

Desempenho do SmartStore de site único
 Sugerir alterações
Sugerir alterações
Esta seção descreve o desempenho do Splunk SmartStore em um controlador NetApp StorageGRID . O Splunk SmartStore move dados quentes para armazenamento remoto, que neste caso é o armazenamento de objetos StorageGRID na validação de desempenho.
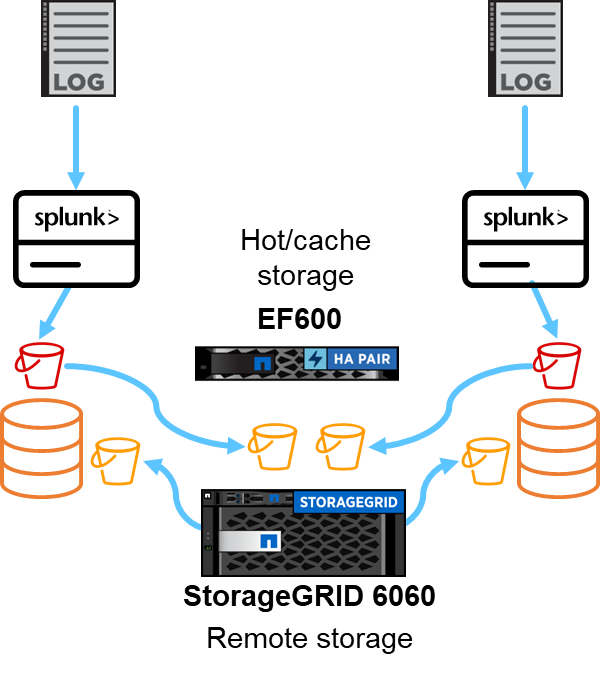
Usamos o EF600 para armazenamento hot/cache e o StorageGRID 6060 para armazenamento remoto. Usamos a seguinte arquitetura para a validação de desempenho. Usamos dois cabeçotes de pesquisa, quatro encaminhadores pesados para encaminhar os dados aos indexadores, sete geradores de eventos Splunk (Eventgens) para gerar os dados em tempo real e 18 indexadores para armazenar os dados.
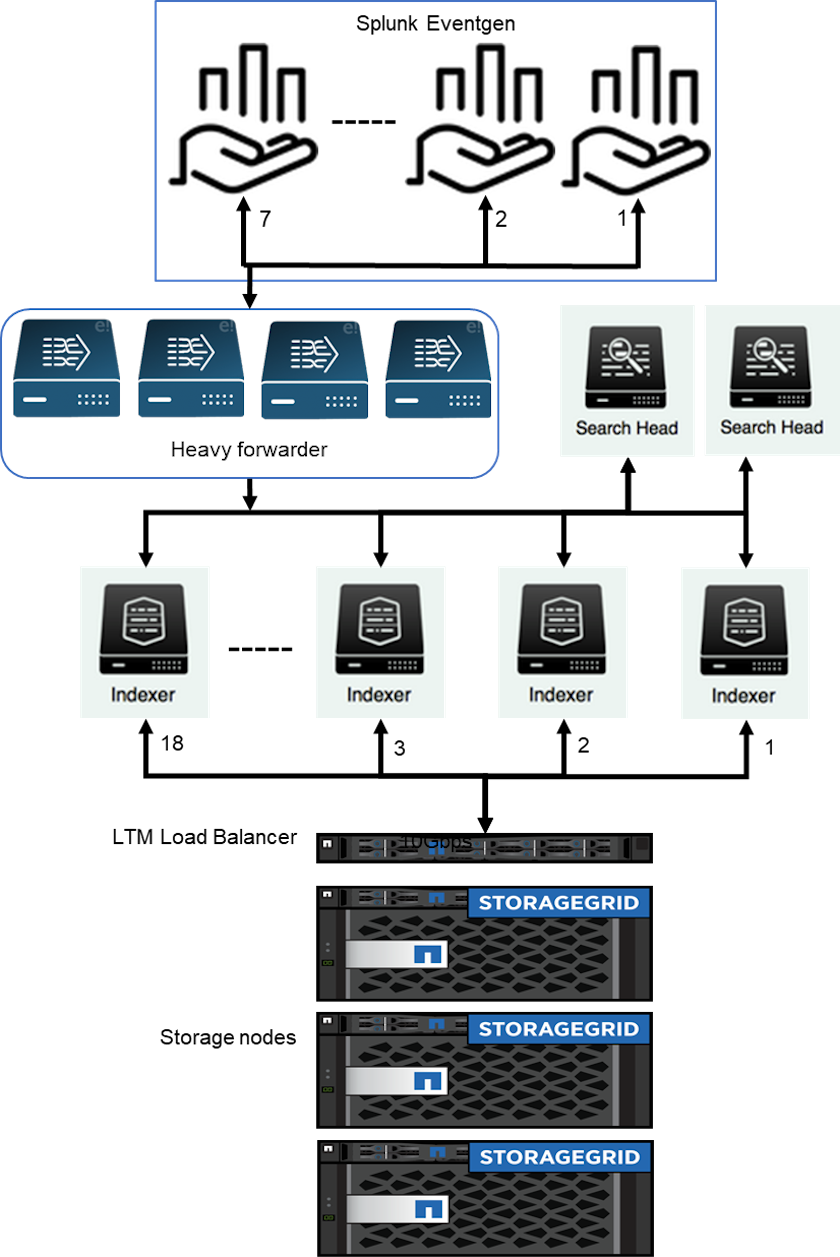
Configuração
Esta tabela lista o hardware usado para a validação de desempenho do SmartStorage.
| Componente Splunk | Tarefa | Quantidade | Núcleos | Memória | SO |
|---|---|---|---|---|---|
Forwarder pesado |
Responsável por ingerir dados e encaminhá-los aos indexadores |
4 |
16 núcleos |
32 GB de RAM |
TRENÓ 15 SP2 |
Indexador |
Gerencia os dados do usuário |
18 |
16 núcleos |
32 GB de RAM |
TRENÓ 15 SP2 |
Cabeçalho de pesquisa |
O front-end do usuário pesquisa dados em indexadores |
2 |
16 núcleos |
32 GB de RAM |
TRENÓ 15 SP2 |
Implantador de cabeça de pesquisa |
Lida com atualizações para clusters de cabeçalhos de pesquisa |
1 |
16 núcleos |
32 GB de RAM |
TRENÓ 15 SP2 |
Mestre do cluster |
Gerencia a instalação e os indexadores do Splunk |
1 |
16 núcleos |
32 GB de RAM |
TRENÓ 15 SP2 |
Console de monitoramento e mestre de licenças |
Executa monitoramento centralizado de toda a implantação do Splunk e gerencia licenças do Splunk |
1 |
16 núcleos |
32 GB de RAM |
TRENÓ 15 SP2 |
Validação de desempenho da loja remota SmartStore
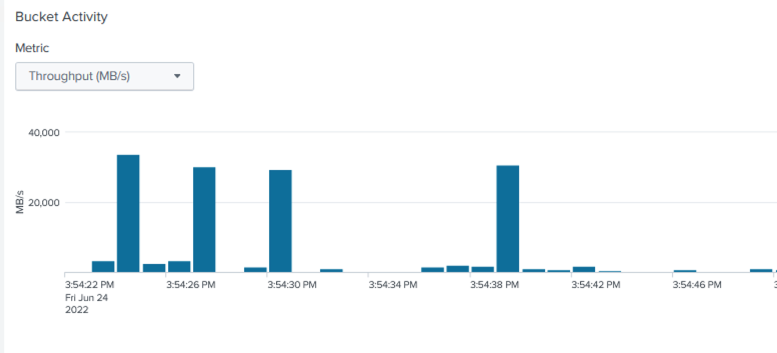
Nesta validação de desempenho, configuramos o cache do SmartStore no armazenamento local em todos os indexadores para 10 dias de dados. Nós habilitamos o maxDataSize=auto (tamanho do bucket de 750 MB) no gerenciador de cluster do Splunk e enviou as alterações para todos os indexadores. Para medir o desempenho de upload, ingerimos 10 TB por dia durante 10 dias e transferimos todos os hot buckets para aquecer ao mesmo tempo e capturamos o pico e a média de transferência por instância e em toda a implantação no painel do SmartStore Monitoring Console.
Esta imagem mostra os dados ingeridos em um dia.
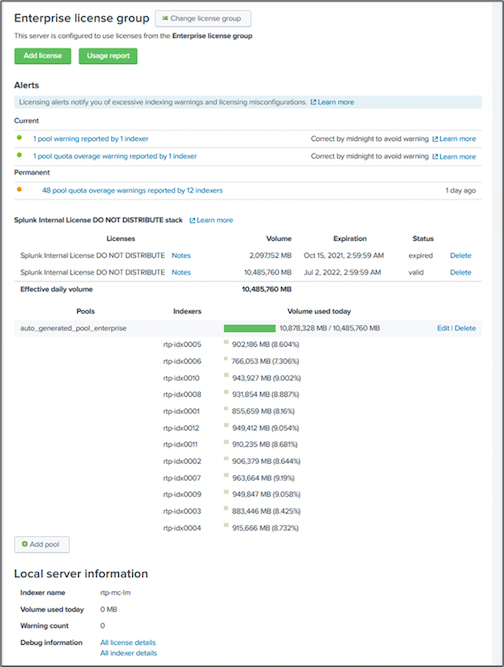
Executamos o seguinte comando do mestre do cluster (o nome do índice é eventgen-test ). Em seguida, capturamos o pico e a média de transferência de upload por instância e em toda a implantação por meio dos painéis do SmartStore Monitoring Console.
for i in rtp-idx0001 rtp-idx0002 rtp-idx0003 rtp-idx0004 rtp-idx0005 rtp-idx0006 rtp-idx0007 rtp-idx0008 rtp-idx0009 rtp-idx0010 rtp-idx0011 rtp-idx0012 rtp-idx0013011 rtdx0014 rtp-idx0015 rtp-idx0016 rtp-idx0017 rtp-idx0018 ; do ssh $i "hostname; date; /opt/splunk/bin/splunk _internal call /data/indexes/eventgen-test/roll-hot-buckets -auth admin:12345678; sleep 1 "; done

|
O mestre do cluster tem autenticação sem senha para todos os indexadores (rtp-idx0001…rtp-idx0018). |
Para medir o desempenho do download, removemos todos os dados do cache executando a CLI evict duas vezes usando o seguinte comando.
|
|
Executamos o seguinte comando no mestre do cluster e executamos a pesquisa no cabeçalho de pesquisa sobre 10 dias de dados do armazenamento remoto do StorageGRID. Em seguida, capturamos o pico e a média de transferência de upload por instância e em toda a implantação por meio dos painéis do SmartStore Monitoring Console. |
for i in rtp-idx0001 rtp-idx0002 rtp-idx0003 rtp-idx0004 rtp-idx0005 rtp-idx0006 rtp-idx0007 rtp-idx0008 rtp-idx0009 rtp-idx0010 rtp-idx0011 rtp-idx0012 rtp-idx0013 rtp-idx0014 rtp-idx0015 rtp-idx0016 rtp-idx0017 rtp-idx0018 ; do ssh $i " hostname; date; /opt/splunk/bin/splunk _internal call /services/admin/cacheman/_evict -post:mb 1000000000 -post:path /mnt/EF600 -method POST -auth admin:12345678; "; done
As configurações do indexador foram enviadas do mestre do cluster SmartStore. O mestre do cluster tinha a seguinte configuração para o indexador.
Rtp-cm01:~ # cat /opt/splunk/etc/master-apps/_cluster/local/indexes.conf [default] maxDataSize = auto #defaultDatabase = eventgen-basic defaultDatabase = eventgen-test hotlist_recency_secs = 864000 repFactor = auto [volume:remote_store] storageType = remote path = s3://smartstore2 remote.s3.access_key = U64TUHONBNC98GQGL60R remote.s3.secret_key = UBoXNE0jmECie05Z7iCYVzbSB6WJFckiYLcdm2yg remote.s3.endpoint = 3.sddc.netapp.com:10443 remote.s3.signature_version = v2 remote.s3.clientCert = [eventgen-basic] homePath = $SPLUNK_DB/eventgen-basic/db coldPath = $SPLUNK_DB/eventgen-basic/colddb thawedPath = $SPLUNK_DB/eventgen-basic/thawed [eventgen-migration] homePath = $SPLUNK_DB/eventgen-scale/db coldPath = $SPLUNK_DB/eventgen-scale/colddb thawedPath = $SPLUNK_DB/eventgen-scale/thaweddb [main] homePath = $SPLUNK_DB/$_index_name/db coldPath = $SPLUNK_DB/$_index_name/colddb thawedPath = $SPLUNK_DB/$_index_name/thaweddb [history] homePath = $SPLUNK_DB/$_index_name/db coldPath = $SPLUNK_DB/$_index_name/colddb thawedPath = $SPLUNK_DB/$_index_name/thaweddb [summary] homePath = $SPLUNK_DB/$_index_name/db coldPath = $SPLUNK_DB/$_index_name/colddb thawedPath = $SPLUNK_DB/$_index_name/thaweddb [remote-test] homePath = $SPLUNK_DB/$_index_name/db coldPath = $SPLUNK_DB/$_index_name/colddb #for storagegrid config remotePath = volume:remote_store/$_index_name thawedPath = $SPLUNK_DB/$_index_name/thaweddb [eventgen-test] homePath = $SPLUNK_DB/$_index_name/db maxDataSize=auto maxHotBuckets=1 maxWarmDBCount=2 coldPath = $SPLUNK_DB/$_index_name/colddb #for storagegrid config remotePath = volume:remote_store/$_index_name thawedPath = $SPLUNK_DB/$_index_name/thaweddb [eventgen-evict-test] homePath = $SPLUNK_DB/$_index_name/db coldPath = $SPLUNK_DB/$_index_name/colddb #for storagegrid config remotePath = volume:remote_store/$_index_name thawedPath = $SPLUNK_DB/$_index_name/thaweddb maxDataSize = auto_high_volume maxWarmDBCount = 5000 rtp-cm01:~ #
Executamos a seguinte consulta de pesquisa no cabeçalho de pesquisa para coletar a matriz de desempenho.
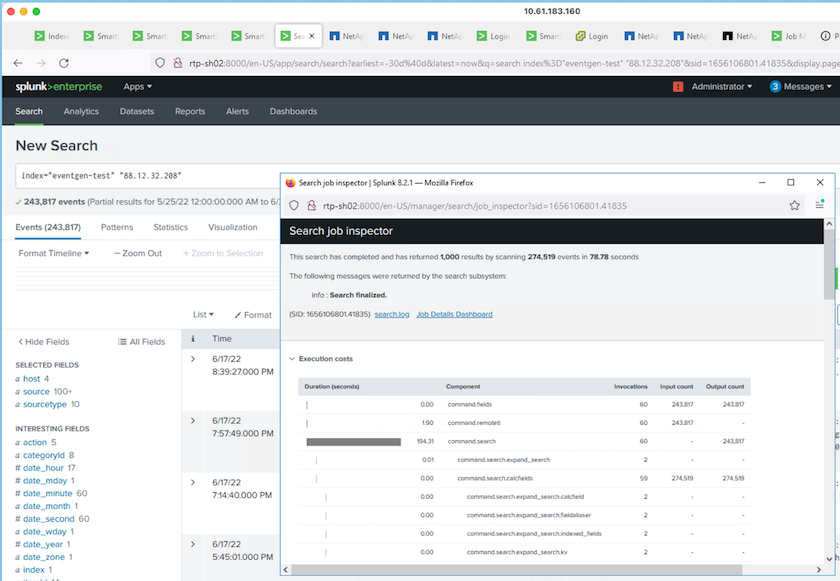
Coletamos as informações de desempenho do mestre do cluster. O desempenho máximo foi de 61,34 GBps.
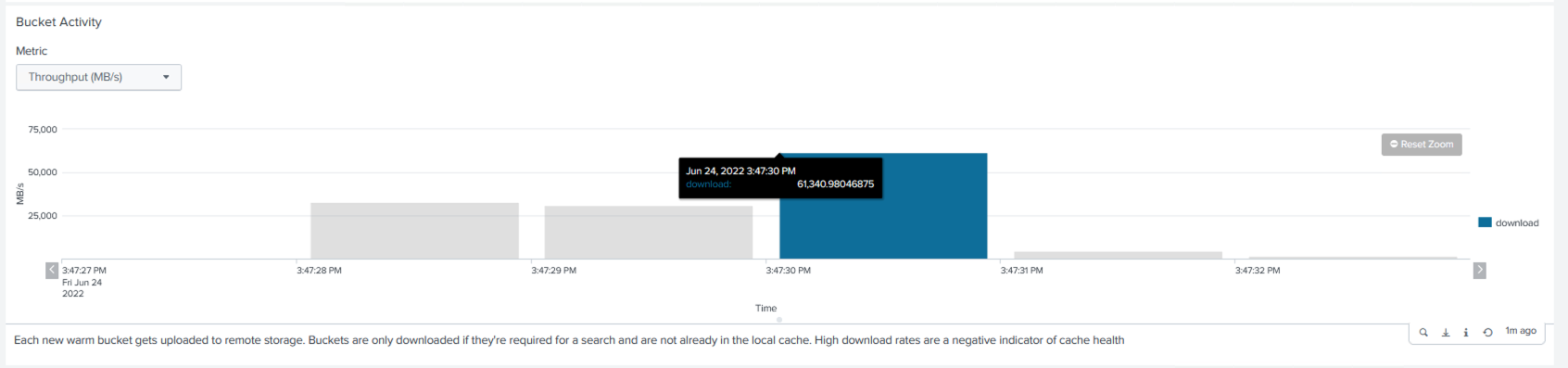
O desempenho médio foi de aproximadamente 29 GBps.
Desempenho do StorageGRID
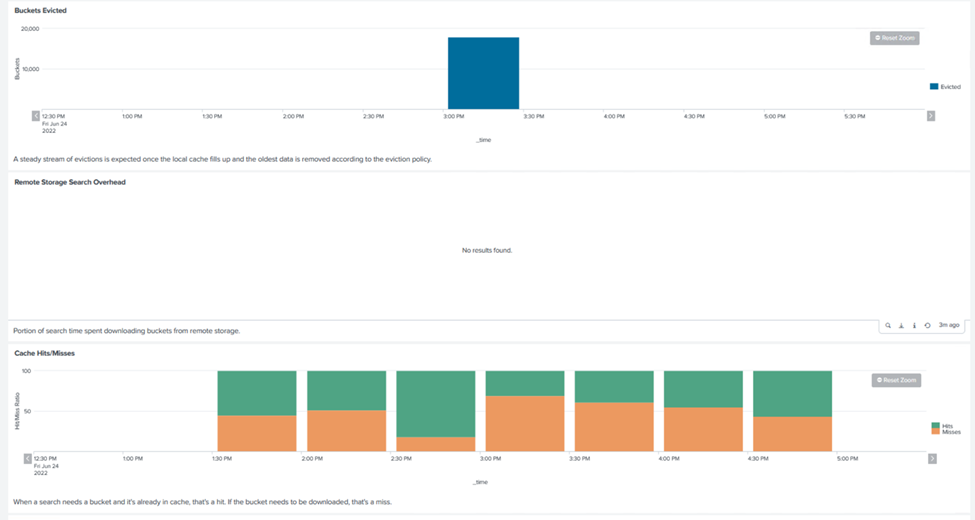
O desempenho do SmartStore é baseado na busca de padrões e sequências de caracteres específicos em grandes quantidades de dados. Nesta validação, os eventos são gerados usando "Eventgen" em um índice Splunk específico (eventgen-test) por meio do cabeçalho de pesquisa, e a solicitação vai para o StorageGRID para a maioria das consultas. A imagem a seguir mostra os acertos e erros dos dados da consulta. Os dados de acertos são do disco local e os dados de erros são do controlador StorageGRID .
|
|
A cor verde mostra os dados de acertos e a cor laranja mostra os dados de erros. |
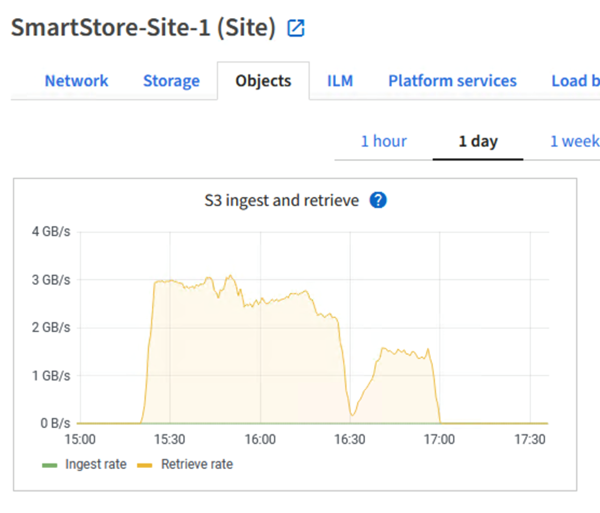
Quando a consulta é executada para a pesquisa no StorageGRID, o tempo para a taxa de recuperação do S3 do StorageGRID é mostrado na imagem a seguir.
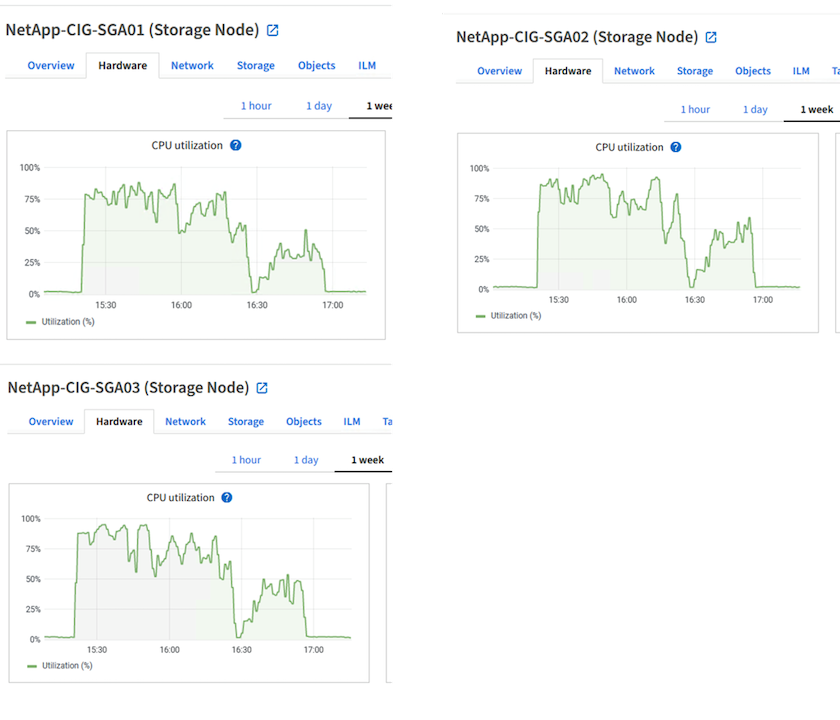
Uso de hardware do StorageGRID
A instância StorageGRID tem um balanceador de carga e três controladores StorageGRID . A utilização da CPU para todos os três controladores é de 75% a 100%.
SmartStore com controlador de armazenamento NetApp - benefícios para o cliente
-
Desvinculando computação e armazenamento. O Splunk SmartStore separa computação e armazenamento, o que ajuda você a dimensioná-los de forma independente.
-
Dados sob demanda. O SmartStore aproxima os dados da computação sob demanda e fornece elasticidade de computação e armazenamento e eficiência de custos para obter maior retenção de dados em escala.
-
Compatível com API AWS S3. O SmartStore usa a API AWS S3 para se comunicar com o armazenamento de restauração, que é um armazenamento de objetos compatível com AWS S3 e API S3, como o StorageGRID.
-
Reduz a necessidade de armazenamento e o custo. O SmartStore reduz os requisitos de armazenamento para dados antigos (quentes/frios). Ele só precisa de uma única cópia de dados porque o armazenamento NetApp fornece proteção de dados e cuida de falhas e alta disponibilidade.
-
Falha de hardware. A falha do nó em uma implantação do SmartStore não torna os dados inacessíveis e tem uma recuperação do indexador muito mais rápida em caso de falha de hardware ou desequilíbrio de dados.
-
Cache com reconhecimento de dados e aplicativos.
-
Adicione e remova indexadores e configure e desmonte clusters sob demanda.
-
A camada de armazenamento não está mais vinculada ao hardware.