validação, o armazenamento de objetos S3 é melhor para o Confluent manter dados.
-
Podemos usar SAN de alto rendimento (especificamente FC) para manter os dados ativos do broker ou o disco local, porque, na configuração de armazenamento em camadas do Confluent, o tamanho dos dados mantidos no diretório de dados do broker é baseado no tamanho do segmento e no tempo de retenção quando os dados são movidos para o armazenamento de objetos.
-
Os armazenamentos de objetos fornecem melhor desempenho quando segment.bytes é maior; testamos 512 MB.
-
No Kafka, o comprimento da chave ou valor (em bytes) para cada registro produzido no tópico é controlado pelo
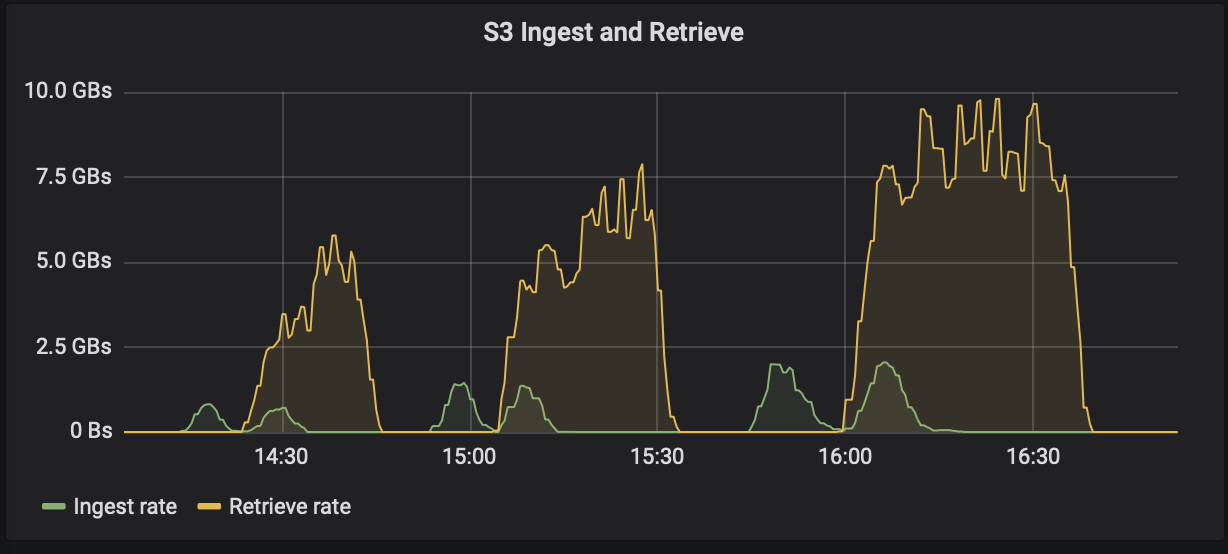
length.key.valueparâmetro. Para StorageGRID, o desempenho de ingestão e recuperação de objetos S3 aumentou para valores mais altos. Por exemplo, 512 bytes forneceram uma recuperação de 5,8 GBps, 1.024 bytes forneceram uma recuperação s3 de 7,5 GBps e 2.048 bytes forneceram perto de 10 GBps.
A figura a seguir apresenta a ingestão e recuperação de objetos S3 com base em length.key.value .
-
Afinação de Kafka. Para melhorar o desempenho do armazenamento em camadas, você pode aumentar TierFetcherNumThreads e TierArchiverNumThreads. Como orientação geral, você deve aumentar TierFetcherNumThreads para corresponder ao número de núcleos físicos da CPU e aumentar TierArchiverNumThreads para metade do número de núcleos da CPU. Por exemplo, nas propriedades do servidor, se você tiver uma máquina com oito núcleos físicos, defina confluent.tier.fetcher.num.threads = 8 e confluent.tier.archiver.num.threads = 4.
-
Intervalo de tempo para exclusão de tópicos. Quando um tópico é excluído, a exclusão dos arquivos de segmento de log no armazenamento de objetos não começa imediatamente. Em vez disso, há um intervalo de tempo com um valor padrão de 3 horas antes que a exclusão desses arquivos ocorra. Você pode modificar a configuração, confluent.tier.topic.delete.check.interval.ms, para alterar o valor deste intervalo. Se você excluir um tópico ou cluster, também poderá excluir manualmente os objetos no respectivo bucket.
-
ACLs sobre tópicos internos de armazenamento em camadas. Uma prática recomendada para implantações locais é habilitar um autorizador de ACL nos tópicos internos usados para armazenamento em camadas. Defina regras de ACL para limitar o acesso a esses dados somente ao usuário do broker. Isso protege os tópicos internos e impede o acesso não autorizado a dados de armazenamento em camadas e metadados.
kafka-acls --bootstrap-server localhost:9092 --command-config adminclient-configs.conf \ --add --allow-principal User:<kafka> --operation All --topic "_confluent-tier-state"

|
Substituir o usuário <kafka> com o principal corretor atual em sua implantação.
|
Por exemplo, o comando confluent-tier-state define ACLs no tópico interno para armazenamento em camadas. Atualmente, há apenas um único tópico interno relacionado ao armazenamento em camadas. O exemplo cria uma ACL que fornece a permissão principal do Kafka para todas as operações no tópico interno.