

Exemplo de fluxo de trabalho - Treinar um modelo de reconhecimento de imagem usando o Kubeflow e o NetApp DataOps Toolkit
 Sugerir alterações
Sugerir alterações
Esta seção descreve as etapas envolvidas no treinamento e na implantação de uma rede neural para reconhecimento de imagem usando o Kubeflow e o NetApp DataOps Toolkit. O objetivo é servir como exemplo para mostrar um trabalho de treinamento que incorpora armazenamento NetApp .
Pré-requisitos
Crie um Dockerfile com as configurações necessárias para usar nas etapas de treinamento e teste dentro do pipeline do Kubeflow. Aqui está um exemplo de um Dockerfile -
FROM pytorch/pytorch:latest
RUN pip install torchvision numpy scikit-learn matplotlib tensorboard
WORKDIR /app
COPY . /app
COPY train_mnist.py /app/train_mnist.py
CMD ["python", "train_mnist.py"]Dependendo de suas necessidades, instale todas as bibliotecas e pacotes necessários para executar o programa. Antes de treinar o modelo de Machine Learning, presume-se que você já tenha uma implantação funcional do Kubeflow.
Treine uma pequena NN em dados MNIST usando PyTorch e pipelines Kubeflow
Usamos o exemplo de uma pequena Rede Neural treinada em dados MNIST. O conjunto de dados MNIST consiste em imagens manuscritas de dígitos de 0 a 9. As imagens têm 28x28 pixels de tamanho. O conjunto de dados é dividido em 60.000 imagens de trens e 10.000 imagens de validação. A rede neural usada neste experimento é uma rede feedforward de duas camadas. O treinamento é executado usando o Kubeflow Pipelines. Consulte a documentação "aqui" para maiores informações. Nosso pipeline do Kubeflow incorpora a imagem do Docker da seção Pré-requisitos.
Visualize resultados usando o Tensorboard
Depois que o modelo estiver treinado, podemos visualizar os resultados usando o Tensorboard. "Tensorboard" está disponível como um recurso no Painel do Kubeflow. Você pode criar um tensorboard personalizado para seu trabalho. O exemplo abaixo mostra o gráfico da precisão do treinamento versus número de épocas e perda de treinamento versus número de épocas.

Experimento com hiperparâmetros usando Katib
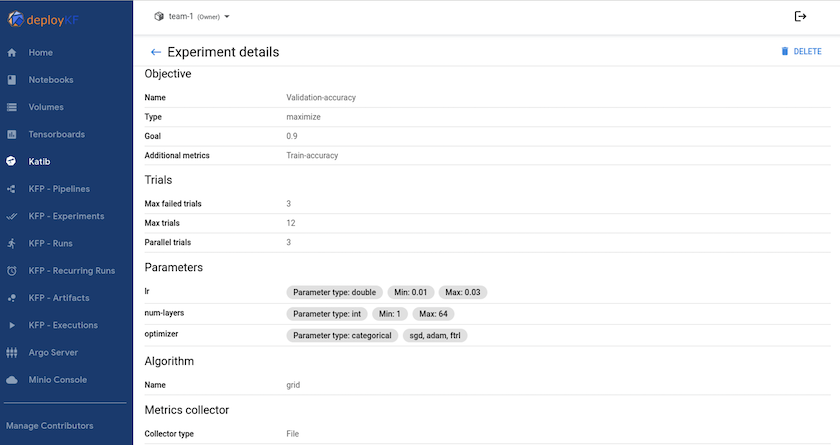
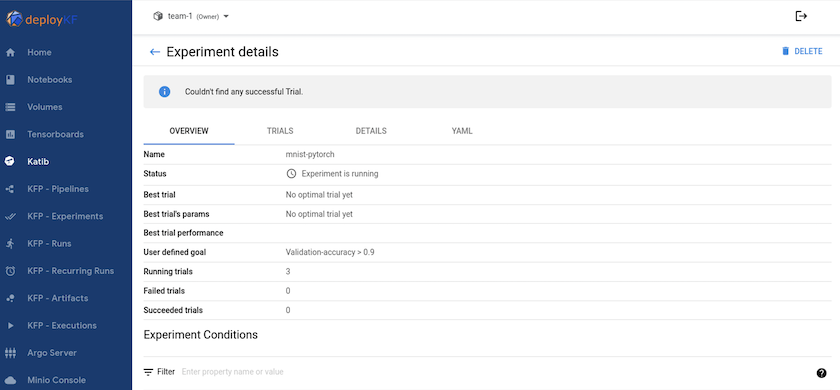
"Katib"é uma ferramenta dentro do Kubeflow que pode ser usada para experimentar os hiperparâmetros do modelo. Para criar um experimento, defina primeiro uma métrica/meta desejada. Geralmente essa é a precisão do teste. Depois que a métrica for definida, escolha os hiperparâmetros com os quais você gostaria de brincar (otimizador/taxa de aprendizado/número de camadas). Katib faz uma varredura de hiperparâmetros com os valores definidos pelo usuário para encontrar a melhor combinação de parâmetros que satisfaçam a métrica desejada. Você pode definir esses parâmetros em cada seção da interface do usuário. Como alternativa, você pode definir um arquivo YAML com as especificações necessárias. Abaixo está uma ilustração de um experimento Katib -
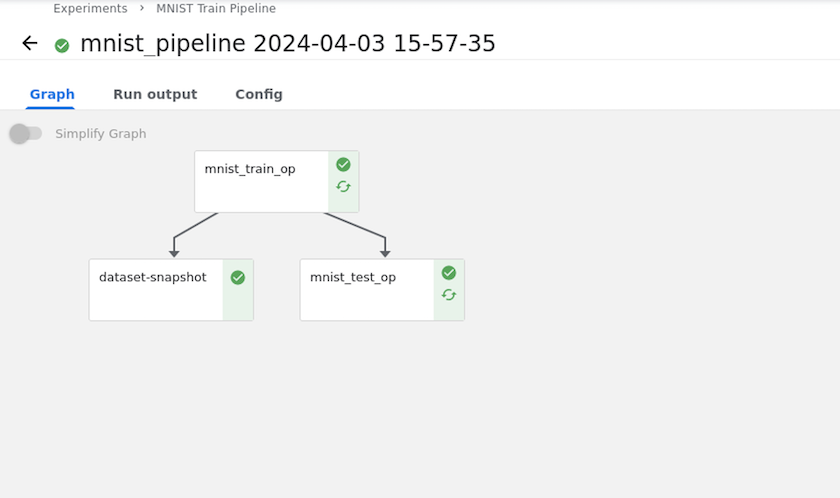
Use instantâneos do NetApp para salvar dados para rastreabilidade
Durante o treinamento do modelo, podemos querer salvar um instantâneo do conjunto de dados de treinamento para rastreabilidade. Para fazer isso, podemos adicionar uma etapa de instantâneo ao pipeline, conforme mostrado abaixo. Para criar o snapshot, podemos usar o "Kit de ferramentas NetApp DataOps para Kubernetes" .

Consulte o "Exemplo do NetApp DataOps Toolkit para Kubeflow" para maiores informações.