

Visão geral da tecnologia
 Sugerir alterações
Sugerir alterações
Esta seção descreve a tecnologia usada nesta solução.
NetApp StorageGRID
O NetApp StorageGRID é uma plataforma de armazenamento de objetos de alto desempenho e econômica. Ao usar o armazenamento em camadas, a maioria dos dados no Confluent Kafka, que são armazenados no armazenamento local ou no armazenamento SAN do broker, são descarregados para o armazenamento de objetos remoto. Essa configuração resulta em melhorias operacionais significativas ao reduzir o tempo e o custo de rebalanceamento, expansão ou redução de clusters ou substituição de um broker com falha. O armazenamento de objetos desempenha um papel importante no gerenciamento de dados que residem na camada de armazenamento de objetos, e é por isso que escolher o armazenamento de objetos correto é importante.
O StorageGRID oferece gerenciamento de dados globais inteligente e orientado por políticas usando uma arquitetura de grade distribuída baseada em nós. Ele simplifica o gerenciamento de petabytes de dados não estruturados e bilhões de objetos por meio de seu onipresente namespace de objetos globais combinado com recursos sofisticados de gerenciamento de dados. O acesso a objetos de chamada única se estende por todos os sites e simplifica arquiteturas de alta disponibilidade, ao mesmo tempo em que garante acesso contínuo a objetos, independentemente de interrupções no site ou na infraestrutura.
A multilocação permite que vários aplicativos de dados corporativos e de nuvem não estruturados sejam atendidos com segurança na mesma grade, aumentando o ROI e os casos de uso do NetApp StorageGRID. Você pode criar vários níveis de serviço com políticas de ciclo de vida de objetos orientadas por metadados, otimizando durabilidade, proteção, desempenho e localidade em várias regiões geográficas. Os usuários podem ajustar as políticas de gerenciamento de dados, além de monitorar e aplicar limites de tráfego para se realinhar com o cenário de dados sem interrupções, conforme seus requisitos mudam em ambientes de TI em constante mudança.
Gerenciamento simples com Grid Manager
O StorageGRID Grid Manager é uma interface gráfica baseada em navegador que permite configurar, gerenciar e monitorar seu sistema StorageGRID em locais distribuídos globalmente em um único painel.
Você pode executar as seguintes tarefas com a interface do StorageGRID Grid Manager:
-
Gerencie repositórios de objetos, como imagens, vídeos e registros, distribuídos globalmente e em escala de petabytes.
-
Monitore nós e serviços de grade para garantir a disponibilidade dos objetos.
-
Gerencie o posicionamento de dados de objetos ao longo do tempo usando regras de gerenciamento do ciclo de vida das informações (ILM). Essas regras controlam o que acontece com os dados de um objeto depois que eles são ingeridos, como eles são protegidos contra perdas, onde os dados do objeto são armazenados e por quanto tempo.
-
Monitore transações, desempenho e operações dentro do sistema.
Políticas de Gestão do Ciclo de Vida da Informação
O StorageGRID tem políticas flexíveis de gerenciamento de dados que incluem manter cópias de réplicas dos seus objetos e usar esquemas de EC (codificação de eliminação) como 2+1 e 4+2 (entre outros) para armazenar seus objetos, dependendo de requisitos específicos de desempenho e proteção de dados. Como as cargas de trabalho e os requisitos mudam ao longo do tempo, é comum que as políticas de ILM também mudem. Modificar políticas de ILM é um recurso essencial, permitindo que os clientes do StorageGRID se adaptem ao seu ambiente em constante mudança de forma rápida e fácil.
Desempenho
O StorageGRID dimensiona o desempenho adicionando mais nós de armazenamento, que podem ser VMs, bare metal ou dispositivos desenvolvidos para esse fim, como o"SG5712, SG5760, SG6060 ou SGF6024" . Em nossos testes, superamos os principais requisitos de desempenho do Apache Kafka com uma grade de três nós de tamanho mínimo usando o dispositivo SGF6024. À medida que os clientes escalam seu cluster Kafka com corretores adicionais, eles podem adicionar mais nós de armazenamento para aumentar o desempenho e a capacidade.
Configuração do balanceador de carga e do endpoint
Os nós de administração no StorageGRID fornecem a interface de usuário (UI) do Grid Manager e o endpoint da API REST para visualizar, configurar e gerenciar seu sistema StorageGRID , bem como logs de auditoria para rastrear a atividade do sistema. Para fornecer um ponto de extremidade S3 de alta disponibilidade para o armazenamento em camadas do Confluent Kafka, implementamos o balanceador de carga StorageGRID , que é executado como um serviço em nós de administração e nós de gateway. Além disso, o balanceador de carga também gerencia o tráfego local e se comunica com o GSLB (Global Server Load Balancing) para ajudar na recuperação de desastres.
Para aprimorar ainda mais a configuração do endpoint, o StorageGRID fornece políticas de classificação de tráfego incorporadas ao nó de administração, permite monitorar o tráfego da carga de trabalho e aplica vários limites de qualidade de serviço (QoS) às suas cargas de trabalho. As políticas de classificação de tráfego são aplicadas aos endpoints no serviço StorageGRID Load Balancer para nós de gateway e nós de administração. Essas políticas podem ajudar na modelagem e monitoramento do tráfego.
Classificação de tráfego no StorageGRID
O StorageGRID tem funcionalidade de QoS integrada. As políticas de classificação de tráfego podem ajudar a monitorar diferentes tipos de tráfego S3 provenientes de um aplicativo cliente. Você pode então criar e aplicar políticas para colocar limites nesse tráfego com base na largura de banda de entrada/saída, no número de solicitações simultâneas de leitura/gravação ou na taxa de solicitações de leitura/gravação.
Apache Kafka
Apache Kafka é uma implementação de framework de um barramento de software que utiliza processamento de fluxo escrito em Java e Scala. O objetivo é fornecer uma plataforma unificada, de alto rendimento e baixa latência para lidar com feeds de dados em tempo real. O Kafka pode se conectar a um sistema externo para exportação e importação de dados por meio do Kafka Connect e fornece fluxos do Kafka, uma biblioteca de processamento de fluxo Java. O Kafka usa um protocolo binário baseado em TCP que é otimizado para eficiência e depende de uma abstração de "conjunto de mensagens" que agrupa mensagens naturalmente para reduzir a sobrecarga da viagem de ida e volta da rede. Isso permite operações de disco sequenciais maiores, pacotes de rede maiores e blocos de memória contíguos, permitindo assim que o Kafka transforme um fluxo contínuo de gravações de mensagens aleatórias em gravações lineares. A figura a seguir descreve o fluxo de dados básico do Apache Kafka.
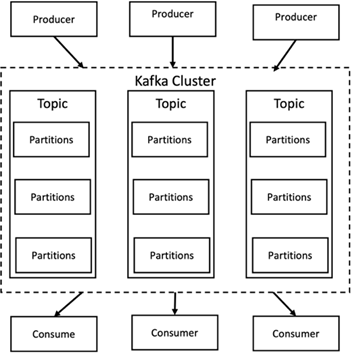
O Kafka armazena mensagens de valor-chave que vêm de um número arbitrário de processos chamados produtores. Os dados podem ser particionados em diferentes partições dentro de diferentes tópicos. Dentro de uma partição, as mensagens são estritamente ordenadas por seus deslocamentos (a posição de uma mensagem dentro de uma partição) e indexadas e armazenadas junto com um registro de data e hora. Outros processos chamados consumidores podem ler mensagens de partições. Para processamento de fluxo, o Kafka oferece a API Streams, que permite escrever aplicativos Java que consomem dados do Kafka e gravam os resultados de volta no Kafka. O Apache Kafka também funciona com sistemas de processamento de fluxo externo, como Apache Apex, Apache Flink, Apache Spark, Apache Storm e Apache NiFi.
O Kafka é executado em um cluster de um ou mais servidores (chamados brokers), e as partições de todos os tópicos são distribuídas entre os nós do cluster. Além disso, as partições são replicadas para vários corretores. Essa arquitetura permite que o Kafka entregue grandes fluxos de mensagens de forma tolerante a falhas e permitiu que ele substituísse alguns dos sistemas de mensagens convencionais, como Java Message Service (JMS), Advanced Message Queuing Protocol (AMQP) e assim por diante. Desde a versão 0.11.0.0, o Kafka oferece gravações transacionais, que fornecem exatamente um processamento de fluxo usando a API Streams.
O Kafka suporta dois tipos de tópicos: regulares e compactados. Tópicos regulares podem ser configurados com um tempo de retenção ou um limite de espaço. Se houver registros mais antigos que o tempo de retenção especificado ou se o limite de espaço for excedido para uma partição, o Kafka poderá excluir dados antigos para liberar espaço de armazenamento. Por padrão, os tópicos são configurados com um tempo de retenção de 7 dias, mas também é possível armazenar dados indefinidamente. Para tópicos compactados, os registros não expiram com base em limites de tempo ou espaço. Em vez disso, o Kafka trata mensagens posteriores como atualizações de mensagens mais antigas com a mesma chave e garante nunca excluir a mensagem mais recente por chave. Os usuários podem excluir mensagens completamente escrevendo uma mensagem de exclusão com o valor nulo para uma chave específica.
Existem cinco APIs principais no Kafka:
-
API do produtor. Permite que um aplicativo publique fluxos de registros.
-
API do consumidor. Permite que um aplicativo assine tópicos e processe fluxos de registros.
-
API do conector. Executa as APIs reutilizáveis de produtor e consumidor que podem vincular os tópicos aos aplicativos existentes.
-
API de fluxos. Esta API converte os fluxos de entrada em saída e produz o resultado.
-
API de administração. Usado para gerenciar tópicos, corretores e outros objetos do Kafka.
As APIs de consumidor e produtor são baseadas no protocolo de mensagens Kafka e oferecem uma implementação de referência para clientes consumidores e produtores Kafka em Java. O protocolo de mensagens subjacente é um protocolo binário que os desenvolvedores podem usar para escrever seus próprios clientes consumidores ou produtores em qualquer linguagem de programação. Isso desbloqueia o Kafka do ecossistema da Máquina Virtual Java (JVM). Uma lista de clientes não Java disponíveis é mantida no wiki do Apache Kafka.
Casos de uso do Apache Kafka
O Apache Kafka é mais popular para mensagens, rastreamento de atividades de sites, métricas, agregação de logs, processamento de fluxo, fornecimento de eventos e registro de confirmações.
-
O Kafka tem melhor produtividade, particionamento integrado, replicação e tolerância a falhas, o que o torna uma boa solução para aplicativos de processamento de mensagens em larga escala.
-
O Kafka pode reconstruir as atividades de um usuário (visualizações de páginas, pesquisas) em um pipeline de rastreamento como um conjunto de feeds de publicação e assinatura em tempo real.
-
O Kafka é frequentemente usado para dados de monitoramento operacional. Isso envolve agregar estatísticas de aplicativos distribuídos para produzir feeds centralizados de dados operacionais.
-
Muitas pessoas usam o Kafka como um substituto para uma solução de agregação de logs. A agregação de log normalmente coleta arquivos de log físicos de servidores e os coloca em um local central (por exemplo, um servidor de arquivos ou HDFS) para processamento. O Kafka abstrai detalhes de arquivos e fornece uma abstração mais limpa de dados de log ou evento como um fluxo de mensagens. Isso permite um processamento de menor latência e suporte mais fácil para múltiplas fontes de dados e consumo de dados distribuídos.
-
Muitos usuários do Kafka processam dados em pipelines de processamento que consistem em vários estágios, nos quais dados de entrada brutos são consumidos de tópicos do Kafka e então agregados, enriquecidos ou transformados em novos tópicos para consumo posterior ou processamento de acompanhamento. Por exemplo, um pipeline de processamento para recomendar artigos de notícias pode rastrear o conteúdo do artigo de feeds RSS e publicá-lo em um tópico "artigos". O processamento posterior pode normalizar ou desduplicar esse conteúdo e publicar o conteúdo do artigo limpo em um novo tópico, e um estágio de processamento final pode tentar recomendar esse conteúdo aos usuários. Esses pipelines de processamento criam gráficos de fluxos de dados em tempo real com base em tópicos individuais.
-
O sourcing de eventos é um estilo de design de aplicativo no qual as alterações de estado são registradas como uma sequência de registros ordenada por tempo. O suporte do Kafka para grandes volumes de dados de log armazenados o torna um excelente backend para um aplicativo criado nesse estilo.
-
O Kafka pode servir como um tipo de log de confirmação externo para um sistema distribuído. O log ajuda a replicar dados entre nós e atua como um mecanismo de ressincronização para nós com falha restaurarem seus dados. O recurso de compactação de log no Kafka ajuda a dar suporte a esse caso de uso.
Confluente
A Confluent Platform é uma plataforma pronta para empresas que complementa o Kafka com recursos avançados projetados para ajudar a acelerar o desenvolvimento e a conectividade de aplicativos, permitir transformações por meio do processamento de fluxo, simplificar as operações empresariais em escala e atender a requisitos arquitetônicos rigorosos. Desenvolvido pelos criadores originais do Apache Kafka, o Confluent expande os benefícios do Kafka com recursos de nível empresarial, ao mesmo tempo em que elimina o fardo do gerenciamento ou monitoramento do Kafka. Hoje, mais de 80% das empresas da Fortune 100 são alimentadas por tecnologia de streaming de dados, e a maioria delas usa Confluent.
Por que Confluent?
Ao integrar dados históricos e em tempo real em uma única fonte central de verdade, a Confluent facilita a criação de uma categoria inteiramente nova de aplicativos modernos e orientados a eventos, obtém um pipeline de dados universal e desbloqueia novos e poderosos casos de uso com total escalabilidade, desempenho e confiabilidade.
Para que é usado o Confluent?
A Confluent Platform permite que você se concentre em como extrair valor comercial dos seus dados em vez de se preocupar com a mecânica subjacente, como a forma como os dados estão sendo transportados ou integrados entre sistemas distintos. Especificamente, a Confluent Platform simplifica a conexão de fontes de dados ao Kafka, a criação de aplicativos de streaming, bem como a proteção, o monitoramento e o gerenciamento da sua infraestrutura Kafka. Hoje, a Confluent Platform é usada para uma ampla gama de casos de uso em vários setores, desde serviços financeiros, varejo omnicanal e carros autônomos até detecção de fraudes, microsserviços e IoT.
A figura a seguir mostra os componentes da plataforma Confluent Kafka.
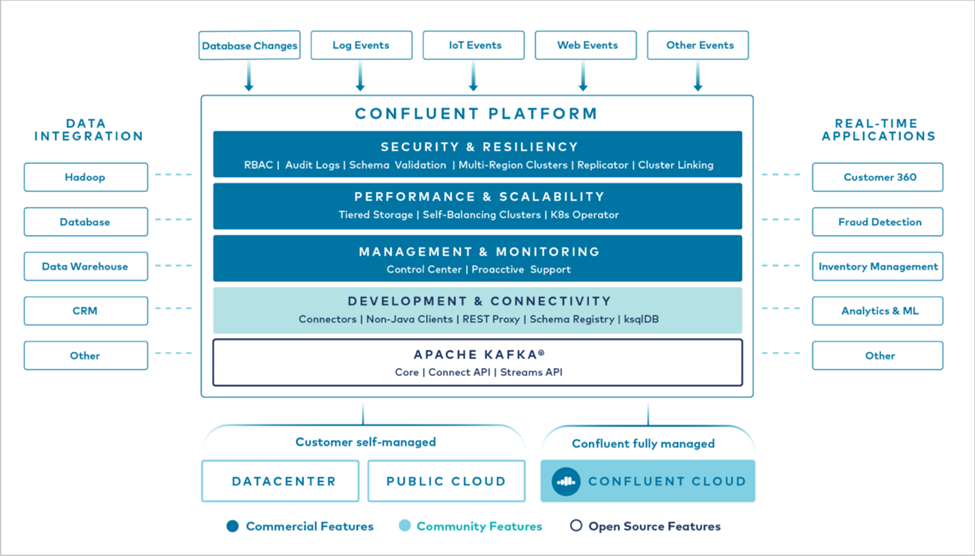
Visão geral da tecnologia de streaming de eventos da Confluent
No centro da Plataforma Confluent está "Apache Kafka" , a plataforma de streaming distribuída de código aberto mais popular. Os principais recursos do Kafka são os seguintes:
-
Publique e assine fluxos de registros.
-
Armazene fluxos de registros de forma tolerante a falhas.
-
Processar fluxos de registros.
Pronto para uso, o Confluent Platform também inclui Schema Registry, REST Proxy, mais de 100 conectores Kafka pré-criados e ksqlDB.
Visão geral dos recursos empresariais da plataforma Confluent
-
Centro de Controle Confluente. Um sistema baseado em GUI para gerenciar e monitorar o Kafka. Ele permite que você gerencie facilmente o Kafka Connect e crie, edite e gerencie conexões com outros sistemas.
-
Confluent para Kubernetes. Confluent for Kubernetes é um operador do Kubernetes. Os operadores do Kubernetes estendem os recursos de orquestração do Kubernetes, fornecendo recursos e requisitos exclusivos para um aplicativo de plataforma específico. Para a Confluent Platform, isso inclui simplificar bastante o processo de implantação do Kafka no Kubernetes e automatizar tarefas típicas do ciclo de vida da infraestrutura.
-
Conectores confluentes para Kafka. Os conectores usam a API do Kafka Connect para conectar o Kafka a outros sistemas, como bancos de dados, armazenamentos de chave-valor, índices de pesquisa e sistemas de arquivos. O Confluent Hub tem conectores para download para as fontes e coletores de dados mais populares, incluindo versões totalmente testadas e suportadas desses conectores com a Confluent Platform. Mais detalhes podem ser encontrados "aqui" .
-
Aglomerados autobalanceados. Fornece balanceamento de carga automatizado, detecção de falhas e autocorreção. Ele fornece suporte para adicionar ou desativar corretores conforme necessário, sem ajuste manual.
-
Ligação de cluster confluente. Conecta clusters diretamente e espelha tópicos de um cluster para outro por meio de uma ponte de link. A vinculação de clusters simplifica a configuração de implantações de vários datacenters, vários clusters e nuvens híbridas.
-
Balanceador automático de dados Confluent. Monitora seu cluster quanto ao número de corretores, ao tamanho das partições, ao número de partições e ao número de líderes dentro do cluster. Ele permite que você transfira dados para criar uma carga de trabalho uniforme em seu cluster, ao mesmo tempo em que reequilibra o tráfego para minimizar o efeito nas cargas de trabalho de produção durante o rebalanceamento.
-
Replicador confluente. Torna mais fácil do que nunca manter vários clusters Kafka em vários data centers.
-
Armazenamento em camadas. Oferece opções para armazenar grandes volumes de dados do Kafka usando seu provedor de nuvem favorito, reduzindo assim a carga operacional e os custos. Com o armazenamento em camadas, você pode manter dados em armazenamento de objetos econômico e escalar corretores somente quando precisar de mais recursos de computação.
-
Cliente JMS Confluent. A Confluent Platform inclui um cliente compatível com JMS para Kafka. Este cliente Kafka implementa a API padrão do JMS 1.1, usando corretores Kafka como backend. Isso é útil se você tiver aplicativos legados usando JMS e quiser substituir o broker de mensagens JMS existente pelo Kafka.
-
Proxy MQTT Confluent. Fornece uma maneira de publicar dados diretamente no Kafka a partir de dispositivos e gateways MQTT sem a necessidade de um broker MQTT no meio.
-
Plugins de segurança Confluent. Os plugins de segurança Confluent são usados para adicionar recursos de segurança a várias ferramentas e produtos da plataforma Confluent. Atualmente, há um plugin disponível para o proxy REST do Confluent que ajuda a autenticar as solicitações recebidas e a propagar o principal autenticado para as solicitações ao Kafka. Isso permite que os clientes proxy REST da Confluent utilizem os recursos de segurança multilocatários do broker Kafka.