Visão geral de desempenho e validação na AWS
 Sugerir alterações
Sugerir alterações
Um cluster Kafka com a camada de armazenamento montada no NetApp NFS foi avaliado quanto ao desempenho na nuvem AWS. Os exemplos de benchmarking são descritos nas seções a seguir.
Kafka na nuvem AWS com NetApp Cloud Volumes ONTAP (par de alta disponibilidade e nó único)
Um cluster Kafka com NetApp Cloud Volumes ONTAP (par HA) foi avaliado quanto ao desempenho na nuvem AWS. Esse benchmarking é descrito nas seções a seguir.
Configuração arquitetônica
A tabela a seguir mostra a configuração ambiental para um cluster Kafka usando NAS.
| Componente de plataforma | Configuração do ambiente |
|---|---|
Kafka 3.2.3 |
|
Sistema operacional em todos os nós |
RHEL8.6 |
Instância NetApp Cloud Volumes ONTAP |
Instância de par HA – m5dn.12xLarge x 2node Instância de nó único – m5dn.12xLarge x 1 nó |
Configuração do volume do cluster NetApp ONTAP
-
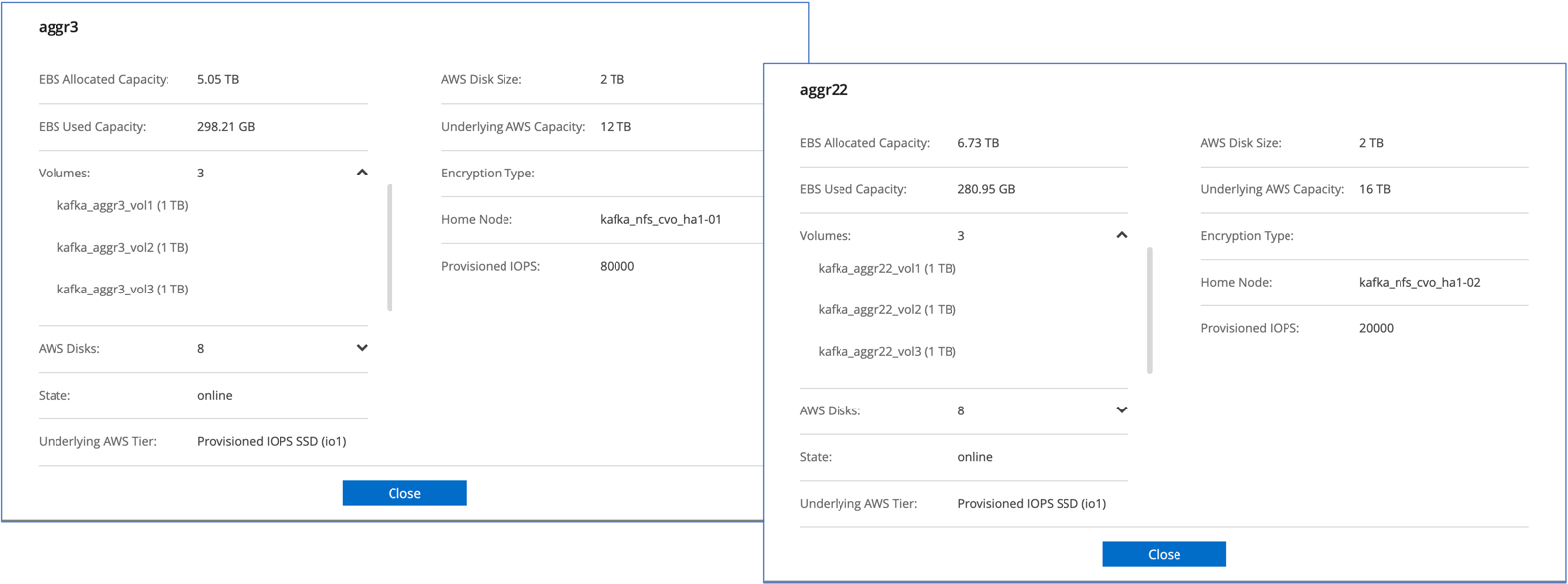
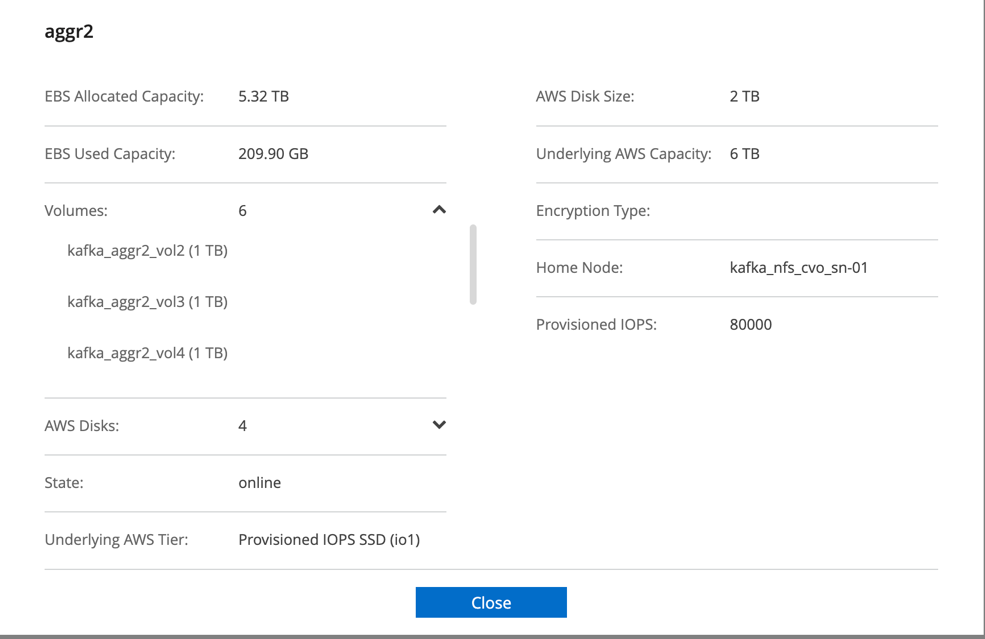
Para o par Cloud Volumes ONTAP HA, criamos dois agregados com três volumes em cada agregado em cada controlador de armazenamento. Para o nó único do Cloud Volumes ONTAP , criamos seis volumes em um agregado.
-
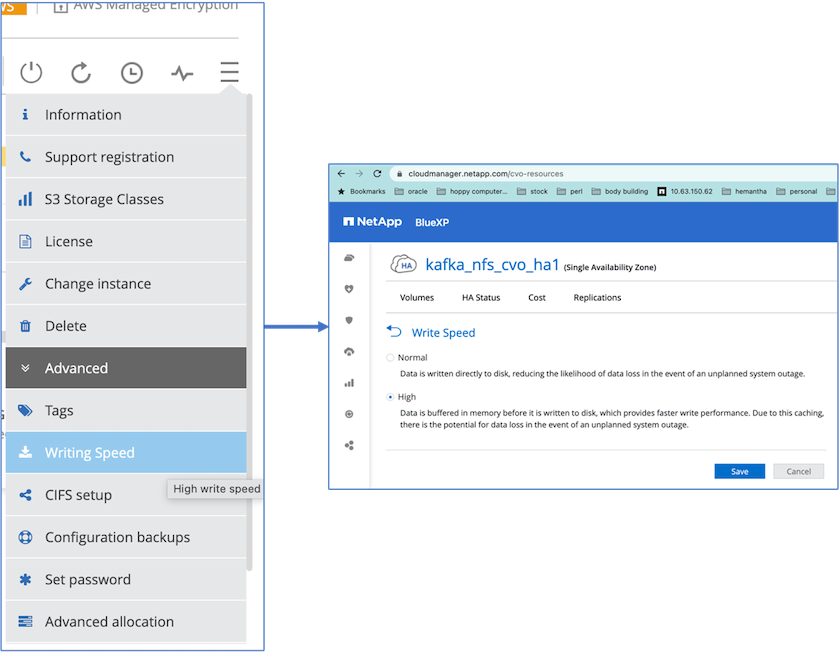
Para obter melhor desempenho de rede, habilitamos a rede de alta velocidade para o par HA e o nó único.
-
Percebemos que a NVRAM ONTAP tinha mais IOPS, então alteramos o IOPS para 2350 para o volume raiz Cloud Volumes ONTAP . O disco de volume raiz no Cloud Volumes ONTAP tinha 47 GB de tamanho. O seguinte comando ONTAP é para o par HA, e a mesma etapa é aplicável para o nó único.
statistics start -object vnvram -instance vnvram -counter backing_store_iops -sample-id sample_555 kafka_nfs_cvo_ha1::*> statistics show -sample-id sample_555 Object: vnvram Instance: vnvram Start-time: 1/18/2023 18:03:11 End-time: 1/18/2023 18:03:13 Elapsed-time: 2s Scope: kafka_nfs_cvo_ha1-01 Counter Value -------------------------------- -------------------------------- backing_store_iops 1479 Object: vnvram Instance: vnvram Start-time: 1/18/2023 18:03:11 End-time: 1/18/2023 18:03:13 Elapsed-time: 2s Scope: kafka_nfs_cvo_ha1-02 Counter Value -------------------------------- -------------------------------- backing_store_iops 1210 2 entries were displayed. kafka_nfs_cvo_ha1::*>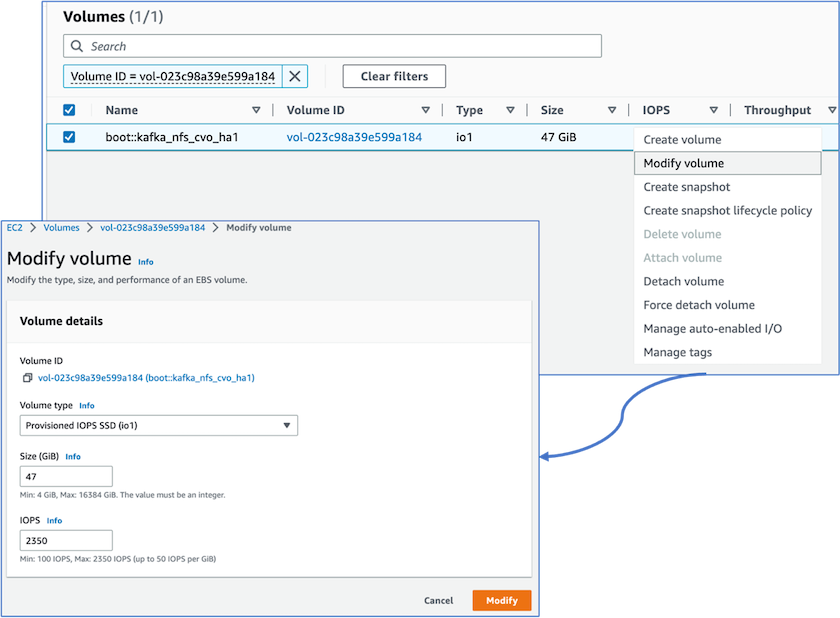
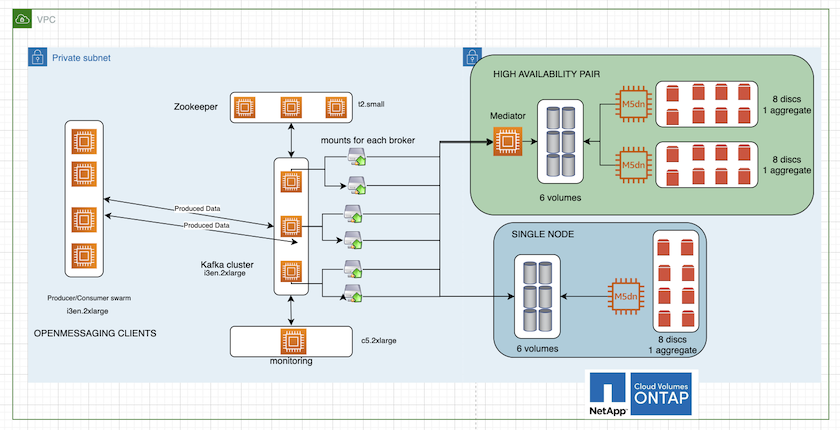
A figura a seguir descreve a arquitetura de um cluster Kafka baseado em NAS.
-
Calcular. Usamos um cluster Kafka de três nós com um conjunto zookeeper de três nós em execução em servidores dedicados. Cada broker tinha dois pontos de montagem NFS para um único volume na instância do Cloud Volumes ONTAP por meio de um LIF dedicado.
-
Monitoramento. Usamos dois nós para uma combinação Prometheus-Grafana. Para gerar cargas de trabalho, usamos um cluster separado de três nós que poderia produzir e consumir neste cluster Kafka.
-
Armazenar. Usamos uma instância ONTAP de volumes em nuvem de par HA com um volume GP3 AWS-EBS de 6 TB montado na instância. O volume foi então exportado para o broker Kafka com uma montagem NFS.
Configurações de benchmarking do OpenMessage
-
Para melhor desempenho do NFS, precisamos de mais conexões de rede entre o servidor NFS e o cliente NFS, que podem ser criadas usando nconnect. Monte os volumes NFS nos nós do broker com a opção nconnect executando o seguinte comando:
[root@ip-172-30-0-121 ~]# cat /etc/fstab UUID=eaa1f38e-de0f-4ed5-a5b5-2fa9db43bb38/xfsdefaults00 /dev/nvme1n1 /mnt/data-1 xfs defaults,noatime,nodiscard 0 0 /dev/nvme2n1 /mnt/data-2 xfs defaults,noatime,nodiscard 0 0 172.30.0.233:/kafka_aggr3_vol1 /kafka_aggr3_vol1 nfs defaults,nconnect=16 0 0 172.30.0.233:/kafka_aggr3_vol2 /kafka_aggr3_vol2 nfs defaults,nconnect=16 0 0 172.30.0.233:/kafka_aggr3_vol3 /kafka_aggr3_vol3 nfs defaults,nconnect=16 0 0 172.30.0.242:/kafka_aggr22_vol1 /kafka_aggr22_vol1 nfs defaults,nconnect=16 0 0 172.30.0.242:/kafka_aggr22_vol2 /kafka_aggr22_vol2 nfs defaults,nconnect=16 0 0 172.30.0.242:/kafka_aggr22_vol3 /kafka_aggr22_vol3 nfs defaults,nconnect=16 0 0 [root@ip-172-30-0-121 ~]# mount -a [root@ip-172-30-0-121 ~]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 31G 0 31G 0% /dev tmpfs 31G 249M 31G 1% /run tmpfs 31G 0 31G 0% /sys/fs/cgroup /dev/nvme0n1p2 10G 2.8G 7.2G 28% / /dev/nvme1n1 2.3T 248G 2.1T 11% /mnt/data-1 /dev/nvme2n1 2.3T 245G 2.1T 11% /mnt/data-2 172.30.0.233:/kafka_aggr3_vol1 1.0T 12G 1013G 2% /kafka_aggr3_vol1 172.30.0.233:/kafka_aggr3_vol2 1.0T 5.5G 1019G 1% /kafka_aggr3_vol2 172.30.0.233:/kafka_aggr3_vol3 1.0T 8.9G 1016G 1% /kafka_aggr3_vol3 172.30.0.242:/kafka_aggr22_vol1 1.0T 7.3G 1017G 1% /kafka_aggr22_vol1 172.30.0.242:/kafka_aggr22_vol2 1.0T 6.9G 1018G 1% /kafka_aggr22_vol2 172.30.0.242:/kafka_aggr22_vol3 1.0T 5.9G 1019G 1% /kafka_aggr22_vol3 tmpfs 6.2G 0 6.2G 0% /run/user/1000 [root@ip-172-30-0-121 ~]#
-
Verifique as conexões de rede no Cloud Volumes ONTAP. O seguinte comando ONTAP é usado a partir do nó Cloud Volumes ONTAP . A mesma etapa é aplicável ao par Cloud Volumes ONTAP HA.
Last login time: 1/20/2023 00:16:29 kafka_nfs_cvo_sn::> network connections active show -service nfs* -fields remote-host node cid vserver remote-host ------------------- ---------- -------------------- ------------ kafka_nfs_cvo_sn-01 2315762628 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762629 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762630 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762631 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762632 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762633 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762634 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762635 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762636 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762637 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762639 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762640 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762641 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762642 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762643 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762644 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762645 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762646 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762647 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762648 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762649 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762650 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762651 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762652 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762653 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762656 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762657 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762658 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762659 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762660 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762661 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762662 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762663 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762664 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762665 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762666 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762667 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762668 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762669 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762670 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762671 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762672 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762673 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762674 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762676 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762677 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762678 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762679 svm_kafka_nfs_cvo_sn 172.30.0.223 48 entries were displayed. kafka_nfs_cvo_sn::>
-
Usamos o seguinte Kafka
server.propertiesem todos os corretores Kafka para o par Cloud Volumes ONTAP HA. Olog.dirsa propriedade é diferente para cada corretor, e as propriedades restantes são comuns para os corretores. Para o broker1, olog.dirso valor é o seguinte:[root@ip-172-30-0-121 ~]# cat /opt/kafka/config/server.properties broker.id=0 advertised.listeners=PLAINTEXT://172.30.0.121:9092 #log.dirs=/mnt/data-1/d1,/mnt/data-1/d2,/mnt/data-1/d3,/mnt/data-2/d1,/mnt/data-2/d2,/mnt/data-2/d3 log.dirs=/kafka_aggr3_vol1/broker1,/kafka_aggr3_vol2/broker1,/kafka_aggr3_vol3/broker1,/kafka_aggr22_vol1/broker1,/kafka_aggr22_vol2/broker1,/kafka_aggr22_vol3/broker1 zookeeper.connect=172.30.0.12:2181,172.30.0.30:2181,172.30.0.178:2181 num.network.threads=64 num.io.threads=64 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 num.partitions=1 num.recovery.threads.per.data.dir=1 offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 replica.fetch.max.bytes=524288000 background.threads=20 num.replica.alter.log.dirs.threads=40 num.replica.fetchers=20 [root@ip-172-30-0-121 ~]#
-
Para o broker2, o
log.dirso valor do imóvel é o seguinte:log.dirs=/kafka_aggr3_vol1/broker2,/kafka_aggr3_vol2/broker2,/kafka_aggr3_vol3/broker2,/kafka_aggr22_vol1/broker2,/kafka_aggr22_vol2/broker2,/kafka_aggr22_vol3/broker2
-
Para o broker3, o
log.dirso valor do imóvel é o seguinte:log.dirs=/kafka_aggr3_vol1/broker3,/kafka_aggr3_vol2/broker3,/kafka_aggr3_vol3/broker3,/kafka_aggr22_vol1/broker3,/kafka_aggr22_vol2/broker3,/kafka_aggr22_vol3/broker3
-
-
Para o nó único do Cloud Volumes ONTAP , o Kafka
servers.propertiesé o mesmo que para o par Cloud Volumes ONTAP HA, exceto paralog.dirspropriedade.-
Para o broker1, o
log.dirso valor é o seguinte:log.dirs=/kafka_aggr2_vol1/broker1,/kafka_aggr2_vol2/broker1,/kafka_aggr2_vol3/broker1,/kafka_aggr2_vol4/broker1,/kafka_aggr2_vol5/broker1,/kafka_aggr2_vol6/broker1
-
Para o broker2, o
log.dirso valor é o seguinte:log.dirs=/kafka_aggr2_vol1/broker2,/kafka_aggr2_vol2/broker2,/kafka_aggr2_vol3/broker2,/kafka_aggr2_vol4/broker2,/kafka_aggr2_vol5/broker2,/kafka_aggr2_vol6/broker2
-
Para o broker3, o
log.dirso valor do imóvel é o seguinte:log.dirs=/kafka_aggr2_vol1/broker3,/kafka_aggr2_vol2/broker3,/kafka_aggr2_vol3/broker3,/kafka_aggr2_vol4/broker3,/kafka_aggr2_vol5/broker3,/kafka_aggr2_vol6/broker3
-
-
A carga de trabalho no OMB é configurada com as seguintes propriedades:
(/opt/benchmark/workloads/1-topic-100-partitions-1kb.yaml).topics: 4 partitionsPerTopic: 100 messageSize: 32768 useRandomizedPayloads: true randomBytesRatio: 0.5 randomizedPayloadPoolSize: 100 subscriptionsPerTopic: 1 consumerPerSubscription: 80 producersPerTopic: 40 producerRate: 1000000 consumerBacklogSizeGB: 0 testDurationMinutes: 5
O
messageSizepode variar para cada caso de uso. Em nosso teste de desempenho, usamos 3K.Usamos dois drivers diferentes, Sync ou Throughput, do OMB para gerar a carga de trabalho no cluster Kafka.
-
O arquivo yaml usado para propriedades do driver de sincronização é o seguinte
(/opt/benchmark/driver- kafka/kafka-sync.yaml):name: Kafka driverClass: io.openmessaging.benchmark.driver.kafka.KafkaBenchmarkDriver # Kafka client-specific configuration replicationFactor: 3 topicConfig: | min.insync.replicas=2 flush.messages=1 flush.ms=0 commonConfig: | bootstrap.servers=172.30.0.121:9092,172.30.0.72:9092,172.30.0.223:9092 producerConfig: | acks=all linger.ms=1 batch.size=1048576 consumerConfig: | auto.offset.reset=earliest enable.auto.commit=false max.partition.fetch.bytes=10485760
-
O arquivo yaml usado para as propriedades do driver Throughput é o seguinte
(/opt/benchmark/driver- kafka/kafka-throughput.yaml):name: Kafka driverClass: io.openmessaging.benchmark.driver.kafka.KafkaBenchmarkDriver # Kafka client-specific configuration replicationFactor: 3 topicConfig: | min.insync.replicas=2 commonConfig: | bootstrap.servers=172.30.0.121:9092,172.30.0.72:9092,172.30.0.223:9092 default.api.timeout.ms=1200000 request.timeout.ms=1200000 producerConfig: | acks=all linger.ms=1 batch.size=1048576 consumerConfig: | auto.offset.reset=earliest enable.auto.commit=false max.partition.fetch.bytes=10485760
-
Metodologia de testes
-
Um cluster Kafka foi provisionado conforme a especificação descrita acima usando Terraform e Ansible. O Terraform é usado para construir a infraestrutura usando instâncias da AWS para o cluster Kafka e o Ansible constrói o cluster Kafka nelas.
-
Uma carga de trabalho OMB foi acionada com a configuração de carga de trabalho descrita acima e o driver Sync.
Sudo bin/benchmark –drivers driver-kafka/kafka- sync.yaml workloads/1-topic-100-partitions-1kb.yaml
-
Outra carga de trabalho foi acionada com o driver Throughput com a mesma configuração de carga de trabalho.
sudo bin/benchmark –drivers driver-kafka/kafka-throughput.yaml workloads/1-topic-100-partitions-1kb.yaml
Observação
Dois tipos diferentes de drivers foram usados para gerar cargas de trabalho para comparar o desempenho de uma instância do Kafka em execução no NFS. A diferença entre os drivers é a propriedade log flush.
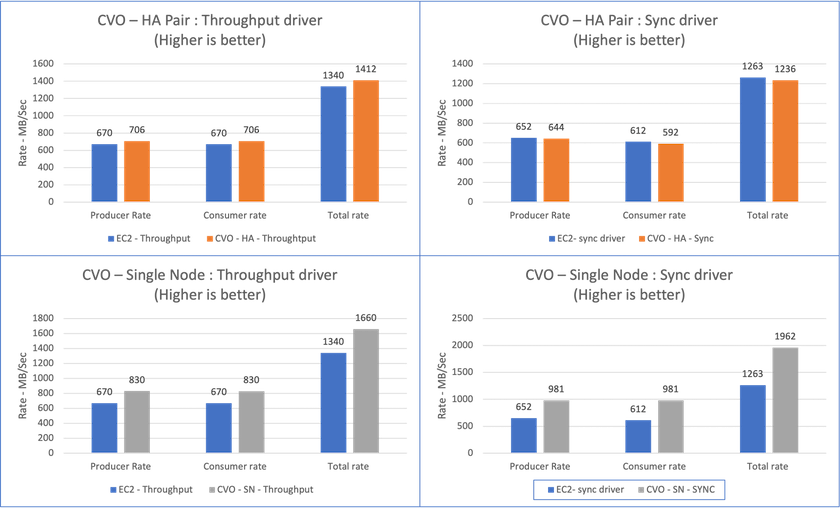
Para um par de Cloud Volumes ONTAP HA:
-
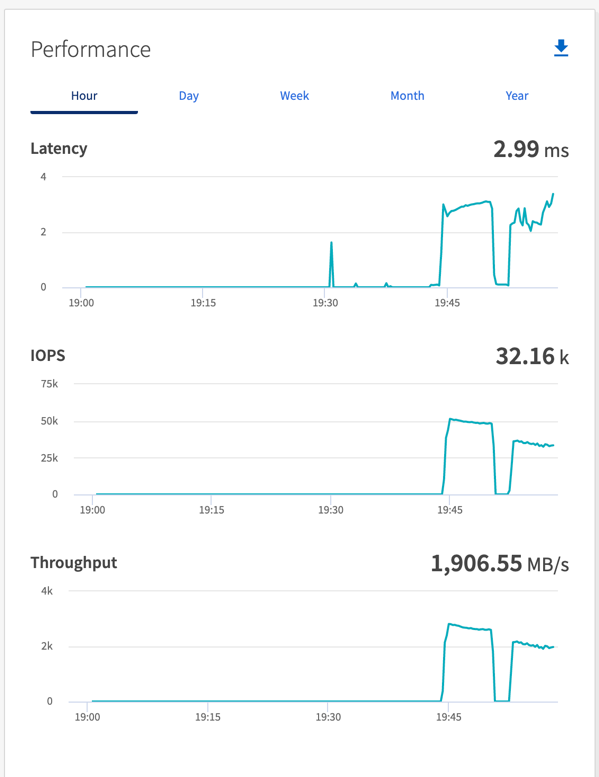
Taxa de transferência total gerada consistentemente pelo driver de sincronização: ~1236 MBps.
-
Taxa de transferência total gerada para o driver de taxa de transferência: pico de ~1412 MBps.
Para um único nó Cloud Volumes ONTAP :
-
Taxa de transferência total gerada consistentemente pelo driver de sincronização: ~ 1962 MBps.
-
Taxa de transferência total gerada pelo driver de taxa de transferência: pico ~1660 MBps
O driver Sync pode gerar uma taxa de transferência consistente, pois os logs são liberados no disco instantaneamente, enquanto o driver Throughput gera picos de taxa de transferência, pois os logs são confirmados no disco em massa.
Esses números de taxa de transferência são gerados para a configuração da AWS fornecida. Para requisitos de desempenho mais altos, os tipos de instância podem ser ampliados e ajustados ainda mais para obter melhores números de taxa de transferência. A produção total ou taxa total é a combinação das taxas do produtor e do consumidor.
Certifique-se de verificar a taxa de transferência de armazenamento ao executar o benchmark de taxa de transferência ou driver de sincronização.