

Casos de uso de banco de dados vetorial
 Sugerir alterações
Sugerir alterações
Esta seção fornece uma visão geral dos casos de uso para a solução de banco de dados vetorial da NetApp .
Casos de uso de banco de dados vetorial
Nesta seção, discutimos dois casos de uso, como Geração Aumentada de Recuperação com Grandes Modelos de Linguagem e chatbot de TI da NetApp .
Geração Aumentada de Recuperação (RAG) com Grandes Modelos de Linguagem (LLMs)
Retrieval-augmented generation, or RAG, is a technique for enhancing the accuracy and reliability of Large Language Models, or LLMs, by augmenting prompts with facts fetched from external sources. In a traditional RAG deployment, vector embeddings are generated from an existing dataset and then stored in a vector database, often referred to as a knowledgebase. Whenever a user submits a prompt to the LLM, a vector embedding representation of the prompt is generated, and the vector database is searched using that embedding as the search query. This search operation returns similar vectors from the knowledgebase, which are then fed to the LLM as context alongside the original user prompt. In this way, an LLM can be augmented with additional information that was not part of its original training dataset.
O NVIDIA Enterprise RAG LLM Operator é uma ferramenta útil para implementar o RAG na empresa. Este operador pode ser usado para implantar um pipeline RAG completo. O pipeline RAG pode ser personalizado para utilizar Milvus ou pgvecto como banco de dados vetorial para armazenar incorporações de base de conhecimento. Consulte a documentação para obter detalhes.
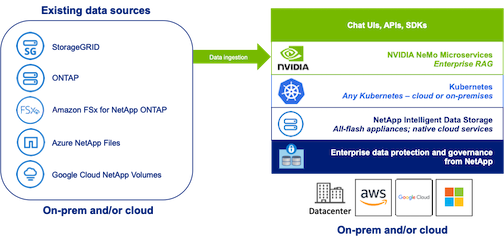
NetApp has validated an enterprise RAG architecture powered by the NVIDIA Enterprise RAG LLM Operator alongside NetApp storage. Refer to our blog post for more information and to see a demo. Figure 1 provides an overview of this architecture.
Figura 1) Enterprise RAG com tecnologia NVIDIA NeMo Microservices e NetApp
Caso de uso do chatbot de TI da NetApp
O chatbot da NetApp serve como outro caso de uso em tempo real para o banco de dados vetorial. Neste caso, o NetApp Private OpenAI Sandbox fornece uma plataforma eficaz, segura e eficiente para gerenciar consultas de usuários internos da NetApp. Ao incorporar protocolos de segurança rigorosos, sistemas eficientes de gerenciamento de dados e recursos sofisticados de processamento de IA, ele garante respostas precisas e de alta qualidade aos usuários com base em suas funções e responsabilidades na organização por meio de autenticação SSO. Esta arquitetura destaca o potencial de mesclar tecnologias avançadas para criar sistemas inteligentes focados no usuário.
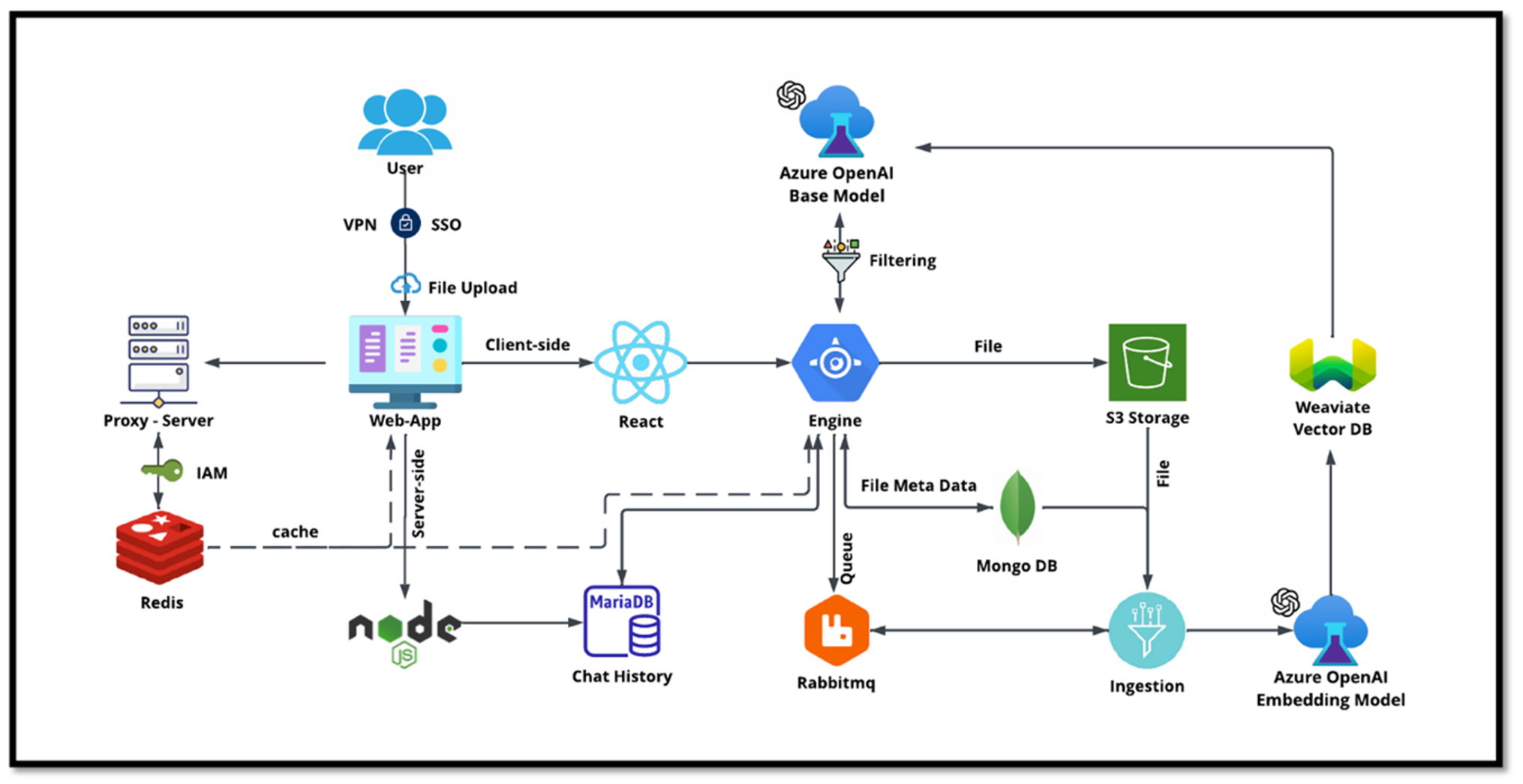
O caso de uso pode ser dividido em quatro seções principais.
Autenticação e verificação do usuário:
-
As consultas do usuário passam primeiro pelo processo de logon único (SSO) da NetApp para confirmar a identidade do usuário.
-
Após a autenticação bem-sucedida, o sistema verifica a conexão VPN para garantir uma transmissão segura de dados.
Transmissão e processamento de dados:
-
Depois que a VPN é validada, os dados são enviados ao MariaDB por meio dos aplicativos web NetAIChat ou NetAICreate. MariaDB é um sistema de banco de dados rápido e eficiente usado para gerenciar e armazenar dados do usuário.
-
O MariaDB então envia as informações para a instância do NetApp Azure, que conecta os dados do usuário à unidade de processamento de IA.
Interação com OpenAI e filtragem de conteúdo:
-
A instância do Azure envia as perguntas do usuário para um sistema de filtragem de conteúdo. Este sistema limpa a consulta e a prepara para processamento.
-
A entrada limpa é então enviada ao modelo base do Azure OpenAI, que gera uma resposta com base na entrada.
Geração e moderação de respostas:
-
A resposta do modelo base é primeiro verificada para garantir que seja precisa e atenda aos padrões de conteúdo.
-
Após passar na verificação, a resposta é enviada de volta ao usuário. Esse processo garante que o usuário receba uma resposta clara, precisa e apropriada à sua consulta.