

Validação de desempenho do banco de dados vetorial
 Sugerir alterações
Sugerir alterações
Esta seção destaca a validação de desempenho que foi realizada no banco de dados de vetores.
Validação de desempenho
A validação de desempenho desempenha um papel fundamental tanto em bancos de dados vetoriais quanto em sistemas de armazenamento, servindo como um fator essencial para garantir a operação ideal e a utilização eficiente de recursos. Bancos de dados vetoriais, conhecidos por manipular dados de alta dimensão e executar pesquisas de similaridade, precisam manter altos níveis de desempenho para processar consultas complexas de forma rápida e precisa. A validação de desempenho ajuda a identificar gargalos, ajustar configurações e garantir que o sistema possa lidar com as cargas esperadas sem degradação do serviço. Da mesma forma, em sistemas de armazenamento, a validação de desempenho é essencial para garantir que os dados sejam armazenados e recuperados de forma eficiente, sem problemas de latência ou gargalos que possam afetar o desempenho geral do sistema. Ele também auxilia na tomada de decisões informadas sobre atualizações ou mudanças necessárias na infraestrutura de armazenamento. Portanto, a validação de desempenho é um aspecto crucial do gerenciamento de sistemas, contribuindo significativamente para manter a alta qualidade do serviço, a eficiência operacional e a confiabilidade geral do sistema.
Nesta seção, pretendemos nos aprofundar na validação de desempenho de bancos de dados vetoriais, como Milvus e pgvecto.rs, com foco em suas características de desempenho de armazenamento, como perfil de E/S e comportamento do controlador de armazenamento netapp em suporte a cargas de trabalho de RAG e inferência dentro do ciclo de vida do LLM. Avaliaremos e identificaremos quaisquer diferenciais de desempenho quando esses bancos de dados forem combinados com a solução de armazenamento ONTAP . Nossa análise será baseada em indicadores-chave de desempenho, como o número de consultas processadas por segundo (QPS).
Confira abaixo a metodologia utilizada para o milvus e o progresso.
Detalhes |
Milvus (autônomo e cluster) |
Postgres(pgvecto.rs) # |
versão |
2.3.2 |
0.2.0 |
Sistema de arquivos |
XFS em LUNs iSCSI |
|
Gerador de carga de trabalho |
"Banco VectorDB"– v0.0.5 |
|
Conjuntos de dados |
Conjunto de dados LAION * 10 milhões de incorporações * 768 dimensões * tamanho do conjunto de dados de ~300 GB |
|
Controlador de armazenamento |
AFF 800 * Versão – 9.14.1 * 4 x 100GbE – para milvus e 2x 100GbE para postgres * iscsi |
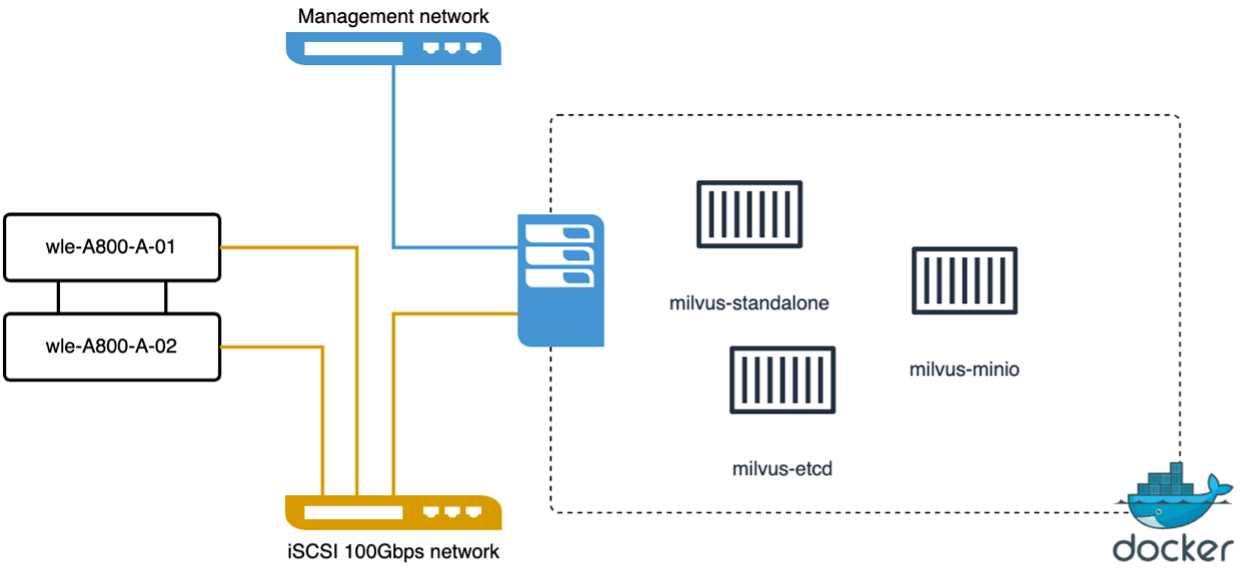
VectorDB-Bench com cluster autônomo Milvus
Fizemos a seguinte validação de desempenho no cluster autônomo milvus com o vectorDB-Bench. A conectividade de rede e servidor do cluster autônomo milvus está abaixo.
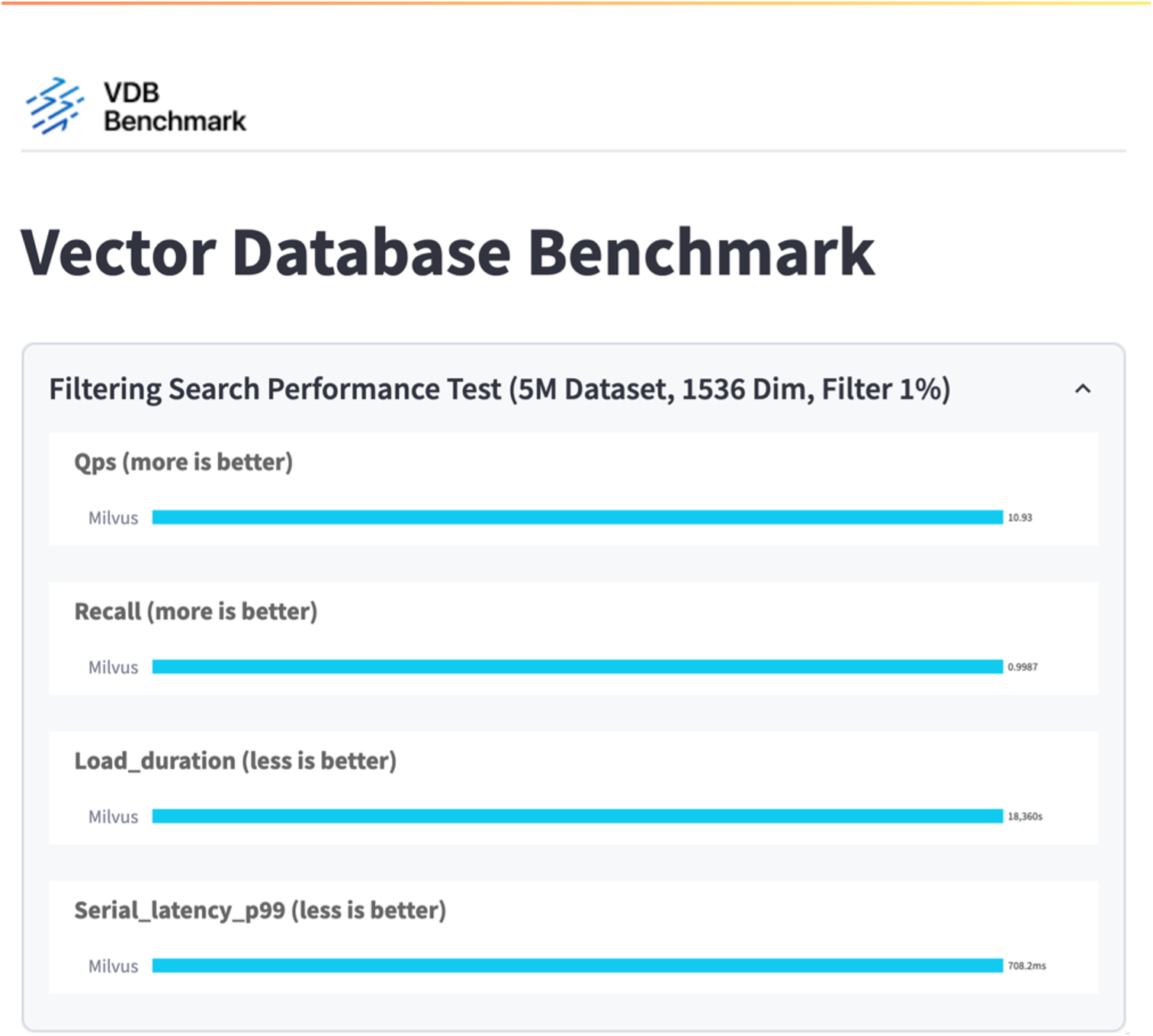
Nesta seção, compartilhamos nossas observações e resultados dos testes do banco de dados independente Milvus. . Selecionamos DiskANN como o tipo de índice para esses testes. . A ingestão, otimização e criação de índices para um conjunto de dados de aproximadamente 100 GB levou cerca de 5 horas. Durante a maior parte desse período, o servidor Milvus, equipado com 20 núcleos (o que equivale a 40 vcpus quando o Hyper-Threading está habilitado), estava operando em sua capacidade máxima de CPU de 100%. Descobrimos que o DiskANN é particularmente importante para grandes conjuntos de dados que excedem o tamanho da memória do sistema. . Na fase de consulta, observamos uma taxa de Consultas por Segundo (QPS) de 10,93 com um recall de 0,9987. A latência do 99º percentil para consultas foi medida em 708,2 milissegundos.
Da perspectiva de armazenamento, o banco de dados emitiu cerca de 1.000 ops/s durante as fases de ingestão, otimização pós-inserção e criação de índice. Na fase de consulta, foram necessárias 32.000 ops/seg.
A seção a seguir apresenta as métricas de desempenho de armazenamento.
| Fase de carga de trabalho | Métrica | Valor |
|---|---|---|
Ingestão de dados e otimização pós-inserção |
IOPS |
< 1.000 |
Latência |
< 400 usecs |
|
Carga de trabalho |
Mistura de leitura/escrita, principalmente escrita |
|
Tamanho de E/S |
64 KB |
|
Consulta |
IOPS |
Pico em 32.000 |
Latência |
< 400 usecs |
|
Carga de trabalho |
100% de leitura em cache |
|
Tamanho de E/S |
Principalmente 8 KB |
O resultado do vectorDB-bench está abaixo.
A partir da validação de desempenho da instância autônoma do Milvus, fica evidente que a configuração atual é insuficiente para suportar um conjunto de dados de 5 milhões de vetores com uma dimensionalidade de 1536. Determinamos que o armazenamento possui recursos adequados e não constitui um gargalo no sistema.
VectorDB-Bench com cluster milvus
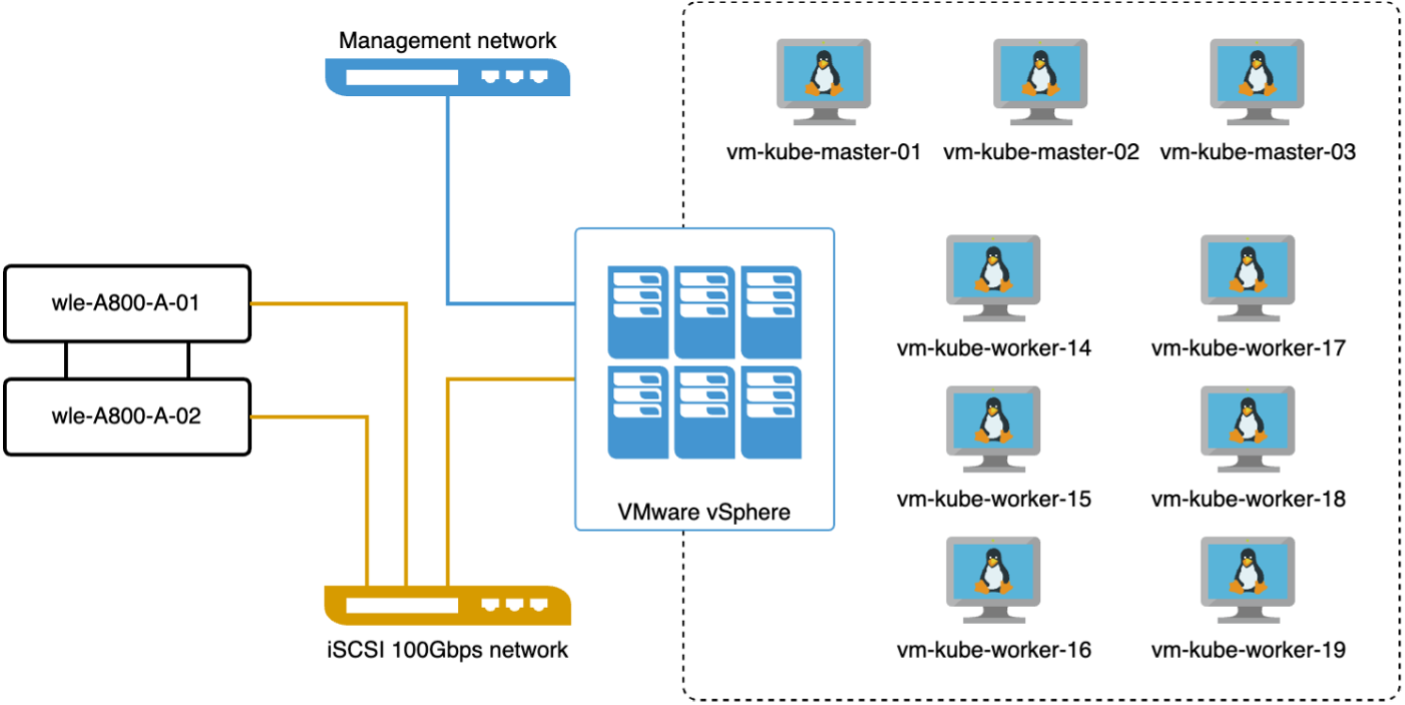
Nesta seção, discutimos a implantação de um cluster Milvus em um ambiente Kubernetes. Esta configuração do Kubernetes foi construída sobre uma implantação do VMware vSphere, que hospedava os nós mestre e de trabalho do Kubernetes.
Os detalhes das implantações do VMware vSphere e do Kubernetes são apresentados nas seções a seguir.
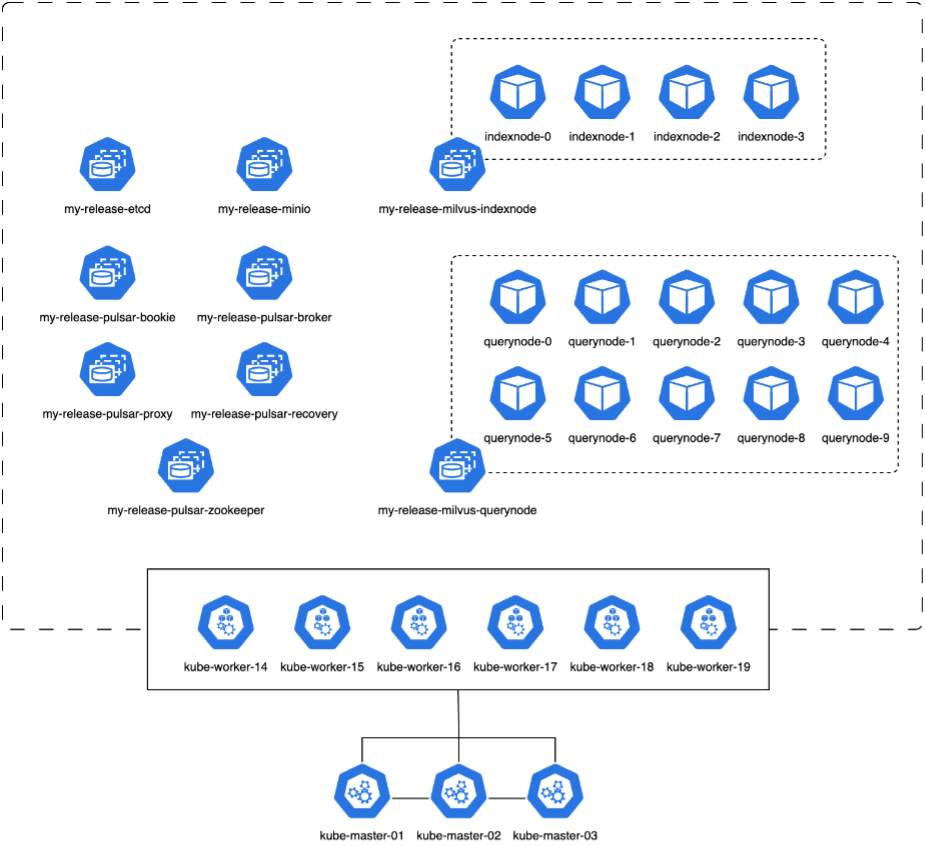
Nesta seção, apresentamos nossas observações e resultados dos testes do banco de dados Milvus. * O tipo de índice usado foi DiskANN. * A tabela abaixo fornece uma comparação entre as implantações autônomas e em cluster ao trabalhar com 5 milhões de vetores em uma dimensionalidade de 1536. Observamos que o tempo necessário para ingestão de dados e otimização pós-inserção foi menor na implantação do cluster. A latência do 99º percentil para consultas foi reduzida em seis vezes na implantação do cluster em comparação à configuração autônoma. * Embora a taxa de Consultas por Segundo (QPS) tenha sido maior na implantação do cluster, ela não estava no nível desejado.

As imagens abaixo fornecem uma visão de várias métricas de armazenamento, incluindo latência do cluster de armazenamento e IOPS (operações de entrada/saída por segundo) total.
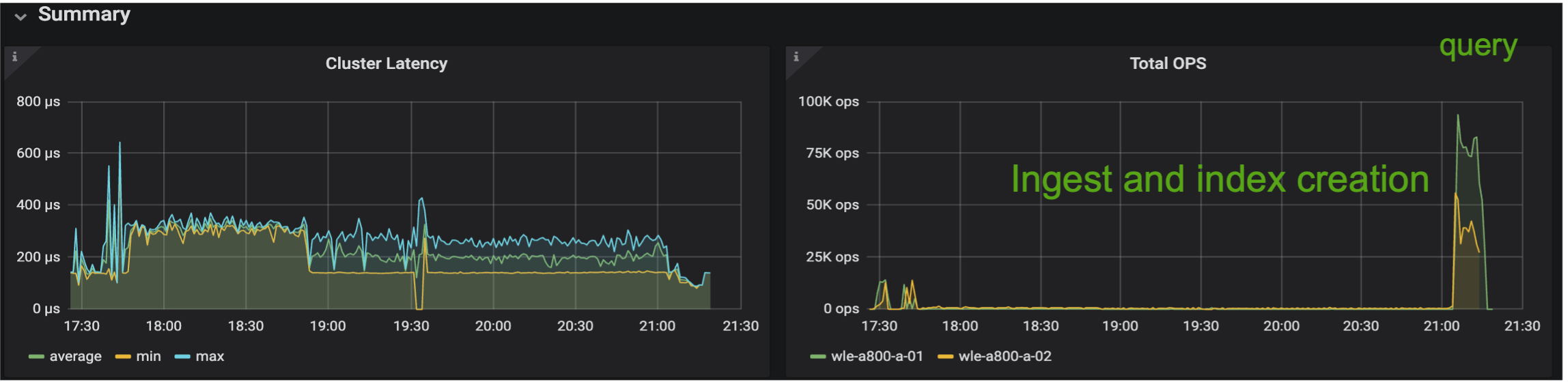
A seção a seguir apresenta as principais métricas de desempenho de armazenamento.
| Fase de carga de trabalho | Métrica | Valor |
|---|---|---|
Ingestão de dados e otimização pós-inserção |
IOPS |
< 1.000 |
Latência |
< 400 usecs |
|
Carga de trabalho |
Mistura de leitura/escrita, principalmente escrita |
|
Tamanho de E/S |
64 KB |
|
Consulta |
IOPS |
Pico em 147.000 |
Latência |
< 400 usecs |
|
Carga de trabalho |
100% de leitura em cache |
|
Tamanho de E/S |
Principalmente 8 KB |
Com base na validação de desempenho do Milvus autônomo e do cluster Milvus, apresentamos os detalhes do perfil de E/S de armazenamento. * Observamos que o perfil de E/S permanece consistente em implantações autônomas e em cluster. * A diferença observada no pico de IOPS pode ser atribuída ao maior número de clientes na implantação do cluster.
vectorDB-Bench com Postgres (pgvecto.rs)
Realizamos as seguintes ações no PostgreSQL (pgvecto.rs) usando o VectorDB-Bench: Os detalhes sobre a conectividade de rede e servidor do PostgreSQL (especificamente, pgvecto.rs) são os seguintes:
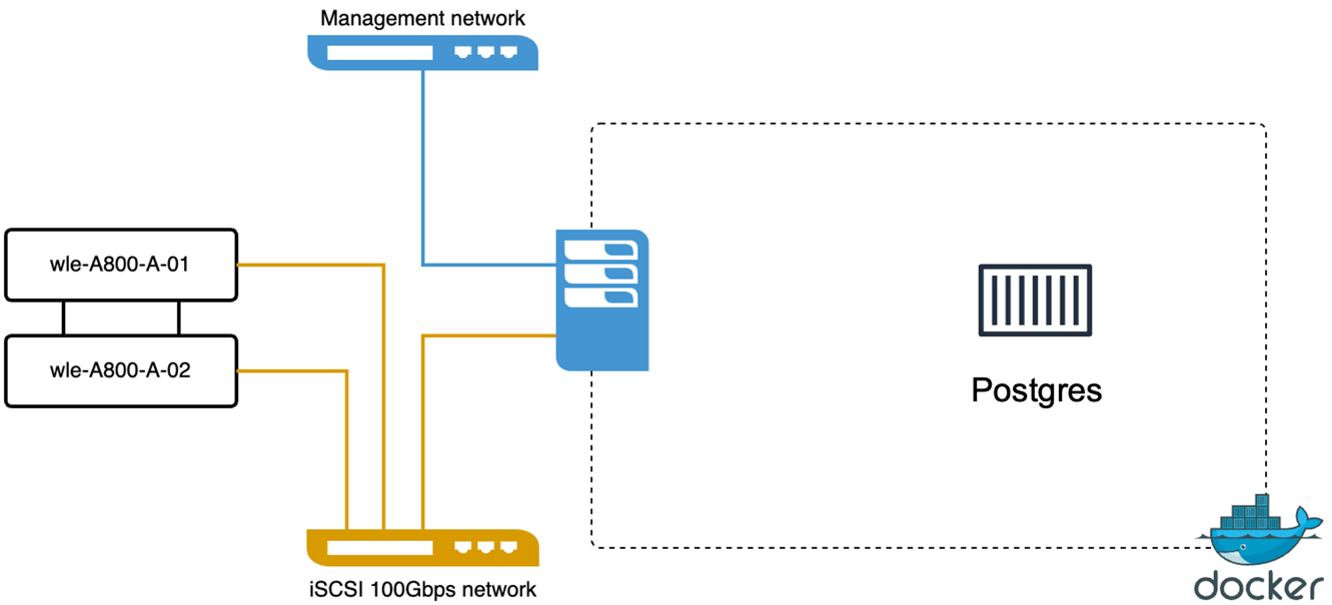
Nesta seção, compartilhamos nossas observações e resultados dos testes do banco de dados PostgreSQL, especificamente usando pgvecto.rs. * Selecionamos HNSW como o tipo de índice para esses testes porque, no momento do teste, o DiskANN não estava disponível para pgvecto.rs. * Durante a fase de ingestão de dados, carregamos o conjunto de dados Cohere, que consiste em 10 milhões de vetores com uma dimensionalidade de 768. Esse processo levou aproximadamente 4,5 horas. * Na fase de consulta, observamos uma taxa de Consultas por Segundo (QPS) de 1.068 com um recall de 0,6344. A latência do 99º percentil para consultas foi medida em 20 milissegundos. Durante a maior parte do tempo de execução, a CPU do cliente estava operando a 100% da capacidade.
As imagens abaixo fornecem uma visão de várias métricas de armazenamento, incluindo latência total do cluster de armazenamento (IOPS) (operações de entrada/saída por segundo).

The following section presents the key storage performance metrics. image:pgvecto-storage-perf-metrics.png["Figura mostrando diálogo de entrada/saída ou representando conteúdo escrito"]
Comparação de desempenho entre milvus e postgres no banco de dados vetorial Bench
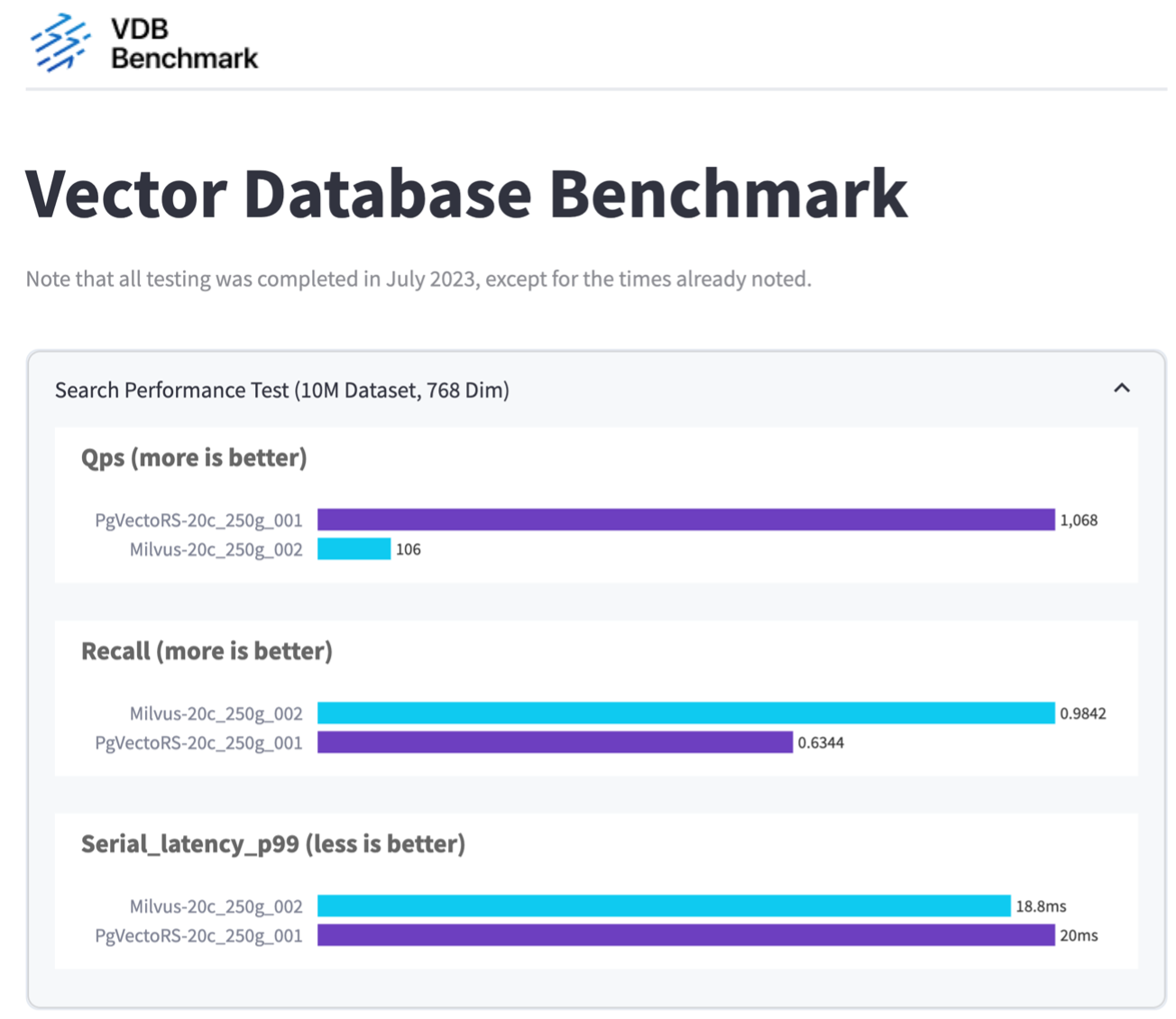
Com base em nossa validação de desempenho do Milvus e PostgreSQL usando VectorDBBench, observamos o seguinte:
-
Tipo de índice: HNSW
-
Conjunto de dados: Cohere com 10 milhões de vetores em 768 dimensões
Descobrimos que pgvecto.rs atingiu uma taxa de Consultas por Segundo (QPS) de 1.068 com um recall de 0,6344, enquanto Milvus atingiu uma taxa de QPS de 106 com um recall de 0,9842.
Se alta precisão em suas consultas for uma prioridade, o Milvus supera o pgvecto.rs, pois recupera uma proporção maior de itens relevantes por consulta. Entretanto, se o número de consultas por segundo for um fator mais crucial, pgvecto.rs supera Milvus. É importante observar, porém, que a qualidade dos dados recuperados via pgvecto.rs é inferior, com cerca de 37% dos resultados da pesquisa sendo itens irrelevantes.
Observação baseada em nossas validações de desempenho:
Com base em nossas validações de desempenho, fizemos as seguintes observações:
No Milvus, o perfil de E/S se assemelha muito a uma carga de trabalho OLTP, como a vista com o Oracle SLOB. O benchmark consiste em três fases: ingestão de dados, pós-otimização e consulta. Os estágios iniciais são caracterizados principalmente por operações de gravação de 64 KB, enquanto a fase de consulta envolve predominantemente leituras de 8 KB. Esperamos que o ONTAP lide com a carga de E/S do Milvus com eficiência.
O perfil de E/S do PostgreSQL não apresenta uma carga de trabalho de armazenamento desafiadora. Dada a implementação na memória atualmente em andamento, não observamos nenhuma E/S de disco durante a fase de consulta.
DiskANN surge como uma tecnologia crucial para diferenciação de armazenamento. Ele permite o dimensionamento eficiente da pesquisa de banco de dados vetorial além do limite de memória do sistema. No entanto, é improvável que seja possível estabelecer diferenciação de desempenho de armazenamento com índices de banco de dados vetoriais na memória, como HNSW.
Também vale a pena notar que o armazenamento não desempenha um papel crítico durante a fase de consulta quando o tipo de índice é HSNW, que é a fase operacional mais importante para bancos de dados vetoriais que dão suporte a aplicativos RAG. A implicação aqui é que o desempenho do armazenamento não afeta significativamente o desempenho geral desses aplicativos.