

Resultados dos testes
 Sugerir alterações
Sugerir alterações
Uma infinidade de testes foram executados para avaliar o desempenho da arquitetura proposta.
Há seis cargas de trabalho diferentes (classificação de imagens, detecção de objetos [pequenos], detecção de objetos [grandes], imagens médicas, conversão de fala em texto e processamento de linguagem natural [PLN]), que você pode executar em três cenários diferentes: offline, fluxo único e multifluxo.

|
O último cenário é implementado apenas para classificação de imagens e detecção de objetos. |
Isso resulta em 15 cargas de trabalho possíveis, todas testadas em três configurações diferentes:
-
Servidor único/armazenamento local
-
Servidor único/armazenamento em rede
-
Armazenamento multi-servidor/rede
Os resultados são descritos nas seções a seguir.
Inferência de IA em cenário offline para AFF
Neste cenário, todos os dados estavam disponíveis no servidor e o tempo necessário para processar todas as amostras foi medido. Relatamos larguras de banda em amostras por segundo como resultados dos testes. Quando mais de um servidor de computação foi usado, relatamos a largura de banda total somada em todos os servidores. Os resultados para todos os três casos de uso são mostrados na figura abaixo. Para o caso de dois servidores, relatamos a largura de banda combinada de ambos os servidores.
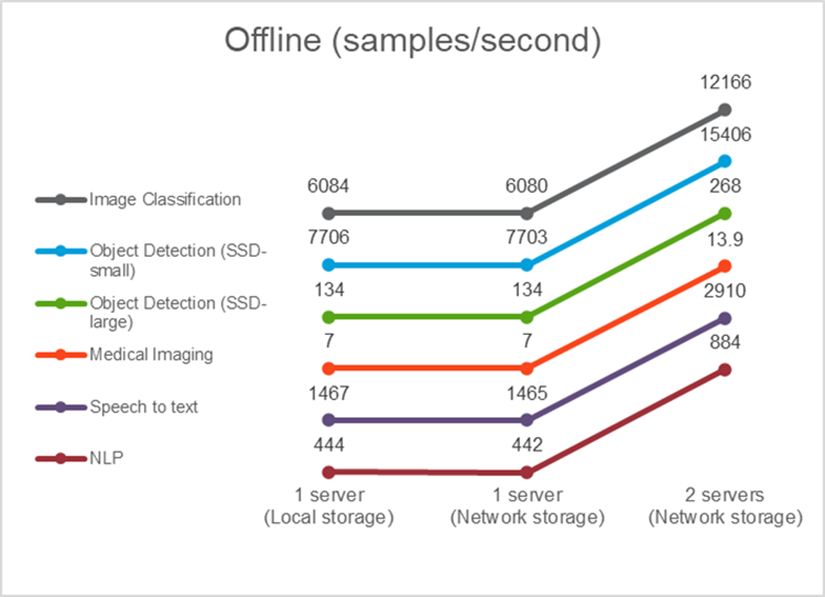
Os resultados mostram que o armazenamento em rede não afeta negativamente o desempenho — a alteração é mínima e, para algumas tarefas, nenhuma é encontrada. Ao adicionar o segundo servidor, a largura de banda total dobra exatamente ou, na pior das hipóteses, a alteração é inferior a 1%.
Inferência de IA em um cenário de fluxo único para AFF
Este benchmark mede a latência. Para o caso de múltiplos servidores computacionais, relatamos a latência média. Os resultados para o conjunto de tarefas são apresentados na figura abaixo. Para o caso de dois servidores, relatamos a latência média de ambos os servidores.
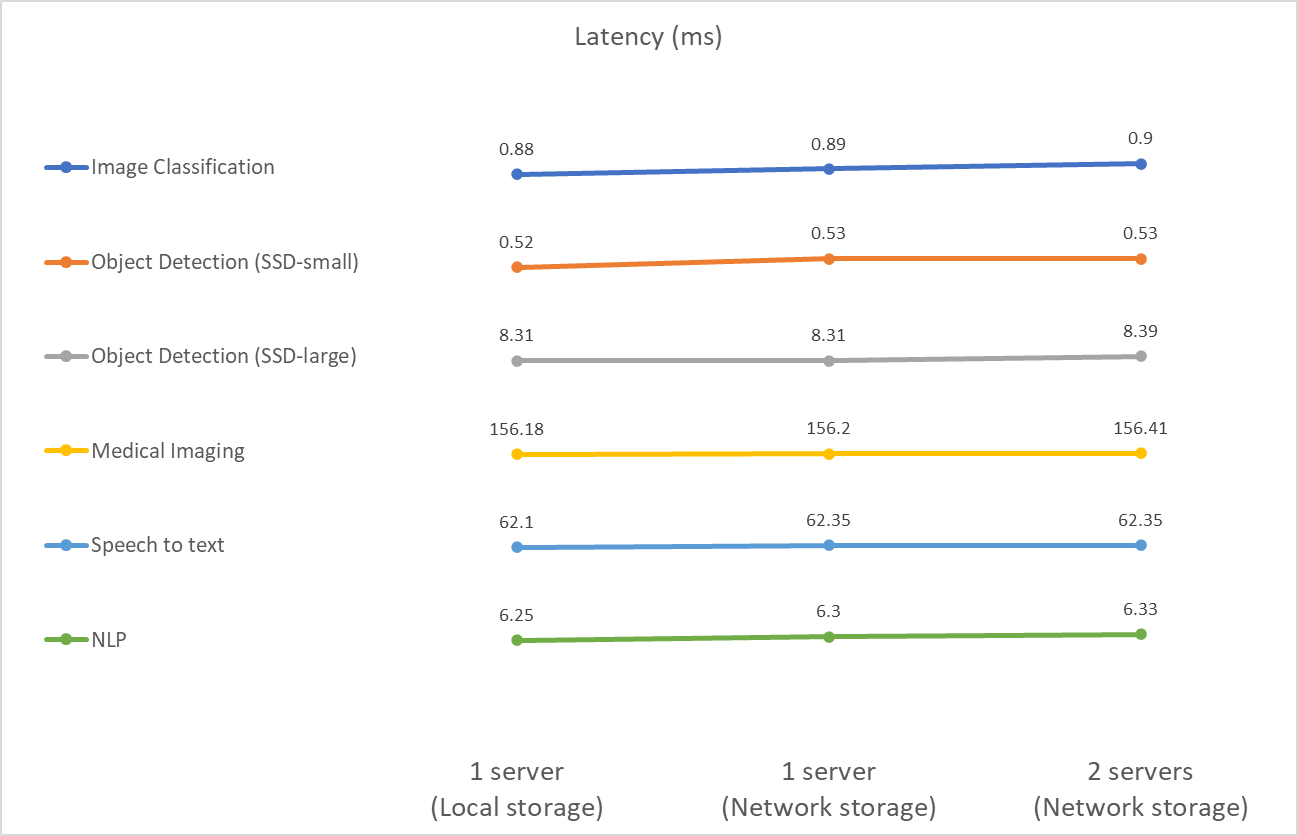
Os resultados, mais uma vez, mostram que o armazenamento em rede é suficiente para lidar com as tarefas. A diferença entre armazenamento local e de rede no caso de um servidor é mínima ou nenhuma. Da mesma forma, quando dois servidores usam o mesmo armazenamento, a latência em ambos os servidores permanece a mesma ou muda em uma quantidade muito pequena.
Inferência de IA em cenário multistream para AFF
Nesse caso, o resultado é o número de fluxos que o sistema pode manipular, satisfazendo a restrição de QoS. Portanto, o resultado é sempre um número inteiro. Para mais de um servidor, relatamos o número total de fluxos somados em todos os servidores. Nem todas as cargas de trabalho suportam esse cenário, mas executamos aquelas que o fazem. Os resultados dos nossos testes estão resumidos na figura abaixo. Para o caso de dois servidores, relatamos o número combinado de fluxos de ambos os servidores.
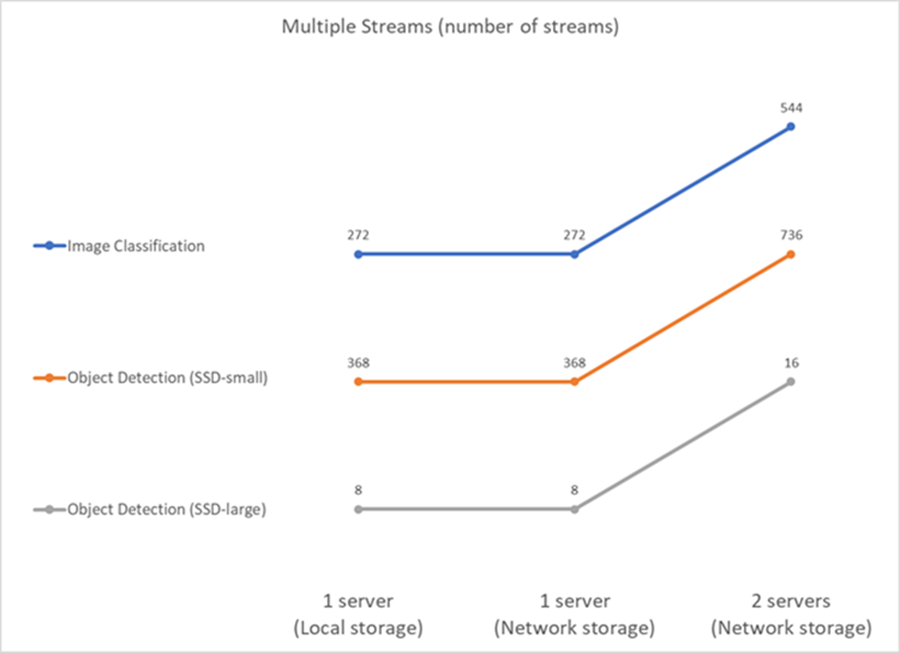
Os resultados mostram o desempenho perfeito da configuração: o armazenamento local e de rede fornecem os mesmos resultados e adicionar o segundo servidor dobra o número de fluxos que a configuração proposta pode manipular.
Resultados dos testes para EF
Uma infinidade de testes foram executados para avaliar o desempenho da arquitetura proposta. Há seis cargas de trabalho diferentes (classificação de imagens, detecção de objetos [pequenos], detecção de objetos [grandes], imagens médicas, conversão de fala em texto e processamento de linguagem natural [PLN]), que foram executadas em dois cenários diferentes: offline e fluxo único. Os resultados são descritos nas seções a seguir.
Inferência de IA em cenário offline para EF
Neste cenário, todos os dados estavam disponíveis no servidor e o tempo necessário para processar todas as amostras foi medido. Relatamos larguras de banda em amostras por segundo como resultados dos testes. Para execuções de nó único, relatamos a média de ambos os servidores, enquanto para execuções de dois servidores, relatamos a largura de banda total somada em todos os servidores. Os resultados para os casos de uso são mostrados na figura abaixo.
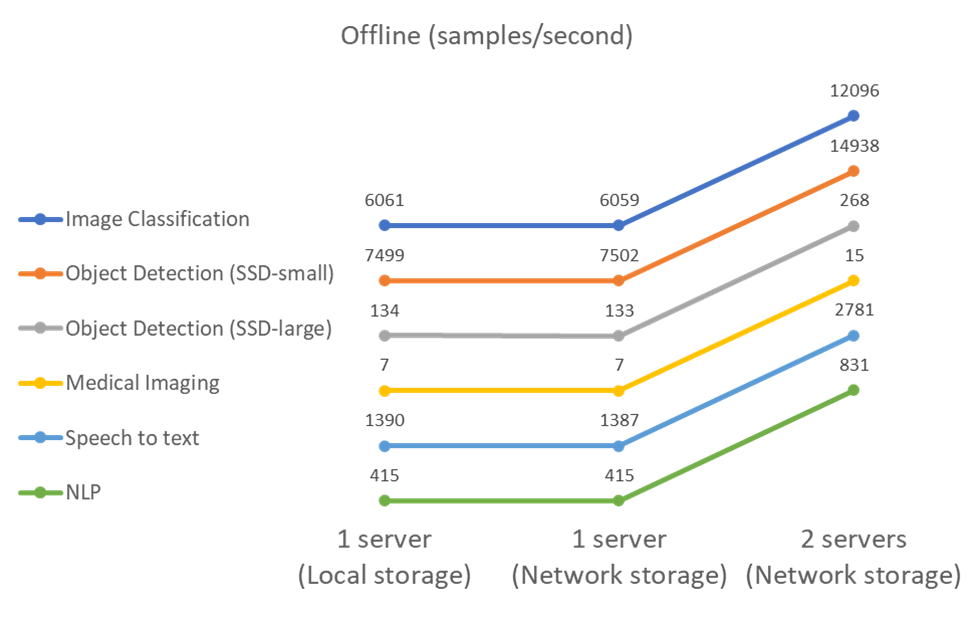
Os resultados mostram que o armazenamento em rede não afeta negativamente o desempenho — a alteração é mínima e, para algumas tarefas, nenhuma é encontrada. Ao adicionar o segundo servidor, a largura de banda total dobra exatamente ou, na pior das hipóteses, a alteração é inferior a 1%.
Inferência de IA em um cenário de fluxo único para EF
Este benchmark mede a latência. Para todos os casos, relatamos a latência média em todos os servidores envolvidos nas execuções. Os resultados para o conjunto de tarefas são fornecidos.
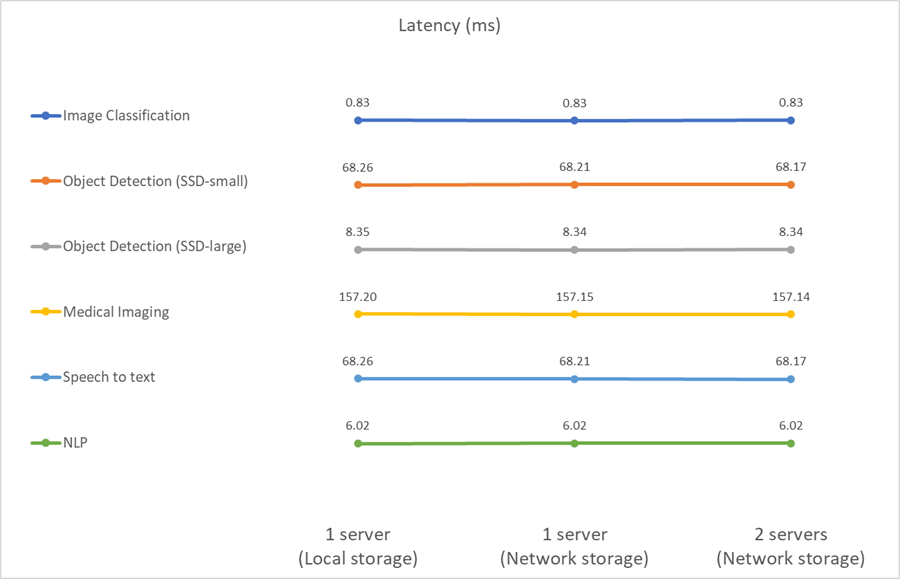
Os resultados mostram novamente que o armazenamento de rede é suficiente para lidar com as tarefas. A diferença entre o armazenamento local e o de rede no caso de um servidor é mínima ou nenhuma. Da mesma forma, quando dois servidores usam o mesmo armazenamento, a latência em ambos os servidores permanece a mesma ou muda em uma quantidade muito pequena.