

Visão geral das soluções NetApp Spark
 Sugerir alterações
Sugerir alterações
A NetApp tem três portfólios de armazenamento: FAS/ AFF, E-Series e Cloud Volumes ONTAP. Validamos o AFF e o E-Series com sistema de armazenamento ONTAP para soluções Hadoop com Apache Spark.
A estrutura de dados alimentada pela NetApp integra serviços e aplicativos de gerenciamento de dados (blocos de construção) para acesso, controle, proteção e segurança de dados, conforme mostrado na figura abaixo.
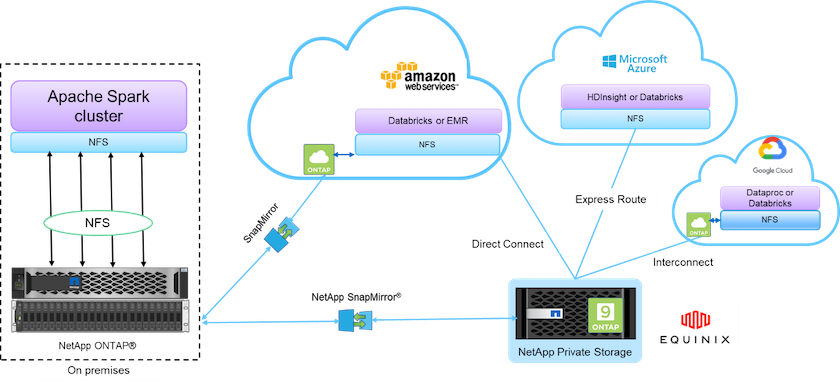
Os blocos de construção na figura acima incluem:
-
* Acesso direto ao NetApp NFS.* Fornece os clusters Hadoop e Spark mais recentes com acesso direto aos volumes NetApp NFS sem requisitos adicionais de software ou driver.
-
* NetApp Cloud Volumes ONTAP e Google Cloud NetApp Volumes.* Armazenamento conectado definido por software baseado em ONTAP em execução no Amazon Web Services (AWS) ou no Azure NetApp Files (ANF) nos serviços de nuvem do Microsoft Azure.
-
* Tecnologia NetApp SnapMirror .* Fornece recursos de proteção de dados entre instâncias locais e ONTAP Cloud ou NPS.
-
Provedores de serviços em nuvem. Esses provedores incluem AWS, Microsoft Azure, Google Cloud e IBM Cloud.
-
PaaS. Serviços de análise baseados em nuvem, como Amazon Elastic MapReduce (EMR) e Databricks na AWS, bem como Microsoft Azure HDInsight e Azure Databricks.
A figura a seguir descreve a solução Spark com armazenamento NetApp .
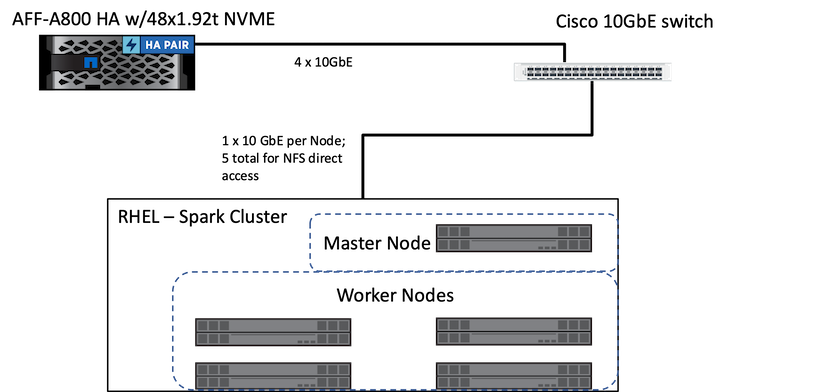
A solução ONTAP Spark usa o protocolo de acesso direto NetApp NFS para análises no local e fluxos de trabalho de IA, ML e DL usando acesso a dados de produção existentes. Os dados de produção disponíveis para os nós do Hadoop são exportados para executar tarefas analíticas e de IA, ML e DL no local. Você pode acessar dados para processar em nós do Hadoop com acesso direto ao NetApp NFS ou sem ele. No Spark com o autônomo ou yarn gerenciador de cluster, você pode configurar um volume NFS usando file://<target_volume> . Validamos três casos de uso com diferentes conjuntos de dados. Os detalhes dessas validações são apresentados na seção "Resultados dos testes". (referência externa)
A figura a seguir descreve o posicionamento do armazenamento do NetApp Apache Spark/Hadoop.
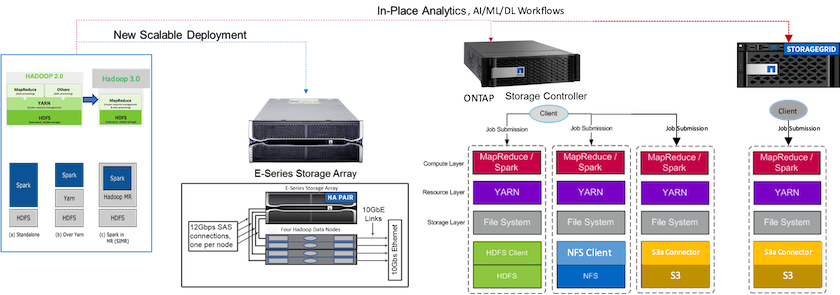
Identificamos os recursos exclusivos da solução E-Series Spark, da solução AFF/ FAS ONTAP Spark e da solução StorageGRID Spark, e realizamos validação e testes detalhados. Com base em nossas observações, a NetApp recomenda a solução E-Series para instalações greenfield e novas implantações escaláveis e a solução AFF/ FAS para análises no local, cargas de trabalho de IA, ML e DL usando dados NFS existentes, e StorageGRID para IA, ML e DL e análises de dados modernas quando o armazenamento de objetos for necessário.
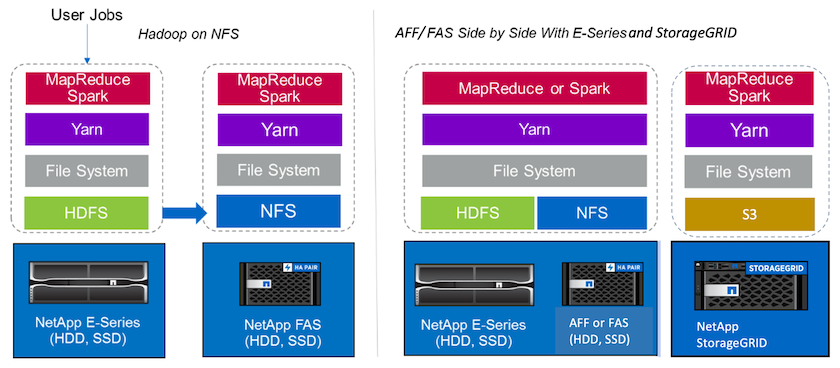
Um data lake é um repositório de armazenamento para grandes conjuntos de dados em formato nativo que pode ser usado para tarefas de análise, IA, ML e DL. Criamos um repositório de data lake para as soluções Spark E-Series, AFF/ FAS e StorageGRID SG6060. O sistema E-Series fornece acesso HDFS ao cluster Hadoop Spark, enquanto os dados de produção existentes são acessados por meio do protocolo de acesso direto NFS ao cluster Hadoop. Para conjuntos de dados que residem no armazenamento de objetos, o NetApp StorageGRID fornece acesso seguro S3 e S3a.