

Visão geral de desempenho e validação com AFF A900 local
 Sugerir alterações
Sugerir alterações
No local, usamos o controlador de armazenamento NetApp AFF A900 com ONTAP 9.12.1RC1 para validar o desempenho e o dimensionamento de um cluster Kafka. Usamos o mesmo ambiente de teste de nossas práticas recomendadas de armazenamento em camadas anteriores com ONTAP e AFF.
Usamos o Confluent Kafka 6.2.0 para avaliar o AFF A900. O cluster conta com oito nós de corretores e três nós de tratadores de zoológicos. Para testes de desempenho, usamos cinco nós de trabalho OMB.
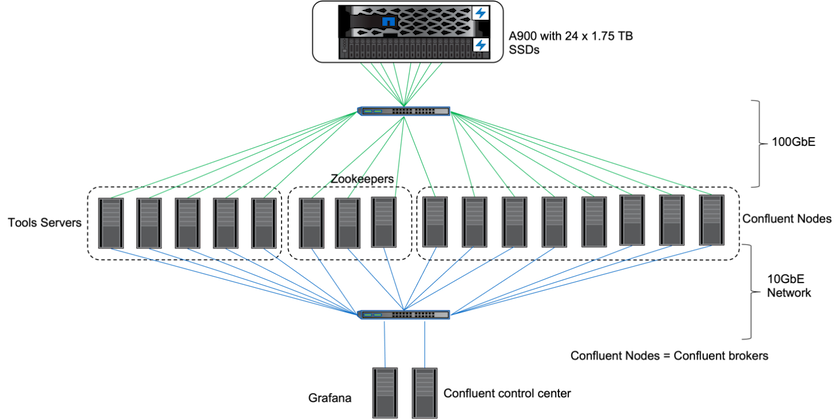
Configuração de armazenamento
Usamos instâncias do NetApp FlexGroups para fornecer um único namespace para diretórios de log, simplificando a recuperação e a configuração. Usamos NFSv4.1 e pNFS para fornecer acesso direto ao caminho para dados de segmento de log.
Ajuste de cliente
Cada cliente montou a instância do FlexGroup com o seguinte comando.
mount -t nfs -o vers=4.1,nconnect=16 172.30.0.121:/kafka_vol01 /data/kafka_vol01
Além disso, aumentamos a max_session_slots` do padrão 64 para 180 . Isso corresponde ao limite de slot de sessão padrão no ONTAP.
Ajuste do corretor Kafka
Para maximizar o rendimento no sistema em teste, aumentamos significativamente os parâmetros padrão para determinados pools de threads principais. Recomendamos seguir as práticas recomendadas do Confluent Kafka para a maioria das configurações. Esse ajuste foi usado para maximizar a simultaneidade de E/S pendentes para armazenamento. Esses parâmetros podem ser ajustados para corresponder aos recursos de computação e atributos de armazenamento do seu corretor.
num.io.threads=96 num.network.threads=96 background.threads=20 num.replica.alter.log.dirs.threads=40 num.replica.fetchers=20 queued.max.requests=2000
Metodologia de teste do gerador de carga de trabalho
Usamos as mesmas configurações de OMB usadas nos testes de nuvem para o driver de throughput e a configuração do tópico.
-
Uma instância do FlexGroup foi provisionada usando o Ansible em um cluster AFF .
--- - name: Set up kafka broker processes hosts: localhost vars: ntap_hostname: 'hostname' ntap_username: 'user' ntap_password: 'password' size: 10 size_unit: tb vserver: vs1 state: present https: true export_policy: default volumes: - name: kafka_fg_vol01 aggr: ["aggr1_a", "aggr2_a", "aggr1_b", "aggr2_b"] path: /kafka_fg_vol01 tasks: - name: Edit volumes netapp.ontap.na_ontap_volume: state: "{{ state }}" name: "{{ item.name }}" aggr_list: "{{ item.aggr }}" aggr_list_multiplier: 8 size: "{{ size }}" size_unit: "{{ size_unit }}" vserver: "{{ vserver }}" snapshot_policy: none export_policy: default junction_path: "{{ item.path }}" qos_policy_group: none wait_for_completion: True hostname: "{{ ntap_hostname }}" username: "{{ ntap_username }}" password: "{{ ntap_password }}" https: "{{ https }}" validate_certs: false connection: local with_items: "{{ volumes }}" -
O pNFS foi habilitado no ONTAP SVM.
vserver modify -vserver vs1 -v4.1-pnfs enabled -tcp-max-xfer-size 262144
-
A carga de trabalho foi acionada com o driver Throughput usando a mesma configuração de carga de trabalho do Cloud Volumes ONTAP. Veja a seção "Desempenho em estado estacionário " abaixo. A carga de trabalho usou um fator de replicação de 3, o que significa que três cópias de segmentos de log foram mantidas no NFS.
sudo bin/benchmark --drivers driver-kafka/kafka-throughput.yaml workloads/1-topic-100-partitions-1kb.yaml
-
Por fim, concluímos medições usando um backlog para medir a capacidade dos consumidores de acompanhar as mensagens mais recentes. O OMB cria um backlog pausando os consumidores durante o início de uma medição. Isso produz três fases distintas: criação de backlog (tráfego somente do produtor), redução de backlog (uma fase com grande demanda do consumidor, na qual os consumidores recuperam os eventos perdidos em um tópico) e o estado estável. Veja a seção "Desempenho extremo e exploração de limites de armazenamento " para mais informações.
Desempenho em estado estacionário
Avaliamos o AFF A900 usando o OpenMessaging Benchmark para fornecer uma comparação semelhante à do Cloud Volumes ONTAP na AWS e do DAS na AWS. Todos os valores de desempenho representam a taxa de transferência do cluster Kafka no nível do produtor e do consumidor.
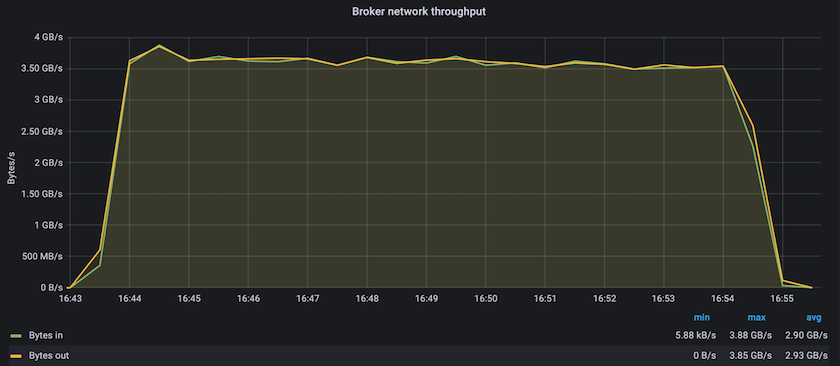
O desempenho em estado estável com o Confluent Kafka e o AFF A900 atingiu uma taxa de transferência média de mais de 3,4 GBps para produtores e consumidores. Isso representa mais de 3,4 milhões de mensagens no cluster Kafka. Ao visualizar a taxa de transferência sustentada em bytes por segundo para BrokerTopicMetrics, vemos o excelente desempenho de estado estável e o tráfego suportado pelo AFF A900.
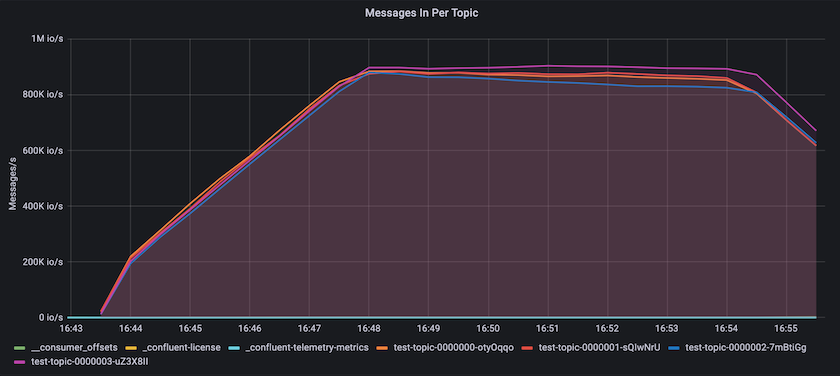
Isso se alinha bem com a visão de mensagens entregues por tópico. O gráfico a seguir fornece uma análise por tópico. Na configuração testada, vimos quase 900 mil mensagens por tópico em quatro tópicos.
Desempenho extremo e exploração de limites de armazenamento
Para o AFF, também testamos com o OMB usando o recurso de backlog. O recurso de backlog pausa as assinaturas do consumidor enquanto um backlog de eventos é criado no cluster do Kafka. Durante esta fase, ocorre apenas o tráfego do produtor, o que gera eventos que são confirmados em logs. Isso emula mais de perto o processamento em lote ou os fluxos de trabalho de análise offline; nesses fluxos de trabalho, as assinaturas do consumidor são iniciadas e devem ler dados históricos que já foram removidos do cache do corretor.
Para entender as limitações de armazenamento na taxa de transferência do consumidor nesta configuração, medimos a fase somente do produtor para entender quanto tráfego de gravação o A900 poderia absorver. Veja a próxima seção "Orientação de dimensionamento " para entender como aproveitar esses dados.
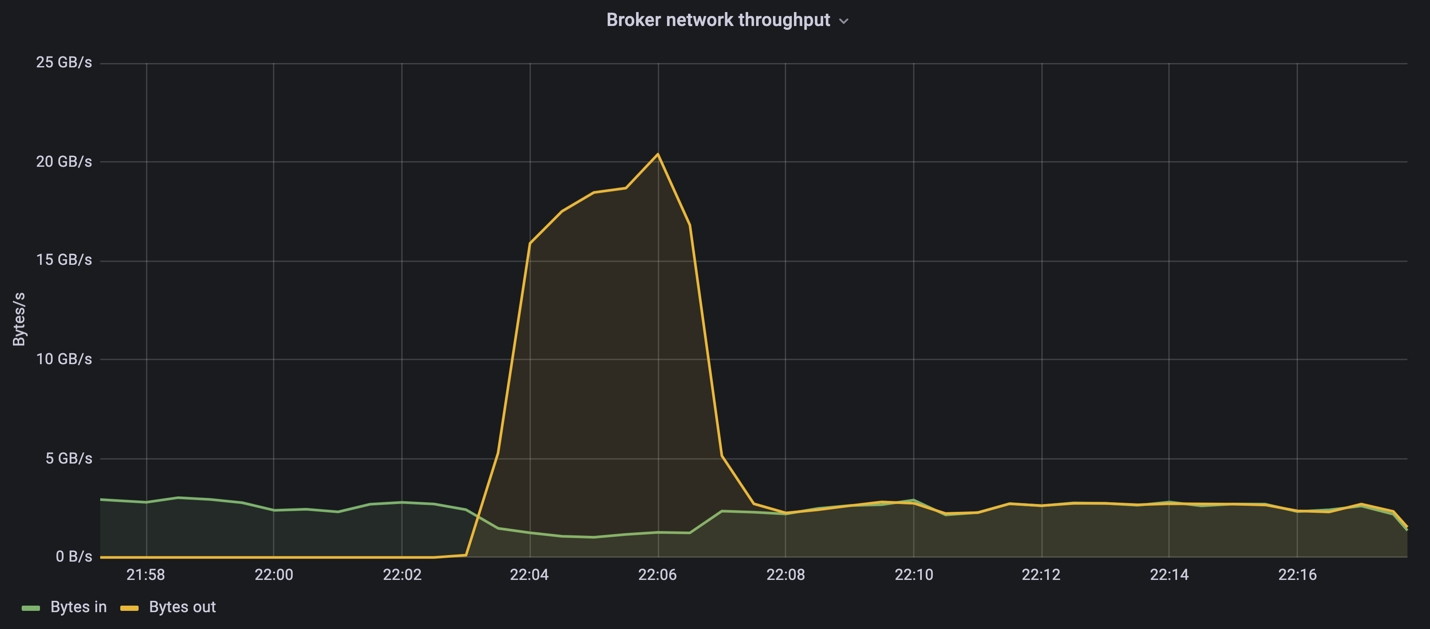
Durante a parte exclusiva do produtor dessa medição, observamos um alto pico de rendimento que ultrapassou os limites de desempenho do A900 (quando outros recursos do corretor não estavam saturados, atendendo ao tráfego de produtores e consumidores).

|
Aumentamos o tamanho da mensagem para 16k para esta medição para limitar as sobrecargas por mensagem e maximizar a taxa de transferência de armazenamento para pontos de montagem NFS. |
messageSize: 16384 consumerBacklogSizeGB: 4096
O cluster Confluent Kafka atingiu um pico de produtividade do produtor de 4,03 GBps.
18:12:23.833 [main] INFO WorkloadGenerator - Pub rate 257759.2 msg/s / 4027.5 MB/s | Pub err 0.0 err/s …
Depois que o OMB concluiu o preenchimento do eventbacklog, o tráfego do consumidor foi reiniciado. Durante as medições com drenagem de backlog, observamos um pico de rendimento do consumidor de mais de 20 GBps em todos os tópicos. A taxa de transferência combinada para o volume NFS que armazena os dados de log OMB se aproximou de ~30 GBps.
Orientação de dimensionamento
A Amazon Web Services oferece uma "guia de tamanhos" para dimensionamento e escalonamento de clusters do Kafka.
Esse dimensionamento fornece uma fórmula útil para determinar os requisitos de taxa de transferência de armazenamento para seu cluster Kafka:
Para uma taxa de transferência agregada produzida no cluster de tcluster com um fator de replicação de r, a taxa de transferência recebida pelo armazenamento do broker é a seguinte:
t[storage] = t[cluster]/#brokers + t[cluster]/#brokers * (r-1)
= t[cluster]/#brokers * r
Isso pode ser simplificado ainda mais:
max(t[cluster]) <= max(t[storage]) * #brokers/r
Usar esta fórmula permite que você selecione a plataforma ONTAP apropriada para suas necessidades de nível ativo do Kafka.
A tabela a seguir explica a produtividade esperada do produtor para o A900 com diferentes fatores de replicação:
| Fator de replicação | Taxa de transferência do produtor (GPps) |
|---|---|
3 (medido) |
3,4 |
2 |
5,1 |
1 |
10,2 |