

Executar uma carga de trabalho de IA distribuída síncrona
 Sugerir alterações
Sugerir alterações
Para executar um trabalho de IA e ML multinó síncrono no seu cluster Kubernetes, execute as seguintes tarefas no host de salto de implantação. Esse processo permite que você aproveite os dados armazenados em um volume NetApp e use mais GPUs do que um único nó de trabalho pode fornecer. Veja a figura a seguir para uma representação de um trabalho de IA distribuído síncrono.

|
Trabalhos distribuídos síncronos podem ajudar a aumentar o desempenho e a precisão do treinamento em comparação com trabalhos distribuídos assíncronos. Uma discussão sobre os prós e contras de trabalhos síncronos versus trabalhos assíncronos está fora do escopo deste documento. |
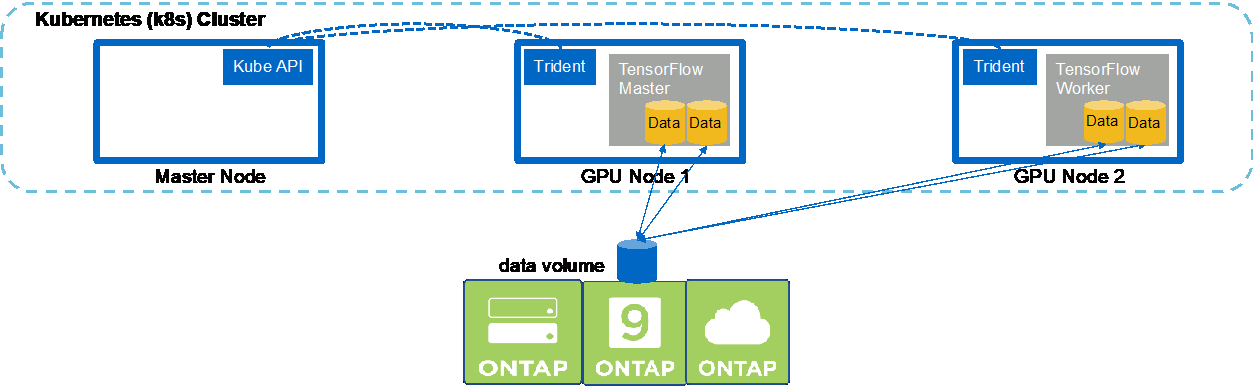
-
Os comandos de exemplo a seguir mostram a criação de um trabalhador que participa da execução distribuída síncrona do mesmo trabalho de benchmark do TensorFlow que foi executado em um único nó no exemplo da seção"Executar uma carga de trabalho de IA de nó único" . Neste exemplo específico, apenas um único trabalhador é implantado porque o trabalho é executado em dois nós de trabalho.
Este exemplo de implantação de trabalhador solicita oito GPUs e, portanto, pode ser executado em um único nó de trabalhador de GPU que apresenta oito ou mais GPUs. Se os nós de trabalho da sua GPU tiverem mais de oito GPUs, para maximizar o desempenho, você pode aumentar esse número para que fique igual ao número de GPUs que os nós de trabalho têm. Para obter mais informações sobre implantações do Kubernetes, consulte o "documentação oficial do Kubernetes" .
Uma implantação do Kubernetes é criada neste exemplo porque esse trabalhador em contêiner específico nunca seria concluído sozinho. Portanto, não faz sentido implantá-lo usando a construção de tarefa do Kubernetes. Se seu trabalhador foi projetado ou escrito para ser concluído sozinho, pode fazer sentido usar a construção de tarefa para implantá-lo.
O pod especificado neste exemplo de especificação de implantação recebe um
hostNetworkvalor detrue. Esse valor significa que o pod usa a pilha de rede do nó de trabalho do host em vez da pilha de rede virtual que o Kubernetes normalmente cria para cada pod. Esta anotação é usada neste caso porque a carga de trabalho específica depende do Open MPI, NCCL e Horovod para executar a carga de trabalho de maneira distribuída e síncrona. Portanto, ele requer acesso à pilha de rede do host. Uma discussão sobre Open MPI, NCCL e Horovod está fora do escopo deste documento. Se isso é verdade ou nãohostNetwork: truea anotação é necessária depende dos requisitos da carga de trabalho específica que você está executando. Para mais informações sobre ohostNetworkcampo, veja o "documentação oficial do Kubernetes" .$ cat << EOF > ./netapp-tensorflow-multi-imagenet-worker.yaml apiVersion: apps/v1 kind: Deployment metadata: name: netapp-tensorflow-multi-imagenet-worker spec: replicas: 1 selector: matchLabels: app: netapp-tensorflow-multi-imagenet-worker template: metadata: labels: app: netapp-tensorflow-multi-imagenet-worker spec: hostNetwork: true volumes: - name: dshm emptyDir: medium: Memory - name: testdata-iface1 persistentVolumeClaim: claimName: pb-fg-all-iface1 - name: testdata-iface2 persistentVolumeClaim: claimName: pb-fg-all-iface2 - name: results persistentVolumeClaim: claimName: tensorflow-results containers: - name: netapp-tensorflow-py2 image: netapp/tensorflow-py2:19.03.0 command: ["bash", "/netapp/scripts/start-slave-multi.sh", "22122"] resources: limits: nvidia.com/gpu: 8 volumeMounts: - mountPath: /dev/shm name: dshm - mountPath: /mnt/mount_0 name: testdata-iface1 - mountPath: /mnt/mount_1 name: testdata-iface2 - mountPath: /tmp name: results securityContext: privileged: true EOF $ kubectl create -f ./netapp-tensorflow-multi-imagenet-worker.yaml deployment.apps/netapp-tensorflow-multi-imagenet-worker created $ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE netapp-tensorflow-multi-imagenet-worker 1 1 1 1 4s -
Confirme se a implantação do trabalhador que você criou na etapa 1 foi iniciada com sucesso. Os comandos de exemplo a seguir confirmam que um único pod de trabalho foi criado para a implantação, conforme indicado na definição de implantação, e que esse pod está atualmente em execução em um dos nós de trabalho da GPU.
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 60s 10.61.218.154 10.61.218.154 <none> $ kubectl logs netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 22122
-
Crie um trabalho do Kubernetes para um mestre que inicia, participa e rastreia a execução do trabalho multinó síncrono. Os comandos de exemplo a seguir criam um mestre que inicia, participa e rastreia a execução distribuída síncrona do mesmo trabalho de benchmark do TensorFlow que foi executado em um único nó no exemplo da seção"Executar uma carga de trabalho de IA de nó único" .
Este exemplo de tarefa mestre solicita oito GPUs e, portanto, pode ser executado em um único nó de trabalho de GPU que apresenta oito ou mais GPUs. Se os nós de trabalho da sua GPU tiverem mais de oito GPUs, para maximizar o desempenho, você pode aumentar esse número para que fique igual ao número de GPUs que os nós de trabalho têm.
O pod mestre especificado neste exemplo de definição de trabalho recebe um
hostNetworkvalor detrue, assim como o grupo de trabalhadores recebeu umahostNetworkvalor detruena etapa 1. Veja a etapa 1 para obter detalhes sobre por que esse valor é necessário.$ cat << EOF > ./netapp-tensorflow-multi-imagenet-master.yaml apiVersion: batch/v1 kind: Job metadata: name: netapp-tensorflow-multi-imagenet-master spec: backoffLimit: 5 template: spec: hostNetwork: true volumes: - name: dshm emptyDir: medium: Memory - name: testdata-iface1 persistentVolumeClaim: claimName: pb-fg-all-iface1 - name: testdata-iface2 persistentVolumeClaim: claimName: pb-fg-all-iface2 - name: results persistentVolumeClaim: claimName: tensorflow-results containers: - name: netapp-tensorflow-py2 image: netapp/tensorflow-py2:19.03.0 command: ["python", "/netapp/scripts/run.py", "--dataset_dir=/mnt/mount_0/dataset/imagenet", "--port=22122", "--num_devices=16", "--dgx_version=dgx1", "--nodes=10.61.218.152,10.61.218.154"] resources: limits: nvidia.com/gpu: 8 volumeMounts: - mountPath: /dev/shm name: dshm - mountPath: /mnt/mount_0 name: testdata-iface1 - mountPath: /mnt/mount_1 name: testdata-iface2 - mountPath: /tmp name: results securityContext: privileged: true restartPolicy: Never EOF $ kubectl create -f ./netapp-tensorflow-multi-imagenet-master.yaml job.batch/netapp-tensorflow-multi-imagenet-master created $ kubectl get jobs NAME COMPLETIONS DURATION AGE netapp-tensorflow-multi-imagenet-master 0/1 25s 25s -
Confirme se o trabalho mestre que você criou na etapa 3 está sendo executado corretamente. O comando de exemplo a seguir confirma que um único pod mestre foi criado para o trabalho, conforme indicado na definição do trabalho, e que esse pod está atualmente em execução em um dos nós de trabalho da GPU. Você também deve ver que o pod de trabalho que você viu originalmente na etapa 1 ainda está em execução e que os pods mestre e de trabalho estão em execução em nós diferentes.
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE netapp-tensorflow-multi-imagenet-master-ppwwj 1/1 Running 0 45s 10.61.218.152 10.61.218.152 <none> netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 26m 10.61.218.154 10.61.218.154 <none>
-
Confirme se o trabalho mestre que você criou na etapa 3 foi concluído com sucesso. Os comandos de exemplo a seguir confirmam que o trabalho foi concluído com sucesso.
$ kubectl get jobs NAME COMPLETIONS DURATION AGE netapp-tensorflow-multi-imagenet-master 1/1 5m50s 9m18s $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 9m38s netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 35m $ kubectl logs netapp-tensorflow-multi-imagenet-master-ppwwj [10.61.218.152:00008] WARNING: local probe returned unhandled shell:unknown assuming bash rm: cannot remove '/lib': Is a directory [10.61.218.154:00033] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 702 [10.61.218.154:00033] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 711 [10.61.218.152:00008] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 702 [10.61.218.152:00008] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 711 Total images/sec = 12881.33875 ================ Clean Cache !!! ================== mpirun -allow-run-as-root -np 2 -H 10.61.218.152:1,10.61.218.154:1 -mca pml ob1 -mca btl ^openib -mca btl_tcp_if_include enp1s0f0 -mca plm_rsh_agent ssh -mca plm_rsh_args "-p 22122" bash -c 'sync; echo 1 > /proc/sys/vm/drop_caches' ========================================= mpirun -allow-run-as-root -np 16 -H 10.61.218.152:8,10.61.218.154:8 -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH -mca pml ob1 -mca btl ^openib -mca btl_tcp_if_include enp1s0f0 -x NCCL_IB_HCA=mlx5 -x NCCL_NET_GDR_READ=1 -x NCCL_IB_SL=3 -x NCCL_IB_GID_INDEX=3 -x NCCL_SOCKET_IFNAME=enp5s0.3091,enp12s0.3092,enp132s0.3093,enp139s0.3094 -x NCCL_IB_CUDA_SUPPORT=1 -mca orte_base_help_aggregate 0 -mca plm_rsh_agent ssh -mca plm_rsh_args "-p 22122" python /netapp/tensorflow/benchmarks_190205/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model=resnet50 --batch_size=256 --device=gpu --force_gpu_compatible=True --num_intra_threads=1 --num_inter_threads=48 --variable_update=horovod --batch_group_size=20 --num_batches=500 --nodistortions --num_gpus=1 --data_format=NCHW --use_fp16=True --use_tf_layers=False --data_name=imagenet --use_datasets=True --data_dir=/mnt/mount_0/dataset/imagenet --datasets_parallel_interleave_cycle_length=10 --datasets_sloppy_parallel_interleave=False --num_mounts=2 --mount_prefix=/mnt/mount_%d --datasets_prefetch_buffer_size=2000 -- datasets_use_prefetch=True --datasets_num_private_threads=4 --horovod_device=gpu > /tmp/20190814_161609_tensorflow_horovod_rdma_resnet50_gpu_16_256_b500_imagenet_nodistort_fp16_r10_m2_nockpt.txt 2>&1
-
Exclua a implantação do trabalhador quando não precisar mais dela. Os comandos de exemplo a seguir mostram a exclusão do objeto de implantação do trabalhador que foi criado na etapa 1.
Quando você exclui o objeto de implantação do trabalhador, o Kubernetes exclui automaticamente todos os pods de trabalhador associados.
$ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE netapp-tensorflow-multi-imagenet-worker 1 1 1 1 43m $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 17m netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 43m $ kubectl delete deployment netapp-tensorflow-multi-imagenet-worker deployment.extensions "netapp-tensorflow-multi-imagenet-worker" deleted $ kubectl get deployments No resources found. $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 18m
-
Opcional: Limpe os artefatos do trabalho mestre. Os comandos de exemplo a seguir mostram a exclusão do objeto de trabalho mestre que foi criado na etapa 3.
Quando você exclui o objeto de trabalho mestre, o Kubernetes exclui automaticamente todos os pods mestres associados.
$ kubectl get jobs NAME COMPLETIONS DURATION AGE netapp-tensorflow-multi-imagenet-master 1/1 5m50s 19m $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 19m $ kubectl delete job netapp-tensorflow-multi-imagenet-master job.batch "netapp-tensorflow-multi-imagenet-master" deleted $ kubectl get jobs No resources found. $ kubectl get pods No resources found.