Por que usar o NetApp NFS para cargas de trabalho do Kafka?
 Sugerir alterações
Sugerir alterações
Agora que há uma solução para o problema bobo de renomeação no armazenamento NFS com o Kafka, você pode criar implantações robustas que aproveitam o armazenamento NetApp ONTAP para sua carga de trabalho do Kafka. Isso não apenas reduz significativamente a sobrecarga operacional, mas também traz os seguintes benefícios aos seus clusters Kafka:
-
Utilização reduzida da CPU em corretores Kafka. O uso do armazenamento NetApp ONTAP desagregado separa as operações de E/S de disco do broker e, portanto, reduz sua pegada de CPU.
-
Tempo de recuperação mais rápido do corretor. Como o armazenamento desagregado do NetApp ONTAP é compartilhado entre os nós do broker do Kafka, uma nova instância de computação pode substituir um broker defeituoso a qualquer momento em uma fração do tempo em comparação às implantações convencionais do Kafka, sem reconstruir os dados.
-
Eficiência de armazenamento. Como a camada de armazenamento do aplicativo agora é provisionada pelo NetApp ONTAP, os clientes podem aproveitar todos os benefícios da eficiência de armazenamento que vem com o ONTAP, como compactação, desduplicação e compactação de dados em linha.
Esses benefícios foram testados e validados em casos de teste que discutimos em detalhes nesta seção.
Utilização reduzida da CPU no broker Kafka
Descobrimos que a utilização geral da CPU é menor do que a do DAS quando executamos cargas de trabalho semelhantes em dois clusters Kafka separados que eram idênticos em suas especificações técnicas, mas diferiam em suas tecnologias de armazenamento. Não apenas a utilização geral da CPU é menor quando o cluster Kafka usa armazenamento ONTAP , mas o aumento na utilização da CPU demonstrou um gradiente mais suave do que em um cluster Kafka baseado em DAS.
Configuração arquitetônica
A tabela a seguir mostra a configuração ambiental usada para demonstrar a utilização reduzida da CPU.
| Componente de plataforma | Configuração do ambiente |
|---|---|
Ferramenta de benchmarking do Kafka 3.2.3: OpenMessaging |
|
Sistema operacional em todos os nós |
RHEL 8.7 ou posterior |
Instância NetApp Cloud Volumes ONTAP |
Instância de nó único – M5.2xLarge |
Ferramenta de benchmarking
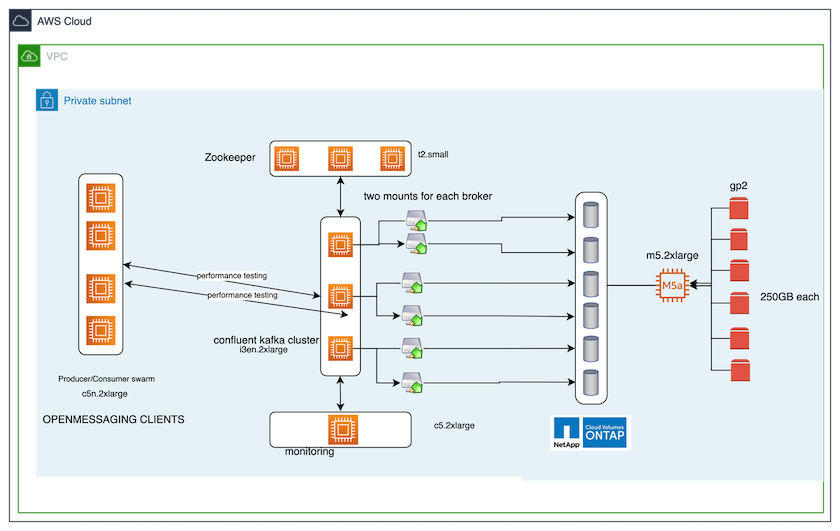
A ferramenta de benchmarking usada neste caso de teste é a "Mensagens abertas" estrutura. O OpenMessaging é neutro em relação a fornecedores e independente de linguagem; ele fornece diretrizes do setor para finanças, comércio eletrônico, IoT e big data; e ajuda a desenvolver aplicativos de mensagens e streaming em sistemas e plataformas heterogêneos. A figura a seguir descreve a interação de clientes do OpenMessaging com um cluster Kafka.
-
Calcular. Usamos um cluster Kafka de três nós com um conjunto zookeeper de três nós em execução em servidores dedicados. Cada broker tinha dois pontos de montagem NFSv4.1 em um único volume na instância NetApp CVO por meio de um LIF dedicado.
-
Monitoramento. Usamos dois nós para uma combinação Prometheus-Grafana. Para gerar cargas de trabalho, temos um cluster separado de três nós que pode produzir e consumir deste cluster Kafka.
-
Armazenar. Usamos uma instância ONTAP de volumes NetApp Cloud de nó único com seis volumes GP2 AWS-EBS de 250 GB montados na instância. Esses volumes foram então expostos ao cluster Kafka como seis volumes NFSv4.1 por meio de LIFs dedicados.
-
Configuração. Os dois elementos configuráveis neste caso de teste foram os corretores Kafka e as cargas de trabalho do OpenMessaging.
-
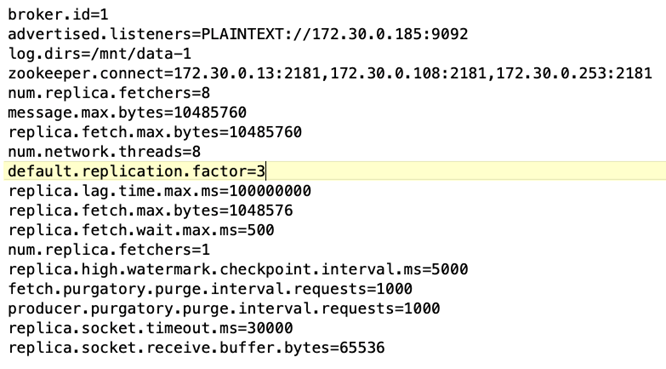
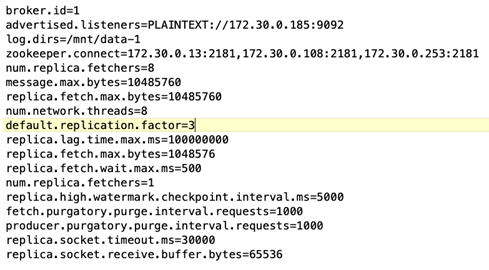
Configuração do corretor As seguintes especificações foram selecionadas para os corretores Kafka. Utilizamos um fator de replicação de 3 para todas as medições, conforme destacado abaixo.
-
-
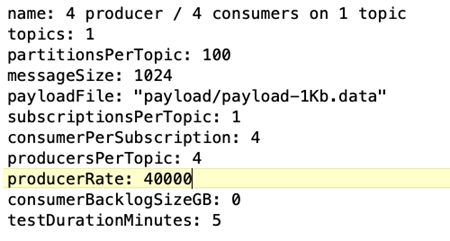
Configuração de carga de trabalho do benchmark OpenMessaging (OMB). As seguintes especificações foram fornecidas. Especificamos uma taxa de produtor alvo, destacada abaixo.
Metodologia de testes
-
Dois clusters semelhantes foram criados, cada um com seu próprio conjunto de enxames de clusters de referência.
-
Grupo 1. Cluster Kafka baseado em NFS.
-
Grupo 2. Cluster Kafka baseado em DAS.
-
-
Usando um comando OpenMessaging, cargas de trabalho semelhantes foram acionadas em cada cluster.
sudo bin/benchmark --drivers driver-kafka/kafka-group-all.yaml workloads/1-topic-100-partitions-1kb.yaml
-
A configuração da taxa de produção foi aumentada em quatro iterações, e a utilização da CPU foi registrada com o Grafana. A taxa de produção foi definida nos seguintes níveis:
-
10.000
-
40.000
-
80.000
-
100.000
-
Observação
Há dois benefícios principais em usar o armazenamento NetApp NFS com o Kafka:
-
Você pode reduzir o uso da CPU em quase um terço. O uso geral da CPU em cargas de trabalho semelhantes foi menor para NFS em comparação aos SSDs DAS; a economia variou de 5% para taxas de produção mais baixas a 32% para taxas de produção mais altas.
-
Uma redução de três vezes no desvio de utilização da CPU em taxas de produção mais altas. Como esperado, houve um aumento na utilização da CPU à medida que as taxas de produção foram aumentadas. No entanto, a utilização da CPU em corretores Kafka usando DAS aumentou de 31% para a menor taxa de produção para 70% para a maior taxa de produção, um aumento de 39%. No entanto, com um backend de armazenamento NFS, a utilização da CPU aumentou de 26% para 38%, um aumento de 12%.
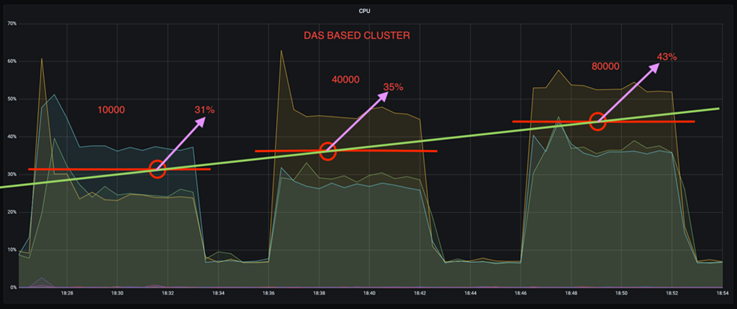
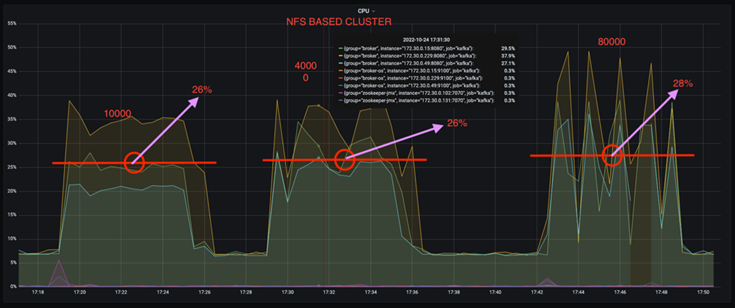
Além disso, com 100.000 mensagens, o DAS mostra mais utilização de CPU do que um cluster NFS.
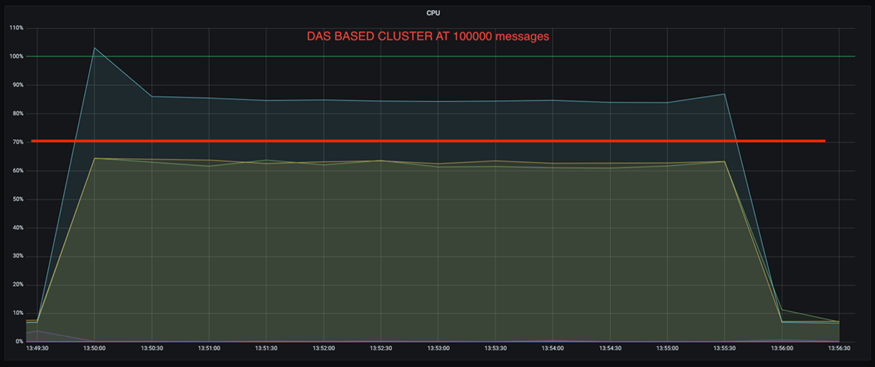
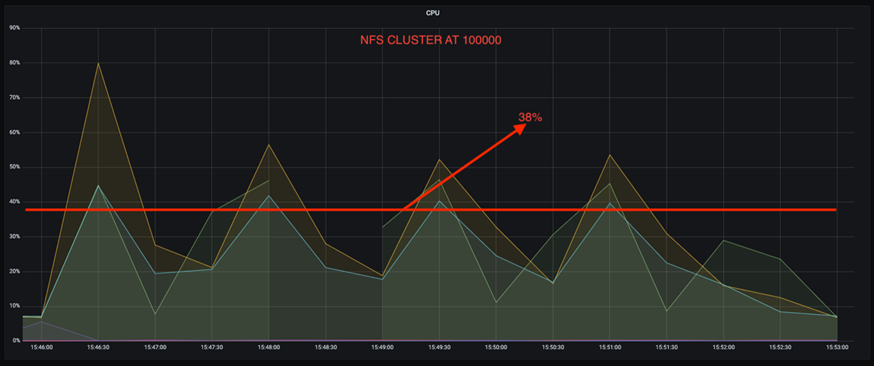
Recuperação mais rápida do corretor
Descobrimos que os corretores do Kafka se recuperam mais rápido quando usam armazenamento NFS compartilhado da NetApp . Quando um broker falha em um cluster do Kafka, esse broker pode ser substituído por um broker íntegro com o mesmo ID de broker. Ao executar este caso de teste, descobrimos que, no caso de um cluster Kafka baseado em DAS, o cluster reconstrói os dados em um broker saudável recém-adicionado, o que consome tempo. No caso de um cluster Kafka baseado em NetApp NFS, o broker substituto continua lendo dados do diretório de log anterior e se recupera muito mais rápido.
Configuração arquitetônica
A tabela a seguir mostra a configuração ambiental para um cluster Kafka usando NAS.
| Componente de plataforma | Configuração do ambiente |
|---|---|
Kafka 3.2.3 |
|
Sistema operacional em todos os nós |
RHEL8.7 ou posterior |
Instância NetApp Cloud Volumes ONTAP |
Instância de nó único – M5.2xLarge |
A figura a seguir descreve a arquitetura de um cluster Kafka baseado em NAS.
-
Calcular. Um cluster Kafka de três nós com um conjunto de zookeepers de três nós em execução em servidores dedicados. Cada broker tem dois pontos de montagem NFS em um único volume na instância NetApp CVO por meio de um LIF dedicado.
-
Monitoramento. Dois nós para uma combinação Prometheus-Grafana. Para gerar cargas de trabalho, usamos um cluster separado de três nós que pode produzir e consumir neste cluster Kafka.
-
Armazenar. Uma instância ONTAP de volumes NetApp Cloud de nó único com seis volumes GP2 AWS-EBS de 250 GB montados na instância. Esses volumes são então expostos ao cluster Kafka como seis volumes NFS por meio de LIFs dedicados.
-
Configuração do corretor. O único elemento configurável neste caso de teste são os corretores Kafka. As seguintes especificações foram selecionadas para os corretores Kafka. O
replica.lag.time.mx.msé definido como um valor alto porque isso determina a rapidez com que um nó específico é retirado da lista ISR. Ao alternar entre nós ruins e saudáveis, você não quer que o ID do broker seja excluído da lista de ISR.
Metodologia de testes
-
Dois clusters semelhantes foram criados:
-
Um cluster confluente baseado em EC2.
-
Um cluster confluente baseado em NetApp NFS.
-
-
Um nó Kafka de espera foi criado com uma configuração idêntica aos nós do cluster Kafka original.
-
Em cada um dos clusters, um tópico de amostra foi criado e aproximadamente 110 GB de dados foram preenchidos em cada um dos corretores.
-
Cluster baseado em EC2. Um diretório de dados do corretor Kafka é mapeado em
/mnt/data-2(Na figura a seguir, Broker-1 do cluster1 [terminal esquerdo]). -
* Cluster baseado em NetApp NFS.* Um diretório de dados do broker Kafka é montado no ponto NFS
/mnt/data(Na figura a seguir, Broker-1 do cluster2 [terminal direito]).
-
-
Em cada um dos clusters, o Broker-1 foi encerrado para acionar um processo de recuperação do broker com falha.
-
Após o encerramento do broker, o endereço IP do broker foi atribuído como um IP secundário ao broker em espera. Isso foi necessário porque um corretor em um cluster Kafka é identificado pelo seguinte:
-
Endereço IP. Atribuído pela reatribuição do IP do broker com falha ao broker em espera.
-
ID do corretor. Isso foi configurado no corretor standby
server.properties.
-
-
Após a atribuição de IP, o serviço Kafka foi iniciado no broker em espera.
-
Depois de um tempo, os logs do servidor foram extraídos para verificar o tempo necessário para construir dados no nó de substituição no cluster.
Observação
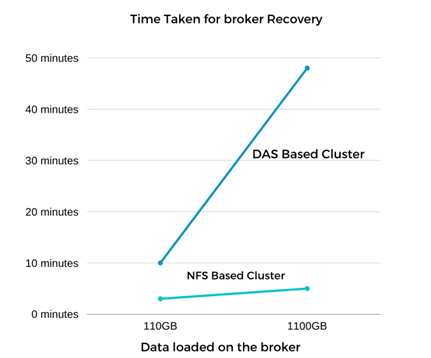
A recuperação do corretor Kafka foi quase nove vezes mais rápida. O tempo necessário para recuperar um nó de broker com falha foi significativamente mais rápido ao usar o armazenamento compartilhado NetApp NFS em comparação ao uso de SSDs DAS em um cluster Kafka. Para 1 TB de dados de tópicos, o tempo de recuperação para um cluster baseado em DAS foi de 48 minutos, em comparação com menos de 5 minutos para um cluster Kafka baseado em NetApp-NFS.
Observamos que o cluster baseado em EC2 levou 10 minutos para reconstruir os 110 GB de dados no novo nó do broker, enquanto o cluster baseado em NFS concluiu a recuperação em 3 minutos. Também observamos nos logs que os deslocamentos do consumidor para as partições do EC2 eram 0, enquanto, no cluster NFS, os deslocamentos do consumidor eram coletados do broker anterior.
[2022-10-31 09:39:17,747] INFO [LogLoader partition=test-topic-51R3EWs-0000-55, dir=/mnt/kafka-data/broker2] Reloading from producer snapshot and rebuilding producer state from offset 583999 (kafka.log.UnifiedLog$) [2022-10-31 08:55:55,170] INFO [LogLoader partition=test-topic-qbVsEZg-0000-8, dir=/mnt/data-1] Loading producer state till offset 0 with message format version 2 (kafka.log.UnifiedLog$)
Cluster baseado em DAS
-
O nó de backup foi iniciado em 08:55:53.730.

-
O processo de reconstrução de dados terminou em 09:05:24.860. O processamento de 110 GB de dados levou aproximadamente 10 minutos.

Cluster baseado em NFS
-
O nó de backup foi iniciado em 09:39:17.213. A entrada de log inicial é destacada abaixo.

-
O processo de reconstrução de dados terminou em 09:42:29.115. O processamento de 110 GB de dados levou aproximadamente 3 minutos.

O teste foi repetido para corretores contendo cerca de 1 TB de dados, o que levou aproximadamente 48 minutos para o DAS e 3 minutos para o NFS. Os resultados são mostrados no gráfico a seguir.
Eficiência de armazenamento
Como a camada de armazenamento do cluster Kafka foi provisionada pelo NetApp ONTAP, obtivemos todos os recursos de eficiência de armazenamento do ONTAP. Isso foi testado gerando uma quantidade significativa de dados em um cluster Kafka com armazenamento NFS provisionado no Cloud Volumes ONTAP. Pudemos ver que houve uma redução significativa de espaço devido aos recursos do ONTAP .
Configuração arquitetônica
A tabela a seguir mostra a configuração ambiental para um cluster Kafka usando NAS.
| Componente de plataforma | Configuração do ambiente |
|---|---|
Kafka 3.2.3 |
|
Sistema operacional em todos os nós |
RHEL8.7 ou posterior |
Instância NetApp Cloud Volumes ONTAP |
Instância de nó único – M5.2xLarge |
A figura a seguir descreve a arquitetura de um cluster Kafka baseado em NAS.
-
Calcular. Usamos um cluster Kafka de três nós com um conjunto zookeeper de três nós em execução em servidores dedicados. Cada corretor tinha dois pontos de montagem NFS em um único volume na instância NetApp CVO por meio de um LIF dedicado.
-
Monitoramento. Usamos dois nós para uma combinação Prometheus-Grafana. Para gerar cargas de trabalho, usamos um cluster separado de três nós que poderia produzir e consumir neste cluster Kafka.
-
Armazenar. Usamos uma instância NetApp Cloud Volumes ONTAP de nó único com seis volumes GP2 AWS-EBS de 250 GB montados na instância. Esses volumes foram então expostos ao cluster Kafka como seis volumes NFS por meio de LIFs dedicados.
-
Configuração. Os elementos configuráveis neste caso de teste foram os corretores Kafka.
A compressão foi desativada pelo produtor, permitindo assim que ele gerasse alto rendimento. A eficiência do armazenamento era gerenciada pela camada de computação.
Metodologia de testes
-
Um cluster Kafka foi provisionado com as especificações mencionadas acima.
-
No cluster, cerca de 350 GB de dados foram produzidos usando a ferramenta OpenMessaging Benchmarking.
-
Após a conclusão da carga de trabalho, as estatísticas de eficiência de armazenamento foram coletadas usando o ONTAP System Manager e a CLI.
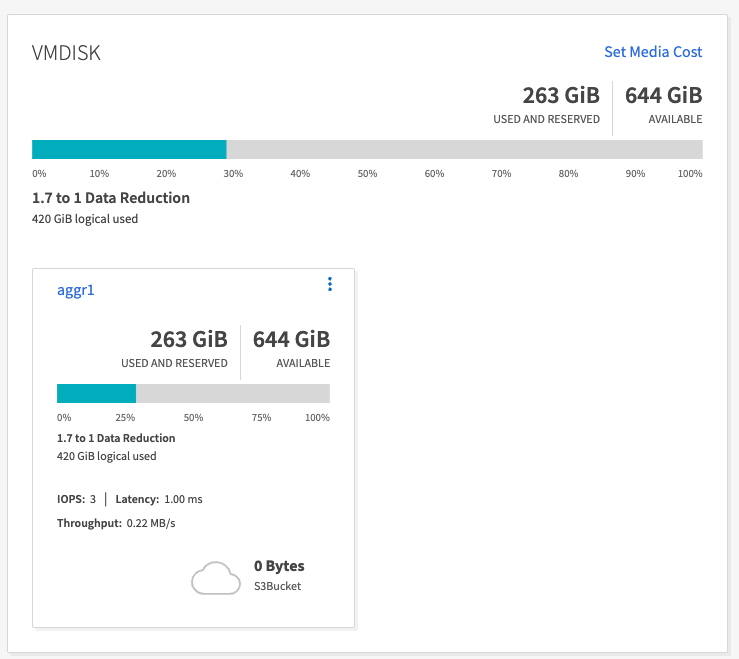
Observação
Para dados gerados usando a ferramenta OMB, observamos uma economia de espaço de ~33%, com uma taxa de eficiência de armazenamento de 1,70:1. Como visto nas figuras a seguir, o espaço lógico utilizado pelos dados produzidos foi de 420,3 GB e o espaço físico utilizado para armazenar os dados foi de 281,7 GB.